1) spark, RDD, schema 생성
%spark.pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("yarn") \
.appName('SparkByExamples.com') \
.getOrCreate()
emptyRDD = spark.sparkContext.emptyRDD()
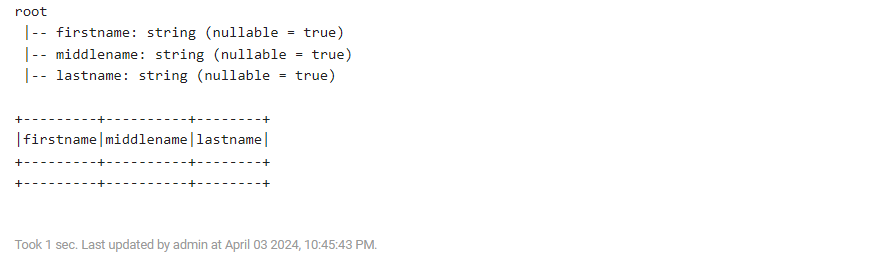
2) 깡통 DataFrame 생성
%spark.pyspark
from pyspark.sql.types import StructType, StructField, StringType
schema = StructType([
StructField('firstname', StringType(), True),
StructField('middlename', StringType(), True),
StructField('lastname', StringType(), True)
])
df = spark.createDataFrame(emptyRDD, schema)
df.printSchema()
df.show()
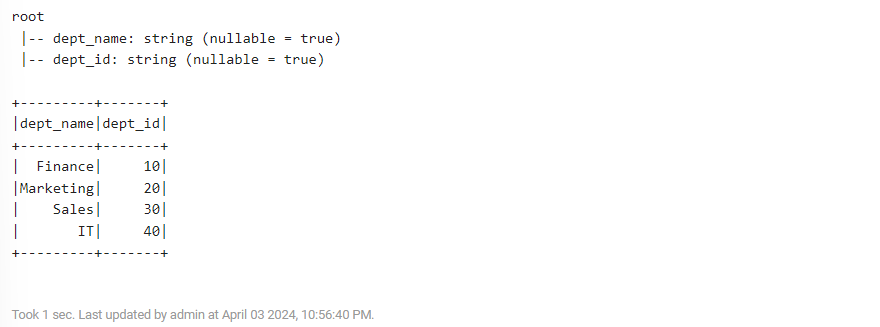
3) DataFrame 생성 1
%spark.pyspark
from pyspark.sql.types import StructType, StructField, StringType
dept = [
("Finance",10),("Marketing",20),("Sales",30),("IT",40)
]
rdd = spark.sparkContext.parallelize(dept)
dept_schema = StructType([
StructField("dept_name", StringType(), True),
StructField("dept_id", StringType(), True)
])
df = spark.createDataFrame(rdd, dept_schema)
df.printSchema()
df.show()
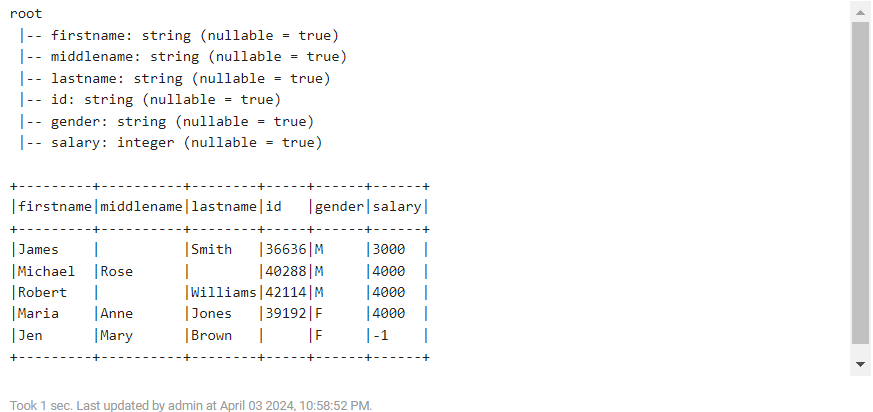
4) DataFrame 생성 2
%spark.pyspark
from pyspark.sql.types import StructType,StructField, StringType, IntegerType
data = [("James","","Smith","36636","M",3000),
("Michael","Rose","","40288","M",4000),
("Robert","","Williams","42114","M",4000),
("Maria","Anne","Jones","39192","F",4000),
("Jen","Mary","Brown","","F",-1)
]
schema = StructType([ \
StructField("firstname",StringType(),True), \
StructField("middlename",StringType(),True), \
StructField("lastname",StringType(),True), \
StructField("id", StringType(), True), \
StructField("gender", StringType(), True), \
StructField("salary", IntegerType(), True) \
])
df = spark.createDataFrame(data, schema)
df.printSchema()
df.show(truncate=False)
5) schema 정보를 json으로 반환
%spark.pyspark
print(df.schema.json())

