1. 스트림 클래스
일반적으로 스트림은 데이터의 흐름을 뜻하는데 자바에서는 이런 데이터의 흐름, 즉 여러개의 데이터가 있는 소스(스트림)를 가지고 다양한 방법으로 어떤 특정한 연속적인 데이터를 추출하는것이 스트림 클래스의 기능이자 정의이다. (그러면서 기존 자료를 변경하지 않는다)
그래서 일반적으로 방금 전 챕터에서 배웠던 배열이나 다른 컬렉션 프레임워크들이 사용된다.
(컬렉션 프레임워크 클래스에 이런 스트림 클래스를 처리하는 메소드들이 있다고 보면 된다)
(스트림 클래스는 java.util.stream 패키지의 멤버 클래스이며 BasicStream 인터페이스를 상속받아 Stream/IntStream/LongStream/DoubleStream 클래스들을 제공한다.)
일단 스트림 클래스는 중간 연산과 최종 연산이 있는데 중간 연산은 처음 받은 스트림 데이터를 거르거나 변경하여 또 다른 자료를 내부적으로 생성한다. 그리고 최종 연산은 그런 중간 연산의 결과 값을 받아 그 자료를 소모해서 최종적인 결과 값을 반환한다.
다음은 중간 연산에 많이 쓰이는 메소드들이다:
1. filter( ) : 조건에 맞는 요소들만 추출
import java.util.Arrays;
import java.util.stream.IntStream;
public class Ex01_Stream1
{
public static void main(String[] args) {
int[] arr = {2,4,6,8,10};
//스트림 클래스 객체 생성
IntStream stm1 = Arrays.stream(arr);
//중간 연산
IntStream stm2 = stm1.filter(n -> n < 7);
//최종 연산
int sum = stm2.sum();
System.out.println(sum);
}
}
이처럼 filter 메소드가 요소들 중 값이 7보다 작은것들만 골라서 새로운 자료 스트림 객체를 만들어 반환한다.
여기서 덧붙이자면 스트림 클래스가 처리되는 과정을 잘 보면 최종 연산 전까지는 모두 스트림 클래스로 반환된다는것을 알 수 있는데, 그래서 첫 스트림 클래스 객체 바로 뒤에 연산 메소드를 연속으로 호출할 수 있다. (위의 과정을 다음과 같이 변경해도 똑같은 결과 값이 나오며 주로 람다식을 같이 병용한다)
int sum = Arrays.stream(arr).filter(n -> n < 7).sum();이것을 파이프라인이라고 한다.
(여기서 더 생각해보면 데이터들을 처리해 원하는 결과 값을 얻는다고 할때 컬렉션 프레임워크를 사용했을때보다 스트림 클래스를 사용하면 더 간결하고 빠르게 결과값을 얻을 수 있다)
2. map( ) : 조건에 맞는 요소로 변환
import java.util.Arrays;
import java.util.List;
public class Ex02_Map
{
public static void main(String[] args)
{
List<String> list = Arrays.asList("apple", "banana", "orange");
list.stream()
.map(s -> s.concat(" juice")) // 뒤쪽에 한칸 띄고 "juice" 문자열 덧붙임
.forEach(n -> System.out.print(n + "\t"));
System.out.println();
}
}
이처럼 map( ) 메소드가 기존에 있던 List의 각각 요소들 뒤에 한칸 띄고 "juice"를 붙여서 반환하는데, map( ) 메소드는 결과적으로 요소들에 조건에 적어놓은 변환 규칙들을 적용해 반환한다고 보면 된다.
3. sorted( ) : 사전순으로 정렬 (조건을 주면 조건대로 정렬)
import java.util.Arrays;
import java.util.List;
public class Ex03_Sorted
{
public static void main(String[] args)
{
List<String> list = Arrays.asList("가자미", "다루마치", "말");
// 사전순 정렬
list.stream()
.sorted()
.forEach(n -> System.out.print(n + "\t"));
System.out.println();
// 글자 길이순 정렬
list.stream()
.sorted((s1, s2) -> s1.length() - s2.length())
.forEach(n -> System.out.print(n + "\t"));
System.out.println();
}
}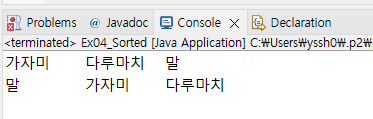
이처럼 sorted 메소드는 조건 없이 적으면 사전순으로 데이터를 정렬시키고, 조건을 주면 조건에 맞춰 데이터를 정렬시킨다.
다음은 자주 쓰이는 최종 연산 메소드들이다:
(다만 알아두어야 할것은 보통 중간 연산으로 나온 중간 결과값을 최종 결과로 연산하는게 최종 연산인데, 한번 최종 연산을 거치면 더이상 해당 스트림 객체는 재사용이 불가능 하다 즉, 중간 연산이 더이상 되지 않는다)
1. forEach( ) : 요소들 하나 하나씩을 꺼냄
2. sum( ) : 요소들의 합계를 int 자료형으로 반환함
3. count( ) : 요소들의 개수를 long 자료형으로 반환함
4. average( ) : (평균값을 구할 수 있다면) 요소들의 평균값을 double 자료형으로 반환함
5. min( ) / max( ) : (최소/최대값을 구할 수 있다면) 요소들의 최소/최대값을 int 자료형으로 반환함
사용법은 아래의 예시와 같다고 보면 된다:
import java.util.stream.IntStream;
public class Ex04_PreTerminal
{
public static void main(String[] args)
{
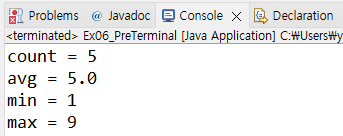
// 합
int sum = IntStream.of(1, 3, 5, 7, 9)
.sum();
System.out.println("sum = " + sum);
// 개수
long cnt = IntStream.of(1, 3, 5, 7, 9)
.count();
System.out.println("count = " + cnt);
// 평균
IntStream.of(1, 3, 5, 7, 9)
.average()
.ifPresent(avg -> System.out.println("avg = " + avg));
// 최소
IntStream.of(1, 3, 5, 7, 9)
.min()
.ifPresent(min -> System.out.println("min = " + min));
// 최대
IntStream.of(1, 3, 5, 7, 9)
.max()
.ifPresent(max -> System.out.println("max = " + max));
}
}
average( )나 min( ), max( ) 메소드는 반환 클래스 형태가 값이 있는지 없는지 선택이 가능한 OptionalDouble 혹은 OptionalInt이기 때문에 여기서 전용 메소드인 ifPresent( ) 메소드를 사용해 먼저 값이 있는지 없는지 확인하고 그에 맞춰 람다식을 이용해 최종 결과값을 도출한다.
+) 더 추가하자면 최종 연산에 reduce( ) 메소드가 있는데 (삼항 연산자 및) 람다식을 사용해 초깃값과 복잡한 조건으로 프로그래머가 직접 지정하는 조건 아래 스트림 클래스의 데이터를 처리할 수 있다:
reduce(0, (a,b) -> a + b); // 0은 초깃값, a와 b는 스트림 데이터의 요소들, a + b는 각각 데이터들이 어떻게 조건 처리되어야 하는지 알려주는 조건식
import java.util.Arrays;
import java.util.List;
public class Ex05_Reduce
{
public static void main(String[] args)
{
List<String> list1 = Arrays.asList("춘식이", "전우치", "손오공");
String name1 = list1.stream()
.reduce("이순신", (s1, s2) ->
s1.length() >= s2.length() ? s1 : s2);
System.out.println(name1);
List<String> list2 = Arrays.asList("홍길동", "강감찬", "연개소문");
String name2 = list2.stream()
.reduce("이순신", (s1, s2) ->
s1.length() >= s2.length() ? s1 : s2);
System.out.println(name2);
}
}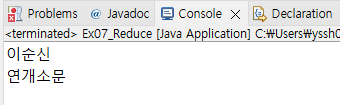
첫 이순신 결과는 List 스트림 데이터의 요소들이 모두 3글자였기 때문에 계속 참인 결과로 이순신이 나왔던것이고 (s1), 두번째 연개소문은 연개소문 차례에서 reduce가 처리될때 연개소문이 4글자이므로 거짓이 나와 마지막 결과로 거짓의 결과인 연개소문이 나왔던것이다. (s2)
2. 예외 처리
실생활에서도 컴퓨터 프로그램 내에서도 마찬가지로 에러(Error), 오류라는것이 발생한다. 컴퓨터 프로그램 개발할때 생기는 에러는 보통 2가지로 구분되는데 프로그램을 설계하고 코드를 작성할때 실수로 발생하는 컴파일 에러 (Compile Error), 코드 상으로는 문제 없었지만 실행시 문제가 발생하는 런타임 에러 (Runtime Error)가 있다.
(앞의 2가지는 예측이 어느정도 가능하지만 이 외에 예측이 불가능한, 시스템 에러가 있다. 보통 프로그램을 돌리는 컴퓨터의 메모리가 갑자기 부족하다던가 개발 실행 프로그램 문제가 아닌 운영체제상 발생한 문제가 영향을 끼친다던가 하는 경우가 이에 속하며 이런 경우는 개발자가 제어 불가능이다)
(시스템 에러를 제외하고) 만약 프로그램 상 에러가 발생하면 보통 콘솔창에 로그가 같이 출력되는데 (로그 log는 프로그램 실행시 발생한 여러 일들이 기록된 내용으로서 파일 형태로 저장되며 파일 이름을 로그 파일이라고 한다) 이런 로그 분석을 통해 에러가 어느 시점에 발생했고 왜 발생했는지 분석이 가능하다. 그래서 프로그램 실행마다 로그를 출력해서 남기는게 가장 중요하다.
여튼 시스템 에러를 제외한 나머지 에러 즉, 컴파일 에러와 런타임 에러는 자바 프로그램으로 제어가 가능한데, 이런 에러들을 예외 (Exception)이라고 하며 이를 예외 처리 (Exception Handling)이라고 한다.
그리고 왜 예외 처리를 하냐면, 에러 발생시 일단 프로그램이 정상적으로 빠르게 종료되게끔 하고 거기에 동시에 아무런 예외 처리를 하지 않은 프로그램에 에러가 발생되면 개발자가 만든 프로그램 코드가 필터링 없이 바로 노출되기에 이런 백엔드 소스 코드 노출을 막기 위해서이다.
일단 자바에서 예외 처리는 먼 조상부터 보자면 Throwable 클래스에서 시작되며 이 클래스를 상속받는 클래스가 Error 클래스와 Exception 클래스가 있는데 앞으로 우리가 볼 예외 처리 클래스는 Exception 클래스이자 모든 에러의 최상위 클래스라고 보면 된다. (Error 클래스는 시스템 에러를 다룬다)
그리고 그런 Exception 클래스에서도 예외 처리를 하지 않으면 컴파일시 오류가 발생하므로 꼭 예외 처리를 해야하는 예외들도 있고 (Compile Error) 컴파일 시에는 에러가 발생하지 않으므로 개발자가 예외 처리를 하던지 아니면 자바 가상 머신이 알아서 처리하던지 선택할 수 있는 예외들도 있다는것을 (Runtime Error) 명심하자.
+) 알아두면 좋은 예외 이름들!
아래는 컴파일 시 에러가 발생하지 않는 런타임 에러들 중 많이 발생되는 예외들이다.
ArithmeticException : 0으로 나누기와 같은 부적절한 연산을 수행할때 발생
IllegalArgumentException : 메서드에 부적절한 매개변수를 전달할 때 발생
IndexOutOfBoundException : 배열, 벡터 등에서 범위를 벗어난 인덱스를 사용할때 발생
NoSuchElementException : 요구한 원소가 없을때 발생
NullPointerException : null값을 가진 참조 변수에 접근할때 발생
NumberFormatException : 숫자로 바꿀 수 없는 문자열을 숫자로 변환하려고 할때 발생
그리고 아래는 컴파일 시 에러가 발생하므로 꼭 개발자가 미리 예외 처리를 해야하는 컴파일 에러, 예외들이다.
ClassNotFoundException : 존재하지 않는 클래스를 사용하려고 할때 발생
NoSuchFieldException : 클래스가 명시한 필드를 포함하지 않을때 발생
NoSuchMethodException : 클래스가 명시한 메서드를 포함하지 않을때 발생
IOException : 데이터 읽기 쓰기 같은 입출력 문제가 발생
그리고 아래 코드는 이런 런타임 에러와 컴파일 에러의 발생 차이를 볼 수 있는 예시 코드 이다:
import java.util.Scanner;
public class Ex01_ExceptionCase
{
public static void main(String[] args)
{
Scanner sc = new Scanner(System.in);
int num1 = sc.nextInt();
int num2 = 10 / num1;
System.out.println(num2);
//My Book book1 = new MyBook();
}
}코드의 num1, num2같은 경우는 먼저 콘솔에서 숫자를 받고 그 숫자로 10을 나누는것이며 다음 book1의 경우에는 그냥 Book 클래스의 인스턴스를 생성하는 간단한 코드들이다.
먼저 num1과 num2의 경우 실행해서 만약 콘솔에 0을 입력하면 아래와 같은 에러가 나오고 (런타임 에러, ArithmeticException, 수학적으로 계산이 불가능해서 나오는 오류)

추가로 문자를 입력하면 아래와 같은 에러가 나오며 (런타임 에러, InputMismatchException, 계산에 필요한 인풋 입력값이 잘못되었기에 나타나는 오류)
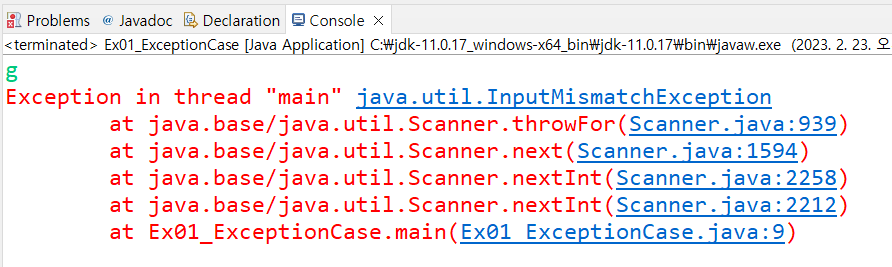
미리 주석처리한 book1부분을 주석 해제하고 저장(컴파일)을 하면 아래와 같은 에러가 나온다. (컴파일 에러, 이클립스는 코드를 작성하자마자 실시간으로 컴파일을 하며 그때마다 미리 검증 가능한 오류가 나오면 이렇게 빨간줄로 에러 표시를 해준다)
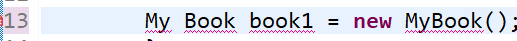

이제 예외가 어떤것인지 확실히 알았으니, 본격적으로 예외 처리하는 방법을 알아보자.
1) try-catch-finally문
일반적인 코드 구성은 아래와 같다:
try {
예외가 발생할 수 있는 코드 부분
} catch(처리할 예외 타입 e) {
try 블록에서 예외가 발생하면 실행되는 예외 처리 구문
} finally { //finally는 선택 사항
try-catch구문에 상관없이 무조건 실행되는 부분
}그럼 이걸 예제를 통해 연습해보자.
만약 아래처럼 크기가 5인 배열안에 0부터 4까지 숫자를 순차적으로 넣는다고 했을때 코드는 아래와 같을것이다:
int[] arr = new int[5];
for(int i = 0; i < 5; i++) {
arr[i] = i;
System.out.println(arr[i]);
}여기서 for문에서 i < 5를 i <= 5로 바꾼다면, 크기가 5인 배열에 0부터 5까지 6개의 숫자가 들어가게 되니 당연히 에러, 예외가 발생한다
(자세히는 런타임 에러 RuntimeException 클래스의 하위 클래스인 ArrayIndexOutofBoundsException으로 예외가 분류되며 이 클래스로 처리를 해야한다.)
이 예외는 런타임 에러에 속하기에 당연히 컴파일시에는 나타나지 않고 실행시 나타나는데 여기서 프로그래머가 미리 예외 처리를 하지 않는다면 예외가 발생하는 순간에 (정확히는 i가 5가 되었을때) 프로그램이 비정상적으로 처리가 되므로
비정상적인 종료를 막기 위해 예외처리를 미리 해주어야 한다. try-catch문을 써서 아래와 같이 말이다:
public class ArrayExceptionHandling {
public static void main(String[] args) {
int[] arr = new int[5];
try{
for(int i = 0; i<=5; i++){
arr[i] = i;
System.out.println(arr[i]);
}
}catch(ArrayIndexOutOfBoundsException e){
System.out.println(e);
System.out.println("예외 처리 부분");
}
System.out.println("프로그램 종료");
}
}그럼 실행했을때 아래와 같이 결과가 나온다:

4 바로 아래에 5가 출력되서 나왔어야 할텐데 나오지 않고 예외 발생의 이유를 알려주는 문구가 나온뒤
(ArrayIndexOutOfBoundsException e, e 객체가 예외에 관한 정보들을 가지고 있으며 이를 System.out.println으로 바로 출력하면 예외 발생에 관한 원인이 담긴, 간단한 문구가 나온다)
나머지 정해진 문구들(catch 구문인 예외 처리 부분, 프로그램 종료)이 콘솔에 출력되었다.
만약 이렇게 예외 처리를 하지 않았다면 마지막 문구인 "프로그램 종료"까지 실행되지 않고 도중에 종료되었을 것이다.
(또한, catch 옆에 들어가는 매개변수인 예외 클래스는 OR의 의미인 |을 이용해 여러 예외를 한꺼번에 처리할 수 있으며 필자가 앞에서 적은것처럼 모든 예외 클래스들은 Exception와 Throwable 클래스를 상속받으므로 Exception e 혹은 Throwable e를 사용하면 모든 예외 처리 상황을 다룰 수 있다)
(그리고 조그마한 팁이기도 한데, 런타임 에러가 발생해서 콘솔에 에러 로그가 뜰 경우 맨 아래서부터 위쪽으로 순차적으로 보면 에러가 발생한 지점을 알아낼 수 있다.)
그 다음 finally는 보통 프로그램이 끝나도 계속 열려있는 서비스 같은 경우에 프로그램이 종료될때 서비스도 같이 종료하도록 닫아줄때 같이 쓰인다.
보통 그런 서비스는 프로그램이 정상적으로 처리되었든 처리되었지 않았던 간에 상관없이 모든 코드가 수행되고 나서 서비스를 닫아줘야 리소스 부족 문제가 일어나지 않기 때문이다.
(닫아주지 않으면 계속 컴퓨터 리소스를 쓰게 되고 이것은 곧 한계에 다다른 컴퓨터가 심각한 에러를 낼 수 있기 때문)
후술하게 될 입출력 클래스의 일부로 FileInputStream 을 쓴 다음과 같은 예시를 보면 된다:
package exception;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class ExceptionWithFinallyHandling {
public static void main(String[] args) {
FileInputStream fis = null;
try {
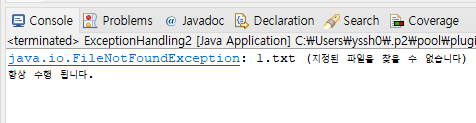
fis = new FileInputStream("1.txt");
} catch (FileNotFoundException e) {
System.out.println(e);
return;
}finally{
if(fis != null){
try {
fis.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
System.out.println("항상 수행 됩니다.");
}
System.out.println("여기도 수행됩니다.");
}
}
첫 try문에서 FileInputStream 객체를 생성하면서 1.txt 문자열을 매개변수로 주었다. 그러나 1.txt는 존재하지 않기에 여기서 예외가 발생하며 미리 작성해두었던 catch 구문(e 콘솔 출력)이 발동하여 콘솔창에 예외 정보를 간단히 출력하고 return;으로 프로그램이 정상 종료된다.
그런데 여기서 끝이 아니라 finally 구문이 꼭 실행되어 두번째 try 구문안 만약 fis 객체가 null이 아닌 경우 close() 메소드로 입출력 클래스 객체 생성에 사용되었던 스트림을 닫는 코드문이 실행되게 되며
(1.txt는 존재하지 않지만 fis 객체는 null이 아닌 실제로 '생성'이 되었기 때문)
두번째 catch구문은 예외가 발생하지 않았으므로 타지 않는다.
그리고 마지막 System.out.println 두 문장 중 "항상 수행됩니다."는 finally 구문 안에 있고 "여기도 수행됩니다."는 finally 구문밖에 있는데,
**앞에서 했던 return; 기준으로 프로그램이 종료되므로 finally 구문밖에 있던 "여기도 수행됩니다." 콘솔 출력은 실행되지 않고,
"항상 수행됩니다."는 finally 구문안에 있으므로 첫번째 catch문 안의 return;과 상관없이 실행을 보장받으며 마지막에 실행된다.
(또한, close 메소드를 try-catch문으로 감싸놓은 이유는 close 메소드가 예외를 일으킬 수 있기 때문에 해놓은것이길 알아둬야 한다 => IOException)
+) 자동으로 close 메소드를 호출하는 try-with-resources구문
자바 7버젼 부터는 이런 리소스를 close 메소드로 닫고 다시 되돌리는 복잡한 구문을 try-with-resources구문으로 간단하게 처리할 수 있게 되었다.
구체적으로는 리소스를 쓰는 해당 클래스가 AutoCloseable 인터페이스를 상속받아서 리소스를 다시 돌리는 메소드 (close)를 구현해야한다.
(FileInputSteam 클래스가 여기에 속하며, 네트워크(socket)와 데이터베이스(connection)관련 클래스들은 거의 대부분 AutoCloseable 인터페이스를 구현한다고 보면 된다)
사용법은 아래와 같다:
try(A a = new A(); B b = new B();) {
...
} catch(Exception e) {
...
}클래스 A 혹은 B가 AutoCloseable 인터페이스를 상속받은, 앞으로 사용할 클래스라고 보면 되고
그것을 try 옆 괄호안에 new 객체 생성문으로 써주기만 하면 된다. (close 메소드 x)
거기다 자바 9버젼에서는 더 향상된 try-with-resources 구문이 추가되어 더 쓰기 편해졌는데
원래는 외부에서 리소스를 사용하고 닫아야하는 클래스 객체가 생성되면 try 괄호안에서 다시 한번 다른 참조 변수로 선언해야 했지만, (다음 코드 참조)
A a = new A();
try(A a1 = a){
...
} catch(Exception e) {
...
}9버젼에서부터는 아래와 같이 외부에서 먼저 생성되고 선언된 리소스 사용 객체라 하더라도 재선언할 필요없이 바로 쓸 수 있게 아래처럼 간편하게 변경되었다:
A a = new A();
try(a){
...
} catch(Exception e) {
...
}2) throws 예외 처리 미루기
위처럼 예외 발생하는것을 try-catch 구문으로 해당 메서드 안에서 처리하는 방법도 있지만, 해당 메서드에서 예외가 발생되어도 그것을 미루고 해당 메서드를 호출하여 사용하는 지점에서 예외를 처리하는 경우도 있다.
그것이 throws 예약어 방법이며 아래의 구조를 띄고 있다:
메서드명([매개변수]) throws 예외[, 예외][, 예외] {
//본문 구현부
}이렇게 throws를 메소드명 옆에 붙인 뒤 발생할 수 있는 예외 클래스들을 적어놓으면 해당 메소드를 호출하여 사용한 지점으로 예외가 넘어가게 되며 그 지점에서 예외 처리가 제대로 되어있어야 한다.
(구체적으로는 메소드를 호출하고 실행하는 직접적인, 마지막 지점에서는 try-catch문으로 확실히 예외 처리가 되어있어야 한다)
그래서 앞의 try-catch문과 throws 예약어를 같이 사용하여 요약 정리겸 다음과 같은 코드문을 작성해보고 실행해보자:
import java.util.InputMismatchException;
import java.util.Scanner;
public class ThrowsInMethod
{
public static void myMethod1()
{
myMethod2();
}
public static void myMethod2()
throws ArithmeticException, InputMismatchException
{
Scanner sc = new Scanner(System.in);
int num1 = sc.nextInt();
int num2 = 10 / num1;
System.out.println(num2);
}
public static void main(String[] args)
{
try
{
myMethod1();
}
catch (ArithmeticException | InputMismatchException e)
{
e.printStackTrace();
}
System.out.println("-----------");
}
}
본 실행부인 main 메소드에 보면 try-catch문이 있고 try문 안에 myMethod1()을 실행하는데,
myMethod1 메소드는 myMethod2를 실행하고 myMethod2 메소드는 Scanner 클래스를 통해 콘솔 창에 입력을 받아 입력 받은 값으로 10을 나누고 그 결과를 콘솔창에 표시하는 기능으로 구현되어있다.
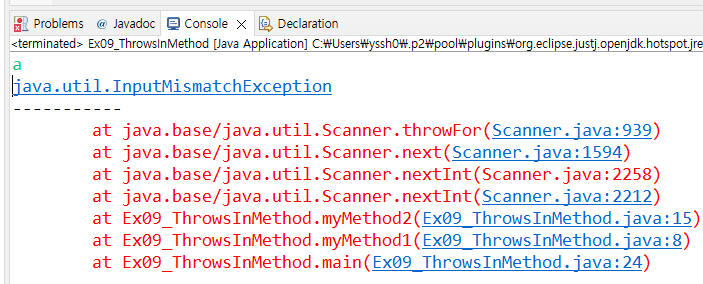
여기서 실행한 뒤 콘솔창에 문자 a를 입력하면 당연히 문자로 10을 나눌 수 없기에 잘못된 입력값을 나타내는 예외인 InputMismatchException이 발생하고
또한 0을 넣으면 수학적 계산 오류로 ArithmeticException 예외가 발생하기에 myMethod2 메소드 옆에 throws 예약어와 함께 해당되는 2개의 예외 클래스들을 적어놓았다.
그러면 이 myMethod2 메소드를 부른 쪽에서 예외 처리가 되어야 하는 셈인데, myMethod2 메소드를 부른것은 myMethod1 메소드이고 여기서 예외 처리가 안되어 있기에 예외는 또 다시 넘겨저 myMethod1을 부른 메소드인 main 메소드에 예외 처리가 넘겨지게 된다.
main 메소드에서는 try-catch문이 있기에 여기서 예외 처리가 확실히 되며 (만약 try-catch문이 없었다면 최종적으로는 자바 가상 실행 환경인 JVM이 처리하며 이는 즉 프로그램의 비정상 종료를 의미한다)
catch 구문을 타서 (ArithmeticException 혹은 InputMismatchException 명시 되어있어서 가능) e.printStackTrace 메소드를 타서 예외 원인 및 전체 로그들이 콘솔에 출력되고 "-----------"이 같이 출력되면서 프로그램이 종료된다.
이처럼 throws와 발생 가능한 해당 예외 클래스를 사용하면 예외 처리를 미룰 수 있는데 왜 이러냐면, 만약 해당 메서드가 공통적으로 사용하는 스태틱 메서드이고 해당 메서드를 여러 프로그램이 가져다 쓰게 된다면 프로그램마다 예외 발생 또한 천차만별일거기에 해당 메서드가 예외를 처리하는게 아닌, 가져다 쓰는 프로그램 즉, 클래스나 메서드에서 예외 처리를 적절하게 해줘야 합리적이기 때문이다.
또한, 기본적으로는 throws를 통한 예외 처리 미루기를 할때는 보통 런타임 에러(실행 예외)는 적지 않고 (적는다고 해서 오류가 나타나지는 않지만) 보통 반드시 처리해줘야하는 컴파일 에러(일반 예외)를 적는다.
덧붙이자면 예외가 여러개 발생할것이 확실시 되는 경우 확실하게 처리해야하는 예외들을 처리하기 위해 catch문을 여러개 써서 다중 예외 처리를 이용해 아래처럼 할 수도 있다:
try {
...
} catch (예외 1 e) {
...
} catch (예외 2 e) {
...
}
.
.
.
catch(Exception e) { // 반드시 마지막에 위치해야함!!
...
}여기서 중요한것이 최상위 클래스인 Exception 클래스를 사용한 catch 구문은 반드시 제일 아래에 있어야 하는데 그 이유는 해당 Exception 클래스가 담긴 catch 구문이 위로 갈 경우 그 catch문이 모든 예외를 다 처리해버리기 때문에 다른 아래에 있는 예외 처리 catch 구문에서 예외 정보를 받을 e 객체가 없어져서 맞게 예외가 발생해도 해당 예외를 적절하게 처리하지 못하기 때문이다.
그래서 반드시 Exception 클래스가 담긴 catch 구문은 제일 아래에 있어야 한다.
추가적으로, 아래 코드문처럼 throw를 사용해 예외를 강제로 발생시키는것도 가능하다:
throw new 예외 클래스명();거기다가 프로그램에 맞춰 예외를 커스텀해 만드는 사용자 정의 예외 처리방법도 있는데, 방금 알아본 throw를 사용해 예외를 강제로 발생시키는 코드문과 연결해 아래처럼 작성해보고 실행해보자:
먼저, 개발자가 직접 사용할 예외 클래스를 아래처럼 만들어야 한다.
package exception;
public class IDFormatException extends Exception{
public IDFormatException(String message){
super(message);
}
}예외 클래스들 중 최상위 클래스 Exception 클래스를 상속받아서 쓰면 되는데 중요한 것은 해당 사용자 정의 클래스의 생성자의 매개변수로 문자열을 받고 그것을 super 예약어로 Exception 클래스 생성자를 불러오면서 매개변수로 넣어야 한다.
Exception 클래스가 미리 생성자, 멤버 변수, 메소드 등 예외 처리에 관한 전반적인 기능들은 모두 갖추고 있으므로 생성자 실행시 받는 매개변수는 자동적으로 예외 메세지로 치환되어
나중에 getMessage 메소드로 실행하면 매개변수로 받았던 해당 예외 메세지가 콘솔로 출력된다.
여기서 이제 해당 예외 클래스를 사용하기 위해 아래와 같은 예제 코드들을 작성하여 실행한다:
package exception;
public class IDFormatTest {
private String userID;
public String getUserID(){
return userID;
}
public void setUserID(String userID) throws IDFormatException{
if(userID == null){
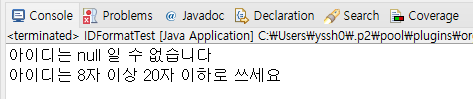
throw new IDFormatException("아이디는 null 일 수 없습니다");
}
else if( userID.length() < 8 || userID.length() > 20){
throw new IDFormatException("아이디는 8자 이상 20자 이하로 쓰세요");
}
this.userID = userID;
}
public static void main(String[] args) {
IDFormatTest test = new IDFormatTest();
String userID = null;
try {
test.setUserID(userID);
} catch (IDFormatException e) {
System.out.println(e.getMessage());
}
userID = "1234567";
try {
test.setUserID(userID);
} catch (IDFormatException e) {
System.out.println(e.getMessage());
}
}
}아이디 검증을 하는 프로그램을 만든다고 가정하고 그 아이디가 null이거나 8자 이하거나 20자 초과일때 예외가 발생해 사용자에게 경고문을 띄우도록 한다고 한다면 아마 위와 같은 코드로 될것이다.
정확히는 아이디 검증을 담당하는 클래스에 throws + 아까 만든 사용자 정의 예외 클래스인 IDFormatException를 붙이고 세터 메소드인 setUserID를 통해 담기는 아이디 값이 만약 null이라면 throw new IDFormatException("아이디는 null 일 수 없습니다");가 실행되어 매개변수 전달과 함께 예외가 의도적으로 발생하며,
만약 아이디가 8자 이하거나 20자 초과일때는 throw new IDFormatException("아이디는 8자 이상 20자 이하로 쓰세요");가 실행되어 매개변수 전달과 함께 예외가 의도적으로 발생하여
main 메소드의 catch문을 건드려 매개변수로 받은 메세지를 출력하는 e.getMessage 메소드를 각각 상황에 맞춰 실행하게 될것이다. (아래처럼 말이다)
여기까지가 예외 처리에 관한 내용이었는데 예외 처리는 프로그램 마무리로써 정말 중요하며 로그와 함께 같이 해야하는 요소이기도 하다. (보통 예상되는 예외를 미리 처리하거나 아니면 발견된 예외를 처리하기 위해선 로그를 필수적으로 사용해야하기 때문이다)
그래서 로그를 남기도록 꼭 예외 처리 부분에서 로그를 남기는 코드 (e.printStackTrace(), e.getMessage(), System.out.println(e)...)를 많이 사용함은 물론
그렇게 나온 로그를 통해 처리해야할 예외에 대해서도 알 수 있기 때문이다.
3. 입출력 클래스(InputStream/OutputStream)
이제 입출력 스트림 클래스에 대해 알아볼 차례이다. 자바 또한 여타 프로그램과 같이 입력과 출력이 가능하도록 짜여져 있는데 이때 입출력 스트림을 사용한다.
(다만, 주의해야할것은 1번에서 배웠던 스트림과는 다른 의미의 용어이기에 그래서 입출력 스트림이라고 부른다)
여기서의 (입출력) 스트림은 네트워크에서 온 것으로 자료 흐름이 물의 흐름과 같다고 해서 온 이름이다.
이런 입출력은 다양한 장치 즉, 파일 메모리 같은 기본적인 장치에서부터 키보드 마우스 모니터 네트워크 등등 여러가지 입출력 장치의 상호 활동으로 발생한다.
자바는 이런 다양한 장치에 맞춰서 다양하게 입출력 방법을 구현하는게 아니라 입출력 장치와 무관하게 스트림 클래스라는 일관적인 방법으로 모든 입출력을 지원한다.
이런 입출력 스트림에도 유형별로 3가지로 나눌 수 있는데, 첫번째는 입력/출력 스트림이다.
입력 스트림: 자료를 입력해서 기록하는 스트림
출력 스트림: 입력된 자료를 출력하는 스트림
보통 스트림 이름이 InputStream이나 Reader로 끝나는 클래스는 입력 스트림 클래스이고, OutputStream이나 Writer로 끝나는 클래스는 출력 스트림 클래스이다.
(FileInputStream, FileReader, BufferedInputStream, BufferedReader 등 <- 입력 스트림)
(FileOutputStream, FileWriter, BufferedOutputStream, BufferedWriter 등 <- 출력 스트림)
두번째는 바이트 단위 스트림과 문자 단위 스트림이다.
일반적으로 자바는 바이트 단위로 자료를 읽고 출력하는데 동영상이나 그림 음악 같은 경우는 그런 바이트 단위로 써도 되지만,
문자 같은 경우는 char형으로 2바이트 형식이기에 1바이트로 읽어내는 바이트 형식은 글자가 깨져버린다.
그래서 별도로 문자 단위 스트림을 자바는 제공하고 있다.
바이트 단위 스트림: 동영상, 그림, 음악 바이트 단위 자료 대상 스트림
문자 단위 스트림: 문자에 특화된 스트림
이름이 Stream으로 끝나는 경우는 바이트 단위, Reader나 Writer로 끝나는 경우는 문자 단위이다.
(FileInputStream, FileOutputStream, BufferedInputStream, BufferedOutputStream <- 바이트 스트림)
(FileReader, FileWriter, BufferedReader, BufferedWriter <- 문자 스트림)
마지막으로 세번째는 기반 스트림과 보조 스트림이다.
기반 스트림: 자료에 직접 연결되어 그것을 읽거나 출력하는 스트림
보조 스트림: 직접 읽거나 쓰는 기능은 없으나 기반 스트림 혹은 또다른 보조 스트림에 연결되어 부가 기능을 제공하는 스트림
(FileInputStream, FileOutputStream, FileReader, FileWriter <- 기반 스트림)
(BufferedInputStream, BufferedOutputStream, BufferedReader, BufferedWriter <- 보조 스트림)
+) 여기서 잠깐 알아가는 자바 표준 입출력
자바 표준 입출력은 지금까지 우리가 썼던 콘솔 입출력 즉, 출력은 System.out/입력은 System.in을 사용한것인데
(빨갛게 에러 표시로 나오는 System.err까지 포함하면 3개)
정확히는 out, in, err 모두 정적 변수이며 System은 클래스이고 out은 static PrintStream, in은 static InputStream, err는 static OutputStream 자료형을 띈다.
그 중 배우지 않은 System.in 사용 방법을 아래와 같은 코드로 알아보겠다:
package stream.inputstream;
import java.io.IOException;
public class SystemInTest {
public static void main(String[] args) {
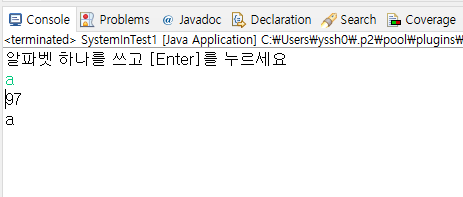
System.out.println("알파벳 하나를 쓰고 [Enter]를 누르세요");
int i;
try {
i = System.in.read();
System.out.println(i);
System.out.println((char)i);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
(입출력의 경우 혹여나 발생할 예외는 IOException이기에 try-catch문에 catch 매개변수로 IOException을 넣어주었다)
입력의 경우 System.in.read() 메소드로 콘솔에서 입력받는것이 가능한데, 자료형이 바이트 단위 (Stream)이고 1바이트만 읽어올 수 있으며 반환하는 값은 정수형 int로 반환한다. (즉, 1바이트 = 128개의 영어문자 + 특수문자 + 숫자 형식의 아스키 코드로 치환됨)
a를 입력했다고 했을때 그래서 read() 메소드 그대로 받은 것을 콘솔에 출력하면 ( System.out.println(i) ) 그에 대응하는 아스키 코드 값인 97이 나오고 문자형 char로 강제 변환하면 ( System.out.println((char)i) ) 입력한 a 그대로 나오는것이다.
여기에 엔터까지 해서 쭉 문자를 이어서 받고 싶다면 아래와 같이 변경하면 된다:
package stream.inputstream;
import java.io.IOException;
public class SystemInTest {
public static void main(String[] args) {
System.out.println("알파벳 여러 개를 쓰고 [Enter]를 누르세요");
int i;
try {
while( (i = System.in.read()) != '\n' ) {
System.out.print((char)i);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
엔터의 경우 \r (CR, Carriage Return 커서를 다시 앞으로 이동)과 \n (LF, Line Feed 줄바꿈)이 같이 붙은 의미이므로 while문 안에서 System.in.read()로 읽어서 넣은 i가 문자 '\n'이 아닐때까지만,
(즉, 엔터인 부분 또한 read 메소드로 긁어올때 실제로 아스키 코드로 치환되기에, 즉 /r CR은 13과 /n LF는 10에 매칭된다)
문자형 char로 강제 형변환해서 출력한다.
이렇게 System.in.read()외에도 주목할만한 입력 클래스는 Scanner 클래스가 있다.
Scanner는 다양한 소스를 받아 자료를 읽어들이는 클래스로 콘솔 화면에서부터 파일, 문자열도 매개변수로 받아 객체 생성이 가능하다.
( 생성자 => Scanner(File source)/Scanner(InputStream source)/Scanner(String source) )
그래서 Scanner (<- 클래스명) scanner (<- 객체명) = new Scanner(System.in) (<- new 생성자(매개변수로 콘솔 입력 변수인 System.in))식으로 콘솔 입력한 값을 Scanner 클래스 객체로 받아 아래의 메소드들로 입력한 값의 특성에 맞춰 끌어와 자바안에서 처리를 할 수 있다:
boolean nextBoolean(): boolean 자료를 읽습니다.
byte nextByte(): 한 바이트 자료를 읽습니다.
short nextShort(): short형 자료를 읽습니다.
int nextInt(): int형 자료를 읽습니다.
long nextLong(): long형 자료를 읽습니다.
float nextFloat(): float형 자료를 읽습니다.
double nextDouble(): double형 자료를 읽습니다.
String nextLine(): 문자열 String을 읽습니다.
한번 아래 예시를 통해 알아보자:
package stream.others;
import java.util.Scanner;
public class ScannerTest {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("이름:");
String name = scanner.nextLine();
System.out.println("직업:");
String job = scanner.nextLine();
System.out.println("사번:");
int num = scanner.nextInt();
System.out.println(name);
System.out.println(job);
System.out.println(num);
}
}
Scanner 클래스의 scanner 객체에 new Scanner(System.in)으로 새로이 만든 스캐너 객체(그런데 콘솔 입력 System.in 베이스인)가 담기게 되고,
이러면 콘솔에 입력받은 값이 scanner 객체에 들어가 다양한 자료형으로 변환되어 자바에서 처리가 가능해진다.
그래서 첫 2개인 이름과 직업을 scanner.nextLine()으로 받아 각각 String name과 String job으로 대입, 마지막 사번은 숫자 번호이기에 scanner.nextInt()로 받아 int num으로 대입한뒤 콘솔에 그대로 출력한다.
이처럼, 콘솔 입력을 Scanner 클래스 객체로 받으면 자바 자료형 내로 치환하여 여러 처리가 가능해진다.
+) next()와 nextInt(), nextLine()의 차이
사실은 Scanner 클래스의 메소드가 또 하나 더 있는데, 그건 next()이다.
next()는 nextLine()처럼 소스로부터 자료를 읽고 그것을 문자열 String로 반환하는것인데,
엔터(/r/n)에 대해 next() 포함 나머지 next 메소드들은 엔터를 무시하고 (인식x) nextLine()은 그것을 인식해 개행문자로써 첫 내용부터 그 개행문자 전까지의 내용을 한줄씩 입력받는다는것이다.
즉, 만약 콘솔에 10을 치고 엔터를 쳤다고 했을때 콘솔로부터 입력을 받고 그 입력값이 임시로 저장되는 공간인 버퍼에는 10/r/n이 있는데 첫 10은 nextInt()로 받게되고 (엔터를 분리자로서 그 전까지의 것만을 입력값으로 인식함), 코드상 다음에 바로 nextLine()이 있다고 했을때 (그리고 이것이 코드상 입력값을 받는 마지막 줄이라고 했을때) 10 다음 입력값은 받아야하는데 받지도 못하고 바로 프로그램이 종료되는 현상이 발생한다.
왜냐하면, 10은 nextInt()로 받고 나면 버퍼에는 오직 엔터만이 남는데 nextLine()으로 이걸 받아버리면 nextLine()은 이 엔터를 개행문자로 제대로 인식을 하고 버퍼 안 첫줄부터 이 엔터값을 포함해 입력값이자 개행문자를 종료값으로 알기 때문에 다음 입력값이 그냥 엔터인줄 알고 받고 프로그램을 종료시켜버리는것이다.(분리자로 인식하지 않고 엔터 또한 입력값으로 포함해서 인식)
즉, 코드상으로는 이런 느낌이다:
//콘솔에 10 엔터 입력
int i = scanner.nextInt(); //i에는 10이 담김, 버퍼엔 엔터만 남음
String s = scanner.nextLine(); //s에는 버퍼에 남아있던 엔터가 담김
//모든 입력값을 받았으니 입력 단계 종료
즉, nextLine으로 다음 입력값을 제대로 받지 못하는 이런 문제에 대해서는 여러가지 해결책이 있긴한데 첫번째로는 위의 예시에서 nextInt() 다음에 nextLine()을 한번 더 쓰거나, 두번째로는 nextInt() 부분을 nextLine으로 바꿔서 일단 엔터까지 다 받고 Integer.parseInt()로 int 자료형으로 변환하거나, 아니면 세번째로 스캐너 객체를 각각 따로하는 방법이 있다. (또 아니면 nextLine을 쓰지 않고 next를 쓰거나)
그렇기 때문에 엔터로 입력값을 종료받는 일반적인 상황에서 nextLine()을 쓸때는 반드시 앞에 nextLine()이 있는지 체크하고 그게 아니라면 보통 nextLine()을 한번 더 쓰면 좋다.
덧붙여, next()는 또한 공백(tab/space)을 분리자이자 종료값으로 인식하지만 입력값에는 넣지는 않는다.
여기까지가 Scanner 클래스 였고 Console 클래스도 있지만 이클립스에서는 호환이 안되기에 패스하고 이제 본격적으로 입출력 스트림 중 바이트 단위로 읽는, InputStream/OutputStream 클래스를 이용한 데이터 입출력을 알아보겠다.
1) 바이트 단위 파일 대상 입출력 스트림 InputStream/OutputStream
전에 말했었지만 간단히 말하자면 입력 스트림은 어떤 외부 소스에서 자료를 읽고 자바에 입력하여 옮기는 스트림을 뜻하고, 출력 스트림은 자바에서 외부로 자료를 써서 출력하는 스트림으로 보면 된다.
그 중 InputStream과 OutputStream은 추상 클래스로서 이를 상속받은 하위 클래스들이 각각의 스트림을 만드는데, 일단 아래 OutputStream 예제를 보면서 이해해보자:
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
public class Ex01_FileWrite1
{
public static void main(String[] args) throws IOException
{
OutputStream out = new FileOutputStream("data.txt");
out.write(65); // ASCII 코드 65 = 'A'
out.close();
}
}기본적으로 입출력 스트림이기에 입출력 예외인 IOException이 throws로 예외처리가 되어있고,
스트림 객체 out 객체를 생성하기 위해 new FileOutputStream 생성자를 사용, (FileOutputStream 클래스는 OutputStream 클래스를 상속받음) 그 매개변수로 문자열로 된 파일 경로 "data.txt"를 넣었다.
(앞에 다른 경로 없이 "파일명.확장자"인 경우 이때의 물리적 경로는 해당 자바 프로그램이 위치한 프로젝트 폴더가 된다.)
그리고 write 메소드를 사용하면서 65 숫자를 매개변수로 넣어 65를 한 바이트로 출력하게 되고 close 메소드로 사용한 스트림을 닫아준다.
이 코드를 실행하면, 아래 사진처럼 프로젝트 폴더내에 data.txt가 자동으로 생기고 그 안 내용에 65에 해당하는 아스키 코드 치환 문자, 대문자 A가 적혀져 있다.

여기서 두가지 내용을 알 수 있는데 첫째는 OutputStream이 추상 클래스인 만큼, 스스로 객체를 생성할 수 없기에 상속받은 하위 클래스의 생성자를 이용해 스트림 객체를 생성하고 생성할때도 매개변수로 경로를 넣어 출력한 파일이 어디에 위치할지 지정히 가능하다는 것이다.
둘째는 write 메소드에 매개변수로 숫자 (정확히는 int형)을 넣으면 바이트 단위로 읽어 자동으로 아스키 코드로 치환한다는것이며 스트림 객체는 사용이 끝나면 close 메소드로 닫아줘야 한다는것이다.
첫번째 클래스 관계에서 자세하게 보자면, OutputStream은 바이트 단위로 출력하는 스트림 중 최상위 클래스이자 추상 클래스로 아래 클래스들을 상속받은 하위 클래스들로 가지고 있다.
FileOutputStream : 바이트 단위로 파일에 자료를 씁니다.
ByteArrayOutputStream : 바이트 배열에 바이트 단위로 자료를 씁니다.
FilterOutputStream : 기반 스트림에서 자료를 쓸때 추가 기능을 제공하는 보조 스트림의 상위 클래스입니다.
또한 객체 생성할때 쓰는 생성자와 매개변수 조합들도 FileOutputStream에 한해서 아래와 같다:
FileOutputStream(String name) : 파일 이름 name(경로 포함)을 매개변수로 받아 해당 경로로 파일이 없으면 파일을 생성하고 출력 스트림을 생성한다.
FileOutputStream(String name, boolean append) : 해당 name 경로 + 피일이름으로 출력 스트림을 생성하는데 append 값이 true면 해당 파일을 닫고 다시 생성해서 다른 내용을 출력했을때 전에 했었던 것에 이어서 출력한다. 디폴트 값은 false다.
FileOutputStream(File f) : File 클래스 객체 f의 정보로 출력 스트림을 생성한다.
FileOutputStream(File f, boolean append) : File 클래스 객체 f의 정보로 출력 스트림을 생성하는데, append 값이 true면 해당 파일을 닫고 다시 생성해서 다른 내용을 출력했을때 전에 했었던 것에 이어서 출력한다. 디폴트 값은 false다.
그리고 다음 2번째 write, close 메소드들을 포함해 OutputStream에서 쓸 수 있는 메소드들이 바로 아래 목록들이다:
void write(int b) : 한 바이트를 출력합니다.
void write(byte[] b) : b 배열에 있는 자료들을 출력합니다.
void write(byte[] b, int off, int len) : b 배열에 있는 자료들의 off 인덱스 위치부터 len 개수만큼 자료를 출력합니다.
void flush() : 출력을 위해 잠시 자료가 머무르는 출력 버퍼를 강제로 비워서 내보내 자료를 출력합니다.
void close() : 출력 스트림과 연결된 대상 리소스를 닫습니다. 출력 버퍼가 지워집니다. (FileOutputStream인 경우 파일 닫음)
일단 OutputStream에 대해서 개략적으로는 이 정도 클래스 구조와 생성자 매개변수 법칙 그리고 메소드 사용법만 알고 가면 되고 위에 했던 예제를 예외를 직접 처리하는 try-catch문과 try 매개변수로 준 객체를 close 메소드 없이 자동으로 리소스 닫기를 해주는 try-with-resources으로 변형하면 다음과 같다:
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
public class Ex02_FileWrite2
{
public static void main(String[] args)
{
OutputStream out = null;
try
{
out = new FileOutputStream("data.txt");
out.write(65); // ASCII 코드 65 = 'A'
//out.close();
}
catch (IOException e)
{
}
finally
{
if (out != null)
{
try
{
out.close();
}
catch (IOException e2)
{
}
}
}
}
}import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
public class Ex03_FileWrite3
{
public static void main(String[] args)
{
try (OutputStream out = new FileOutputStream("data.txt"))
{
out.write(65); // ASCII 코드 65 = 'A'
}
catch(IOException e)
{
e.printStackTrace();
}
}
}여기서 더 나아가서 바이트 배열 byte[ ]로 출력해보는건 아래와 같다:
package stream.outputstream;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileOutputStreamTest2 {
public static void main(String[] args) throws IOException {
FileOutputStream fos = new FileOutputStream("output2.txt",true);
try(fos){ //java 9 부터 제공되는 기능, 향상된 try-with-resources 문법
byte[] bs = new byte[26];
byte data = 65; //'A' 의 아스키 값
for(int i = 0; i < bs.length; i++){ // A-Z 까지 배열에 넣기
bs[i] = data;
data++;
}
fos.write(bs); //배열 한꺼번에 출력하기
}catch(IOException e) {
e.printStackTrace();
}
System.out.println("출력이 완료되었습니다.");
}
}바이트 자료형 배열 기반으로 26개의 공간을 만들어 객체 bs를 생성하고 바이트 자료형 data는 65를 대입받고 이걸 bs의 길이만큼 돌리면서 data 값을 bs의 0번부터 끝까지 넣는데 한번 돌릴때마다 data가 1씩 늘어나면서 한다.
그리고 마지막으로 그렇게 입력받은 값이 모두 담긴 바이트 배열 bs를 write 메소드의 매개변수로 넣으면 배열 안 값들이 처음 객체 생성했을때 매개변수로 받았단 경로 + 파일명.확장자명에 모두 출력된다. 그리고 두번째 매개변수로 true로 넣었기에 계속 실행하면 전에 출력했던 내용 끝에서 계속 이어서 쓰게 된다. (아래 사진처럼 말이다.)

여기서 덧붙이자면 write 메소드 안에 매개변수로 2와 10을 두번째 및 세번째 매개변수로 넣으면 배열의 인덱스 번호 2번부터 10개를 출력한다는 의미이므로 여기서의 결과는 아마 CDEFGHIJKL로 출력된다.
또한, flush 메소드는 write 메소드로 썼던 출력 내용들을 담는 출력 버퍼의 내용들을 강제로 출력되게 하고 버퍼를 비우는 메소드인데, 원래 write 메소드를 한다고 해도 바로 바로 출력되는게 아니라 출력 버퍼에 어느정도 용량이 쌓이면 출력되는 방식이라 자료의 양이 많지 않으면 write 메소드로 출력이 되지 않는 경우가 있다. 그래서 그때 필요한 것이 flush 메소드이며 비록 close 메소드가 실행되면 flush 메소드도 실행되지만 명확하게 하기 위해 flush 메소드를 하고 close 메소드를 실행하는것이 좋다.
이제 입력 스트림으로 넘어가서 InputStream에 대해 알아보자.
위에서 했었던 data.txt를 재사용해서 해보면 다음과 같다:
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class Ex04_FileRead
{
public static void main(String[] args)
{
try (InputStream in = new FileInputStream("data.txt"))
{
int dat = in.read();
System.out.println(dat);
System.out.printf("%c \n", dat);
}
catch(IOException e)
{
e.printStackTrace();
}
}
}
이제 입력 스트림은 반대로 파일의 내용을 읽어내어 자바에서 처리하는것으로 위처럼 data.txt에 담겨 있던 내용(A)을 read 메소드로 읽어 내어 int형 dat으로 치환후 그 dat을 그대로 출력하면 1바이트만 읽기에 아스키 코드 표 기준 A에 해당하는 숫자 65로 출력되고 이것을 printf 메소드에서 %c로 한 문자 char 자료형으로 변환하면 A로 출력된다.
일단, OutputStream과 마찬가지로 InputStream 또한 입력 스트림 최상위 클래스이자 추상 클래스로 상속받아 실제로 쓰이는 하위 클래스들은 다음과 같다:
FileInputStream : 바이트 단위로 파일에서 자료를 읽어냅니다.
ByteArrayInputStream : 바이트 배열에 바이트 단위로 자료를 읽어냅니다.
FilterInputStream : 기반 스트림에서 자료를 읽을때 추가 기능을 제공하는 보조 스트림의 상위 클래스입니다.
또한 생성자와 매개변수 조합은 FileInputStream에 한해서 다음과 같다:
FileInputStream(String name) : 파일 이름 name(경로 포함)을 매개변수로 받아 해당 경로로 파일이 없으면 파일을 생성하고 입력 스트림을 생성한다.
FileInputStream(File f) : File 클래스 객체 f의 정보로 입력 스트림을 생성한다.
그리고 InputStream에서 쓸 수 있는 메소드들은 다음과 같다:
int read() : 입력 스트림으로부터 한 바이트 자료를 읽습니다. 읽은 자료의 바이트 값을 반환합니다.
int read(byte[] b) : 입력 스트림으로부터 배열 b 크기만큼의 자료를 읽어 b 배열에 순차적으로 값을 넣습니다. 읽은 자료의 총 바이트 자료 개수를 반환합니다.
int read(byte[] b, int off, int len) : 입력 스트림으로부터 배열 b 크기만큼의 자료를 읽고 b의 인덱스 번호 off부터 len 개수만큼 순차적으로 값을 넣습니다. 읽은 자료의 총 바이트 자료 개수를 반환합니다.
void close() : 입력 스트림과 연결된 대상 리소스를 닫습니다. (FileInputStream인 경우 파일 닫음)
여기서 중요한건, 입력 스트림의 메소드의 경우 반환값이 있고 그것이 int형인데 만약 읽은 값이 있다면은 상관없지만 해당 자료안에 읽을 값이 아예 없어 읽지 못한 경우 이때 read 메소드는 반환값으로 -1을 내뱉는다.
(그래서 보통 System.in.read()도 그렇고 여기 InputStream도 그렇고 read() != -1을 조건으로 while문을 돌려 자료안에 적힌 값들의 끝까지 뽑아내 입력 스트림을 처리하는 경우가 많다)
또 중요한건, 입력 스트림의 대상이자 읽어올 자료가 미리 준비되어있지 않으면 해당 입력 스트림을 사용한 코드는 예외가 발생하게 되는데, 자세히는 읽어올 자료를 찾을 수 없다는FileNotFoundException과 이 때문에 스트림 객체가 아예 생성되지 않아 만약 close 메소드가 실행되면 스트림 객체가 null이기에 close 메소드를 실행할 수 없는 NullPointerException이 발생한다.
그러니 꼭, 입력 스트림의 경우 읽어올 자료가 있는지 꼭 확인하고 실행하자.
마지막으로 바이트 배열 기준으로 파일을 끝까지 읽고 해당 바이트 배열에 넣는 아래 예제를 보면서 입력 스트림을 마무리를 지어보자:
package stream.inputstream;
import java.io.FileInputStream;
public class FileInputStreamTest4 {
public static void main(String[] args) {
try(FileInputStream fis = new FileInputStream("input2.txt")){
//input2.txt안에는 대문자 A부터 Z까지 알파펫 26개 값이 있음
//input2.txt를 읽는 try-with-resources 구문 close 메소드 x
byte[] bs = new byte[10];
//바이트 배열 10 크기 생성 bs
int i;
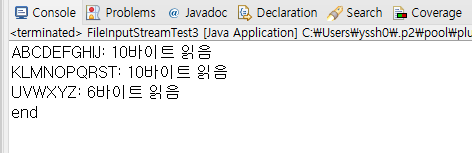
while ( (i = fis.read(bs, 0, 10)) != -1){
//bs 인덱스 번호 0부터 10개 while 반복문 실행하는데
//더이상 자료가 없을때 까지 i가 -1 읽는다.
//read로 읽어낸 값들은 모두 bs에 순차적으로 담긴다.
//i는 read로 읽어낸 총 바이트 자료 개수가 담긴다.
/*for(byte b : bs){
System.out.print((char)b);
}*/
//위 코드는 bs 배열에서
//10개씩 뽑아낸 것을 단순히 for 향상문으로 출력만 함
//이런 경우 마지막 출력이 UVWXYZ에서 끝나는게 아니라
//이전에 담겼던 QRST까지 출력된다.
for(int k= 0; k<i; k++){
System.out.print((char)bs[k]);
}
//하지만 위의 for문은 int형 k를 0으로 두고
//read로 읽어낸 총 바이트 자료 개수인 i 바로 전까지 for문 돌리면
//바이트 배열 bs에 그때 그때 담긴 자료까지만(UVWXYZ) 출력하는 셈이 된다.
//10 + 10 + 6 = 26개의 알파벳 마지막만 6개 출력
System.out.println(": " +i + "바이트 읽음" );
}
}catch (Exception e) {
e.printStackTrace();
}
System.out.println("end");
}
}
2) 문자 단위 스트림 Reader/Writer
이제는 문자 단위 스트림인 Reader와 Writer 차례이다. 먼저 Reader 클래스부터 보면 아래 하위 클래스들을 가지고 있다:
FileReader : 파일에서 문자 단위로 읽는 스트림 클래스이다.
InputStreamReader : 바이트 단위로 읽은 자료를 문자로 변환해주는 보조 스트림 클래스이다.
BufferedReader : 문자로 읽을 때 배열을 제공하여 한꺼번에 읽을 수 있는 기능을 제공해주는 보조 스트림이다.
메소드들은 아래와 같다:
int read() : 파일로부터 한 문자를 읽습니다. 읽은 값을 반환합니다.
int read(char[] buf) : 파일로부터 buf 배열에 문자를 읽습니다.
int read(char[] buf, int off, int len) : 파일로부터 buf 배열의 off 인덱스 위치부터 len 개수만큼 문자를 읽습니다.
void close() : 스트림과 연결된 리소스를 닫습니다.
일단 하위 클래스들 중 많이 사용하는 FileReader부터 알아보자.
생성자와 매개변수 조합은 다음과 같다:
FileReader(String name) : 파일 이름 name을 경로 포함해서 매개변수로 받아 입력 스트림 객체를 생성합니다.
FileReader(File f) : File 클래스 정보를 매개변수로 받아 입력 스트림을 생성합니다.
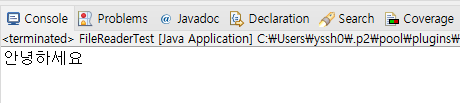
이제 "안녕하세요"가 써있는 reader.txt를 FileReader로 읽는 예제를 아래에서 보자:
package stream.reader;
import java.io.FileReader;
import java.io.IOException;
public class FileReaderTest {
public static void main(String[] args) {
try(FileReader fr = new FileReader("reader.txt")){
int i;
while( (i = fr.read()) != -1){
System.out.print((char)i);
}
}catch (IOException e) {
e.printStackTrace();
}
}
}
만약 여기서 FileReader가 아닌 아래 FileInputStream으로 읽는다면 결과가 어떻게 나올까?
package stream.reader;
import java.io.FileInputStream;
import java.io.IOException;
public class FileInputStreamTest2 {
public static void main(String[] args) throws IOException {
FileInputStream fis = null;
fis = new FileInputStream("reader.txt");
int i;
while ( (i = fis.read()) != -1){
System.out.print((char)i);
}
fis.close();
System.out.println("end");
}
}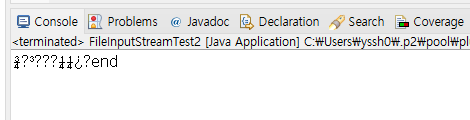
한글에 해당하는 바이트 값이 없어 (아스키 코드 x) 글자가 깨져서 결과가 출력되었다. 이래서 한글같은 문자를 처리할때에는 문자 단위 스트림인 Reader, 그 중 파일에 관해선 FileReader를 써야한다.
그러면 다음 Writer 클래스에 대해 알아보기 위해 먼저 아래 하위 클래스부터 설명을 보자:
FileWriter : 파일에 문자 단위로 출력하는 스트림 클래스이다.
OutputStreamWrtier : 파일에 바이트 단위로 출력한 자료를 문자로 변환해주는 보조 스트림이다.
BufferedWriter : 문자로 쓸 때 배열을 제공하여 한꺼번에 쓸 수 있는 기능을 제공해주는 보조 스트림이다.
다음은 메소드들이다:
void write(int c) : c값에 해당하는 한 문자를 출력합니다.
void write(char[] buf) : 문자 배열 buf의 내용을 파일에 출력합니다.
void write(char[] buf, int off, int len) : 문자 배열 buf에서 off 인덱스 위치부터 len 개수만큼 파일에 출력합니다.
void write(String str) : 문자열 str을 파일에 출력합니다.
void write(String str, int off, int len) : 문자열 str의 off번째 문자부터 len 개수만큼 파일에 출력합니다.
void flush() : 파일을 출력하기 전에 자료가 있는 임시 공간(출력 버퍼)을 비워 강제 출력합니다.
void close(): 파일과 연결된 스트림을 닫습니다. 출력 버퍼도 비워집니다.
FileWriter에 대해 볼텐데 마찬가지로 파일이 없으면 자동적으로 파일을 생성한다. 아래는 생성자와 매개변수 조합이다:
FileWriter(String name) : 파일 이름 name을 경로 포함해서 매개변수로 받아 출력 스트림을 생성한다.
FileWriter(String name, boolean append) : 파일 이름 name을 경로 포함해서 매개변수로 받아 출력 스트림을 생성하는데, append 값이 true면 파일 스트림을 닫고 다시 쓰면 파일 내용 끝에 이어서 출력된다. 디폴트 값은 false이다.
FileWriter(File f) : 파일 클래스 f의 정보를 매개변수로 받아 출력 스트림을 생성한다.
FileWriter(File f, boolean append) : 파일 클래스 f의 정보를 매개변수로 받아 출력 스트림을 생성하는데, append 값이 true면 파일 스트림을 닫고 다시 쓰면 파일 내용 끝에 이어서 출력된다. 디폴트 값은 false이다.
아래 예제로 이제 FileWriter 사용법을 익혀보자:
package stream.writer;
import java.io.FileWriter;
import java.io.IOException;
public class FileWriterTest {
public static void main(String[] args) {
try(FileWriter fw = new FileWriter("writer.txt")){
fw.write('A'); // 문자 하나 출력
char buf[] = {'B','C','D','E','F','G'};
fw.write(buf); //문자 배열 출력
fw.write("안녕하세요. 잘 써지네요"); //String 출력
fw.write(buf, 1, 2); //문자 배열의 일부 출력
fw.write("65"); //숫자를 그대로 출력
}catch(IOException e) {
e.printStackTrace();
}
System.out.println("출력이 완료되었습니다.");
}
}

문자 하나도, 배열도, String 문자열도, 쌍따옴표로 숫자를 문자열로 넣은것도 잘 출력되는것을 확인할 수 있다.
3) 보조 스트림
보조 스트림은 지금까지 봐왔던 스트림들과 달리 파일이나 네트워크에 직접 자료를 쓰거나 출력하는 기능은 없다, 다만 그런 스트림에 보조 기능을 추가하는게 보조 스트림이다.
보통 해당 보조 스트림의 생성자의 매개변수로 입출력을 담당하는 기반 스트림이 들어가면서 보조 스트림 자신이 감싸고 있는 기반 스트림에 보조적인 기능을 추가하는 형식이다.
(그래서 또 다른 이름으로는 Wrapper 스트림이라고 불리기도 한다)
(1) 보조 스트림 최상위 클래스 FilterInputStream, FilterOutputStream
일단, FilterInputStream과 FilterOutputStream이 보조 스트림들의 최상위 클래스로 알려져 있으며 다른 말로는 모든 보조 스트림은 이 해당 스트림들을 각각 상속받는다.
그래서 생성자와 매개변수의 조합은 다음과 같다:
protected FilterInputStream(InputStream in) : 생성자의 매개변수로 InputStream in을 받습니다.
protected FilterOutputStream(OutputStream out) : 생성자의 매개변수로 OutputStream out을 받습니다.
위의 두 보조 스트림은 이 생성자외에는 다른 생성자가 없다. 그렇기에 이 두 보조 스트림을 상속받은 보조 스트림 하위 클래스들은 똑같이 매개변수로 어떤 스트림을 받아야 한다.
다만, 여기서 중요한게 기반 스트림만 매개변수로 받는게 아니라 보조 스트림을 매개변수로도 받을 수 있다. 그런데, 조건은 매개변수로 오는 보조 스트림이 기반 스트림을 품고 있어야 한다는것이다.
예를 들어 아래와 같은 경우가 있을 수 있다는 것이다:
바이트 단위 파일 입력 스트림 + 문자로 변환 기능 추가 보조 스트림 + 버퍼링 추가 보조 스트림
(2) 바이트 단위 자료를 문자로 InputStreamReader, OutputStreamReader
우리가 위에서 보았단 자바 표준 콘솔 입출력 System.in이라던지 네트워크나 인터넷 쪽으로 오는 자료들은 보통 바이트 단위인 InputStream과 OutputStream으로 다루는 경우가 많다.
그런데 이것을 그대로 표현하면은 한글과 같은 영어 외의 문자들은 깨지기 마련이기에 이런 문자들을 위해 바이트 자료를 문자 단위 스트림으로 입출력을 해줘야 하는데 그 보조 기능을 하는것이 InputStreamReader와 OutputStreamReader이다.
일단 InputStreamReader 생성자 및 매개변수 조합은 아래와 같다:
InputStreamReader(InputStream in) : InputStream 객체 in을 매개변수로 받아 Reader 객체를 생성한다.
InputStreamReader(InputStream in, Charset cs) : InputStream in과 Charset 클래스 (외부 자료와 내부 프로그램간 문자 인코딩 타입 차이가 날때 이것을 호환되게 해주는 클래스) cs를 매개변수로 받아 Reader 객체를 생성한다.
InputStreamReader(InputStream in, CharsetDecoder dec) : InputStream과 CharsetDecoder(문자 인코딩 디코딩 클래스, 외부 자료를 어떻게 변환해서 자바에 옮길지 결정)를 매개변수로 받아 Reader를 생성한다.
InputStreamReader(InputStream in, String charsetName) : InputStream과 String 문자세트이름을 매개변수로 받아 Reader를 생성한다.
이렇듯 InputStreamReader는 기반 스트림인 InputStream 자체와 문자 인코딩/디코딩을 어떻게 할건지 결정하는 문자세트(Charset)를 매개변수로 받아 Reader 객체를 형성한다.
(문자 세트를 지정하지 않을 경우 시스템이 기본으로 사용하고 있는 문자 세트로 외부 자료 문자 인코딩/디코딩을 결정해 Reader에 반영한다)
(문자 세트는 각 문자가 가지는 고유 값이 어떤 값으로 이뤄져있는지 결정하는 표준으로 자바의 경우 대표적으로 UTF-16 문자 세트가 있는데 이것은 우리가 알고 있는 유니코드를 나타내는 문자 세트들 중 하나이다)
그럼 InputStreamReader를 어떻게 사용하는지 아래 예제로 확인하자:
package stream.decorator;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
public class InputStreamReaderTest {
public static void main(String[] args) {
try(InputStreamReader isr = new InputStreamReader(new FileInputStream("reader.txt"))){
int i;
while( (i = isr.read()) != -1){ //보조 스트림으로 읽습니다.
System.out.print((char)i);
}
}catch(IOException e) {
e.printStackTrace();
}
}
}
원래는 FileReader 클래스 형태로 읽어도 되지만 설명을 위해 일부러 FileInputStream으로 하고 그 마지막을 InputStreamReader로 보조 기능을 추가하는 형태로 한 것이다.
그리고 위에서 말했다시피 콘솔 입력인 System.in이나 네트워크 인터넷으로 오는 자료들이 영어가 아닌 한글 같은 다른 문자를 포함할때 InputStreamReader로 해야한다고 했는데, 보통 System.in은 Scanner 클래스로 이 작업을 간편하게 대체하므로 잘 쓰지는 않고 주로 네트워크나 인터넷으로 있는 외부 소스들이 바이트 단위로 처리할때가 많아서 이때 주로 쓰인다.
(예를 들면 한글을 포함한 다중 문자를 쓰는 채팅 프로그램과 같은 경우)
(3) Buffered 스트림
이름에 버퍼가 들어가있는 만큼 임시공간을 활용해 빠른 처리시간을 보장하는 버피링 기능을 추가하는 보조 스트림이 Buffered 스트림이다.
Buffered 스트림은 내부적으로 8,192 바이트 크기의 배열을 가지고 있으며 이 배열을 추가해 기존 기반 스트림에 빠른 입출력을 가능하게끔 한다.
해당 기능을 제공하는 Buffered 스트림들은 아래와 같다:
BufferedInputStream : 바이트 단위로 읽는 스트림에 버퍼링 기능을 추가합니다.
BufferedOutputStream : 바이트 단위로 출력하는 스트림에 버퍼링 기능을 추가합니다.
BufferedReader : 문자 단위로 읽는 스트림에 버퍼링 기능을 제공합니다.
BufferedWriter : 문자 단위로 출력하는 스트림에 버퍼링 기능을 제공합니다.
이런 Buffered 스트림도 역시 매개변수로 기반/보조 스트림을 품는다. BufferedInputStream의 형식은 아래와 같다:
BufferedInputStream(InputStream in) : InputStream 클래스를 생성자의 매개변수로 받아 BufferedInputStream 객체를 생성한다.
BufferedInputStream(InputStream in, int size) : InputStream과 버퍼 크기 size를 생성자의 매개변수로 받아 BufferedInputStream 객체를 생성한다.
나머지 BufferedOutputStream, BufferedReader와 BufferedWriter 또한 각각 맞게 OutputStream/Reader/Writer를 생성자의 매개변수로 받는다.
Buffered 스트림의 빠른 입출력을 확인하기 위해 바이트 단위로 처리하는 FileInputStream과 FileOutputStream 그리고 BufferedInputStream과 BufferedOutputStream의 파일 복사를 서로 비교해보겠다. 약 5MB 파일인 a.zip 파일을 copy.zip으로 복사하는 예제를 아래에서 보자:
(FileInputStream, FileOutputStream의 경우)
package stream.decorator;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileCopyTest {
public static void main(String[] args) {
long millisecond = 0;
try(FileInputStream fis = new FileInputStream("a.zip");
FileOutputStream fos = new FileOutputStream("copy.zip")){
millisecond = System.currentTimeMillis();
int i;
while( ( i = fis.read()) != -1){
fos.write(i);
}
millisecond = System.currentTimeMillis() - millisecond;
}catch(IOException e) {
e.printStackTrace();
}
System.out.println("파일 복사 하는 데 " + millisecond + " milliseconds 소요되었습니다.");
}
}
바이트 단위로 5MB 파일을 복사하는데 총 25초가 걸렸다. 즉, 한 바이트씩 InputStream, OutputStream 객체로 i에 담고 서로 교환하고 처리하는데 그 정도의 시간이 걸렸다는것이고 여러 바이트를 한꺼번에 읽어서 하는것보다 오래 걸렸다는 의미이다.
그리고 아래 보조 스트림인 BufferedInputStream, BufferedOutputStream을 사용한 예제를 보자:
package stream.decorator;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class BufferedStreamTest {
public static void main(String[] args) {
long millisecond = 0;
try(FileInputStream fis = new FileInputStream("a.zip");
FileOutputStream fos = new FileOutputStream("copy.zip");
BufferedInputStream bis = new BufferedInputStream(fis);
BufferedOutputStream bos = new BufferedOutputStream(fos)){
millisecond = System.currentTimeMillis();
int i;
while( ( i = bis.read()) != -1){
bos.write(i);
}
millisecond = System.currentTimeMillis() - millisecond;
}catch(IOException e) {
e.printStackTrace();
}
System.out.println("파일 복사 하는 데 " + millisecond + " milliseconds 소요되었습니다.");
}
}
보시다시피 try-with-resources 구문의 try 매개변수에 추가적으로 BufferedInputStream과 BufferedOutputStream이 들어갔지만, 파일을 복사하는데 걸리는 시간은 20초도, 10초도, 5초도, 1초도 아닌 약 0.071초가 걸렸다.
Buffered 스트림은 멤버 변수로 8,192 바이트 배열을 가지고 있으므로 한번 자료를 읽을때 약 8kb씩 자료를 읽을 수 있기에 1킬로바이트인 한 바이트 씩 읽는 바이트 단위 스트림보다 파일을 빠르게 읽고 출력할 수 있다. 또한, 배열 크기는 생성자의 두번째 매개변수로 조절이 가능하다.
여기서 더 나아가서 아까 말한 채팅 프로그램의 일환으로 소켓 통신을 바탕으로 스트림과 함께 만든다고 가정할때, 아래와 같이 바이트 단위 입출력 + 문자 단위 입출력 + 버퍼링 기능 추가로 스트림을 강화해서 코드를 짤 수 있다.
Socket socket = new Socket(); //자바에서 소켓 통신 클래스 Socket
BufferedReader br = new BufferedReader(new InputStreamReader(socket.getInputStream()));
BufferedWriter wr = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
//(4) 메모리에 저장된 값을 0과 1로 읽는 DataInputStream/DataOutputStream
DataStream 클래스는 메모리에 저장된 0과 1로 읽기에 자료형의 크기가 그대로 보존된다.
생성자와 매개변수 조합은 아래와 같다:
DataInputStream(InputStream in) : InputStream을 생성자 매개변수로 삼아 DataInputStream을 생성한다.
DataOutputStream(OutputStream out) : OutputStream을 생성자 매개변수로 삼아 DataOutputStream을 생성한다.
DataInputStream 클래스는 아래와 같은 메소드들을 제공한다:
Byte readByte() : 1바이트를 읽어 반환한다.
boolean readBoolean() : 읽은 자료가 0이 아니면 true를, 0이면 false를 반환한다.
char readChar() : 한 문자를 읽어 반환한다.
short readShort() : 2바이트를 읽어 정수값을 반환한다.
int readInt() : 4바이트를 읽어 정수값을 반환한다.
long readLong() : 8바이트를 읽어 정수값을 반환한다.
float readFloat() : 4바이트를 읽어 실수값을 반환한다.
double readDouble() : 8바이트를 읽어 실수값을 반환한다.
String readUTF() : 수정된 UTF-8 인코딩 기반으로 문자열을 읽어 반환한다.
DataOutputStream 또한 위의 read 메소드들에 대응되는 write 메소드들을 아래처럼 가지고 있다:
void writeByte(int i) : 1 바이트로 int형 i값을 출력합니다.
void writeBoolean(boolean b) : 1 바이트로 boolean형 b값을 출력합니다.
void writeChar(int i) : 2 바이트로 int형 i값을 char 형으로 출력합니다.
void writeShort(int i) : 2 바이트로 int형 i값을 short 형으로 출력합니다.
void writeInt(int i) : 4 바이트로 int형 i값을 int 형으로 출력합니다.
void writeLong(long l) : 8 바이트로 Long형 ㅣ값을 long 형으로 출력합니다.
void writeFloat(float v) : 4 바이트로 float형 v값을 float 형으로 출력합니다.
void writeDouble(double v) : 8 바이트로 Double형 v값을 Double 형으로 출력합니다.
void writeUTF(String str) : 수정된 UTF-8 인코딩 기반으로 문자열을 출력합니다.
이렇게 기본 구조에 대해 보았고 가장 주의해야할 점은 자료를 쓴(출력한) 순서대로 자료를 읽어오는것(입력하는것)도 맞춰야 한다는것이다. 즉, 처음에 자료를 writeByte 메소드를 사용해서 바이트로 했다면 자료를 읽어서 입력할때도 바이트 단위인 readByte 메소드를 사용해야한다는것이다. 여러 값을 다양한 자료형으로 썼을 경우 순서도 맞춰야 함은 물론이다.
일단 아래 예제를 통해 알아보자:
package stream.decorator;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class DataStreamTest {
public static void main(String[] args) {
try(FileOutputStream fos = new FileOutputStream("data.txt");
DataOutputStream dos = new DataOutputStream(fos))
{
dos.writeByte(100);
dos.writeChar('A');
dos.writeInt(10);
dos.writeFloat(3.14f);
dos.writeUTF("Test");
}catch(IOException e) {
e.printStackTrace();
}
try(FileInputStream fis = new FileInputStream("data.txt");
DataInputStream dis = new DataInputStream(fis))
{
System.out.println(dis.readByte());
System.out.println(dis.readChar());
System.out.println(dis.readInt());
System.out.println(dis.readFloat());
System.out.println(dis.readUTF());
}catch (IOException e) {
e.printStackTrace();
}
}
}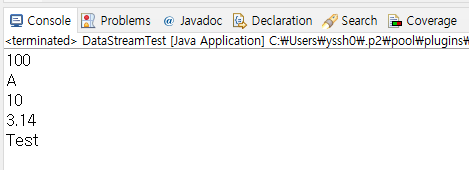
바이트로 썼던 100, char 문자형으로 썼던 A, int형으로 썼던 10, 실수 float형으로 썼던 3.14, UTF-8로 썼던 문자열 Test에 맞춰 각각 read 메소드들을 순서대로 한 결과 모두 콘솔에
잘 출력됨을 알 수 있다.
이처럼 DataStream은 한 파일이나 네트워크 외부 소스에 여러 자료형을 넣고서 손실 없이 입력하고 출력할때 유용하게 쓸 수 있는 보조 스트림이다.
이제 보조 스트림을 정리하자면, 보조 스트림은 기반 스트림은 물론 다른 보조 스트림에도 붙어 유동적이고 효율적으로 기능을 추가하거나 제거할 수 있는 클래스이다. 이러한 구조를 코드 디자인 패턴에서는 데코레이터 패턴이라고 부른다. 즉, 자바의 입출력 스트림 클래스 구조는 데코레이터 패턴이라고 보면 된다. 보조로 추가 기능을 제공하는 클래스와 실제 역할을 하는 클래스가 나뉘어진 구조이다. 여기서 보조로 추가 기능을 제공하는 클래스, 보조 스트림 클래스를 데코레이터(Decorator, 장식자)라고 부른다.
4) 직렬화
클래스를 사용하게 되면 해당 인스턴스를 사용할때마다 안의 멤버변수 값이 계속 변하는 일이 많을 것이다. 그런데 가끔 네트워크로 딱 그때의 해당 인스턴스 상태를 저장하거나 전송해야할 일이 종종 있다. 이런 작업을 직렬화(Serialization)이라고 하며 저장된 내용이나 전송받은 내용을 다시 인스턴스로 되돌리는, 직렬화의 반대를 역직렬화(Deserialization)이라고 한다.
이 과정에서 인스턴스의 내용을 파일로 저장하거나 네트워크로 전송하는 과정이 필수이기에 즉, 인스턴스 전체를 연속 스트림화한다고 보면 된다. 정확히는 인스턴스 변수 값을 스트림으로 만들어야 하는데, 이는 보조 스트림 중 하나인 ObjectInputStream과 ObjectOutputStream으로 하면 된다.
아래는 두 스트림의 생성자 및 매개변수 조합이다.
ObjectInputStream(InputStream in) : InputStream을 생성자의 매개변수로 받아 ObjectInputStream을 생성합니다.
ObjectOutputStream(OutputStream out) : OutputStream을 생성자의 매개변수로 받아 ObjectOutputStream을 생성합니다.
이제 설명을 위해서 Person 클래스를 하나 만들고 이것을 인스턴스화 한뒤 파일에 써서 직렬화를 했다가 다시 인스턴스로 복원하는 역직렬화를 해보겠다. 이 과정에서 생기는 파일 이름은 serial.out이다
그리고 직렬화의 의미는 인스턴스의 내용이 파일이나 네트워크를 통해 외부로 유출된다는 의미이기에 직렬화 의도를 클래스에 표시해야한다. 그래서 Person 클래스를 Implements로 Serializable 해주어야 한다.
(이때 이 java.io.Serializable 인터페이스는 추상 메서드가 아예 없고 단순히 직렬화 의미를 표시하는 인터페이스이기에 마커 인터페이스 marker interface라고 불린다):
package stream.serialization;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
class Person implements Serializable{
private static final long serialVersionUID = -1503252402544036183L;
//버전 관리를 위한 고유 아이디 번호, 선언하지 않으면 JVM에서 디폴트로 자동으로 생성
//하지만 선언하지 않으면 이클립스에서 워닝을 보내므로 어차피 선언후 사용할것
String name;
String job;
public Person() {}
public Person(String name, String job) {
this.name = name;
this.job = job;
}
public String toString()
{
return name + "," + job;
}
}
public class SerializationTest {
public static void main(String[] args) throws ClassNotFoundException {
Person personAhn = new Person("안재용", "대표이사");
Person personKim = new Person("김철수", "상무이사");
try(FileOutputStream fos = new FileOutputStream("serial.out");
ObjectOutputStream oos = new ObjectOutputStream(fos)){
oos.writeObject(personAhn);
oos.writeObject(personKim);
//writeObject 메소드로 매개변수로 받은 인스턴스 값을
//oos를 통해 serial.out에 출력
}catch(IOException e) {
e.printStackTrace();
}
try(FileInputStream fis = new FileInputStream("serial.out");
ObjectInputStream ois = new ObjectInputStream(fis)){
Person p1 = (Person)ois.readObject();
Person p2 = (Person)ois.readObject();
//ois의 serial.out 파일 정보를 기반으로 readObject 메소드 실행
//저장된 인스턴스 값 정보 불러와서 p1, p2에 각각 입력
System.out.println(p1);
System.out.println(p2);
}catch (IOException e) {
e.printStackTrace();
}
}
}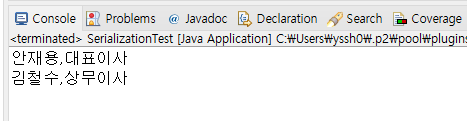
위 사진처럼 미리 정해놓은 인스턴스 객체안 값을 정상적으로 파일로 저장하고 또 다시 불러와서 콘솔에 출력하는것까지 잘 되는 모습을 확인할 수 있다.
(참고로 에디터로 열어보면 아래와 같이 텍스트로는 확인할 수 없는 값으로 저장된다.)

여기서 인스턴스 안의 변수 값들 중 만약 저장되면 안되는 값이 있다거나 직렬화하고 싶지 않는 클래스가 있다면 transient 예약어를 사용하면 된다. (복원할때도 복원이 안된다.) 아래처럼 클래스 Person 중 job만 transient를 해보고 다시 실행해보자:
String name;
transient String job;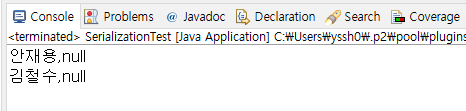
그러면 위 사진처럼 job 부분이 String 자료형의 기본값, null로 저장되었음을 알 수 있다.
그리고 serialVersionUID에 관한 사항인데 직렬화를 하고 난 뒤 클래스가 변경되면 역직렬화를 할 수 없다. 왜냐하면, 직렬화할때 자동으로 serialVersionUID로 클래스 버전 정보가 기록되는데 클래스가 수정되거나 변경되면 내부적으로 serialVesrionUID 또한 변경되기 때문이다. 이렇게 serialVesrionUID가 서로 맞지 않으면 클래스 버전이 맞지 않는다고 오류를 발생시킨다.
이를 해결하기 위해선, 매번 클래스가 변경될때마다 새로 배포할 수는 있겠지만 너무 번거로우니까 그 방법 말고 개발자가 직접 클래스 버전 관리를 할 수 있는데 그 방법을 사용하는것이 좋다. 자바 설치 경로의 bin/serialver.exe를 실행하면 serialVersionUID가 생성되는데 (이미 선언되어있으면 선언된 번호가 나옴) 이 번호를 클래스 파일에 적어주면 된다. 아래처럼 말이다:
C:\Users\yssh0>D:
//D 드라이브로 이동
D:\>cd D:\JAVA_LAB-master\JAVA_LAB-master\Chapter15\bin
//해당 프로젝트 폴더\bin으로 cd 이동
D:\JAVA_LAB-master\JAVA_LAB-master\Chapter15\bin>serialver stream.serialization.Person
stream.serialization.Person: private static final long serialVersionUID = -1503252402544036183L;
//serialver -classpath- 입력또한 이클립스에서는 툴팁으로 자동으로 serialVersionUID를 생성해주는 add generated serial version UID 기능도 있으니 참고바란다 (아래 사진)
직렬화/역직렬화 중 마지막 부분으로 Externalizable 인터페이스가 있는데 이건 앞서 본 Serializable과 달리 프로그래머가 직접 구현해야할 메소드가 있으며 좀 더 직렬화와 역직렬화를 더 세밀하게 다듬을때 사용한다. 아래를 보자:
package stream.serialization;
import java.io.Externalizable;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInput;
import java.io.ObjectInputStream;
import java.io.ObjectOutput;
import java.io.ObjectOutputStream;
class Dog implements Externalizable{
String name;
public Dog() {}
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeUTF(name);
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
name =in.readUTF();
}
public String toString() {
return name;
}
}
public class ExternalizableTest {
public static void main(String[] args) throws IOException, ClassNotFoundException {
Dog myDog = new Dog();
myDog.name = "멍멍이";
FileOutputStream fos = new FileOutputStream("external.out");
ObjectOutputStream oos = new ObjectOutputStream(fos);
try(fos; oos){
oos.writeObject(myDog);
}catch(IOException e) {
e.printStackTrace();
}
FileInputStream fis = new FileInputStream("external.out");
ObjectInputStream ois = new ObjectInputStream(fis);
Dog dog = (Dog)ois.readObject();
System.out.println(dog);
}
}Externalizable을 사용할거면 꼭 구현해야하는 메소드 2가지, writeExternal과 readExternal 메소드가 있다. 또 복원될때 디폴트 생성자가 호출되므로 디폴트 생성자를 적어줘야 한다. (각각 메소드 안에 쓴 writeUTF/readUTF는 UTF-8로 인코딩된 문자열을 출력/입력하는 메소드이다)
5) 그 외 입출력 클래스
(1) 파일 File 클래스
File 클래스는 우리가 여태까지 배웠던 스트림의 매개체들 중 하나인 파일 자체의 경로 등 파일 정보를 담는 클래스이다. 생성자 및 매개변수 조합은 아래와 같다:
File(String pathname) : pathname을 매개변수로 받아 파일 객체를 생성합니다.
아래 예제를 통해 File 클래스가 제공하는 여러 메소드들을 보자:
package stream.others;
import java.io.File;
import java.io.IOException;
public class FileTest {
public static void main(String[] args) throws IOException {
File file = new File("D:\\easyspub\\JAVA_LAB\\Chapter15\\newFile.txt");
file.createNewFile();
System.out.println(file.isFile());
System.out.println(file.isDirectory());
System.out.println(file.getName());
System.out.println(file.getAbsolutePath());
System.out.println(file.getPath());
System.out.println(file.canRead());
System.out.println(file.canWrite());
file.delete();
}
}File 클래스 객체를 생성할때 new File 생성자 안 매개변수로 들어가는 것은 실제 파일이 위치하게될 물리적 경로이고(문자열), 이후 실제 파일을 물리적으로 생성하는 것은 createNewFile 메소드로 한다.
isFile은 실제로 그 경로에 파일이 물리적으로 있는지 확인 뒤 있으면 true를 반환하고,
isDirectory는 파일 객체 안에 저장된 경로 중 마지막 파일이 폴더인지 아닌지 확인 뒤 폴더면 true를 반환하며,
getName은 그냥 경로 빼고 마지막 파일 이름만을 반환하며, (확장자 포함)
etAbsolutePath는 실제 파일이 위치한 물리적 경로 (절대 경로, 최상위 드라이브부터 시작) 값을 반환하고,
getPath는 절대 경로가 아닌 상대 경로 (현재 본 코드가 작성된 프로그램이 실행되는 곳, .java 파일을 기준 위치로 잡고 해당 파일이 어디 위치해야하는지 상대적으로 표시한 경로, 보통 같은 위치면 파일명 아니면 ./파일명 혹은 좀 더 상위 폴더인 바깥쪽에 위치하면 ../파일명으로 표시한다) 값을 반환하며,
canRead는 그 파일 객체의 경로 값으로 실제 파일을 읽을 수 있는지 확인 뒤 가능하면 true를 반환하며,
canWrite는 그 파일 객체의 경로 값으로 실제 파일을 쓸 수 있는지 확인 뒤 가능하면 true를 반환하고,
마지막으로 delete는 실제 그 파일을 물리적으로 삭제하는 메소드이다.
+) mkdir vs mkdirs 메소드
File 클래스에는 종종 쓰이는 메소드로 2가지가 더 있는데, 그것은 mkdir과 mkdirs 메소드이다.
(약어에서 보다시피 make directory, 즉 폴더를 실제로 생성하는 메소드이다)
mkdir 메소드는 마지막에 폴더를 생성하는 경로 중 중간 빠진 디렉토리(폴더)가 하나라도 있다면 false를 반환하고 그 마지막 폴더 자체를 생성하지 않는다.
(ex: First/Second/Third가 경로인데 만약 Second 폴더가 미리 준비되어있지 않다면 mkdir은 false를 반환하고 Third 폴더를 생성하지 않는다.)
그런데 mkdirs 메소드는 중간에 빠진 디렉토리가 있더라도 자동으로 그 폴더를 생성하고 마지막 폴더까지 알아서 생성한다.
(ex: First/Second/Third가 경로인데 만약 Second 폴더가 미리 준비되어있지 않다고 하더라도 mkdirs는 true를 반환하고 Third 폴더를 생성한다.)
그래서 보통은 mkdir은 중간 폴더가 미리 준비된 상태에서만 쓰고 mkdirs를 대표적으로 더 많이 쓴다.
이처럼 이렇게 생성한 File 클래스의 객체는 FileInputStream과 같은 파일 입출력에 쓸 수 있다.
(2) RandomAccessFile 클래스
입출력 클래스 중 유일하게 파일 입출력을 동시에 할 수 있는 클래스이며 이 클래스는 파일 포인터라는것이 있어 현재 파일의 어느 위치에서 파일 입출력을 할건지 임의적으로 위치를 정할 수 있다.따로 스트림을 쓰지 않고 간단하게 파일 입출력을 할 때 쓸 수 있으며 생성자와 매개변수 조합은 아래와 같다:
RandomAccessFile(File file, String mode) : 입출력 할 File과 입출력 mode를 매개변수로 받는다. mode에는 읽기 전용인 "r"과 읽고 쓰기 기능인 "rw"를 대입할 수 있다
RandomAccessFile(String file, String mode) : 입출력 할 파일 이름을 문자열로 받으면서 입출력 mode를 매개변수로 받는다. mode에는 읽기 전용인 "r"과 읽고 쓰기 기능인 "rw"를 대입할 수 있다
그리고 RandomAccessFile 클래스는 Closeable, AutoCloseable과 DataInput, DataOutput 인터페이스를 implements해 구현해놓았으므로 DataInputStream/DataOutputStream 처럼 다양한 자료형의 값들을 입출력 할 수 있다. 아래 예제를 한번 보자:
package stream.others;
import java.io.IOException;
import java.io.RandomAccessFile;
public class RandomAccessFileTest {
public static void main(String[] args) throws IOException {
RandomAccessFile rf = new RandomAccessFile("random.txt", "rw");
rf.writeInt(100);
System.out.println("파일 포인터 위치:" + rf.getFilePointer());
rf.writeDouble(3.14);
System.out.println("파일 포인터 위치:" + rf.getFilePointer());
rf.writeUTF("안녕하세요");
System.out.println("파일 포인터 위치:" + rf.getFilePointer());
rf.seek(0);
System.out.println("파일 포인터 위치:" + rf.getFilePointer());
int i = rf.readInt();
double d = rf.readDouble();
String str = rf.readUTF();
System.out.println("파일 포인터 위치:" + rf.getFilePointer());
System.out.println(i);
System.out.println(d);
System.out.println(str);
}
}
RandomAccessFile 객체 rf를 random.txt 파일에 rw 읽고 쓰기 모드로 생성하면서 첫 값은 int형 100을 쓰고,(writeInt) 다음은 Double형 3.14를 쓰고,(writeDouble) 마지막으로 문자열을 UTF-8형태로 "안녕하세요"를 썼다.
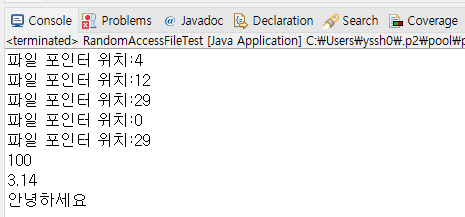
그러면서 중간 중간마다 getFilePointer메소드르 쓰고 나서의 파일 포인터 위치를 콘솔에 출력했다.
첫 값 int형 100을 쓴 다음에는 포인터 위치가 4로 이동했고, (4바이트)
두번째 Double형 3.14를 쓴 다음에는 포인터 위치가 12로 이동했으니 8만큼 더 이동했으며, (8바이트)
세번째 문자열 UTF-8 기반 "안녕하세요"를 쓴 다음에는 포인터 위치가 29로 이동했으니 17만큼 더 이동했다. (한글 3바이트 * 5글자 + NULL 공간 2바이트 = 17바이트)
일단 그렇게 random.txt에 출력한 값을 읽어오기 위해 seek 메소드에 매개변수로 0을 넣어 값을 입력 받기 전 가장 처음 위치 0바이트로 포인터 위치를 이동시켰고
이 상태에서 값을 넣었던 순서대로 readInt, readDouble, readUTF 메소드를 실행시켜 그 값들을 모아 콘솔에 출력했다.
(꼭 파일 포인터를 원하는 값 위치에 정확히 위치 시킨다음 메소드를 실행해야한다.)
여기까지 해서 참 길었지만 입출력 클래스에 관한 내용이었고 다음 마지막으로 스레드에 대해 알아보겠다.
4. 스레드
스레드를 하기 이전에 먼저 프로세스에 대한 것을 알고 가야한다. 프로세스는 지금 현재 운영체제(Operating System, OS)에서 실행되고 있는 프로그램 한 단위를 뜻한다. 그리고 엄밀히 말해서 CPU는 단 하나의 프로그램, 프로세스를 실행한다.
그런데 우리가 컴퓨터를 사용할때 이 프로그램, 프로세스를 하나만 쓰지 않고 여러개를 쓴다. (웹 브라우저도 키고 영상도 보고 게임도 하고...등등) 이처럼, 프로세스를 여러개 작동시키면서 동시에 작업을 하는 것을 멀티 태스킹 (multi-tasking)이라고 한다. (여기서의 task는 운영체제에서 작업하는 한 단위 또는 정해진 일을 수행하기 위한 코드들의 집합을 뜻하며 프로세스보다는 큰 범위를 가지고 있다)
이런 멀티 태스킹은 우리에게 CPU가 동시에 다중으로 프로세스를 동작시키게끔 보이게 한다. 그런데 그 이면에는 여러 task, process들을 빠른 시간으로 바꿔 가면서 동작시키는 것이다. 이때의 task, process들은 모두 독립적이다.
또 멀티 프로세싱(Multi-processing)이라는것도 나올 수 있는데, 멀티 프로세싱은 앞서 말한 프로세스가 아닌 프로세서(Processor) 즉, CPU가 다수 존재하여 이 다수의 프로세서가 다수의 task(process)들을 서로 같이 동시에 작업하는것을 뜻한다. 이러면 만약에 한 프로세서가 고장나도 다른 프로세서가 이미 일을 하고 있기에 작업 속도가 줄 뿐 단일 프로세서 작업처럼 작업이 멈추지는 않는다. 즉, 병렬 처리가 기본적으로 깔려있으며 원래는 옛날에 이런 멀티 프로세싱은 높은 성능과 많은 메모리가 필요한 다중 CPU를 담은 서버 컴퓨터에 많이 적용했었다.(Multi-processor) 그런데 요즘은 기술의 발전으로 멀티 코어 프로세서(Multi-core processor) 즉, CPU 하나에 연산 계산이 되는 핵심 부품이 다중으로 있는 프로세서가 대중으로 많이 보급이 되면서 여기에 코어가 멀티 프로세싱까지 하도록 적용한 컴퓨터가 많이 나오고 있다.
그리고 마지막으로 알고 가야할 멀티 프로그래밍에 대해서 알아보자면 CPU가 맡고 있는 하나의 프로세스가 입출력 과정에서 대기 시간이 걸릴때 이때 비는 유휴시간을 다른 프로세스로 돌려 CPU가 다른 프로세스로 접속해 작업을 하게끔 하는것을 뜻한다. 위에서 보았던 멀티 태스킹의 작동 방식들 중 하나이다.
이제 정말 스레드에 대해서 알아보자면, 스레드는 위에서 보았던 프로세스, 하나의 프로그램이 할당받은 자원 내에서 움직이는 하나의 흐름 단위라고 보면 된다. 그리고 스레드는 프로세스처럼 적어도 하나 이상으로 존재한다. 덧붙여 여기서 중요한것이, 프로세스는 위에서 말했듯 서로 독립된 것이기에 메모리나 데이터 또한 서로 따로 따로 할당해주어야 하는데 스레드는 해당 프로세스가 서로 동일하다면 스레드가 몇 개든간에 메모리와 데이터를 모두 공유한다. 즉, 동일한 메모리와 데이터를 사용해야한다면 아주 효율적으로 쓰일 수 있는것이 스레드이다.
여기서 스레드가 다중, 즉 하나의 프로세스안에서 데이터와 메모리를 공유하면서 다중 스레드가 작업하는것을 멀티 스레딩(Multi-threading)이라고 보면 된다.
1)스레드(thread)를 사용한 클래스 구현법
이런 스레드, 그 중 멀티 스레드의 특성을 활용한 클래스는 아래 2가지의 방법으로 가능하다:
① Runnable 인터페이스를 implements받아 구현한 클래스(run 메소드 이미 오버라이딩)를 Thread 클래스의 생성자 매개변수로 보내어 스레드 객체 생성
② Thread 클래스를 extends로 상속받아 구현한 클래스에서 run() 메소드 오버라이딩후 해당 클래스로 스레드 생성
1번 Runnable 인터페이스는 아래 예제를 한번 보자:
class MyThread3 implements Runnable
{
public void run()
{
int sum = 0;
for (int i=0; i<10; i++)
sum = sum + i;
String name = Thread.currentThread().getName();
System.out.println(name + ": " + sum);
}
}
public class Ex03_RunnableInterface1
{
public static void main(String[] args)
{
Thread t = new Thread(new MyThread3());
t.start();
System.out.println("main: " + Thread.currentThread().getName());
}
}
MyThread3 클래스에 Runnable 인터페이스를 implements해 현재 스레드의 이름 ( Thread.currentThread().getName(), 보통 스레드에 따로 이름을 지정하지 않은 경우 Thread-일련번호 형식으로 이름이 나온다 ) + ":" + 0부터 9까지 다 더한 값 sum을 콘솔에 출력하는 run 메소드를 오버라이드 시켰다.
이것을 main 메소드 (main 메소드를 돌리는 스레드가 따로 있다) 에서 자바에서 스레드를 담당하는 Thread 클래스의 생성자에 new MyThread3 생성자를 매개변수로 넣어 MyThread3 내용이 적용된 Thread 클래스 객체 t를 생성하고 start 메소드를 실행시켜 run 메소드 내용을 실행시켰다.
마지막 System.out.println의 Thread.currentThread().getName()은 프로그램 실행을 맡은 main 메소드의 스레드 이름을 콘솔에 출력한다.
여기서 결과가 왜 코드 제일 아랫줄인 main 메소드의 스레드 이름이 나왔냐면은, MyThread3으로 한 Thread 클래스 t의 경우 start 메소드를 실행할 때 약간의 준비시간이 걸리기에 동시에 실행중이던 main 메소드가 나머지 다음 라인을 실행하기 때문이다.
즉, main 메소드 단일의 보통 코드는 순차적으로 이전 코드의 결과가 나올때까지 기다리면서 실행되지만 MyThread3로 만든 스레드의 경우 main 메소드와 별개로 동시에 작동하면서 결과를 반환한다. 그리고 별개의 스레드가 다 실행되어 종료될때까지 main 메소드는 종료가 지연된다. (왜냐하면 main 메소드는 스레드(들)을 포함하는 본 프로그램의 실행과 종료를 다루고 있기 때문이다.)
다음은 2번째 방법 Thread 클래스를 extends 상속받아서 하는 방법이다:
class MyThread2 extends Thread
{
public void run()
{
int sum = 0;
for (int i=0; i<10; i++)
sum = sum + i;
String name = Thread.currentThread().getName();
System.out.println(name + ": " + sum);
}
}
public class Ex02_ThreadClass
{
public static void main(String[] args)
{
MyThread2 t = new MyThread2();
t.start();
System.out.println("main: " + Thread.currentThread().getName());
}
}결과 또한 앞서 했던 Runnable 인터페이스 implements와 같다.
람다식으로도 가능하다:
public class Ex04_RunnableInterface2
{
public static void main(String[] args)
{
Runnable task = () -> {
try
{
Thread.sleep(3000);
}
catch (Exception e) { }
int sum = 0;
for (int i=0; i<10; i++)
sum = sum + i;
String name = Thread.currentThread().getName();
System.out.println(name + ": " + sum);
};
Thread t = new Thread(task);
t.start();
System.out.println("main: " + Thread.currentThread().getName());
}
}Thread 클래스의 스태틱 메소드인 sleep 메소드는 매개변수로 받은 숫자만큼 밀리세컨드로 계산해서 본 스레드 실행을 지연시킨다. (여기서는 3000 = 3초 정도가 되겠다)
그리고 이처럼 람다식으로도 가능하다면, 그와 같은 익명클래스로도 가능하다는 의미이기도 하다.
이번에는 본격적으로 하나의 프로세스안에 여러개의 스레드를 실행시켜보겠다:
public class Ex05_MultiThread
{
public static void main(String[] args)
{
Runnable task1 = () -> {
try
{
for (int i=0; i<20; i=i+2) // 20 미만 짝수 출력
{
System.out.print(i + " ");
Thread.sleep(1000); // 1000밀리세컨드(1초) 쉼
}
}
catch(InterruptedException e) { }
//InterruptedException은 만약 스레드가 처리해야할 데이터를
//기다리고 있어서 잠시 멈춰있거나 다른 스레드의 간섭을 막는
//블록킹 메서드(sleep 메소드 포함)가 실행중이라면
//여기서 interrupt 즉, 스레드를 종료시키는 메소드를 실행하면
//InterruptedException 스레드 멈춤 예외를 발생시킨다.
};
Runnable task2 = () -> {
try
{
for (int i=9; i>0; i--) // 10 미만 수 출력
{
System.out.print("(" + i + ") ");
Thread.sleep(500); // 500밀리세컨드 쉼
}
}
catch(InterruptedException e) { }
};
Thread t1 = new Thread(task1);
Thread t2 = new Thread(task2);
t1.start();
t2.start();
}
}
Runnable 인터페이스 형태의 task1 람다식에는 for문으로 20미만의 짝수를 0부터 1씩 증가시키면서 콘솔에 출력하도록 되어있는데 여기서 각각의 값을 출력하고 나서 1초동안 스레드를 쉬는 내용이 담겨있고,
마찬가지로 똑같은 Runnable 인터페이스 형태의 task2 람다식에는 10미만의 수를 9부터 1씩 감소시키면서 콘솔에 출력하도록 되어있는데 여기서 각각의 값을 출력하고 나서 0.5초 동안 스레드를 쉬는 내용이 담겨있다.
그리고 이것을 Thread 생성자에 담아 객체를 생성하고 start 메소드를 통해 실행시키면, 위 사진처럼 출력값이 서로 무작위로 번갈아 나오는 모습을 알 수 있다.(동시 실행)
여기서 중요한것이, 다중 스레드를 실행하는것은 좋은데 그렇다면 적어도 2개 이상의 스레드가 하나의 데이터값을 가지고 연산한다면 결과가 어떻게 되냐를 생각해볼수 있는 것이다.
만약 스레드 1과 스레드 2가 있다고 가정할때, 메모리에 있는 변수 하나의 값을 위처럼 스레드 1은 증가시키고 스레드 2는 그 값을 감소 시킬때 스레드 1이 실행될때까지 스레드 2는 실행되지 않는다는 규칙이 없으면 위처럼 실행할때마다 결과값이 항상 무작위로 나올것이 분명하다. 실제로 한번 아래 예제를 보자:
public class Ex06_ProblemOfThread
{
public static int money = 0;
public static void main(String[] args) throws InterruptedException
{
Runnable task1 = () -> {
for(int i = 0; i<10000; i++)
money++;
};
Runnable task2 = () -> {
for(int i = 0; i<10000; i++)
money--;
};
Thread t1 = new Thread(task1);
Thread t2 = new Thread(task2);
t1.start();
t2.start();
t1.join(); // t1이 참조하는 스레드의 종료를 기다림
t2.join(); // t2이 참조하는 스레드의 종료를 기다림
// 스레드가 종료되면 출력을 진행함. 위 join의 영향
System.out.println(money);
}
}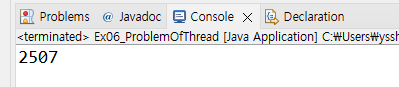
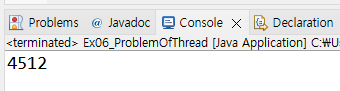

만약 money 변수 값을 스태틱 변수로 두고 그 값을 task1은 0부터 9999까지 총 10000번 동안 1씩 더하여 증가시키고 task2는 0부터 9999까지 총 10000번 동안 1씩 빼서 감소시키는 내용이고 이 두 스레드를 실행시켜서 task1과 task2가 서로 규칙적으로 번갈아 실행되면서 예상되는 값인 0을 최종 값으로 받고자 할때,
위 사진들처럼 실행할때마다 결과값이 천차만별로 달라지는데 이는 CPU 상황이나 그때 그때 스레드의 상황에 따라서 달라지는것도 있지만 스레드간의 규칙으로서 스레드가 서로 동기화가 되지 않았기 때문에 그렇다.
이처럼 만약 다중 스레드가 메모리 안에 서로 공유되는 동일한 값을 참조해서 동시에 연산한다고 할때 값을 무작위로 받지 않는 상황을 만들지 않으려면 동기화, 즉 synchronized 예약어를 사용해야한다. 방법은 아래와 같다:
public synchronized void 메소드명()
{
//동기화 대상 코드, 메소드 전체 동기화
}
//또는
public void 메소드명()
{
synchronized (공유객체)
{
//동기화 대상 코드, 코드 일부 동기화
}
}자 그러면 한번 동기화를 적용시켜서 위 예제를 다시 보자:
public class Ex07_SyncMethod
{
public static int money = 0;
public synchronized static void deposit()
{
money++;
}
public synchronized static void withdraw()
{
money--;
}
public static void main(String[] args) throws InterruptedException
{
Runnable task1 = () -> {
for (int i = 0; i<10000; i++)
deposit();
};
Runnable task2 = () -> {
for (int i = 0; i<10000; i++)
withdraw();
};
Thread t1 = new Thread(task1);
Thread t2 = new Thread(task2);
t1.start();
t2.start();
t1.join(); // t1이 참조하는 스레드의 종료를 기다림
t2.join(); // t2이 참조하는 스레드의 종료를 기다림
// 스레드가 종료되면 출력을 진행함. 위 join의 영향
System.out.println(money);
}
}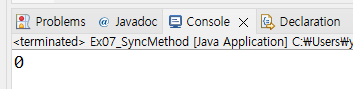
두 스레드 task1과 task2가 서로 공유하는 값인 money는 static 처리해주고 각각 사용하는 증가/감소 메소드도 deposit과 witdraw로 따로 스태틱 처리하여 코드를 간편하게 한 뒤, 이를 람다식으로 표현, 실행하면 위 사진처럼 몇 번을 실행해도 정확히 0의 값을 콘솔에 출력하게 된다.
이처럼 동기화 synchronized는 서로 다른 스레드가 같은 값을 공유하는 처리를 할 경우, 한 스레드가 끝날때까지 다른 스레드는 그 값에 간섭하지 못하게 되며 그 스레드가 실행이 완료되어야 그 다음에 비로소 처리가 가능해지도록 규칙을 정한다고 보면 된다.
다만, 이런 동기화를 남발할 경우 많은 스레드가 한 스레드가 처리될때까지 다른 스레드들은 기다려야 하는 병목현상에 걸릴 수 있으므로 조심해야한다.
일반적인 스레드 내용은 여기까지이며 그 외에도 스레드 관련해서 많은 스레드를 오버헤드 안나게 효율적으로 관리하는 스레드 풀, 스레드로부터 결과값을 반환받을 수 있는 Callable과 Future 클래스, 코드로 명시적으로 동기화 하는 ReentrantLock 클래스, 마지막으로 앞서 배웠던 컬렉션 프레임워크 동기화 방법까지 있는데 그리 중요한건 아니므로 필요하다면 다른데서 구글링으로 찾아보기를 권한다.
