목표:
1) 영화 데이터(movie.csv)를 hadoop에 전달.
2) 실행파일(ex01.py) 생성
2) Spark의 Client모드로 Data 출력
1) movie.csv (ubuntu->hadoop)
# 디렉토리 생성
hdfs dfs -mkdir -p /spark/movie/input/
# movie.csv (ubuntu -> hadoop)
hdfs dfs -put /home/ubuntu/data/movie.csv /spark/movie/input/
# 확인
hdfs dfs -ls -R /spark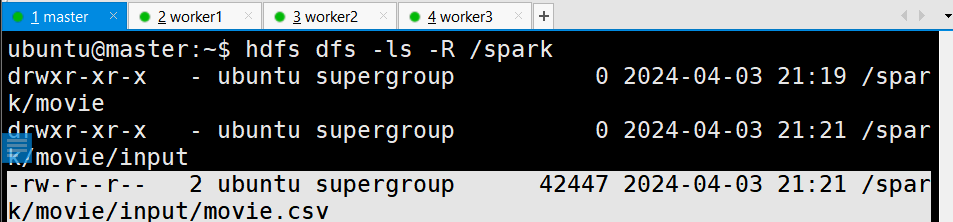
2) 실행 스크립트 생성 (pyspark_ex01.py)
cd ~/src
vim pyspark_ex01.py###############
### pyspark_ex01.py ###
###############
from pyspark.sql import SparkSession
sc = SparkSession.builder\
.master("yarn")\
.appName("PySpark Test")\
.getOrCreate()
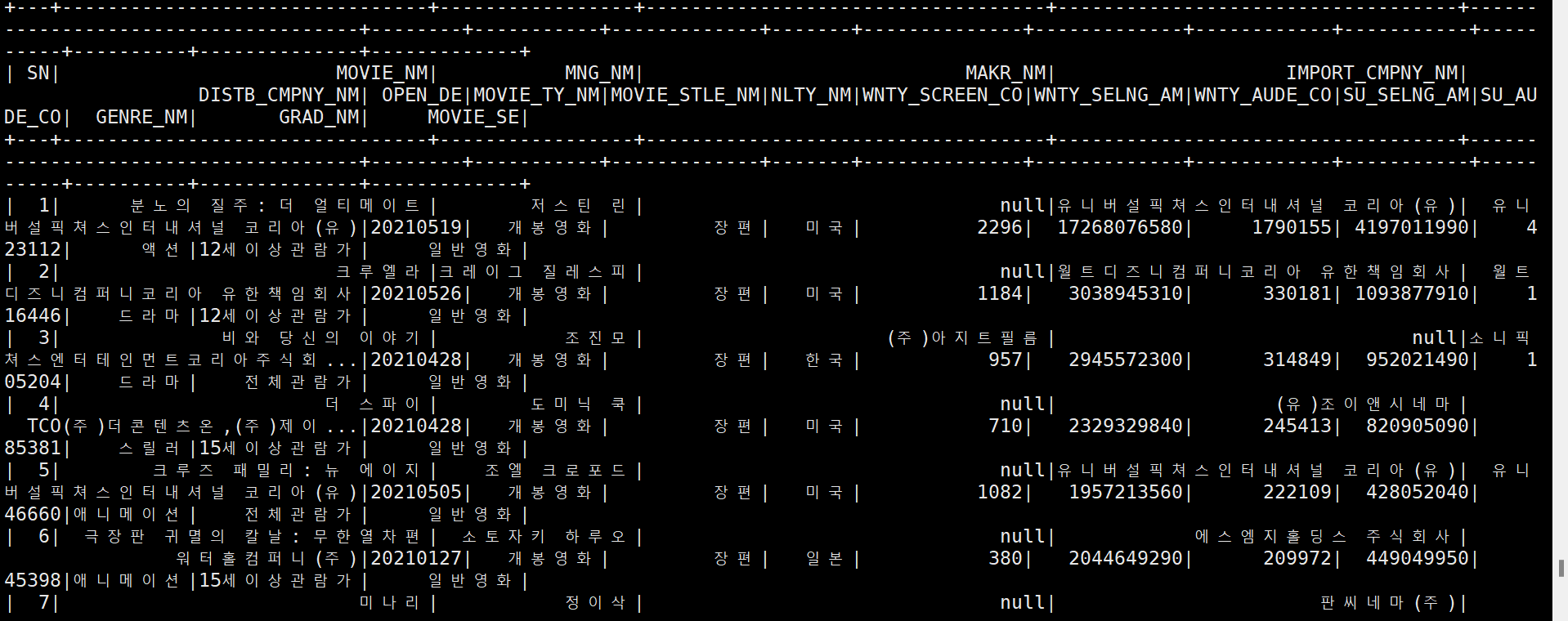
df = sc.read.csv("hdfs:///spark/movie/input/movie.csv", header=True)
df.show()3) Client Mode로 Data 출력
# cd ~/src
spark-submit --master yarn --deploy-mode client pyspark_ex01.py