Part 09. 머신러닝 - 앙상블 기법
정밀도와 재현율의 tradeoff
# classification_report
from sklearn.metrics import classification_report
print(classification_report(y_test, lr.predict(X_test))) precision recall f1-score support
0.0 0.68 0.58 0.62 477
1.0 0.77 0.84 0.81 823
accuracy 0.74 1300 macro avg 0.73 0.71 0.71 1300
weighted avg 0.74 0.74 0.74 1300
# confusion matrix
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, lr.predict(X_test)))
#[[275 202]
# [131 692]]
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve
# 적절한 클래스에 대한 확률을 선택
pred = lr.predict_proba(X_test)[:, 1] # 양성 클래스(1)에 대한 확률
# precision-recall curve 계산
precisions, recalls, thresholds = precision_recall_curve(y_test, pred)
# 그래프 그리기
plt.figure(figsize=(10, 8))
plt.plot(thresholds, precisions[:-1], label='Precision')
plt.plot(thresholds, recalls[:-1], label='Recall')
plt.grid()
plt.legend()
plt.show()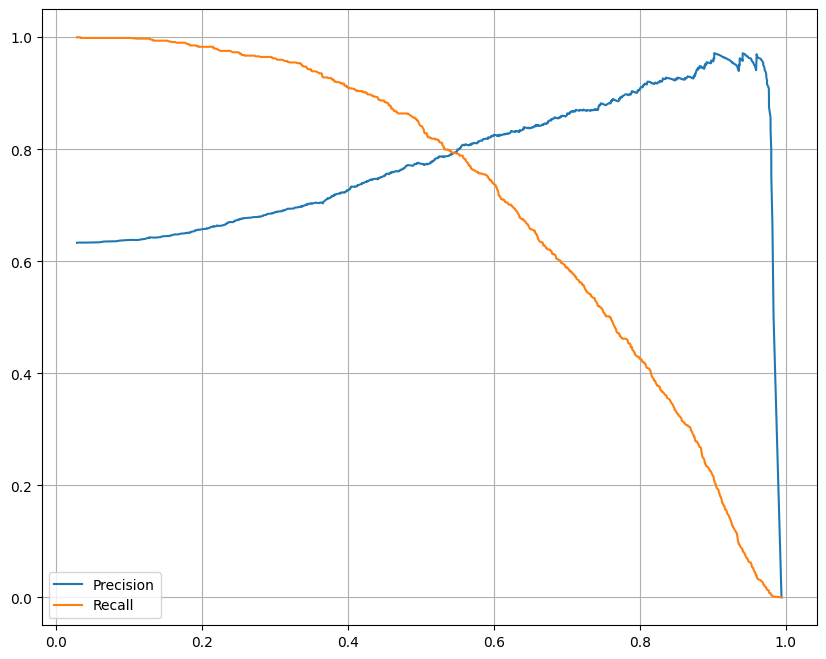
=> precision을 높게 가져가면 Recall이 많이 떨어짐
# threshlod = 0.5
pred_proba = lr.predict_proba(X_test)
pred_proba[:3]
# 0일 확률, 1일 확률
# array([[0.40526731, 0.59473269],
# [0.50957556, 0.49042444],
# [0.10215001, 0.89784999]])
# 각 테스트 샘플에 대해 예측된 확률과 예측된 클래스를 열 방향으로 결합하여 하나의 배열로 만들기
import numpy as np
np.concatenate([pred_proba, y_pred_test.reshape(-1,1)], axis=1)
array([[0.40526731, 0.59473269, 1. ],
[0.50957556, 0.49042444, 0. ],
[0.10215001, 0.89784999, 1. ],
...,
[0.22540242, 0.77459758, 1. ],
[0.67366935, 0.32633065, 0. ],
[0.31452992, 0.68547008, 1. ]])
# threshold 바꿔보기
from sklearn.preprocessing import Binarizer
binarizer = Binarizer(threshold=0.6).fit(pred_proba)
pred_bin = binarizer.transform(pred_proba)[:, 1]
pred_bin
# array([0., 0., 1., ..., 1., 0., 1.])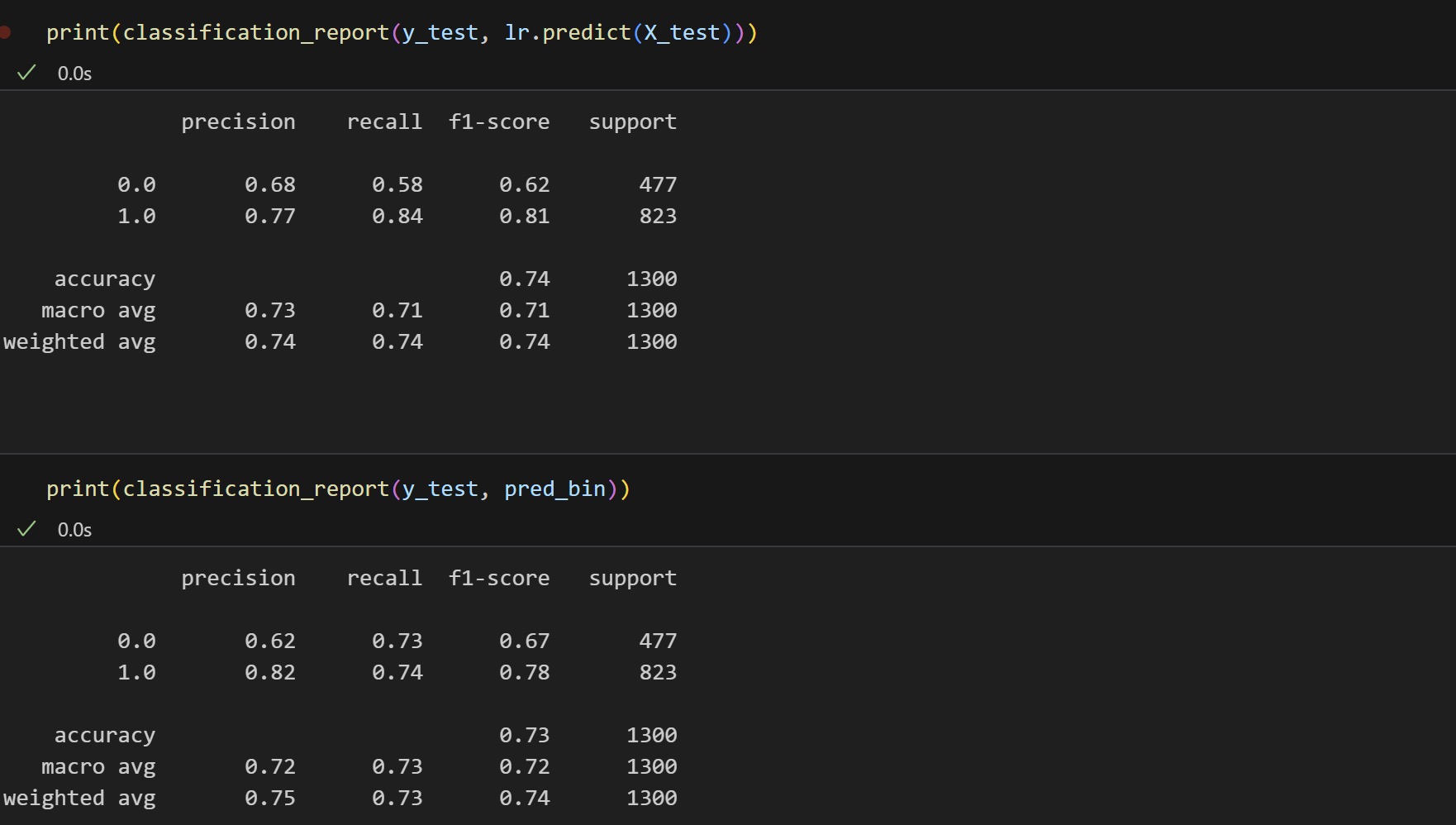
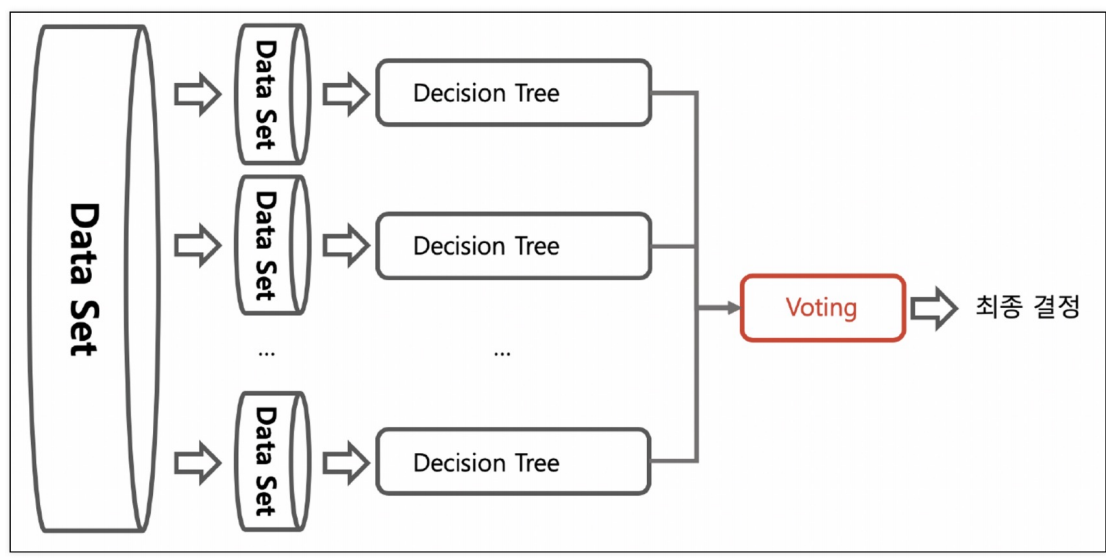
앙상블 기법

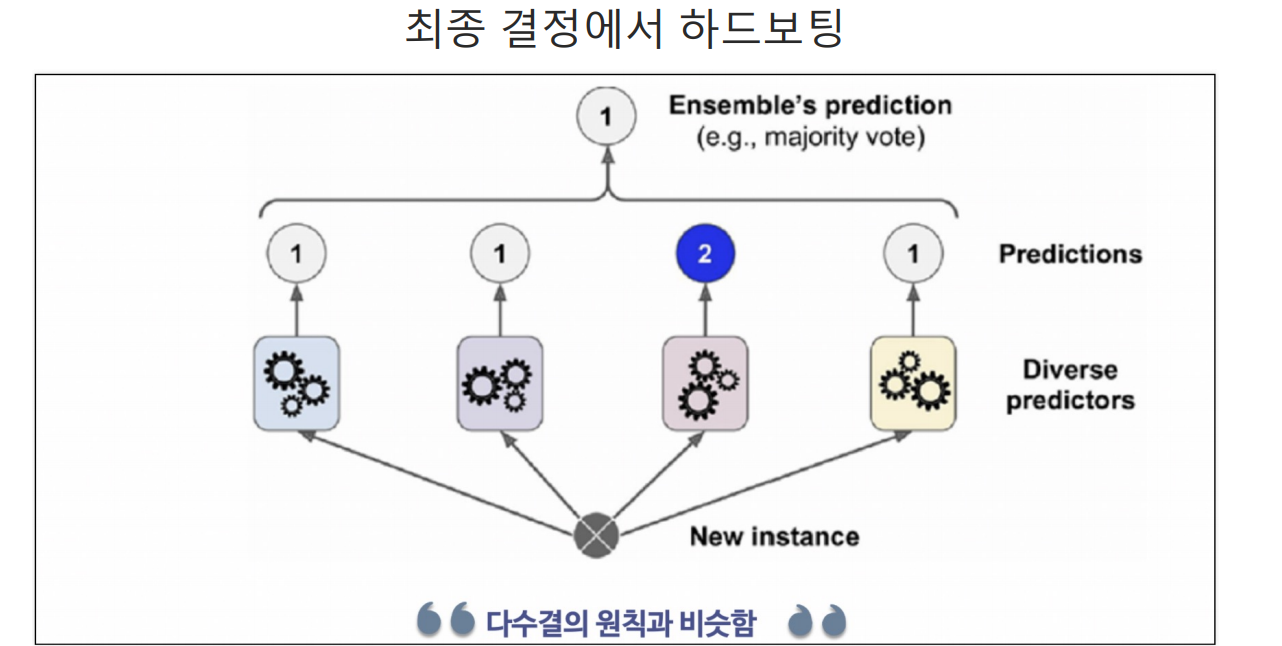
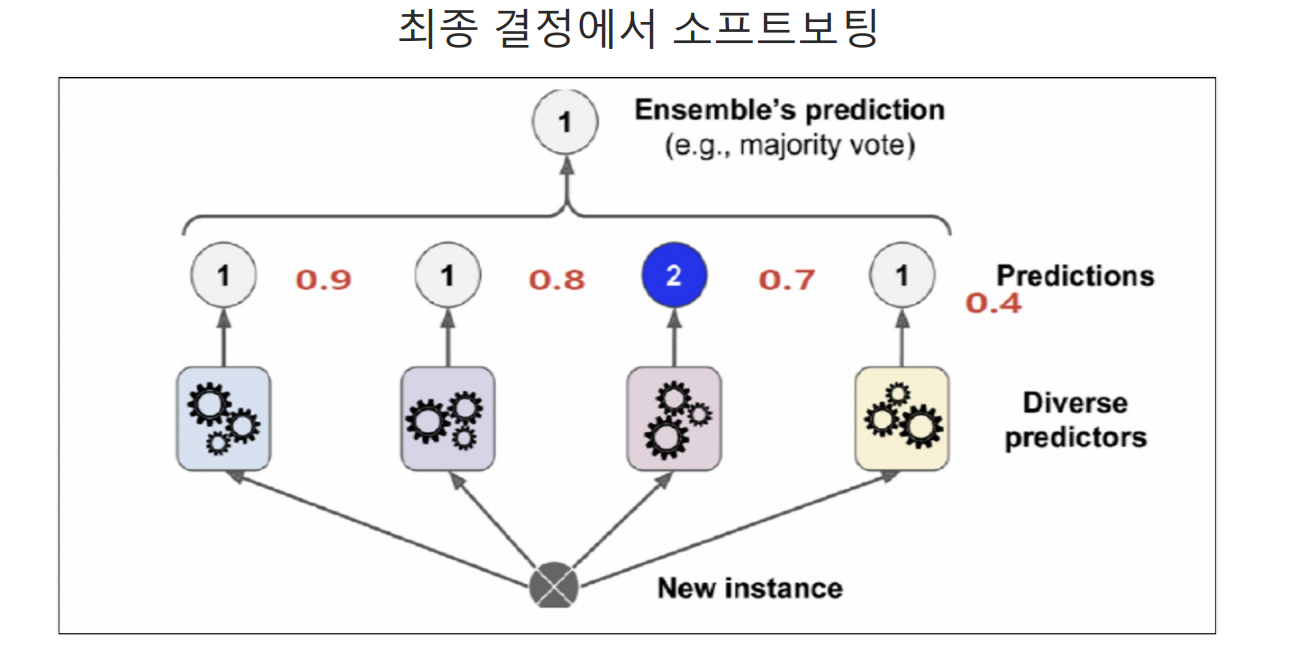
Voting
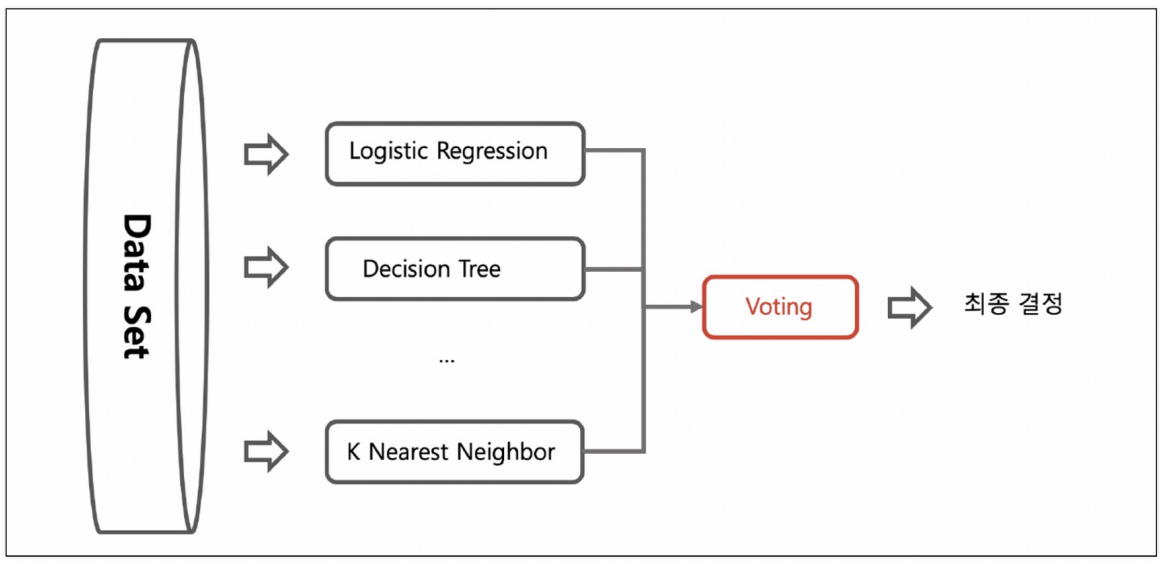
하나의 데이터에 가각 다른 알고리즘 적용
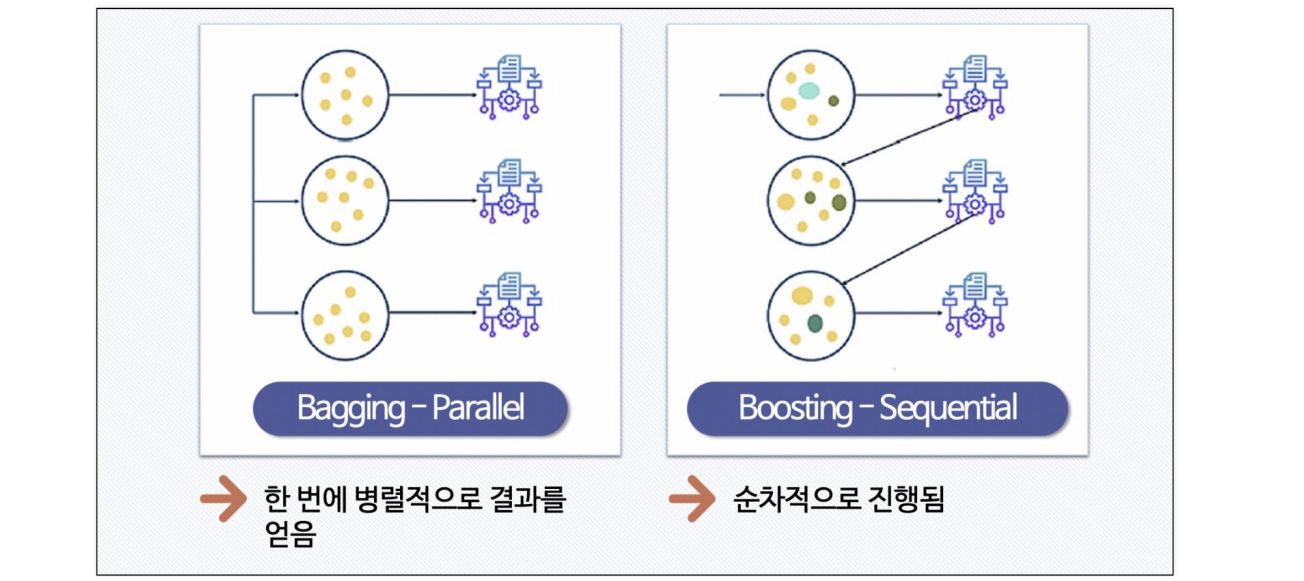
Bagging

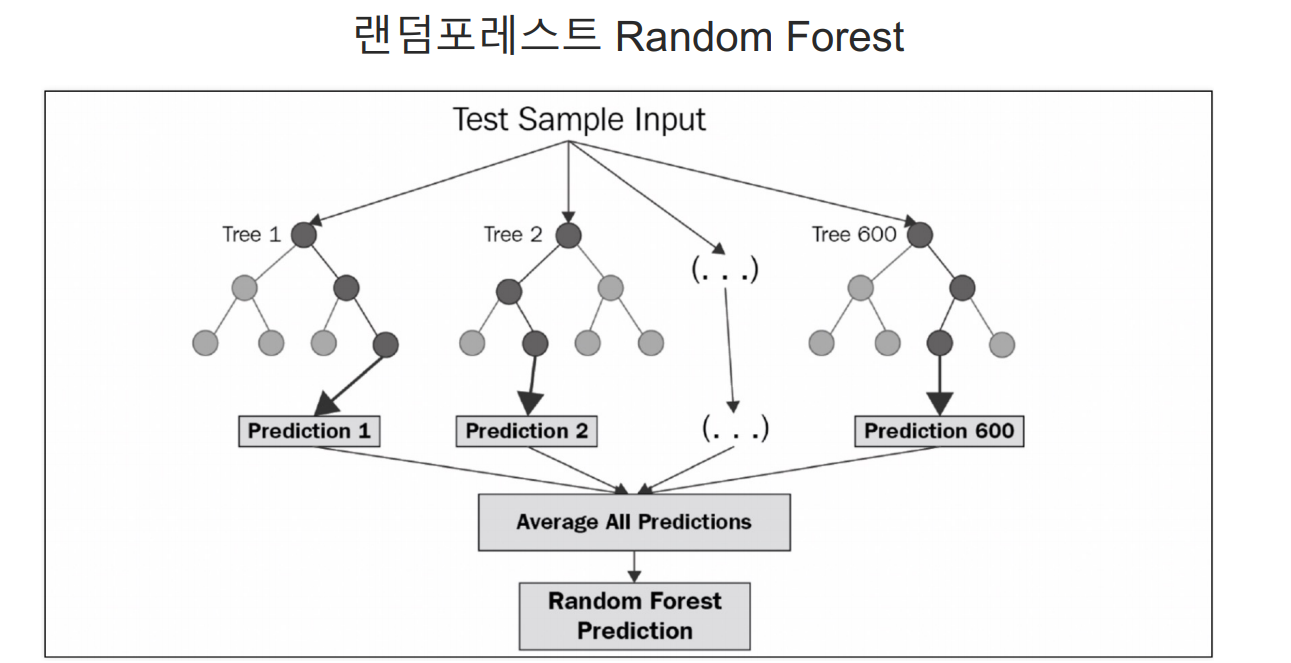
random forest

Bagging : RandomForestClassifier
여러 모델을 독립적으로 학습시키고 그 예측 결과를 평균하거나 다수결로 결합하는 방법
HAR : Human Activity Recognition
max_depth를 다양하게 하기 위해 GridSearchCV 이용
GridSearchCV
앙상블 모델의 성능을 최적화
하이퍼파라미터 튜닝을 자동화하고, 교차 검증을 통해 모델의 일반화 성능을 평가하는 데 유용한 도구
-
하이퍼파라미터: 모델 학습 전에 설정해야 하는 파라미터로, 모델의 구조나 학습 과정을 제어
예) 결정 트리의 최대 깊이, 랜덤 포레스트의 트리 개수, SVM의 커널 종류 등 -
교차 검증 (Cross-Validation): 데이터셋을 여러 개의 폴드로 나누어 모델을 여러 번 학습시키고 평가 => 모델의 일반화 성능을 평가할 수 있음
-
그리드 서치 (Grid Search): 하이퍼파라미터의 가능한 모든 조합을 체계적으로 탐색하여 최적의 조합을 찾는 방법
RandomForestClassifier
대표적 Bagging 방식
여러 개의 결정 트리(decision tree)를 사용하여 예측을 수행
분류 문제 - 다수결 투표 방식
회귀 문제 - 평균
트리마다 무작위로 서로 다른 데이터 샘플과 특징을 사용
=>모델의 다형성을 높이고 과적합(overfitting)을 줄이는 데 도움을 줌
각 결정 트리가 독립적으로 만들어지기 때문에 병렬 처리에 유리
=>학습 속도를 높이는 데 기여
이상치(outlier)와 노이즈에 덜 민감하여 강건한 성능을 발휘
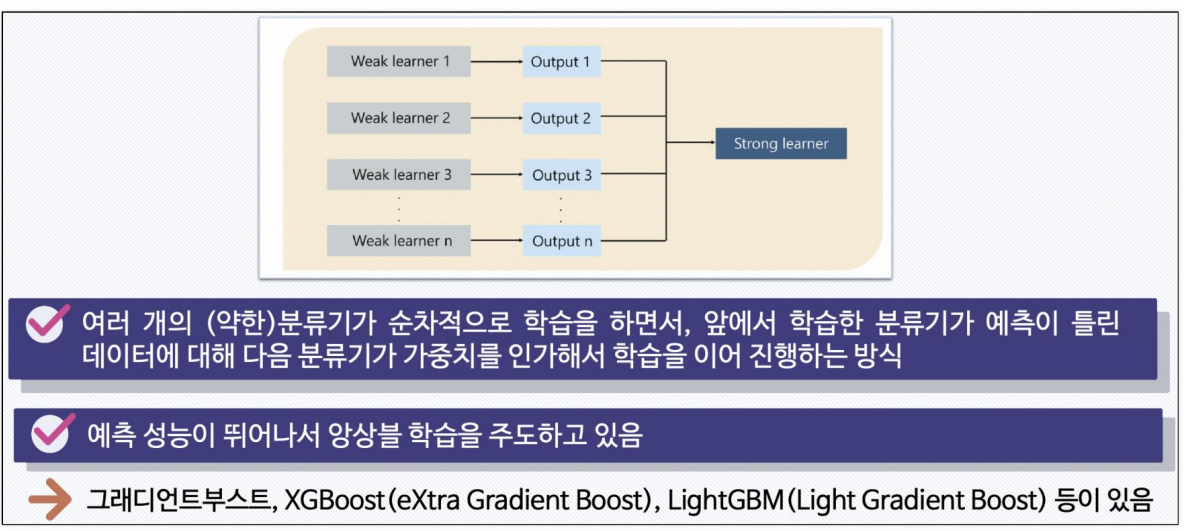
Boosting Alogrithm : GBM, XGBoost, LGBM

bagging과 boosting의 차이
GBM(Gradient Boosting Machine): 기본적인 Gradient Boosting 알고리즘,
여러 약한 모델을 결합하여 강력한 예측 모델을 만드는 앙상블 학습 기법,
각 모델은 이전 모델의 오류를 줄이도록 학습

XGBoost(Extreme Gradient Boosting): 여러 최적화 기법을 적용한 고성능 GBM의 구현체,
주요 특징으로는 정규화, 병렬 처리, tree pruning, sparsity awareness, weighted quantile sketch 등이 있음
GBM의 기본 원리를 따르지만, 여러 가지 성능 최적화 기법을 적용하여 더 높은 성능과 효율성을 제공

주요 파라미터:

LGBM(Light Gradient Boosting Machine): 학습 속도와 메모리 효율성을 극대화한 GBM의 구현체

KNN
k Nearest Neighber
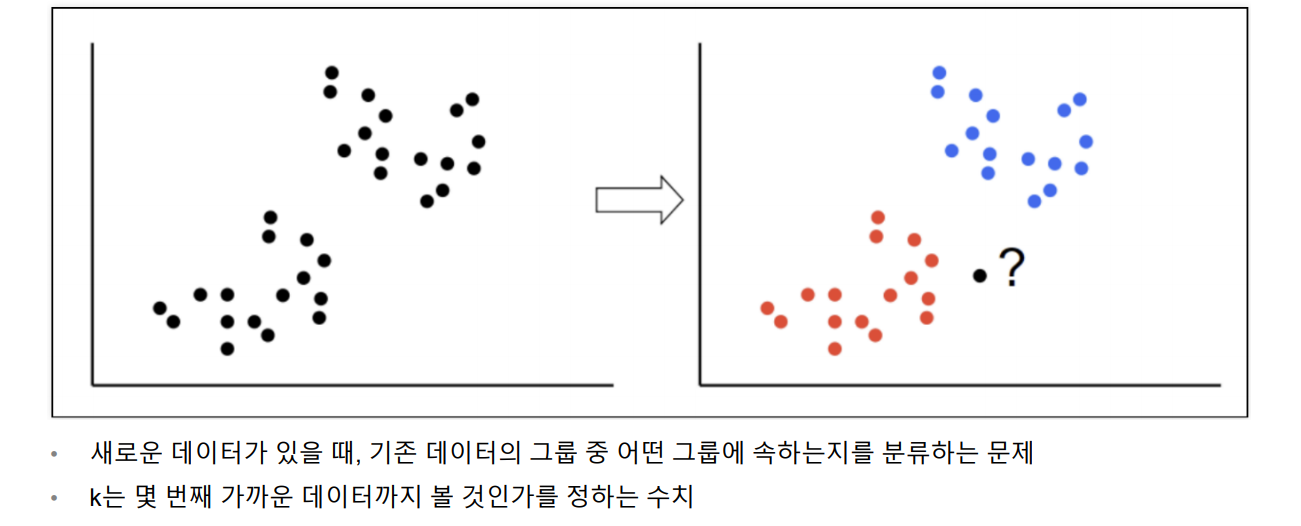
단위에 따라 바뀔 수도 있다 - 표준화 필요
장단점
• 실시간 예측을 위한 학습이 필요치 않다.
• 결국 속도가 빨라진다.
• 고차원 데이터에는 적합하지 않다.
Train 데이터: 모델을 학습시키는 데 사용되는 데이터셋입니다.
Test 데이터: 모델의 성능을 평가하는 데 사용되는 데이터셋
이 데이터셋은 모델이 학습하는 동안 볼 수 없으며, 오직 평가 목적으로만 사용
scaler를 제외하고는 원칙적으로 train데이터만 조작(test데이터는 왜곡 될 수 있음)
왜 Train 데이터만 조작해야 하는가?
-
과적합 방지:
모델이 test 데이터를 학습 과정에서 보게 되면, 모델은 해당 데이터에 대해 특화된 학습을 하게 되어 실제로 새로운 데이터를 예측하는 데 필요한 일반화 능력을 잃게 된다 => 과적합(overfitting) -
일관된 평가:
모델의 성능을 평가할 때, 평가 데이터(test 데이터)는 모델이 학습하지 않은 데이터여야만 합니다. 이렇게 해야 모델이 새로운 데이터를 얼마나 잘 예측할 수 있는지에 대한 객관적인 평가가 가능
