Vox-Fusion: Dense Tracking and Mapping with Voxel-based Neural Implicit Representation 리뷰
공유용으로 영어로 작성했는데 그대로 올림
논문 링크: https://arxiv.org/abs/2210.15858
이제 완전히 feature grid embedding + octree가 기본 구조로 자리잡은 듯 하다.
spatial한 구조가 나름 최적화 된 것 같으니 여러 센서와의 퓨전 (특히 라이다와의 찰떡궁합을 예상)으로 쭉쭉 영역을 넓혀 나갈거라고 예상했는데 아니나 다를까 블로그에 포스팅 하는 지금 벌써 NeRF-LOAM이라는 애가 선발로 치고 나왔다.. 미묘한 기분이 든다.
바로 NeRF-LOAM 리뷰를 연이어 해야겠다.
- dense tracking&mapping system
- fuses neural implicit representations with traditional volumetric fusion methods
- use mlp to encode and optimize the scene inside each voxel
- octree-based structure for dynamic expansion (it enables the model to work without knowing the environment like in previous works)
- traditional visual slam method → they are incapable of rendering novel views as they cannot hallucinate the unseen parts of the scene.
- previous SLAM work with NeRF focusing to encode and compress the scene in terms of memory usage → pre-trained networks used in these systems generalize poorly to different types of scenes, making them less useful in practical scenarios
similar to NICE-slam, difference is:
(1) dynamically allocate sparse voxels on the fly (improves usability, reduces memory consumption)
(2) all learned on-the-fly (no pre-trained)
(3) keyframe strategy suitable for sparse voxels
NeRF is not the best for surface reconstruction, which takes main place for AR tasks. We force the network to learn more details near the surface within a distance.
~~ explenations about the pros of explicit feature grid~~
encodes 3D scenes with neural networks and local embeddings just as Vox-Surf
SYSTEM
(0) initialize the global map by running a few mapping iterations for the first frame.
(1) under fixed network, estimate cam pose and send every frame with pose to mapper to construct global map
(2) The mapping process first takes the estimated camera poses and allocates new voxels and appropriately transformed 3D point cloud from the input depth map. Then it fuses the new voxel-based scene into the global map and applies the joint optimization.
(appropriately transformed 3D point cloud?)
(3) In order to reduce the complexity of optimization, we only maintain a small number of keyframes, which are selected by measuring the ratio of observed voxels. 음. 꽤 직관적이네.
(4) long-term map consistency is maintained by constantly optimizing a fixed window of keyframes.
voxel embeddings are attached to the vertices of each voxel and are shared by neighboring voxels → trilerp
efficient point sampling (inside voxel grid)-
- For each sampled pixel, we first check if it has hit any voxel along the visual ray by performing a fast ray-voxel intersection test. Pixels without any hit are masked out since they do not contribute to rendering
- enforce a limit M_h on how many voxels a single pixel is able to see
optimization
4 losses:
RGB loss, depth loss, free-space loss, SDF loss on the sampled points
- RGB/depth - MAE loss
- free-space/SDF loss - works with a truncation distance within which the surface is defined → similar to regularizer
tracking
- optim under lie algebra
- zero motion model
- simple back-propagation
- use pixel whose ray has intersection with existing voxel
mapping
Key-frame selection
Unlike previous works where key-frames are only inserted based on
- heuristically chosen metrics
- fixed interval
by an intersection test
This is risky for loopy camera motions → we also enforce a maximum interval between adjacent frames
Joint mapping and pose update
randomly select N keyframes(including the recently tracked frame), jointly optimize the scene network and feature embeddings
dynamic grid
dynamic Octree + morton
EXPERIMENT
datasets:
- all seq. of Replica dataset
- ScanNet
- custom (with iPhone)
metric:
(1) reconstruction quality
- accuracy, completion, completion ratio
(2) ATE RMSE
implementation detail:
- 0.2m voxel length
we use 0.07 length for room0 (reso=128)
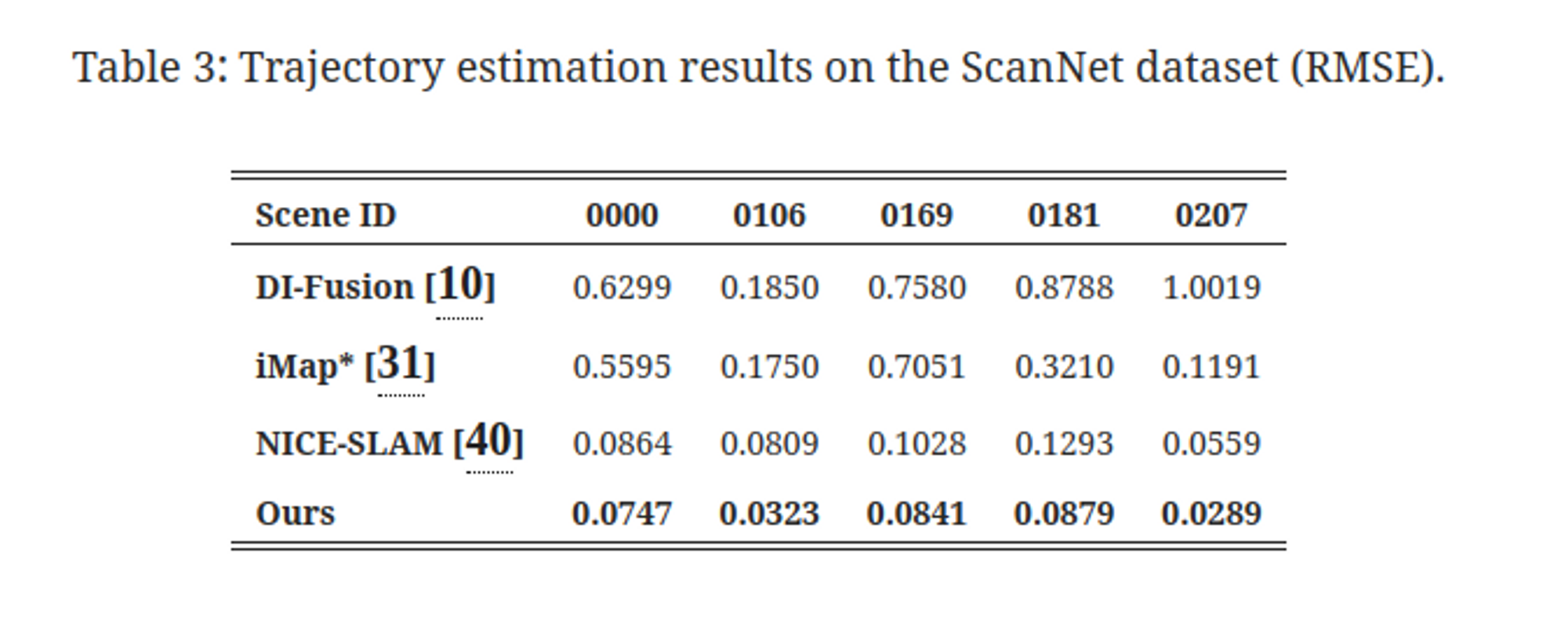
pose accuracy only on ScanNet.
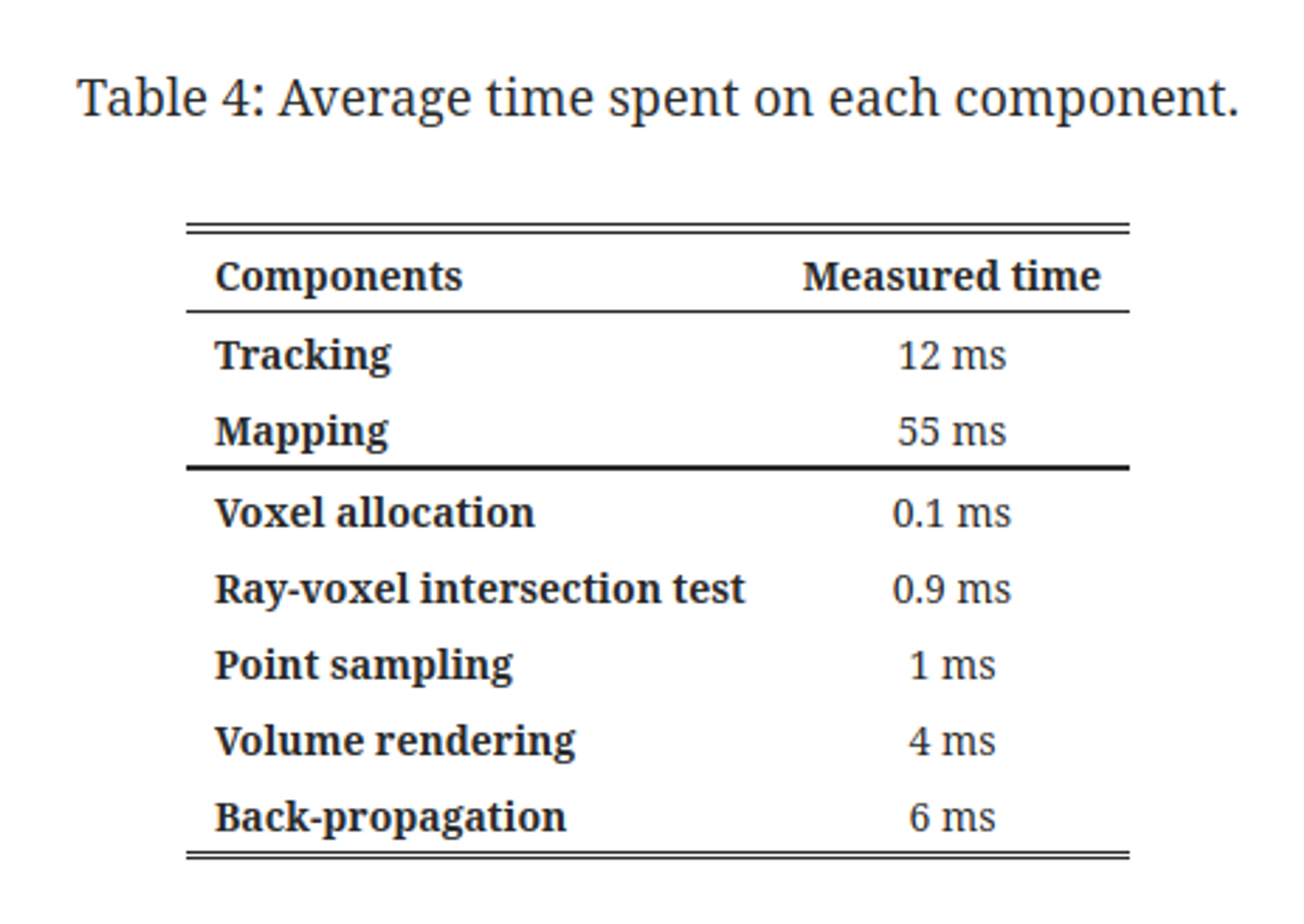
(single NVidia RTX 3090, on Replica set)
tracking and mapping are profiled on a per-iteration
Depending on the scene complexity, our method can take around 150-200ms to track a new frame and 450-550ms for the joint frame and map optimization.
5hz for tracking, 2hz for optimization → quite slow
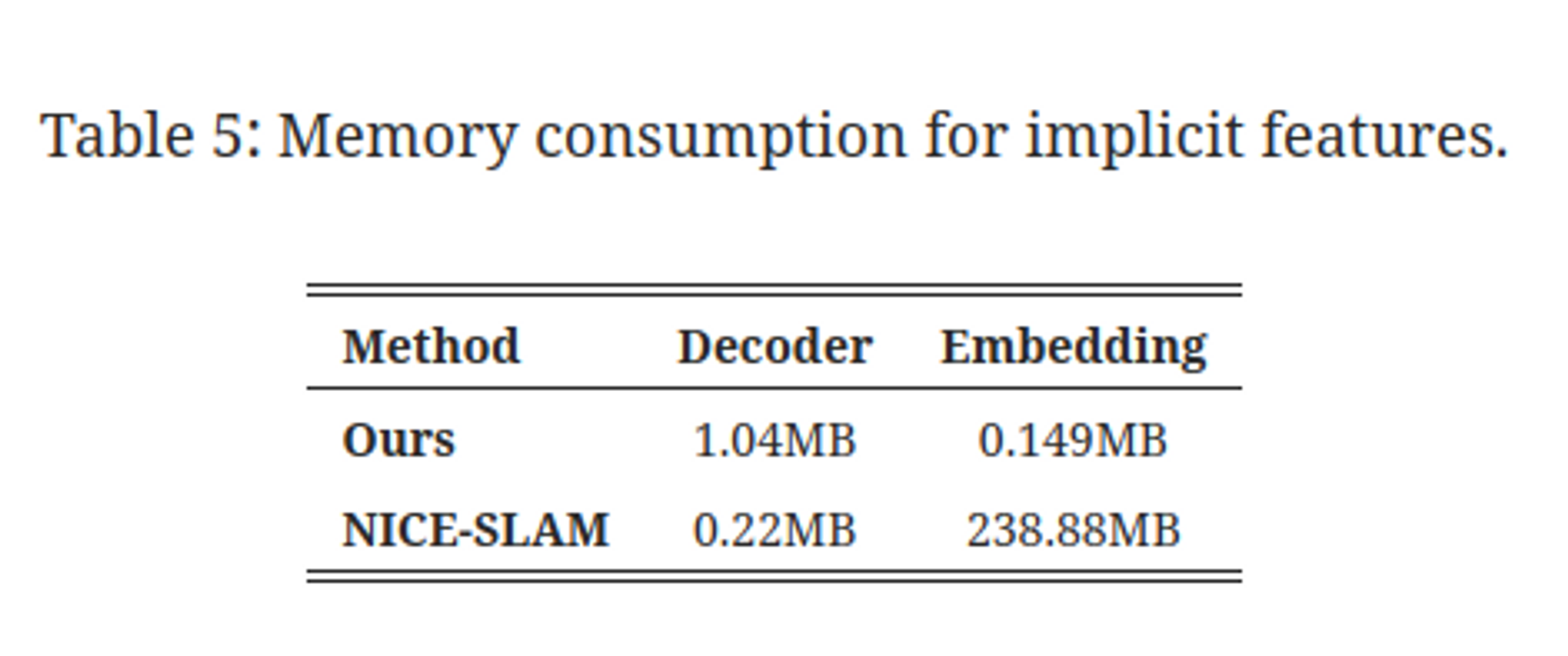
(on the Replica office-0 scene)
very small!!! (but I have to check for office0)
(for room0, 2.6MB under reso=64)
