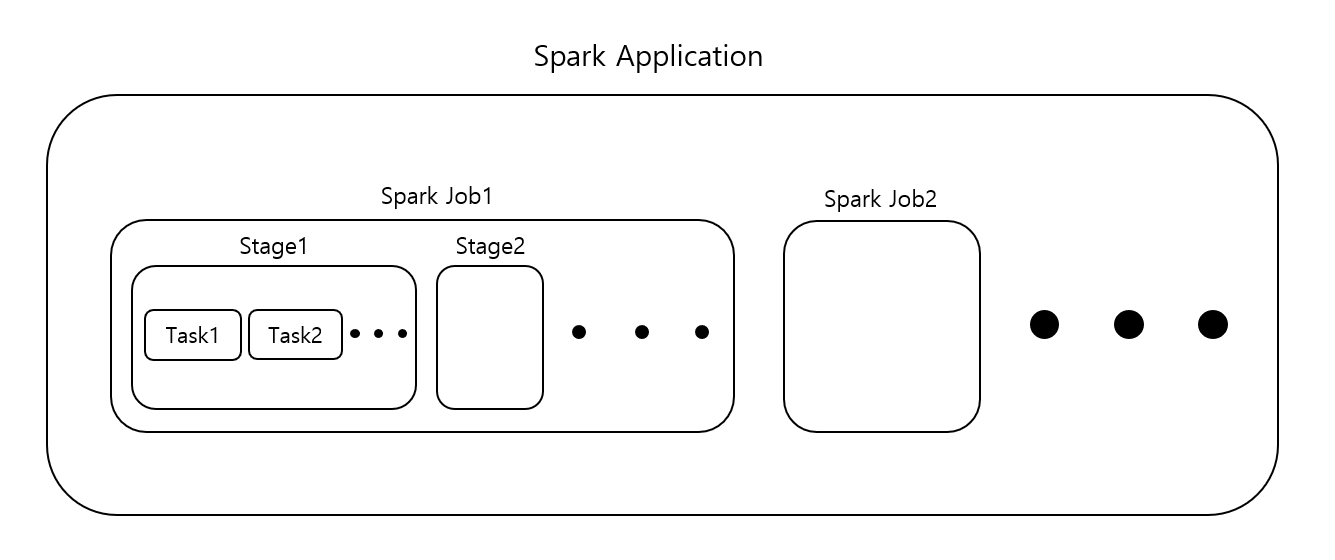
[Spark Application, Job, Stage, Task]
-
하나의 Application은 하나 이상의 Job을 수행할 수 있으며, 동일한 Application에서 수행된 이전 Job에서 caching된 RDD에 접근할 수 있는 매커니즘이 있다.
-
Job은 항상 RDD 및 공유변수를 제공하는 Application의 SparkContext 내에서 실행된다. (per action)
-
하나의 Map과 하나의 Reduce로 구성된 단일 MapReduce의 Job과는 다르게, Spark의 job은 방향성 비순환 그래프(DAG)인 Stage로 구성된다. (per shuffle)
-
Spark가 실행될 때 Stage는 여러 Task로 분할되고, 각 Task는 MapReduce의 Task와 같이 cluster에 분산된 RDD partition에서 병렬로 실행된다. (per partition)
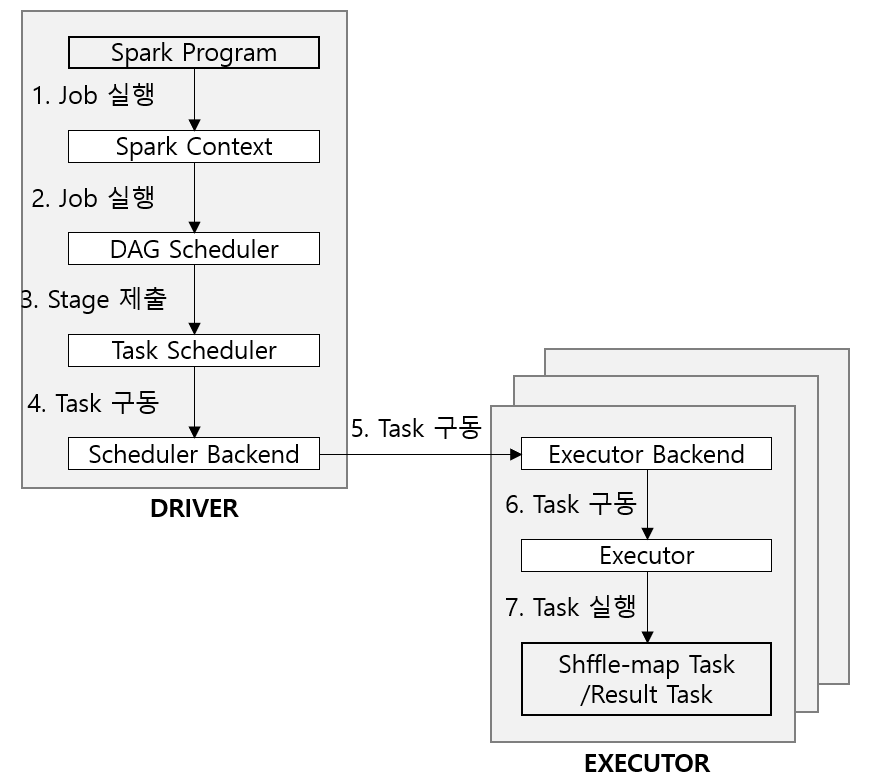
[Spark Application의 Job 제출]
-
Spark Job은 한 개 이상 transformation을 거친 RDD에 count()와 같은 action이 호출될 때 자동을 제출된다. (내부적으로는 SparkContext의 runJob()이 호출된다)
-
요청을 DAG 스케줄러에 전달한다.
-
DAG 스케줄러는 전체 Stages의 DAG를 구성한 후 개별 Stage의 Task 집합을 Task 스케줄러에 넘긴다.
- 이때 Task 스케줄러는 해당 애플리케이션이 실행되는 익스큐터의 목록을 찾고 배치 우선권이 있는 익스큐터에 각 태스크를 매핑한다. 그 다음에 빈 코어가 있는 익스큐터에 Task를 할당한다.
-
태스크가 할당되면 스케줄러의 백엔드에서 구동을 위한 작업이 시작된다.
-
스케줄러 백엔드는 익스큐터 백엔드에 태스크를 구동하라는 원격 메세지를 보낸다.
-
익스큐터는 해당 태스크를 실행한다.
-
첫번째로 태스크의 JAR 및 파일 의존성을 검사하여 최신인지 확인한다. 두번째로 Task 구동 메세지의 일부로 전송된 직렬화 바이트를 사용자 함수가 포함된 Task 코드로 역직렬화한다. 세번째로 Task 코드를 수행한다. 이 때 Task는 익스큐터와 동일한 JVM에서 실행되므로 Task 실행에 따른 프로세스 오버헤드는 없다.
-
Task는 드라이버에 결과를 반환할 수 있다. 그 결과는 직렬화되어 익스큐터 백엔드로 전송된다. 그리고 상태변경 메세지를 드라이버에 돌려준다. 셔플 맵 태스크는 다음 스테이지를 위해 출력 파티션에 대한 정보를 반환하고, 결과 태스크는 처리한 파티션의 결곽값을 반환한다. 드라이버는 반환된 값을 취합하여 최종결과를 사용자 프로그램에 돌려준다.
※ 스파크는 원격 호출에 하둡 RPC를 사용하지 않고, 고확장성의 이벤트 기반 분산 애플리케이션을 구축할 수 있는 액터 기반 플랫폼인 Akka를 사용한다.
※ 스케줄러는 두 부분으로 구성된다. DAG스케줄러는 Job을 Stage의 DAG로 구분하고, Task 스케줄러는 각 Stage의 관련 Task를 클러스터에 제출한다.
