※ 스파크에서 자원 사용량을 기반으로 효율적인 코드를 작성하고 싶거나, 에러를 만났을 때 어떻게 처리해야할지 알기 위해 LifeCycle을 알 필요가 있다. 라이브러리를 추가 설치하거나, 특정 에러를 조치하려면 어플리케이션을 다시 시작해야할 수도 있다. 또, action이 일어날 때마다 익스큐터들이 동적으로 변하는 현상의 배경을 이해할 필요가 있다.
● 스파크 외부
1. Spark Application Job 제출
- Spark Driver Process를 생성하는 것이 목적이다.
- Spark Application은 compiled JAR나 library file이다.
- CLI script 작성 또는 code 상 action을 통해 cluster manager에 제출한다.
- 이 과정에서 spark driver process의 자원을 함께 요청한다.
- Cluster manager가 요청을 받아들이고 Cluter node 중 하나(Master)에 driver process를 실행한다.
- Spark job을 제출한 client process는 종료된다.
- ※ 하나의 SparkSession 은 하나의 Spark Application에 대응한다.
2. 시작
- Executor process를 시작하는 것이 목적이다.
- Driver process가 cluster에 배치되었으니 사용자 코드를 실행할 수 있다.
- 사용자 코드는 SparkSession이라는 객체를 진입점으로 통신한다.
- ① SparkSession이 cluster manager와 통신하여 executor 실행을 요청한다.
- ② Cluster manager가 executor process를 실행한다.
- 이 때 인수를 지정하여 executor 수와 설정 값을 지정할 수 있다.
- Cluster manager는 executor process 시작 결과를 받아 executor 위치/관련 정보를 driver process로 회신한다.
3. 실행
- Driver process와 executor process는 code를 실행하고 data를 이동하는 과정에서 서로 통신한다.
- Driver process는 각 executor에 task를 할당한다.
- Task를 할당받은 executor는 task의 상태와 성공/실패 여부를 driver에 전송한다.
4. 완료
- 스파크 어플리케이션 실행이 완료되면 드라이버 프로세스가 성공/실패 중 하나의 상태로 종료된다.
- 그 후에 클러스터 매니저는 드라이버가 속한 스파크 클러스터의 모든 익스큐터를 종료시킵니다.
- 스파크 어플리케이션의 성공/실패 여부는 클러스터 매니저에 요청해 확인할 수 있다.
● 스파크 내부
-
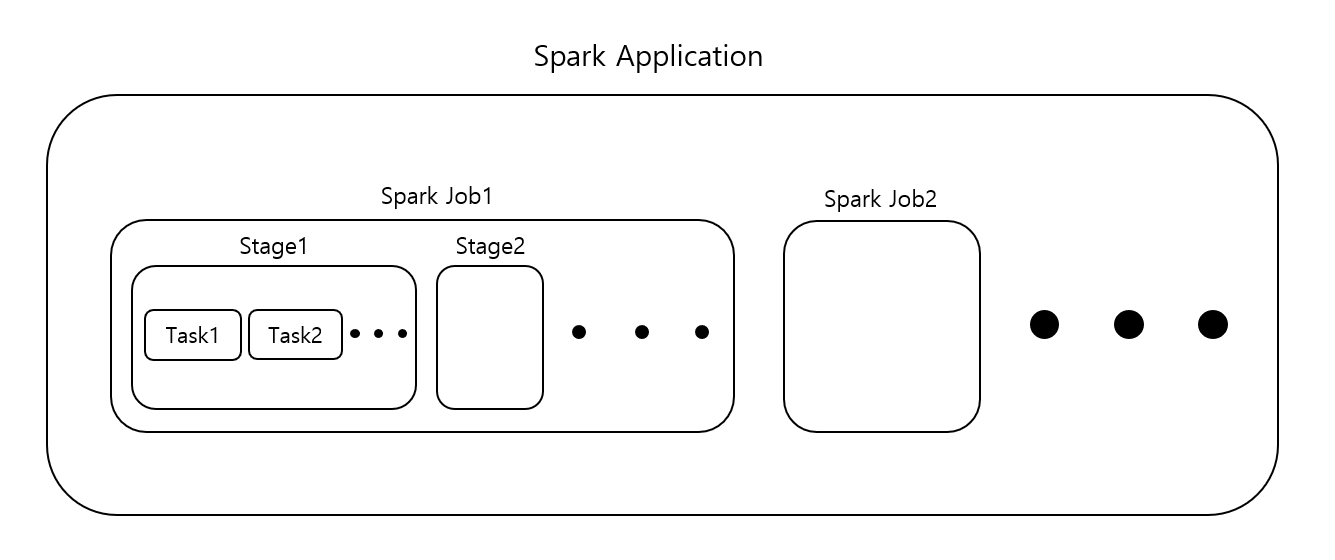
스파크어플리케이션은 하나 이상의 Job으로 구성되며, 이는 사용자 코드로 정의됩니다.
-
멀티 스레딩 등 병렬처리를 하는 것이 아니라면 Spark Job은 차례대로 수행됩니다.
-
동작원리를 이해하고 모니터링을 하려면 Spark Job/Stage/Task의 관계를 알아야합니다.
-
Spark Job
- 보통 액션 하나당 하나의 스파크 잡이 생성되며, 액션은 결과를 반환합니다.
- 스파크 잡은 일련의 스테이지로 나뉘며, 스테이지 수는 셔플작업이 얼마나 많이 발생하는지에 따라 달라집니다.
-
Spark Stage
- 스테이지는 다수의 머신에서 동일한 연산을 수행하는 태스크의 그룹을 나타냅니다.
- 스파크는 가능한 많은 태스크(job의 transformations)를 동일한 스테이지로 묶습니다.
- 셔플 작업이 일어난 다음에는 반드시 새로운 스테이지를 시작합니다.
- 디폴트 값으로 셔플작업 후에 파티션 수는 200입니다.
- spark.sql.shuffle.partitions 값을 조정할 수 있습니다.
- 효율적인 수행을 위해 클러스터 코어 수에 맞추어 설정합니다. 경험적으로 익스큐터 수보다 파티션 수를 더 크게 지정하는 것이 좋습니다.
- 로컬 머신에서 코드를 실행하는 경우 병렬로 처리할 수 있는 태스크 수가 제한적이므로 이 값을 작게 설정해야합니다.
-
Spark Task
- 스파크의 스테이지는 태스트로 구성됩니다.
- 각 태스크는 단일 익스큐터에서 실행할 데이터의 블록과 다수의 트랜스포메이션 조합으로 볼 수 있습니다.
- 데이터가 하나의 파티션으로 구성된 경우 하나의 태스크만 생성됩니다.
- 1천개의 작은 파티션으로 구성된 경우 1천개의 태스크를 만들어 병렬로 실행할 수 있습니다.
- 즉, 태스크는 데이터 단위(파티션)에 적용되는 연산 단위를 의미합니다.
- 파티션 수를 늘리면 높은 병렬 성을 얻을 수 있는 것입니다. 기본적으로 최적화를 위한 가장 간단한 방법입니다.

yozzum