- DAG 구성
-
Job이 Stage로 구분되는 방법을 이해하려면 먼저 Stage에서 실행되는 Task의 종류를 알아야한다.
-
두 종류의 Task가 있다 ; Shuffle Map Task와 Result Task이다.
-
Shuffle Map Task : 맵리듀스 셔플의 맵 부분과 비슷하다. 각 Shuffle Map Task는 파티셔닝 함수에 기반하여 RDD 파티션 당 하나의 계산을 실행하고, 그 결과를 새로운 파티션 집합에 저장한다. 새로운 파티션의 데이터는 Shuffle Map Task나 Result Task로 구성된 다음에 Stage에서 사용된다. Shuffle Map Task는 마지막 스테이지를 제외한 모든 Stage에서 실행될 수 있다.
-
Result Task : count() 액션의 결과처럼 그 결과를 사용자 프로그램에 돌려주는 마지막 스테이지에서 실행된다. 각 결과 태스크는 RDD 파티션에서 계산을 수행하고 그 결과를 드라이버에 돌려준다. 드라이버는 각 파티션의 결과를 하나로 모아서 최종 결과를 만든다. 예를 들어 saveAsTextFile()과 같은 액션은 각각의 결과를 모으지 않고 독립적으로 저장한다.
- 예시
val hist: Map[Int, Long] = sc.textFile(inputPath)
.map(word => (word.toLowerCase(), 1))
.reduceByKey((a, b) => a + b)
.map(_.swap)
.countByKey()
- 처음 두 개의 트랜스포메이션인 map()과 reduceByKey()는 단어 수를 센다. 세번째 트랜스포메이션은 map()으로, 각 쌍에서 key와 value 순서를 바꾸어 (count, word)의 쌍으로 만든다. 마지막 연산인 countByKey() 액션은 각 단어 수 의 빈도를 반환한다.
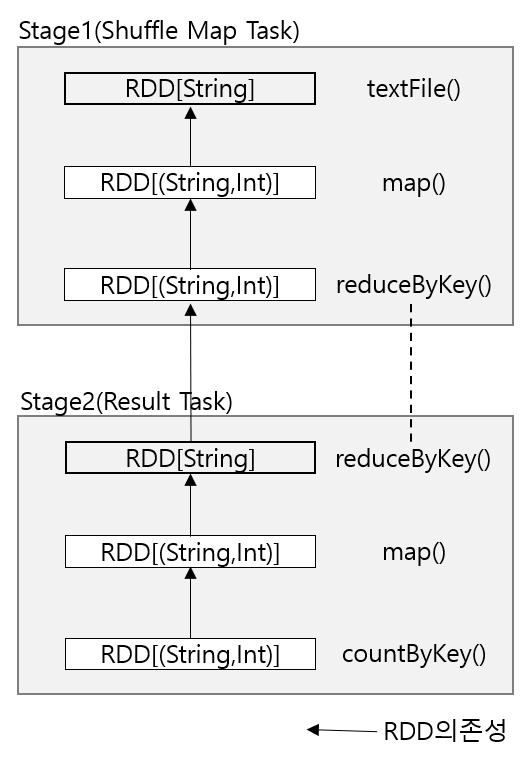
- DAG 스케줄러는 이 Job을 두개의 스테이지로 변환하는데, reduceByKey() 연산이 셔플 스테이지가 필요하기 때문이다.
-
단어 빈도 분포를 계삲나는 Spark Job의 Stage와 RDD
-
textFile() : MappedRDD[String]을 생성하여 반환한다.
-
reduceByKey() : 셔플로 구현되어있으며, 이 함수는 맵리듀스와 유사하게 맵부분(Stage1)에서는 Combiner로 동작하고, Reduce 부분(Stage2)에서는 Reducer로 동작한다.
※ 지역성 : DAG 스케줄러는 Task 스케줄러가 데이터 지역성을 활용할 수 있도록 개별 Task의 배치 우선권을 지정한다. 예를 들어 HDFS에 저장된 입력 RDD의 파티션을 처리하는 Task는 파티션의 블록을 저장하고 있는 Data node에 배치 우선권이 주어진다.(노드 로컬) 반면 메모리에 저장된 RDD의 파티션을 처리하는 Task는 RDD 파티션을 저장하고 있는 익스큐터를 선호한다(프로세스 로컬)
※ Spark에서 셔플을 구현할 때는 맵리듀스와 마찬가지고 결과를 심지어 인메모리 RDD를 사용하더라도 로컬 디스크에 파티션파일로 저장한 후 그 파일을 다음 스테이지의 RDD에서 불러온다.(p706, Hadoop the Definitive Guide)
