공부 내용
- Gradient Descent
- Optimization 주요 컨셉
- Gradient Descent 방법
- Regularization
Gradient Descent
- 미분 가능한 함수의 극소값을 찾기 위한 1차 iterative optimization 알고리즘
Optimization 주요 컨셉
- Generalization
- Under-fitting vs over-fitting
- Cross validation
- Bias-variance tradeoff
- Bootstrapping
- Bagging and boosting
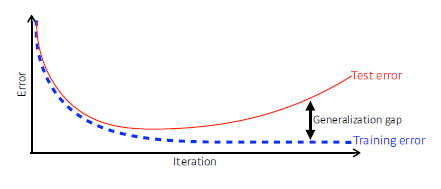
Generalization
- unseen data(test data)에 대해서 학습된 모델이 얼마나 잘 일반화 되는지
-> Test error를 최소화 하고 Generalization gap을 최소화 해야 한다.
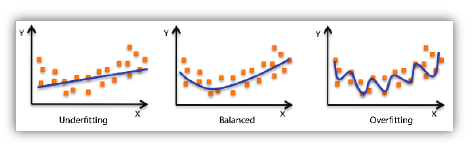
Underfitting vs Overfitting
- Overfitting
- 학습 데이터에 대해서 과도하게 학습 -> 테스트 데이터에서 잘 동작하지 않음
- Underfitting
- 네트워크가 간단하거나 학습을 조금 시켜서 학습이 잘 안된 경우 -> 학습 데이터에서도 잘 동작하지 않음
- 모델을 적절히 학습시키는 게 중요
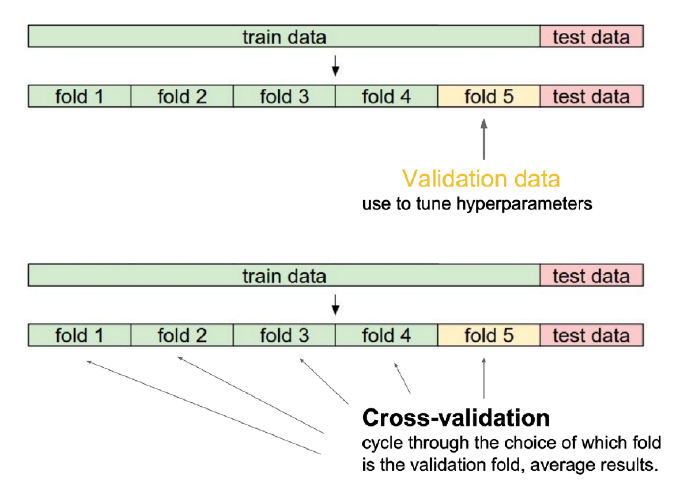
Cross-validation
- 독립 테스트 데이터로 얼마나 잘 일반화되는지 평가하기 위한 model validation 기술
- train data와 validation data를 나눔 -> validation data 기준으로 평가
- test data는 학습에 사용하면 안 됨
Bias & Variance
- Varience
- low : 비슷한 입력을 넣었을 때 출력이 일관적으로 나온다
- high : 비슷한 입력이 들어와도 출력이 많이 달라짐
- Bias
- low : true target에 가까움
- high : 원하는 target과 크게 벗어난 상태
Bias and Variance Tradeoff
-
cost는 3개의 구성 요소로 분해될 수 있다.
-
3개의 구성요소를 활용해서 cost를 최소화해야 한다.
-
구성 요소 중 하나가 줄어들면 다른 하나는 커질 수 밖에 없다.
-> noise가 많이 껴 있으면 bias나 variance를 줄이기 힘들다

Bootstrapping
- 학습 데이터에 대해서 일부만 활용해서 여러 개의 모델을 만든다.
-> 각 모델들이 예측하는 값이 얼마나 일치하는지를 보고 전체 model의 uncertainty를 예측
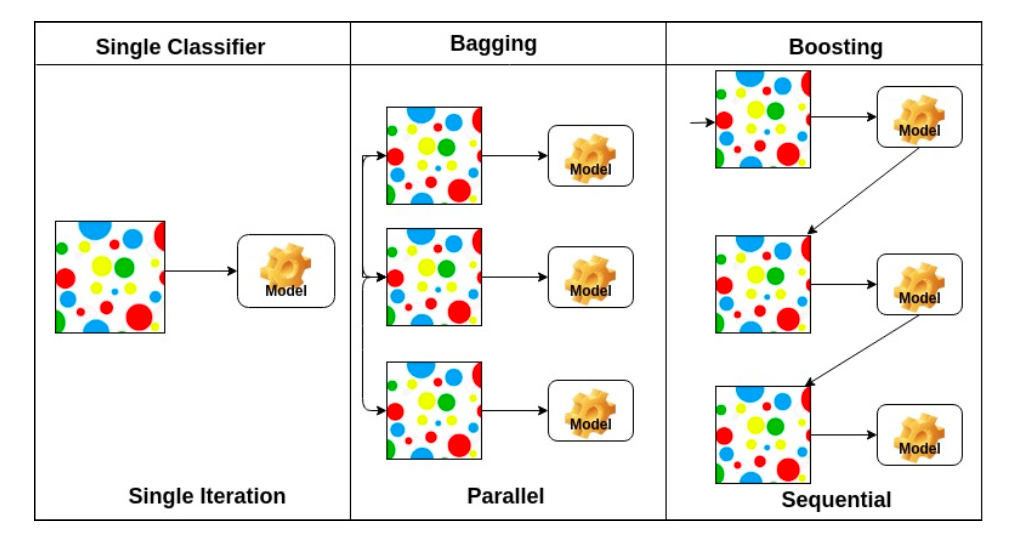
Bagging vs Boosting
Bagging (Booststrapping aggregating)
- 다수의 모델이 bootstrapping과 함께 학습
-> 학습 데이터 여러개를 만든다. - 여러 모델을 random subsampling을 통해 만들고 여러 모델의 output 평균냄
-> voting or averaging
Boosting
- 학습 데이터를 sequential하게 바라봄
- 특정 모델에서 잘 학습이 되지 않은 데이터에 대해 잘 학습되도록 모델 만든다.
- weak learner를 sequential하게 합쳐서 strong learner를 만듦
-> weak learner에서의 실수를 보완
Gradient Descent 방법
데이터 단위 별 방법
- Stochastic gradient descent
- 단일 sample로부터 계산된 gradient 업데이트
- Mini-batch gradient descent
- subset of data(mini-batch)로부터 계산된 gradient 업데이트
- Batch gradient descent
- 전체 데이터로부터 계산된 gradient 업데이트(잘 사용하지 않음)
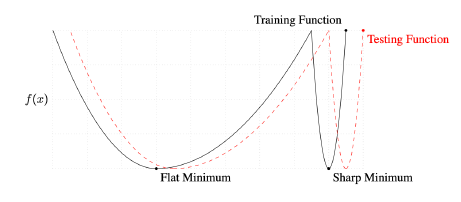
Batch-size Matters
- batch size가 크면 sharp minimizer
- batch size가 작으면 flat minimizer
- flat minimizer에 도달하는 게 더 좋음
-> generalization 성능이 높음
Optimizer 종류
- Stochastic gradeint descent(SGD)
- Momentum
- Nesterov accelerated gradient
- Adagrad
- Adadelta
- RMSprop
- Adam
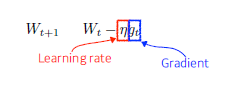
Stochastic gradient descent
- weight를 gradient와 learning rate를 곱한 만큼 빼 줌
-> 적절한 learning rate 설정 중요
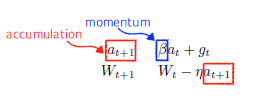
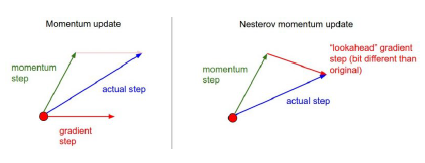
Momentum
- momentum을 활용해서 기존의 gradient를 조금 더 이어가는(활용하는) 방법
Nesterov Accelerated Gradient
- Lookahead gradient 계산
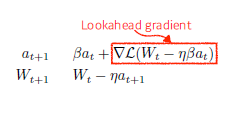
- a만큼 한번 이동 후 간 지점에서 gradient 계산해서 축적
Adagrad
- 이전까지의 파라미터의 변화 반영(Adaptive learning rate)
-> 덜 변화된 파라미터 더 많이 변화시킴 - Sum of gradient squares : 지금까지 gradient가 얼마나 많이 변했는지 제곱해서 더함
-> 아래 식에 따라 값이 커지면 분모가 커져서 더 작게 변화시킴 - Epsilon : 분모를 0으로 만들지 않기 위해 사용
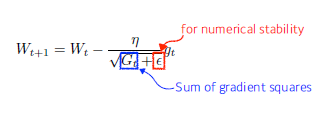
- 뒤로 가면 갈수록 G가 커지기 때문에 학습이 잘 안 된다는 문제발생
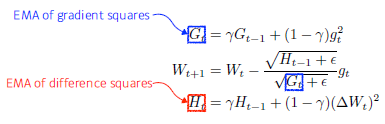
Adadelta
- Adagrad를 확장하여 accumulation window를 제한하여 학습률을 단조롭게 감소시킴
- 의 증가로 인한 학습률 감소를 막고자 활용
- learning rate가 없다는 특징 -> 잘 활용되지 않음
- Exponential moving average
- 많은 파라미터 수로 인해 GPU 터지는 것을 방지
- : Exponential moving average of gradient squares
- : Exponential moving average of difference squares
-> 실제 업데이트 하려는 weight의 변화값
RMSProp
- 논문에서 나온 방법이 아님(Geoff Hinton이 강의에서 소개)
- adaptive learning rate를 적용함
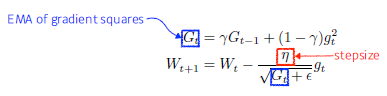
Adam
- 과거 gradient와 제곱 gradient를 모두 활용
- momentum과 adaptive learning rate 둘 다 활용

Regularization
- Early stopping
- Parameter norm penalty
- Data augmentation
- Noise robustness
- Label smoothing
- Dropout
- Batch normalization
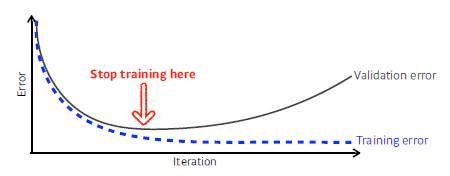
Early stopping
- Validation error가 더 이상 감소하지 않으면 훈련 멈춤
- 추가적인 validation data가 필요함
Parameter Norm Penalty
- Weight Decay라고도 함
- neural network 파라미터가 너무 커지지 않게 함
-> network weight의 숫자들이 크기 관점에서 작을수록 좋다 - neural network가 만드는 function space에서 함수를 최대한 부드럽게 하는 것
-> 함수가 부드러울수록 generalization performance가 높을 거라는 가정
Data augmentation
- 데이터는 많으면 많을수록 좋다.
-> 많으면 많을수록 deep learning의 성능은 올라간다. - 학습에 사용할 Data를 늘리는 방법
Noise Robustness
- input이나 weight에 random noise를 더함
- noise가 모델의 성능을 높여주는 효과를 가짐

Label Smoothing
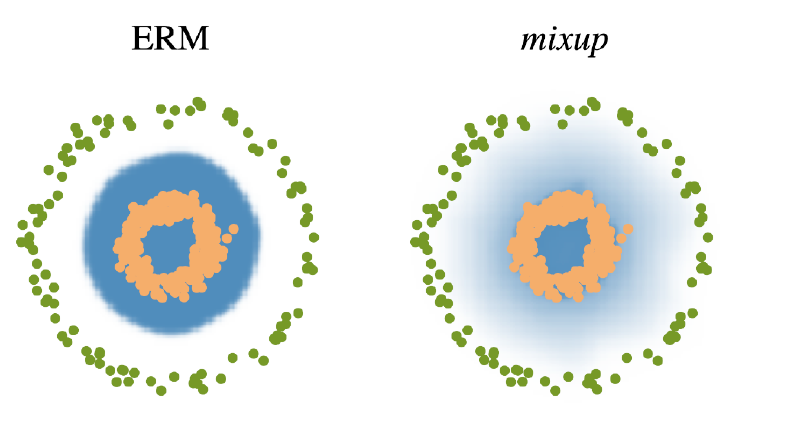
Mixup
- 학습 데이터 두개를 뽑아서 두 개를 섞어 줌
- decision boundary를 부드럽게 만들어서 분류가 잘 되게 함
- 이미지도 같이 섞어버림
Cutout
- 이미지에서 일정 영역을 빼버림
Cutmix
- 이미지를 섞을 때 각 영역에 각 라벨 이미지를 할당
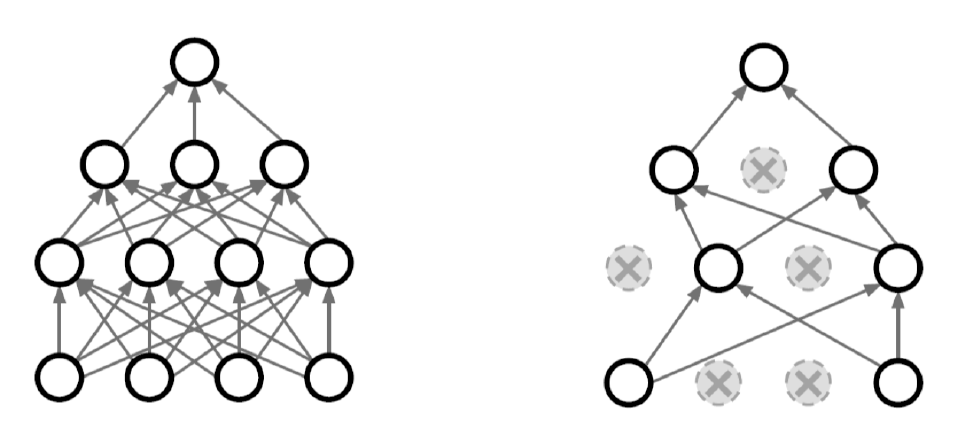
Dropout
- 각 forward pass에서 일정 비율의 neuron을 랜덤하게 0으로 설정
-> 각 neuron이 robust한 feature까지 잡을 수 있음
Batch Normalization
-
Batch Normalization은 각 계층에 대해 독립적으로 평균과 분산을 계산하고 정규화
-> internal covariant shift 줄임으로서 학습 잘 된다고 주장 -
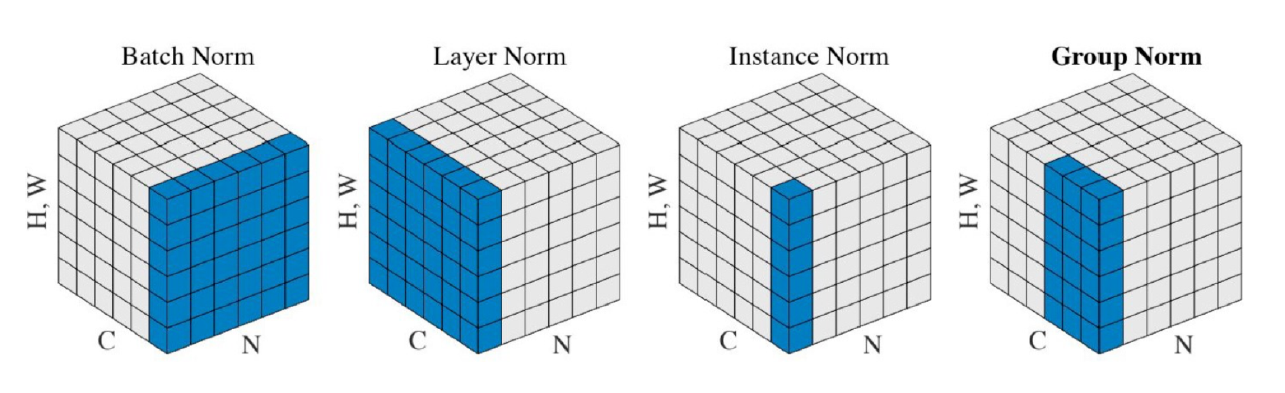
normalization에도 다양한 종류가 있다
- Batch Norm
- Layer Norm
- Instance Norm
- Group Norm
-
Batch Norm은 batch 개수(N개)의 sample normalization
-> 나머지는 1개의 sample normalization(정규화 채널 수(C)가 달라짐)