1. 제네릭
우리는 자바를 여태까지 다루면서 가장 많이 다뤘던 것이 두 가지가 있는데, 바로 그건 변수와 클래스이다.
여태까지 우리가 배워온 바로는, 매개 변수 포함 자바 안에서 변수는 항상 하나만의 자료형을 가져야 하는데 (클래스 인스턴스 또한 마찬가지이다.) 만약, 클래스를 만들고 그 클래스에서 써야할 매개 변수가 자신이 아닌 다른 클래스의 인스턴스를 써야 하는데 상황에 따라 매개 변수로 올 인스턴스의 클래스가 어떤것이 올지 모르거나 혹은 매개 변수로 올 인스턴스의 클래스가 2개 이상이 필요하다고 가정하면 어떨까? 그런 경우에는 자바에서 어떻게 처리해야할까?
그런 상황을 위해 나온것이 제네릭이다. 예를 들면, 클래스 A와 클래스 B가 있고, 클래스 A는 숫자 "5"를 대표하는 클래스이고, 클래스 B는 문자 "오를 대표하는 클래스이며 이 클래스 A,클래스 B를 통해 "이 클래스가 가진 변수의 숫자는 5/오입니다."라는 결과를 얻고 싶어한다고 해보자.
위 내용을 코드로 구현한 것은 아래와 같다:
public class A {
int a = 5;
public void printA () {
System.out.println("이 클래스가 가진 변수의 숫자는 " + a + "입니다.");
}
public void main (String [] args) {
A aTest = new A();
aTest.printA();
} public class B {
String b = "오";
public void printB () {
System.out.println("이 클래스가 가진 변수의 숫자는 " + b + "입니다.");
}
public void main (String [] args) {
B bTest = new B();
aTest.printB();
}이 두 코드문을 해서 실행해보면 당연히 우리가 예상하는 결과가 바로 아래처럼 나올것이다:
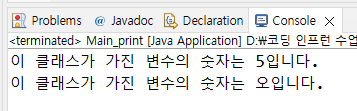
이 클래스가 가진 변수의 숫자는 5입니다.
이 클래스가 가진 변수의 숫자는 오입니다.
이처럼 제네릭을 모른다고 가정할때는 결과의 의미는 같지만 이렇게 단순히 자료형이 달라서(출력해야하는 결과값이 달라져서) 이렇게 클래스를 두 개로 나눠서 만들수밖에 없다 (이러면 해당 클래스와 인스턴스를 각각 두개씩, 메모리에 4개나 공간을 차지하게 한다.)
그런데 만약, 할당해야하는 인스턴스 메모리를 줄이면서 관리하기 쉽게 마지막에 통합해서 해당 클래스 둘 다 인스턴스로 받고 출력도 다 각각 하는, 그런 기능을 담당하는 통합 클래스를 따로 만든다면 어떻게 해야할까?
그렇게 통합해서 하고 싶다면 마지막 출력을 담당하는 통합 클래스에서 클래스 A, 클래스 B의 인스턴스를 매개변수로 받되, 메소드 안에서 해당 인스턴스의 자료형을 Object 클래스(모든 클래스의 최상위 클래스, 기본 클래스에 속하며 모든 클래스의 부모 클래스이기에 어떤 클래스로든 형 변환이 가능하다. 이 부분은 나중에 후술하겠다.)로 형 변환하여 반환하는 방법이 있긴 하다.
그렇게 해서 결국 마지막에 출력하고 싶어하는 결과에 따라 메소드 호출 후 리턴하고 나온 Object 클래스 인스턴스를 출력하고 싶어하는 클래스 자료형으로 명시적 형 변환을 치뤄야 한다는 수고가 든다. 바로 아래처럼 말이다:
class A5 { //a는 "5"를 가진 A5 클래스
int a = 5;
public void printA5 () {
System.out.println("이 클래스가 가진 변수의 숫자는 " + a + "입니다.");
}
}
class B5 { //a는 "오"를 가진 B5 클래스
String b = "오";
public void printB5 () {
System.out.println("이 클래스가 가진 변수의 숫자는 " + b + "입니다.");
}
}
public class Main_print {
Object ins_AB;
public void setAB (Object ins_AB) {
this.ins_AB = ins_AB;
}
public Object getAB () {
return ins_AB;
}
public static void main (String [] args) {
Main_print m1 = new Main_print();
A5 a1 = new A5(); //A5 인스턴스 생성
m1.setAB(a1); //a1이 A5 클래스 이지만 Object가 모든 클래스의 상위 클래스이기에 오류 안나고 자동 형 변환
A5 a2 = (A5) m1.getAB(); //getAB하고 나온 자료형이 상위 클래스 Object이기에 ()으로 강제 형 변환
a2.printA5(); //원하는 결과를 보여주는 A5의 메소드 호출
B5 b1 = new B5(); //B5 인스턴스 생성
m1.setAB(b1); //b1이 B5 클래스 이지만 Object가 모든 클래스의 상위 클래스이기에 오류 안나고 자동 형 변환
B5 b2 = (B5) m1.getAB(); //getAB하고 나온 자료형이 상위 클래스 Object이기에 ()으로 강제 형 변환
b2.printB5(); //원하는 결과를 보여주는 B5의 메소드 호출
}
}
그래서, 이렇게 마지막에 통합해서 하고 싶어하는 경우 그리고 메소드 호출 후 마지막 원하는 출력값을 각각 얻기 위해 Object 클래스를 명시적 형 변환으로 하는 코드를 넣어야 하는 번거로움을 피하고 싶다고 한다면 평소에는 자료형이 정해져 있지 않다가 어떤 클래스의 인스턴스가 자료형으로 배치될때 확실히 자료형이 정해지는 그런 기능을 가진 자료형 타입이 필요하다.
그런 필요에 의해 자바는 그런 자료형 타입, 제네릭이라는 기능을 두었고 이 기능은 클래스 선언부에서 클래스명 다음에 보통 < T >로 쓴다. (자료형 매개변수 type parameter라고 한다 그리고 제네릭이 들어가는 자료형은 String 포함 클래스형 이상만 가능하다, String 제외 기본 자료형은 안된다. 제네릭 자료형을 쓰는 클래스를 제네릭 클래스, 그리고 제네릭 클래스에서 제네릭 자료형 T를 매개변수로 사용한 메서드를 제네릭 메서드라고 한다.)
위의 사례를 제네릭 < T >로 고친다고 한다면 아래와 같다:
class A_int { //a는 "5"를 가진 int 클래스
@Override
public String toString() {
return "이 클래스가 가진 변수의 숫자는 5입니다.";
}
}
class A_String { //a는 "오"를 가진 String 클래스
@Override
public String toString() {
return "이 클래스가 가진 변수의 숫자는 오입니다.";
}
}
public class Generic_A <T>{ //<T>로 class A_int, class A_String을 자료형으로 둘 다 받을수 있게끔 함
T ins_A; //아래 메서드에서 쓰기 위해 인스턴스 미리 생성, 멤버 변수 선언
public void setA (T ins_A) { //set 메서드로 매개 변수로 받은 클래스 인스턴스를 멤버 변수 자료형 T 인 ins_A에 세팅
this.ins_A = ins_A;
}
public T getA () { //get 메서드로 해당 클래스 자료형 인스턴스도 반환 가능
return ins_A;
}
@Override //toString() 오버라이드로 바로 해당 클래스 인스턴스의 toString() 메서드 String으로 반환
public String toString() {
return ins_A.toString();
}
이제 위의 코드문을 통해 메인 메소드에서 인스턴스를 만들고 메서드를 실행해서 결과를 보자:
//main 메서드만 발췌
public static void main (String[] args) {
//제네릭 클래스 생성
Generic_A <A_int> ai = new Generic_A <A_int>();
Generic_A <A_String> as = new Generic_A <>();
//set 메서드에 해당 자료형 클래스 인스턴스를 매개변수로 줌
ai.setA(new A_int());
as.setA(new A_String());
//아래처럼 get 메서드로 자료형으로 썼던 해당 클래스의 인스턴스로 반환도 가능
A_int ai_re = ai.getA();
A_String as_re = as.getA();
//그대로 콘솔 출력하면 미리 세팅한 toString이 자동으로 반환
System.out.println(ai_re);
System.out.println(as_re);
System.out.println(ai);
System.out.println(as);
}
이렇게 클래스 하나만으로 여러 클래스형 자료형을 받고 반환할수 있게 만드는게 제네릭 < T >이며, 이를 이용하면 굳이 Object 클래스로 자동 형 변환하고 또 명시적 형 변환을 하는 수정 코드 입력을 줄일수 있을 뿐더러 인스턴스 메모리도 아끼는 그런 결과를 얻을수 있다. 또한, 잘만 설정하면 클래스 2개 뿐만이 아니라 그 이상 여러개의 클래스를 한꺼번에 자료형으로 받고 처리하는 통합 클래스도 만들수 있는것이다.
이처럼 이 이 제네릭은 컬렉션 프레임워크라는, 자바에서 미리 지정한 자료구조에서 사용된다.
예를 들면, 바로 아래처럼 우리가 앞서 상속 부분에서 살짝 맛보았던 ArrayList는 자바의 대표적 컬렉션 프레임워크로서 이 제네릭을 자료형으로 쓴다:
ArrayList<String>list = new ArrayList<>();(여기서 <>를 다이아몬드 연산자라고 한다. 왼쪽 항에서 < String >을 쓰고 오른쪽 항에서 <>을 한것은 이미 왼쪽에서 String이라고 자료형이 선언되었기 때문이다. 보통 ArrayList는 제네릭 자료형으로 < E >를 쓴다. )
그리고 여기서 유의해야할 점은 인스턴스 생성과 상관없이, 프로그램 실행만으로 메모리에 로드되어 사용가능한 static 변수는 제네릭 변수로 사용할수 없다. (왜냐하면 제네릭의 자료형이 정해지는 순간은 제네릭을 담은 제네릭 클래스의 인스턴스가 형성된 시점이기 때문이다)
또한, 제네릭은 문자 < T >만 쓸수 있는게 아니라 < E >(Element), < K > (Key), < V >(value)와 같이 자료형이 어떤 타입이냐에 따라 문자를 달리 쓸수 있다.
(꼭 위에서 언급한 문자가 아니어도 임의로 어떤 문자든 사용이 가능하다. 다만, 개발자 사이에서 관습적으로 딱 봐도 의미를 알수 있는것이 바로 저런 문자들이기에 주로 저런 문자들이 주로 쓰인다.)
또, 우리가 앞서 배운 상속 extends로 나중에 제네릭으로 올 클래스 자료형을 제한할수도 있다.
(예를 들면, 위의 사례에서 추상 클래스 A_intString을 만들고 toString()을 추상 메서드로 둔 다음 클래스 A_int와 클래스 A_String가 둘 다 A_intString 추상 클래스를 상속 받아 toString() 메서드를 구체화 한뒤
마지막 Generic_A 선언부에서 그냥 < T > 대신 < T extends A_intString>을 같이 입력하면 된다. 이러면 자료형으로는 A_int와 A_String밖에 오지 못한다. 인터페이스도 마찬가지이다. 또한 이렇게 상속으로 미리 선언하면 해당 상속을 한 상위 클래스의 변수나 메서드를 꺼내올수도 있다.)
2. 컬렉션 프레임워크
우리가 앞서 살짝 맛 본 ArrayList에서 느꼈겠지만, ArrayList 같은 컬렉션 프레임 워크는 자바가 기본 제공하는 자료 구조이자 자바에서 데이터(자료)를 어떻게 저장하고 처리할지 (구조) 결정하는 도구, 라이브러리라고 보면 된다.
이런 컬렉션 프레임워크들은 인터페이스의 Iterator(반복자)를 상속받은 여러 인터페이스들이며, 크게는 Collection과 Map으로 나뉘어져 있다. 보통 Collection은 하나의 자료 유형을 한데 모아서 관리하는 유형이고 Map은 쌍, pair, 정확히는 키(key)와 밸류(value)로 이뤄진 자료 유형을 관리하는 유형이다.
Collection 유형
먼저 Collection 유형부터 보자면, 또 List와 Set으로 나뉘어진다. List는 순차적인 자료를 관리하는데 쓰이면서 중복을 허용하는 인터페이스이고, Set은 순서는 상관없지만 중복을 허용하지 않는 인터페이스이다.
List 인터페이스를 구체적으로 구현한 클래스에는 우리가 이미 본 ArrayList, Stack, Queue, Vector, LinkedList등이 있으며, Set 인터페이스에는 HashSet, TreeSet이 있다.
일단 Collection 인터페이스에 속한 클래스들은 아래와 같은 메소드들이 기본 제공되어 주로 쓰여진다:
boolean add(E e) : Collection에 객체를 추가한다. (E는 Element, 요소를 뜻한다)
void clear() : Collection 안에 있는 모든 객체를 제거한다.
Iterator< E > iterator : Collection을 순환할 반복자(iterator)를 반환한다.
boolean remove(Object o) : Collection에 매개변수에 해당하는 인스턴스가 존재하면 제거한다.
int size() : Collection에 있는 요소의 개수를 반환한다
(add나 remove로 반환되는건 boolean으로 되어있는데 왜냐하면, 컬렉션 프레임워크 안에 객체가 잘 들어갔는지 / 잘 제거됐는지 여부를 반환하는것이다.)
이렇게 컬렉션 프레임워크에서 공통적으로 쓰는 메소드들을 보았고 먼저 순서가 있는 List 인터페이스에 들어가기전에 잠깐 컬렉션 프레임워크에서 반복적으로 나오는, 반복자 (Iterator)에 대해서 자세히 들여다보자.
이 Iterator 클래스는 순서가 없는 인터페이스, 즉 Set 인터페이스에 주로 쓰이는데 왜냐하면 List 인터페이스의 경우 순서가 있는 배열로 구성되어 있기에 for문과 인덱스 번호를 이용해 배열 안 요소들을 꺼내면 되지만, Set 인터페이스의 경우 순서가 없기에 인덱스 번호가 없어서 for문을 사용할수 없다.
그렇기에 나온것이 이 Iterator고, Collection 인터페이스를 구현한 객체라면 어떤것이든 iterator() 메소드를 호출하는 방식으로 해당 객체의 Iterator 클래스 객체를 반환받을수 있다. 그래서 이 Iterator 클래스 객체를 가지고 아래 메소드와 함께 Set 인터페이스 기반인 객체의 요소들을 하나 하나씩 끌고올수 있다:
boolean hasNext() : 이후에 요소가 더 있는지 체크하는 메소드이며, 요소가 있다면 true를 반환한다. (더 이상 끌고 올 요소가 없다면 false를 반환, 보통 while문과 함께 쓴다)
E next() : 다음에 있는 요소를 반환한다 (요소를 가리키는 커서라는것이 있는데, next() 메소드는 항상 해당 차례의 요소를 반환하면 그 커서를 움직여서 항상 다음 요소를 미리 가리키고 있다.)
Iterator 예시는 아래 코드문과 같다:
//ArrayList, <String>, 요소 모두 콘솔 출력의 경우
Iterator<String> ir = ArrayList.iterator();
while(ir.hasNext()){
String str = ir.next();
System.out.println(str);
}1) List 인터페이스
앞서 말했다시피, List 인터페이스에는 순차적인 자료들을 관리하고 중복을 허용하는 인터페이스이며 대표적인 구현 클래스로는 ArrayList, Vector등이 있다.
먼저 대표적으로 잘 쓰이면서 우리에게 그나마 친숙한 ArrayList 클래스부터 보겠다.
(실제로 실습했던, 아래 예시 코드문을 한번 보자:)
import java.util.*;
public class CollEx01
{
public static void main(String[] args)
{
// 리스트 생성
ArrayList<String> arrList = new ArrayList<String>();
// 리스트에 요소의 저장 add 메소드
arrList.add("넷"); //0
arrList.add("둘"); //1
arrList.add("셋"); //2
arrList.add("하나"); //3
//arrList.size() ArrayList 객체 배열의 길이 반환
// 리스트 요소의 출력, 향상된 for문
for (String s : arrList)
{
System.out.println(s);
}
List<String> lst = new ArrayList<String>(); //new ArrayList<>(); 가능
//List 인터페이스형을 상속받은 ArrayList 클래스 객체 생성 lst
lst.add("alpha");
lst.add("beta");
lst.add("charlie");
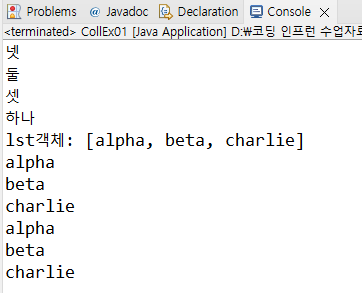
System.out.println("lst객체: " + lst); //List 객체 + 출력문 = 배열 대괄호 + 배열 자체 값 각각 출력
Iterator<String> iter = lst.iterator(); //컬렉션 객체의 요소 요소를 하나 하나씩 떼서 객체 iter에 저장 (.iterator 메소드 사용)
while (iter.hasNext()) //iterator형 iter 객체의 다음 요소 값이 존재하면 true값 반환, 없으면 false값 반환
{
String str = iter.next(); //next 메소드는 항상 iter의 다음값을 반환 => 요소를 가리키는 커서는 next 메소드가 해당 객체 요소값을 반환하고 그 요소값 바로 직후 뒤로 움직임
System.out.println(str);
}
for (String str : lst)
{
System.out.println(str);
}
}
}
위의 코드문은 크게 4가지 구조로 볼수 있다:
첫번째, 컬렉션 프레임워크를 쓰기 위해선 클래스 선언문 이전에 어떤 컬렉션 프레임워크를 쓸건지 최상단에서 임포트문을 사용하여 해당 컬렉션 프레임워크를 끌어와야한다. (위의 사례에선 편의를 위해 자바의 유틸 기본 패키지 전부를 끌어오는 import java.util.*;을 사용했지만 원래는 ArrayList만을 쓰기 때문에 import java.util.ArrayList;를 선언해야한다.)
두번째, ArrayList<제네릭 자료형> 객체명 = new ArrayList<>(); 혹은 new ArrayList<제네릭 자료형>();으로 ArrayList에 해당하는 객체를 만든다.
세번째, 빈 ArrayList 객체에 .add() 메소드로 요소들을 채워넣는다. (상황에 따라 .clear(), .remove(), .size() 메소드를 쓰기도 한다)
네번째,향상된 for문이나 혹은 .iterator() 메소드로 Iterator 인터페이스(모든 컬렉션 프레임워크의 최상위 클래스) 객체를 만들어 이것을 while문 + .hasNext()메소드로 반복 돌리는 방식으로 ArrayList가 가진 객체 하나 하나를 끌어낸다.
(또한 for문과 합쳐서 get 메소드를 같이 써서 객체 하나 하나를 끌어낼수 있다. 단, get 메서드는 순서가 있는 배열에서만 사용하는 메서드이며, 반환형은 add, remove 메서드처럼 boolean이다. 이처럼 ArrayList안에 있는 객체들을 하나 하나 끌어내는 방법은 여러가지가 있다.)
Vector도 ArrayList와 동일하게 배열을 구현한 클래스이지만 차이가 있는데 Vector는 동기화(synchronization)를 지원한다는것이다.
이 부분은 후술하겠지만, 간단히 말하자면 우리가 클래스나 클래스들 혹은 인터페이스 등 객체들을 구현하고 그것을 main 메소드 하나에서 돌린다고 했을때, 이때 이 메인 메소드, 프로그램을 실행하는 공간이자 주체가 바로 스레드(thread)이고 이것을 다중으로 하면 멀티 스레드(multi-thread)가 되며 멀티 스레드의 경우 같은 메모리를 동시에 쓰기 때문에 오류가 발생할수 있다, 이 상황에서 각각의 스레드가 같은 메모리를 서로 동시에 사용하지 않게 하고 순서를 맞추는것이 동기화이다.
그래서 이런 동기화의 경우 한 스레드가 작업중이면 해당 메모리는 다른 스레드가 접근하지 못하도록 Lock을 걸기에 Vector는 동기화를 지원하지만 ArrayList보다 작업시간이 더 걸린다는 단점이 있다. 그렇기에 웬만하면 동기화를 신경쓰지 않아도 된다면 ArrayList를 쓰는 편이 좋다.
다음은 LinkedList이다.
배열의 가장 큰 단점은 기존 배열에서 새로운 요소를 추가할때마다 크기가 더 큰 배열 공간을 새로 생성해서 거기다가 기존 배열 요소들을 복사해 옮겨 넣어야 하는 작업이 필요하다는것이다.
이런 단점을 해결한게 바로 LinkedList로, LinkedList는 각각의 요소가 그 공간에 저장되는 자료 데이터와 서로 다음에 올 요소들을 가리키고 있는 주소를 포함하고 있어 내부에 요소를 추가하거나 삭제하는데 있어서 기존 배열보다 처리 시간을 아낄수 있다.
(추가의 경우, 단순히 추가될 요소의 공간 이전 인덱스 번호를 가진 요소를 찾고 그 요소가 가진, 다음에 올 요소를 가리키는 주소를 추가될 요소의 주소로 바꾸면 되고,
삭제의 경우, 삭제될 요소를 가리키는 그 이전 요소가 가진 다음 요소 주소를 변경하면 그만이다. 그렇게 주소 연결이 끊어진, 삭제되는 요소는 가비지 콜렉터에 의해 알아서 삭제 처리가 된다.)
그렇다고 무조건 LinkedList가 좋은것은 아니다, 배열 안 어떤 특정 인덱스 번호에 해당하는 데이터를 찾아야할때 그냥 일반 배열은 물리적으로 연결되어 있기 때문에 인덱스 번호로 바로 찾을수 있다. 즉, 자료 변동이 많은 경우에는 LinkedList를, 자료 변동이 거의 없는 경우에는 그냥 일반 배열을 쓰는것이 좋다.
(그리고 LinkedList부터는 앞서 ArrayList에서 본 .add()메소드와 .remove()메소드 이외에 .addFirst(), .addLast(), .removeFirst(), .removeLast() 메서드를 추가적으로 제공한다.)
이번에 설명할 List 인터페이스에 속한 컬렉션 프레임워크는 Stack이다.
스택은 어떤 물건을 차례 차례로 아래에서 위로 쌓아서 생긴 구조라고 보면 된다. 그래서, 스택 구조에서 제일 마지막이 아닌, 중간이나 처음에 있는 어떤 특정 요소를 바로 꺼내거나 접근할수가 없다.
그렇기에, 맨 마지막에 쌓은 요소를 먼저 꺼낼수 밖에 없고 그렇게 밖에 할수가 없다. (마지막에 들어온것이 맨 처음 꺼내야 한다 => Last In First Out => LIFO, 후입선출법)
stack을 구현하는 방법은 많은데, 일단 ArrayList로 구현한 코드문은 아래와 같다:
package collectionFramework_prac;
import java.util.ArrayList;
class StackClass {
ArrayList<String> StackList = new ArrayList<>();
public void push(String data) {
StackList.add(data);
}
//스택 맨 뒤에 요소 추가
public String pop() {
int size = StackList.size();
//size() => 스택의 사이즈 크기 반환
if(size == 0) {
System.out.println("스택이 비었습니다.");
return null;
}
return (StackList.remove(size-1));
//remove 메소드는 해당 인덱스 번호에 있는 데이터 요소를 배열에서 제거한 뒤 그 요소 자체를 반환함
}
}
public class StackArrayListExample
{
public static void main(String[] args)
{
StackClass ex1 = new StackClass();
ex1.push("A");
ex1.push("B");
ex1.push("C");
System.out.println(ex1.pop());
System.out.println(ex1.pop());
System.out.println(ex1.pop());
}
}
아래에서 위로 쌓는 push 메소드를 구현하고 (add() 메서드 이용) 가장 마지막에 추가되었고 맨 위에 쌓여진 요소를 꺼내는 pop 메소드를 따로 구현했다. (remove() 메소드 + size-1 맨 마지막 가리키는 인덱스 값)
그렇게 해서 위 결과처럼 가장 마지막에 넣은 C, B, A 순서대로 콘솔에 출력되었다.
(그리고 우리가 앞서 배웠던 자바의 메모리 영역 중 Stack 메모리 (함수와 지역변수 공간) 또한 이 Stack 구조를 표방하고 있다
=> 만약, 함수와 지역변수들이 서로 중첩이 되어있다고 할때, 가장 바깥쪽에 있는 함수가 먼저 호출이 되고 그 내부에 있는 함수들이나 지역 변수들이 호출되는 순서는 가장 바깥쪽에 위치한 대로 호출되면서 서로 연산 처리를 거친다. 이 처리가 최종적으로 다 끝나서 리턴값이 있으면 리턴값을 받을때까지, 아니면 더 이상 연산 처리할 함수나 변수가 없을때까지 가장 바깥 함수는 계속해서 메모리를 점유한다.)
이 다음은 Queue이다.
ArrayList나 Stack처럼 요소 추가는 맨 마지막에 되지만 (enqueue) 요소 삭제는 맨 처음에 들어갔던 요소가 먼저 삭제된다. (dequeue)
큐도 Stack처럼 보통 ArrayList나 LinkedList로 구현이 가능하며 구현 방식은 위의 Stack 코드문과 거의 비슷하지만 추가 메소드는 enQueue()로, 삭제 메소드는 deQueue로 하되 삭제 메소드에선 return 배열명.remove(0)으로 바꿔야 한다.
2) Set 인터페이스
앞서 말했다싶이 순서가 없지만 중복을 허용하지 않는것이 Set 인터페이스라고 했다. 그럼 일상 생활의 경우에 어떤 것들이 Set 인터페이스에 속할까? 학교에 입학하면 학번, 회사에 입사하면 사번이 주어지는데 이런 학번과 사번의 경우 중복을 허용하지 않고 반,부서마다 사람이 달리 배치되기에 순서가 연속적이지 않다. 이런 경우에 Set 인터페이스를 통해 자료를 묶어 자바에서 관리할수 있는것이다.
Set 인터페이스에는 HashSet, TreeSet 클래스가 있는데 먼저 HashSet부터 아래 코드문으로 보자:
import java.util.Hashset;
import java.util.Iterator;
public class HashSetExample1
{
public static void main(String[] args)
{
Set <String> set = new HashSet<String>();
set.add("Java");
set.add("JDBC");
set.add("Servlet/JSP");
set.add("Java"); //중복 체크 & 덮어쓰기
set.add("iBATIS");
int size = set.size(); //set 요소 갯수 4개
System.out.println("총 객체수: " + size);
Iterator<String> iterator = set.iterator();
while(iterator.hasNext()) {
String element = iterator.next();
System.out.println("\t" + element);
}
set.remove("JDBC");
set.remove("iBATIS");
System.out.println("총 객체수: " + set.size());
for(String element : set) {
System.out.println("\t" + element);
}
set.clear(); //값 & 공간 전부 삭제 비워냄 (List에서도 사용 가능)
if(set.isEmpty()) { System.out.println("비어 있음"); } //isEmpty 객체 값 공간 있는지 확인 true/false 반환
System.out.println(set.size());
}
}
일단 Hashset 클래스의 < String > 자료형으로 새 객체를 만들고 그걸 Set 인터페이스의 set 객체에 담았다. 그리고 .add() 메소드로 Java, JDBC, Servlet/JSP, java, iBATIS순으로 set 객체안에 요소들을 넣었는데 분명 Java를 맨 앞에도 한번, 4번째에도 한번 넣었는데 나중에 콘솔로 출력해보니 중복으로 반영되지 않았다.
이처럼, Set 인터페이스 기반인 컬렉션 프레임워크 클래스 객체는 중복값을 허용하지 않는다는것을 알 수 있다.
(사실 정확히는 중복을 허용하지 않는게 아니라 중복값이 들어오면 그 중복값을 기존 값에 새로 덮어씌우는것이다. 어쨋든 결과적으로는 중복을 허용하지 않는것이 맞다.)
그리고 객체 안 요소 하나 하나씩 끌어오는건 Iterator(iterator(), hasNext(), next()) 인터페이스를 이용하는 수밖에 없고 (List 인터페이스 기반인 클래스 객체들은 for문과 Iterator 둘다 사용 가능) 또한 요소 값과 공간 전부를 삭제하는 clear 메소드 또한 사용했다.
그런데 만약, Set 인터페이스 안에서 자료를 추가할때 제네릭 자료형이 String처럼 미리 기본으로 있는 클래스가 아닌, 개발자가 따로 선언한 클래스이고 이 클래스 안에 멤버 변수가 여러개라면 어떻게 될까? 만약 멤버 변수인 아이디와 이름을 가지고 자료가 중복인지 아닌지 비교해야할때 아이디가 중복이면 중복처리를 하고 싶을땐 어떻게 해야할까?
일단, Set 인터페이스의 제네릭 자료형이 될 클래스, Member 클래스를 먼저 아래와 같이 만들고 Set 인터페이스를 구현하고 안의 요소가 될 자료를 추가해보자:
public class Member {
public int memberId;
public String name;
public int age;
public Member(int memberId, String name, int age) {
this.memberId = memberId;
this.name = name;
this.age = age;
}
@Override
public String toString() {
return (memberId + "/" + name + "/" + age);
}
}import java.util.*;
public class HashSetExample2
{
public static void main(String[] args)
{
Set<Member> set = new HashSet<Member>();
set.add(new Member(1001,"홍길동", 30));
set.add(new Member(1001,"홍길동", 30));
set.add(new Member(1003,"고길동", 45));
System.out.println(set);
System.out.println("총 객체수 : " + set.size());
}
}
이처럼 제네릭 자료형에 해당하는 클래스에 단순히 멤버 변수와 생성자만 해두고 Set 인터페이스를 구현할 경우 중복을 가려낼때 클래스 안 멤버 변수 값 자체를 비교하는게 아니라 add 메소드로 자료를 넣을때 생기는 인스턴스의 주소만을 비교해서 위처럼 안의 값이 같아도 서로 다른 인스턴스로 새로 생성되어 들어갔으면 값 자체가 중복이어도 중복으로 걸러내지 못하는 문제가 생긴다.
(아까 처음 봤던 예시는 지금 처럼 멤버 변수가 많은 사용자 정의 클래스가 아닌 String만을 제네릭 자료형으로 썼고 String 클래스는 자체적으로 중복값을 걸러내는 로직이 따로 기본 내장되어 있기때문에 따로 소스코드를 붙여주지 않아도 중복값을 걸러내는것이 가능했었다.)
그래서 Member 클래스 안에 어떻게 중복을 처리할지 정하는 로직이 담긴 소스코드가 필요한데 아이디가 같으면 중복으로 처리하도록 하려면 아래와 같이 해주면 된다:
public class Member {
public int memberId;
public String name;
public int age;
public Member(int memberId, String name, int age) {
this.memberId = memberId;
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object obj) { //Object 최상위 클래스 equals 메소드 오버라이드 재정의
if(obj instanceof Member) {
Member member = (Member) obj;
if(this.memberId == member.memberId) //아이디가 같으면 true 반환
return true;
else
return false;
} else {
return false;
}
}
@Override
public int hashCode() { //객체 주소를 반환하는 hashCode() 메소드 오버라이드 재정의
return memberId; //아이디를 반환
}
@Override
public String toString() {
return (memberId + "/" + name + "/" + age);
}
}public class HashSetExample2
{
public static void main(String[] args)
{
Set<Member> set = new HashSet<Member>();
set.add(new Member(1001,"홍길동", 30));
set.add(new Member(1001,"홍길동", 40));
set.add(new Member(1003,"고길동", 45));
System.out.println(set);
System.out.println("총 객체수 : " + set.size());
}
}
아이디가 같으면 중복이라고 인식하도록 해야하므로 중복인지 아닌지 판단하는, 최상위 클래스 Object에 있던 메소드 둘(객체 주소를 반환하는 hashCode(), 두 객체가 동일한지 아닌지 판단하는 equals() 메소드)을 위처럼 오버라이드 재정의하여 hashCode()는 아이디를 반환하도록 하고 equals는 주어진 매개 변수인 객체를 Member 클래스로 강제 형 변환한뒤 미리 있던 객체의 아이디와 주어진 매개 변수 객체의 아이디를 서로 비교해 같으면 true 반환, 아니면 false를 반환하도록 했다.
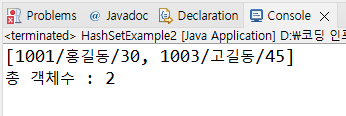
그리고 나서 아이디가 둘 다 1001이고 이름이 홍길동이며 나이만 30과 40으로 다른 Member 객체를 add 메소드로 Set 인터페이스에 추가하고 요소를 콘솔에 출력하면
위와 같이 아이디가 같은 홍길동 객체는 하나만 들어갔음을 알 수 있다.
이처럼, 기본적으로 값 하나만 다루고 중복 처리가 미리 기술된 String이나 후술하게 될 int형 기본 클래스 < Integer > 클래스와 달리 개발자가 따로 정의한 클래스의 경우 위처럼 클래스 안에서 중복을 구분하는 equals, hashCode 메소드를 오버라이드 재정의하지 않으면 중복값을 허용하지 않는 Set 인터페이스를 제대로 구현하지 못할수 있다. (재정의 하지 않으면 그저 객체의 주소값만을 가지고 비교하기 때문)
다음은 TreeSet 클래스이다.
TreeSet 클래스는 기본적으로 자료의 중복을 허용하지 않으면서 출력 결과값을 정렬하는 클래스이다. 다만, 정렬할때 따르는 규칙이 이진 검색 트리 (Binary search Tree)를 사용한다. (TreeSet은 순서가 있는 Set 인터페이스이며 기본값으로 기준이 되는 값이 작은것부터 정렬이 되는 Set 인터페이스이다.)
이진 검색 트리가 뭐냐면, 어떤 값을 기준으로 삼고 앞으로 추가되는 값을 배치한다고 가정했을때, 왼쪽에 두면 기준값보다 작은값, 오른쪽에 두면 기준값보다 큰값이라는 규칙을 두고 값들을 정렬하는게 이진 검색 트리이다. (값들을 노드라고 하며 이런 규칙으로 정렬한 결과를 보면 마치 나무, 트리 모양을 띄워서 유래했다)
여태까지 해왔던 대로 import java.util.TreeSet으로 임포트하고 제네릭, .add, .remove, iterator 반복자를 이용해 TreeSet 클래스를 만들면 되긴 하지만, 아래 문구와 같은 오류창이 뜰것이다.
패키지이름.TreeSet클래스이름 cannot be cast to java.base/java.lang.Comparable
TreeSet을 구현할때 Comparable 인터페이스를 이용하지 않았다는 의미인데, 즉슨 TreeSet을 구현할때 어떤 기준으로 노드들을 비교하교 배치할지 정하지 않았다는 의미이다. 이때 사용해야하는 인터페이스가 Comparable 혹은 Comparator이다.
먼저, TreeSet으로 구현할 클래스에서 interface를 도입(implements)해야한다:
public class TreeSet클래스이름 implements Comparable < TreeSet클래스이름 >
그리고, Comparable 인터페이스는 추상 메서드 compareTo()를 가지고 있기 때문에 도입한 TreeSet 클래스에서 구현을 다음과 같이 해줘야 한다: (TreeSet에서 각각 값들을 비교할때 시스템에서 자동적으로 호출해 기준으로 하는 메소드(콜백 함수)가 바로 compareTo()이다)
@public int compareTo(TreeSet클래스 객체명) {
return (this.비교할 멤버 변수 값 - 기존 객체명.비교할 멤버 변수 값)
}
//this <= 새로 추가될 객체반환 값은 새로 추가될 객체와 기존에 있는 객체 둘다 가지고 있는, 공통되면서 비교할 값들의 차이인데 이 반환값이 양수면 오름차순으로 정렬되고 음수면 내림차순으로 정렬된다.
Comparator 인터페이스도 마찬가지이다. implements 도입하고 compare() 메소드 구현하면 된다. 다만, Comparator 도입한 클래스를 기반으로 객체 생성을 할때 아래와 같이 써야한다:
TreeSet<클래스 이름> 객체명 = new TreeSet< 클래스 이름 >(new 클래스 이름());
다만, 매개변수를 2개로 받기에 첫번째 매개변수와 두번째 매개변수의 차이를 비교하는데, 첫번째 매개변수보다 두번째 매개변수가 큰 경우 서로의 차이로 반환값을 매겨 양수가 나와 오름차순으로 정렬된다, 아래처럼 말이다:
@Override
public int compare(TreeSet 클래스 이름 객체1, TreeSet 클래스 이름 객체2) {
return 객체1의 기준값 - 객체2의 기준값;그리고 Comparator 인터페이스를 쓰는 경우는 String 클래스처럼 이미 Compare 인터페이스를 구현하고 있고, 그래서 내부적으로 compareTo() 메소드가 오름차순으로 구현되어있는데 final로 선언되어서 오버라이드 재정의할수 없을때, 그런데 추가적으로 내림차순을 구현하고 싶을때 쓰는 경우가 있다.
(Comparator 인터페이스를 implements한 클래스에서 compare() 메소드를 오버라이드 하되, 첫번째 매개변수명.compareTo(두번째 매개변수명)의 값에 -1을 곱하고 그대로 return, 그리고 메소드 오버라이드가 속한 클래스를 기반으로 새 객체 new 클래스 이름()을 TreeSet 클래스 생성자에 매개변수로 넣으면 된다)
3) Map 인터페이스
map은 어떤 특정 Key 키와 어떤 특정 Value 밸류 값이 키-밸류 마다 마다 연결되어있는 구조를 뜻한다.
Key 값은 유일하며 value값은 서로 중복될수 있으며, 특정 value값을 끌어오기 위해선 그에 맞는 key값을 끌어와야한다.
map은 자바 컬렉션 프레임워크 뿐만 아니라 자바스크립트 파생인 jquery, jsp, json에서 많이 쓰이니 더 자세히 후술할 기회가 있다면 후술하겠다. (어차피 일부 메소드에서 차이가 있을뿐, 해당 컬렉션 프레임워크 기반 클래스를 만들고, 요소를 추가하거나 삭제하고, 반복자로 치환해 해당 요소들을 다루는것은 앞서 적었던 컬렉션 프레임워크 예시들과 거의 동일하다.)
그래서 여기서는 map 인터페이스에서만 쓰이는 일부 메소드와 map 인터페이스에 해당하는 클래스들만 짤막하게 보고 넘어가겠다:
V put(K key, V value): 해당 key에 맞춰서 value값을 map 객체에 저장하고 저장되면 value값을 반환한다.
V remove(Object key): 해당 key에 해당하는 value값을 삭제하고 key 값 스스로도 삭제한다.
Set keySet(): . 접근연산자로 물린 map 객체 안에 담긴 key값들을 Set 인터페이스로 반환한다.
V get(key): 매개변수로 주어진 해당 키에 대응하는 value 값을 반환한다.
boolean containsKey(Object key), containsValue(Object value): 매개변수로 주어진 Key/Value값을 .접근 연산자로 물린 map 객체안에 있는지 확인하고 있으면 true, 없으면 false 반환한다.
Set< Map.Entry<K, V>> entrySet(): .접근연산자로 물린 map 객체의 key값과 value값을 pair(쌍,커플)단위로, 즉 Entry단위로 묶어서 그것들을 또 모아 Set 자료형으로 최종 반환한다. 이 Set 객체에서 키값 밸류값을 뽑아내는 방법으로는 반환된 Set 객체에 키값을 안다면 그걸 매개변수로 주고 get 메소드를 연결하거나 아니면 반복자 iterator(iterator()메소드)와 엮어서 키값만 빼오는 getKey(), Value값만 빼오는 getValue()메소드로 마무리를 지어 키값, 밸류값을 빼오는 방식 이 두가지가 존재한다.
Map 인터페이스를 구현한 클래스는 2가지가 있는데 HashMap 클래스, HashTable 클래스가 존재. (HashMap은 Value 값에 null을 허용하고, HashTable은 Value 값에 null 허용하지 않음.또한 HashTable은 멀티스레드 환경을 지원한다. 또한 이진 검색 트리와 key값으로 정렬이 적용되는 TreeMap이 있다.)
3. 이너 클래스
클래스 안에 클래스가 중첩된 클래스를 이너 클래스라고 하며, 보통 밖에 영역을 가진 클래스를 외부 클래스라고 하며 안에 있는 클래스를 이너 클래스/ 내부 클래스라고 한다. 내부 클래스 객체를 생성하는 형식은 아래와 같다:
외부 클래스명.해당 내부 클래스명 객체명 = 외부 클래스명.new 내부 클래스명();
우리가 변수를 인스턴스/static/지역으로 나누는것처럼 이 이너 클래스도 인스턴스/static/지역 클래스로 나누고 있다. 아래 설명을 보자:
인스턴스 내부 클래스: 클래스안에 별다른 선언없이 그저 평범하게 클래스가 중첩되는 클래스로, 인스턴스 클래스는 내부에서는 static 변수/메서드는 사용할수 없지만, 그 인스턴스 클래스를 감싸는 외부 클래스의 static 변수/메서드는 사용 가능하다. 외부 클래스와 변수나 메서드 이름이 겹치는 경우 외부 클래스와 내부 클래스 따로 따로 객체를 달리 생성해서 각각 메소드를 호출하면 되고, 아니면 그냥 호출하면 된다.
static 내부 클래스: 클래스안에 중첩된 내부 클래스이지만 static으로 선언된 클래스. 클래스 내부에 선언된, static 멤버 변수/메소드는 물론 클래스 내부에 선언된 일반 멤버 변수/메소드도 사용 가능하다. 다만, 외부 클래스에서 선언된 static 변수/메소드만 사용 가능하다. static 성격에 맞게 static 내부 클래스 안에서 static으로 선언된 변수/메소드는 클래스명으로 접근 가능하고 나머지 일반 멤버 변수/메서드는 객체 생성후에 접근 가능하다.
지역 내부 클래스: 외부 클래스의 메소드안에 내부 클래스가 있는 경우로, 해당 메소드안에 내부 클래스의 객체를 만드는 식이 있어야 한다. 그래서 내부 클래스에 접근해서 내부 클래스에 있는 요소를 실행해보려면 외부 클래스의 객체를 먼저 생성하고 해당 메소드를 실행해야한다.
내부 클래스를 인스턴스 클래스 혹은 static 클래스로 만든것이 바로 아래 코드문이다:
public static void main(String[] args)
{
Outer outer = new Outer();
//내부클래스 객체 생성
Outer.InstanceInner instanceInner = outer.new InstanceInner();
System.out.println("instanceInner.iv : " + instanceInner.iv);
System.out.println();
System.out.println("Outer.StaticInner.cv : " + Outer.StaticInner.cv);
//static 변수라서 바깥 클래스명.해당 내부 클래스명.static 변수명
Outer.StaticInner.cv = 50;
System.out.println("Outer.StaticInner.cv : " + Outer.StaticInner.cv);
Outer.StaticInner staticInner = new Outer.StaticInner();
System.out.println("staticInner.iv : " + staticInner.iv);
System.out.println();
outer.myMethod();
instanceInner.myMethod();
staticInner.myMethod();
staticInner.iv = 50;
System.out.println("staticInner.iv : " + staticInner.iv);
}
}
class Outer {
int data = 0;
static int data1 = 50;
void myMethod() {
System.out.println("Outer 클래스의 메소드 data : "+data);
}
// 내부클래스 1 - 멤버 이너 클래스
class InstanceInner{
int iv = 100;
void myMethod() {
System.out.println("InstanceInner 클래스의 메소드 data : "+data + ", iv: "+ iv );
}
}
// 내부클래스 2 - 정적 클래스
static class StaticInner {
int iv = 200;
static int cv = 300;
void myMethod() {
System.out.println("StaticInner 클래스의 메소드 data1 : "+data1);
// System.out.println("StaticInner 클래스의 메소드 data : "+data);
// 클래스 외부 데이터인 경우는 static만 올 수 있다.
System.out.println("StaticInner 클래스의 iv : "+iv +", cv: "+cv );
}
}
}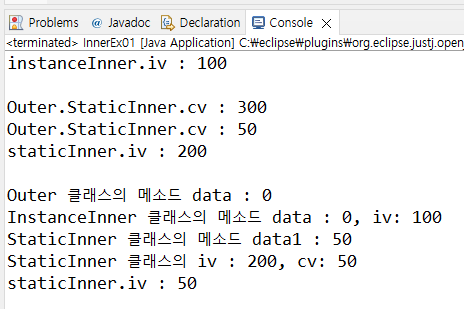
출력 결과는 보는대로 인스턴스 클래스이자 그 객체인 InstanceInner(instanceInner)는 인스턴트 클래스의 멤버 변수 iv, 외부 클래스 Outer의 멤버 변수 data에 접근이 가능했고, 스태틱 클래스이자 그 객체인 StaticInner(staticInner)는 스태틱 클래스의 멤버 변수 iv, 정적 멤버 변수 cv, 외부 클래스의 정적 변수 data1까지 접근이 가능했다.
다음은 메소드 호출로 생성되는 지역 클래스이다:
public class InnerEx02
{
private int data = 30;
void display() {
class Local { //지역 이너클래스
void msg() {
System.out.println(data);
display2();
}
}
Local l = new Local();
l.msg();
}
class InstanceInner{
int iv = 100;
void myMethod() {
display();
// msg();
System.out.println("InstanceInner 클래스의 메소드 data : "+data + ", iv: "+ iv );
}
}
void display2() {
System.out.println("display2() 메소드 호출");
}
public static void main(String[] args)
{
InnerEx02 obj = new InnerEx02();
obj.display();
InnerEx02.InstanceInner obj1 = obj.new InstanceInner();
obj1.myMethod();
}
}
외부 클래스인 InnerEx02과 그 안의 display() 메소드로 로딩되어 나오는 지역 클래스 Local, 그리고 또 다른 내부 인스턴스 클래스인 InstanceInner가 존재하는데 main 메소드에서 display()메소드와 myMethod()메소드만 호출되므로 display 메소드 안 지역 클래스 Local이 메모리 로딩되어 또 그 안에서 Local 클래스 생성후 msg 메소드를 호출하는데 msg 메소드는 외부 클래스의 data값을 출력하고 콘솔에 출력문을 실행하는 display2메소드도 호출하기에 위와 같은 결과가 나온것이다.
어쨌든 내부 클래스는 외부 클래스가 먼저 생성되거나 외부 클래스에 먼저 접근해야 생성이 가능하거나 접근이 가능하며 종류로는 인스턴스/정적/지역 내부 클래스가 있고 이름에서 알수 있다시피 이름에서 의미하는대로 각각 성격이 다르다.
그 다음은 익명클래스이다.
익명클래스는 이너 클래스에 속하지만 앞의 이너 클래스들과 다르게 이름이 없는 클래스라고 보면 된다. 보통 new 키워드를 통해서 객체를 생성할때 우항에 기술되는 new 클래스명 () 바로 오른쪽 옆에 중괄호 {};를 달고 안에는 익명 클래스 내용이 기술되는 방식으로 진행된다. (그 왼쪽으로 오는 클래스를 상속받는다고 보면 된다)
이렇게 왜 객체를 생성할때 옆에 익명클래스를 달아야 하냐면 좌항 대입받는 곳에서 상속받은 클래스의 부모 인터페이스 혹은 추상 클래스의 형태로 객체가 최종적으로 생성이 되어야 할때 그리고 부모 클래스가 생성자가 없는 인터페이스나 추상 클래스의 경우 우항 new 자식 클래스 () 옆에서 이름 없는 클래스로 클래스 내용을 그 중괄호 안에 전부 넣어 최종적으로 그 내용을 달고 나오는 인터페이스 혹은 추상 클래스 객체를 만들기 위함이다.
한가지 주의할 점이 익명 클래스는 외부 클래스의 멤버 변수를 써도 되는데 익명 클래스 내부 안에서 그 변수 값이 변하지 않아야 한다. (Effectively final, 마지막으로 받는 형태가 인터페이스 및 추상 클래스면 변수가 무조건 final을 안적어도 final로 인식하기에 그렇다. 아니면 애초에 final 선언을 해야한다)
그리고 익명 클래스의 멤버 변수는 일반 멤버 변수와 static final 선언한 멤버 변수로만 존재할수 있고 그냥 static 선언된 변수는 사용할수 없다.
그리고 만약 부모 인터페이스 혹은 추상 클래스에는 없는, 자식 클래스 만의 메소드가 있다고 할때, 그 자식 클래스 메소드는 사용할수 없다. (변수 또한 마찬가지이다.)
결국, 익명 클래스란 익명 클래스 위치에 옆에 생성자로 온 클래스의 부모 인터페이스 혹은 추상 클래스 형태의 객체를 최종적으로 생성하고 싶은데 자식 클래스와는 다른 내용으로 가고 싶을때 쓰는 클래스라고 보면 된다. (나머지 적용되는 규칙은 상속 및 오버라이딩 그리고 하이딩 규칙, 인터페이스, 추상 클래스가 적용된다)
아래 예시를 코드 보면서 마무리 해보자:
abstract class AnnonyEx01Abstract { //부모 추상 클래스
public abstract void doSomething();
}
class ASub extends AnnonyEx01Abstract{ //자식 구현 클래스
@Override
public void doSomething() {
System.out.println("ASub클래스 doSomething()메소드 호출");
}
}
public class AnnonyExTest01
{
public static void main(String[] args)
{
int aa = 5;
final int AA = 7;
AnnonyEx01Abstract myClass = new ASub() { //이 익명 클래스는 ASub 클래스를 상속받지만 마지막 좌항, 그러니까 최종 형태는 추상 클래스 객체이다. (자식 클래스 멤버 변수 및 메소드 하이딩)
// 익명 클래스는 생성자가 없는 abstract 클래스나 인터페이스를 상속받아 대신 생성자,객체생성,메소드 오버라이드까지 한꺼번에
// 메인 클래스(메인 메소드 안)에서 처리할수 있게 해준다.
private int a = 15;
String s = "AnnonymousClass";
// final int AA = 0; //오류
static final int AA = 0; //익명 클래스는 '클래스'이기 때문에 static 선언이 가능
// static int st = 0; //final 선언이 추가적으로 되어야 함! (상수)
@Override
public void doSomething() {
// aa = a + aa; //오류
super.doSomething();
System.out.println("내부 익명 클래스의 doSomething메소드");
System.out.println("s : "+s);
System.out.println("a : "+a);
System.out.println("aa: "+aa);
System.out.println("AA: "+AA);
etcMethod();
}
public void etcMethod() {
System.out.println("기본 메소드입니다.");
}
};
myClass.doSomething();
// myClass.etcMethod(); //오류
// aa = aa + 15; //오류
System.out.println("aa: "+aa);
// System.out.println(myClass.s); //오류
}
}
결과를 보면 위에서 말한것처럼 상속받은 익명 클래스의 doSomething 메소드가 호출되었고, 변수들은 동일한게 외부 클래스와 내부 클래스에 동시에 있더라도 내부 클래스의 지역 변수를 우선으로 가져왔으며 (AA) 동일하지 않고 익명 클래스에 없는 변수는 외부 클래스에서 직접 끌어왔음을 알 수 있다. (s, a, aa)
결국 익명 클래스는 최종적인 목적은 스스로 객체를 생성할수 없는 추상 클래스나 인터페이스의 객체를 메인 메소드에서 new 예약어 옆에 기술함으로써 바로 생성하기 위함인데, 그 결과가 위처럼 메소드를 통하거나 아니면 따로 원본 추상 클래스나 인터페이스로 받고 그 다음에 메소드를 호출해서 그 익명 클래스의 기능을 실현하는 방법 두 가지가 있다.
이렇게 익명 클래스가 있었고, 마지막은 람다식이다.
지금까지 우리가 자바로 프로그래밍하던 방식은 클래스를 만들고 안에 필요한 변수와 메소드를 담은 뒤 쓰고 싶으면 객체를 생성한 뒤 직접 그 변수와 메소드를 호출하는 방식이었다. (클래스 기반 객체 지향) 그런데 그런 경우 일일이 클래스/변수/메소드를 다 일일이 만들어야 했기에 이런 불편함을 해소하고자 나온게 바로 람다식이다.
람다식은 함수의 구현과 호출만으로 프로그램을 짜는 함수형 프로그래밍 (Functional Programming, FP)중 하나인데 그 중 자바의 함수형 프로그래밍 방식은 람다식(Lamda Expression)이라고 부른다.
람다식의 일반적인 형태는 다음과 같다:
(매개변수[들]) -> {실행문};좌항에 매개변수를 넣으면 우항의 실행문이 실행되어 결과가 나오는 단순한 함수 형태인데 단 다음과 같은 규칙을 지켜야 한다:
- 기본적으로 매개변수의 자료형을 생략할 수 있으며, 매개 변수가 하나이면 소괄호도 생략이 가능하다. 또한, 중괄호의 구현 문장이 한 문장이면 중괄호도 생략이 가능하다.
str -> System.out.println(str);
- 다만, 중괄호 안 구현 문장이 한 문장이어도 일반적으로 return이 있는 경우 중괄호를 생략할 수 없다.
str -> return str.length(); //잘못된 형식
- 예외적으로 중괄호 안 return문이 하나라면, 중괄호 및 return문까지 생략할수는 있다.
(x,y) -> x+y str -> str.length()
- 매개변수가 없다면 소괄호는 생략이 불가능하다.
() -> System.out.println("abc");
그럼 본격적으로 간단한 함수형 인터페이스의 구체적인 예시는 다음과 같다:
interface Ramda01{
int getMax(int num1, int num2);
// int add(int num1, int num2);
}
public class RamdaEx01
{
public static void main(String[] args)
{
//람다식을 인터페이스형 max변수(객체, 람다식에 한해서만!)에 대입
Ramda01 max = (x,y) -> (x>=y) ? x: y; //getMax 메소드 오버라이드
int r = max.getMax(10,20); //리턴 받음 그대로 r에 대입
//인터페이스형 변수로 메소드 호출
System.out.println(r);
}
}
이렇게 람다식을 적용할 인터페이스 객체에 등호의 우항으로 람다식을 적으면 그 객체의 추상 메소드에 람다식이 오버라이드 되는것이고, 그렇게 만든 객체에 접근해서 매개 변수를 주면서 오버라이드 된 추상 메소드를 호출하면 결과가 나오는 형태이다.
람다식이 왜 이렇게 나타나는 거냐면, 앞서 배운 익명 클래스와 밀접한 연관이 있는데 사실 익명 클래스를 간단히 나타낸게 람다식이라고 봐도 무방하다.
위의 있는 예시를 익명 클래스로 다시 바꾸면 다음과 같기 때문이다:
interface Ramda01{
int getMax(int num1, int num2);
// int add(int num1, int num2);
}
public class RamdaEx01
{
public static void main(String[] args)
{
Ramda01 max = new Ramda01(){
@Override
public int getMax(int num1, int num2) {
if(x>=y) return x;
else return y;
};
int r = max.getMax(10,20);
System.out.println(r);
}
}이런 익명 클래스 형태에서 매개변수는 놔두고 new 예약어와 생성자 그리고 전체를 감싸는 구현부만 제거하고 실행문은 한문장으로 압축한 뒤 매개변수와 실행문 사이를 -> 화살표로 이어주기만 하면 람다식이 완성되는것이다. 즉, 람다식은 익명 클래스와 같이 이름이 없는, 익명 클래스의 메소드(함수) 버젼이라고 보면 된다.
그리고 람다식은 이름이 없는 메소드이기에 람다식 이전 선언된, 람다식이 오버라이드 할 인터페이스의 메소드 개수는 딱 오직 1개여야만 한다. (2개 이상이면 어떤 메소드를 람다식으로 오버라이드할건지 애매하해지기 때문)
마지막으로 덧붙이자면, 람다식이 익명 클래스의 축소판이기에 람다식은 익명 클래스의 규칙을 따른다. (람다식 내부에서 메인 메소드나 원본 인터페이스의 static final 지역 변수를 변경할 수 없다) 그리고 앞서 본 인터페이스형 변수에 대입하는 방식 말고도 람다식 자체를 또다른 함수의 매개변수로 전달하거나 함수의 반환 값으로 사용이 가능하다.
여기까지해서 제네릭과 컬렉션 프레임워크, 이너클래스, 람다식에 대해서 알아봤는데 컬렉션 프레임워크는 종종 쓰이니 꼭 알아두어야 하며 람다식도 가끔 쓰이는것으로 알고 있다.
다음 장에서는 데이터를 정렬하거나 선택적으로 반환해 출력하게 해주는 스트림 클래스와 프로그램 처리 중 오류가 발생했을때 자동적으로 처리하게 해주는 예외 처리 기법, 그리고 마지막으로 외부에서 자바로/자바에서 외부로 입출력을 받을수 있게 하기 위해 만들어진 입출력 클래스 InputStream/OutputStream 그리고 마지막으로 스레드를 알아보면서 자바 기초 내용을 마무리 짓겠다.
