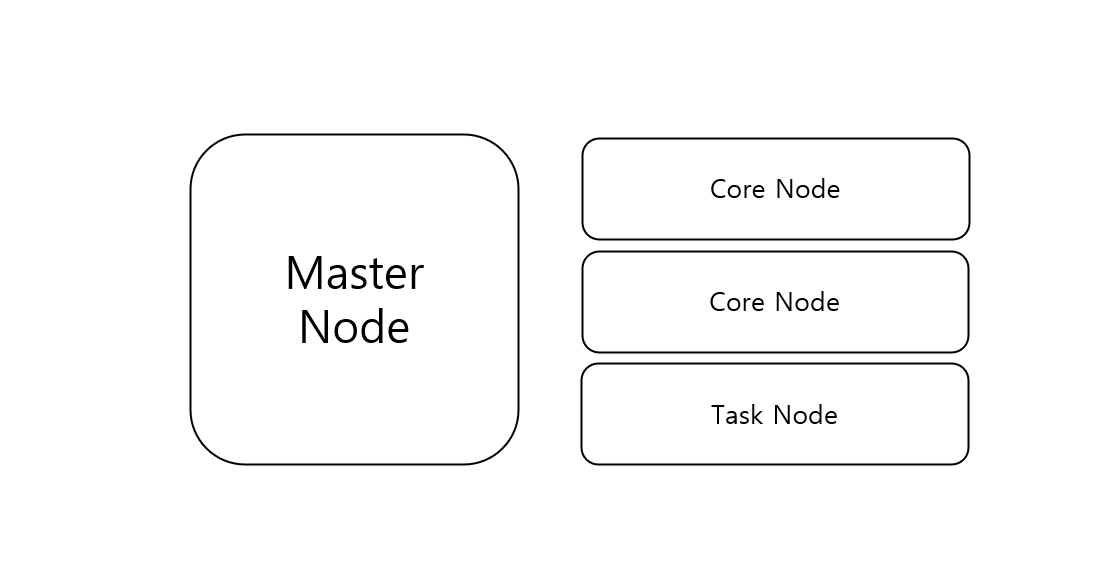
- Spark 물리 구성
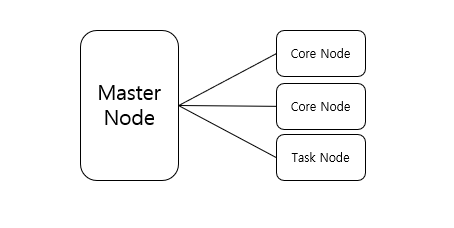
- AWS EMR에서는 Master/Core/Task node를 각각 spec과 함께 선택할 수 있다.
- Core와 Task는 둘 다 Worker node로, HDFS가 있고 없음의 차이이다.
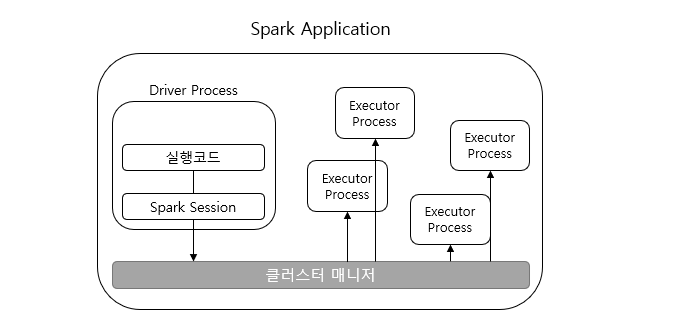
- Spark 논리 구성
- 주요 구성은 Driver, Executor, Cluster Manager이다.
-
Cluster Manager : Standalone/Apache Mesos/Hadoop YARN/Kubernetes
- Cluster의 물리적 machine/resource 관리 및 유지
- 물리적 master/worker node의 자원을 spark driver와 executor 자원에 할당/관리
- 모든 node에 떠 있는 demon process 형태이다.
- 사용자는 cluster manager에 Spark Application을 제출한다.
-
Spark Driver
- SparkContext를 포함한 spark application의 실행 제어 및 job의 task를 scheduling
- executor의 상태와 task의 모든 상태 정보 유지
- cluster manager와 통신하여 물리적 computing 자원 확보 및 executor 실행
- AWS EMR에서 Driver는 Master node에 생성된다.
-
Spark Executor
- application의 실행을 관장
- spark driver가 할당한 task를 수행
- task의 상태와 task 실행 결과를 driver에 보고
- AWS EMR에서 executor는 worker node에 생성된다.
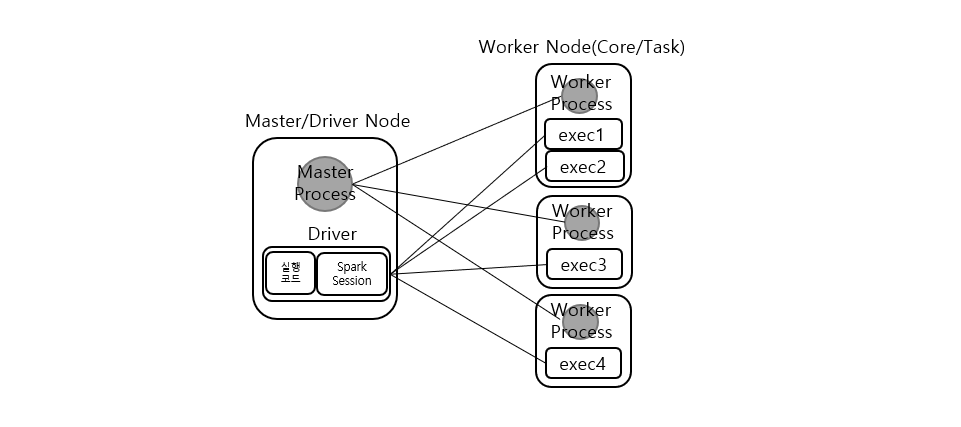
- 스파크 물리 + 논리 구성
- Cluster manager는 논리적으로 Master Node와 Worker Node 중간에 위치할 수 있지만, 물리적으로는 Master 노드를 중심으로 모든 node에 managing 작업을 위한 demon process를 가리킨다.
- 그림에서는 회색으로 표기한 부분이다.
※ SparkSession
- 모든 스파크 어플리케이션은 가장 먼저 SparkSession을 생성합니다.
- SparkSession을 생성하면 스파크 코드를 실행할 수 있습니다.
- 모든 스파크 코드는 RDD명령으로 컴파일됩니다.
- 사용자는 스파크 코드를 실행하기 위해 SparkSession 객체를 진입점으로 사용합니다.
from pyspark.sql import SparkSession spark = SparkSession.builder.master("local").appName("Test")\ .config("spark.some.config.option", "some-value")\ .getOrCreate()
※ SparkContext
- SparkSession의 SparkContext는 스파크 클러스터에 대한 연결을 가리킵니다.
- 과거에는 sc 변수를 활용했습니다.
- SparkContext를 통해 RDD와 같은 저수준 API를 사용할 수 있습니다.
- SparkSession으로 SparkContext에 접근 가능하니 명시적으로 SparkContext를 초기화할 필요는 없습니다.

yozzum