Zeppelin Web UI 사용
http://127.0.0.1:18888/#/
1) Spark 객체
%spark.pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("yarn") \
.appName('SparkByExamples.com') \
.getOrCreate()
print(spark.sparkContext)
print("Spark App Name : "+ spark.sparkContext.appName)
2) emptyRDD
- spark.sparkContext.emptyRDD()
%spark.pyspark
emptyRDD = spark.sparkContext.emptyRDD()- Column Name, Dtype 지정 후 DataFrame 생성.
%spark.pyspark
from pyspark.sql.types import StructType,StructField, StringType
#Create Schema
schema = StructType([
StructField('firstname', StringType(), True),
StructField('middlename', StringType(), True),
StructField('lastname', StringType(), True)
])
#Create empty DataFrame from empty RDD
df = spark.createDataFrame(emptyRDD,schema)
df.printSchema()
df.show()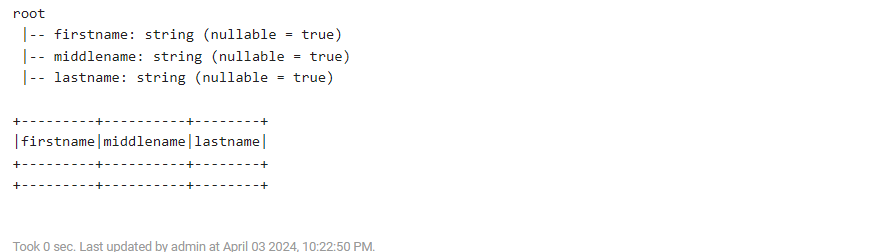
3) movie.csv 출력
%spark.pyspark
from pyspark.sql.functions import col
# Hadoop 내 movie.csv 경로
df = spark.read.csv("/spark/movie/input/movie.csv", header=True)
# Column 지정 후 출력
df.select(col("MOVIE_NM"), col("MNG_NM"), col("IMPORT_CMPNY_NM"), col("GRAD_NM")).show()
4) View 생성
%spark.pyspark
df.createOrReplaceTempView("movie")%spark.sql
# 주의: %spark.sql 사용
# SQL 쿼리처럼 사용 가능
select * from movie;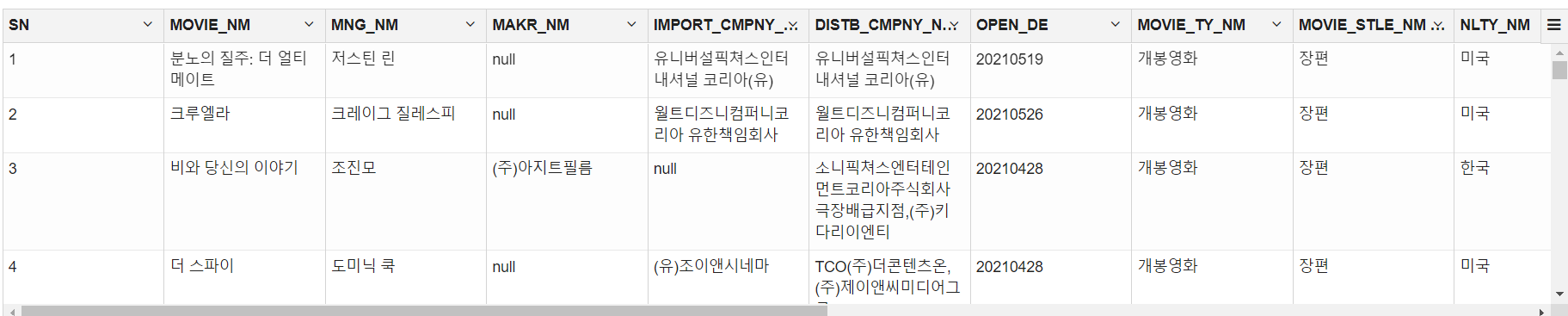
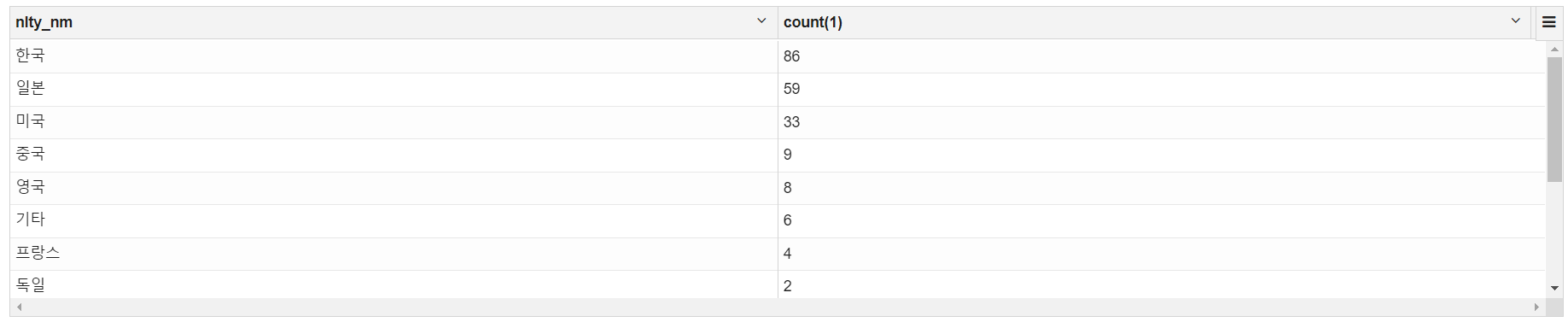
%spark.sql
# 국가별 영화 수
select nlty_nm, count(*) from movie group by 1 order by 2 desc;