식물의 사진으로 질병 유무 판단
캐글 데이터를 이용하여 식물 사진으로 질병 유무를 판단해보자
실습은 colab에서 실행하였다.
데이터 가져오기
먼저 데이터를 구글 드라이브에 저장하고
아래 코드를 실행해서 압축 파일을 풀어서 데이터를 불러온다
!unzip -qq '/content/drive/MyDrive/Colab Notebooks/식물질병예측/dataset.zip' -d './dataset'
데이터 정리
데이터를 train, test, val 폴더를 생성해서 넣어주려고 한다.
이를 위해 먼저 폴더를 생성한다.
import os
original_dataset_dir = './dataset/'
classes_list = os.listdir(original_dataset_dir) #dataset에 있는 폴더 list
base_dir = './splitted' #나중에 생성될 train, test, val데이터 폴더를 갖는 폴더
os.mkdir(base_dir)
#데이터 정리를 위한 목록 및 폴더 생성
import shutil
#splitted폴더 하위폴더로 train, val, test 폴더 생성
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'val')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
for cls in classes_list: #train, val, test 폴더에도 기존 데이터에 있는 하위폴더를 모두 똑같이 넣기 위함
os.mkdir(os.path.join(train_dir, cls))
os.mkdir(os.path.join(validation_dir, cls))
os.mkdir(os.path.join(test_dir, cls))생성된 폴더에 데이터를 넣어준다.
#데이터 현황 확인
import math
for cls in classes_list:
path = os.path.join(original_dataset_dir, cls) #dataset에 있는 모든 폴더를 돌고
fnames = os.listdir(path) # 폴더안에 있는 파일명을 fnames에 저장
#train:val:test = 6:2:2로 분리
train_size = math.floor(len(fnames) * 0.6)
validation_size = math.floor(len(fnames) * 0.2)
test_size = math.floor(len(fnames) * 0.2)
#설정한 인덱스에 해당하는 파일들을 각 폴더에 저장
train_fnames = fnames[:train_size] #위에서 지정한 비율만큼 처음부터 train_size의 60퍼까지
print('Train size(',cls,'): ', len(train_fnames))
for fname in train_fnames:
src = os.path.join(path, fname) #기존 파일경로
dst = os.path.join(os.path.join(train_dir, cls), fname) #카피할 파일경로
shutil.copyfile(src, dst) # 기존파일경로를 카피할 파일경로train dir에 저장
validation_fnames = fnames[train_size:(validation_size+train_size)] #train size부터 val size까지
print('Validation size(',cls,'): ', len(validation_fnames))
for fname in validation_fnames:
src = os.path.join(path, fname)
dst = os.path.join(os.path.join(validation_dir, cls), fname)
shutil.copyfile(src, dst)
test_fnames = fnames[(train_size+validation_size):(validation_size+train_size+test_size)]
print('Test size(',cls,'): ', len(test_fnames))
for fname in test_fnames:
src = os.path.join(path, fname)
dst = os.path.join(os.path.join(test_dir, cls), fname)
shutil.copyfile(src, dst)학습
#학습준비
import torch
import os
USE_CUDA = torch.cuda.is_available()
DEVICE = torch.device('cuda' if USE_CUDA else 'cpu')
BATCH_SIZE = 256
EPOCH = 30
DEVICE위 코드에서 cuda가 출력된다면 GPU를 사용하도록 설정된 것이다.
import torchvision.transforms as transforms
from torchvision.datasets import ImageFolder
#ImageFolder : 폴더 이름을 라벨로 본다
transform_base = transforms.Compose([transforms.Resize((64,64)),transforms.ToTensor()])
train_dataset = ImageFolder(root='./splitted/train', transform=transform_base)
val_dataset = ImageFolder(root='./splitted/val', transform=transform_base)
#배치
from torch.utils.data import DataLoader
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=4)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=4)모델
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
self.pool = nn.MaxPool2d(2,2)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.conv3 = nn.Conv2d(64, 64, 3, padding=1)
self.fc1 = nn.Linear(4096, 512)
self.fc2 = nn.Linear(512, 33)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.pool(x)
x = F.dropout(x, p=0.25, training=self.training) #train에서만 dropout을 사용, test에서는 x
x = self.conv2(x)
x = F.relu(x)
x = self.pool(x)
x = F.dropout(x, p=0.25, training=self.training)
x = self.conv3(x)
x = F.relu(x)
x = self.pool(x)
x = F.dropout(x, p=0.25, training=self.training)
x = x.view(-1, 4096)
x = self.fc1(x)
x = F.relu(x)
x = F.dropout(x, p=0.5, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
#모델선언
model_base = Net().to(DEVICE)
optimizer = optim.Adam(model_base.parameters(), lr=0.001)함수를 생성하여 학습하고 평가해보자
#학습
def train(model, train_loader, optimizer):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(DEVICE), target.to(DEVICE)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
#평가
def evaluate(model, test_loader):
model.eval()
test_loss = 0
correct = 0
#with 자원을 열면 자원을 닫지 않아도 with 구분이 끝나면 저절로 닫힘(error 대응 잘함)
with torch.no_grad(): # no_grad()기 동작하는 동안 아래 반복문을 돌려라
for data, target in test_loader:
data, target = data.to(DEVICE), target.to(DEVICE)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
test_accuracy = 100. * correct / len(test_loader.dataset)
return test_loss, test_accuracyimport time
import copy
def train_baseline(model, train_loader, val_loader, optimizer, num_epochs = 30):
best_acc = 0.0 #가장 좋은 acc 저장할 변수
best_model_wts = copy.deepcopy(model.state_dict()) #가장 좋은 acc 모델의 weight 저장
for epoch in range(1, num_epochs + 1):
since = time.time()
train(model, train_loader, optimizer)
train_loss, train_acc = evaluate(model, train_loader)
val_loss, val_acc = evaluate(model, val_loader)
if val_acc > best_acc: #epoch 중 가장 val_acc가 좋은 weight를 저장
best_acc = val_acc
bset_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print('-------------------- epoch {} --------------------'.format(epoch))
print('train Loss: {:.4f}, Accuracy: {:.2f}%'.format(train_loss, train_acc))
print('val Loss: {:.4f}, Accuracy: {:.2f}%'.format(val_loss, val_acc))
print('Completed in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
model.load_state_dict(best_model_wts)
return model
base = train_baseline(model_base, train_loader, val_loader, optimizer, EPOCH) #(16)
torch.save(base, 'baseline.pt')
전이학습
잘 학습된 모델의 weight를 가져와서 내 상황에 맞게 적절히 바꾸어 학습시키는 것
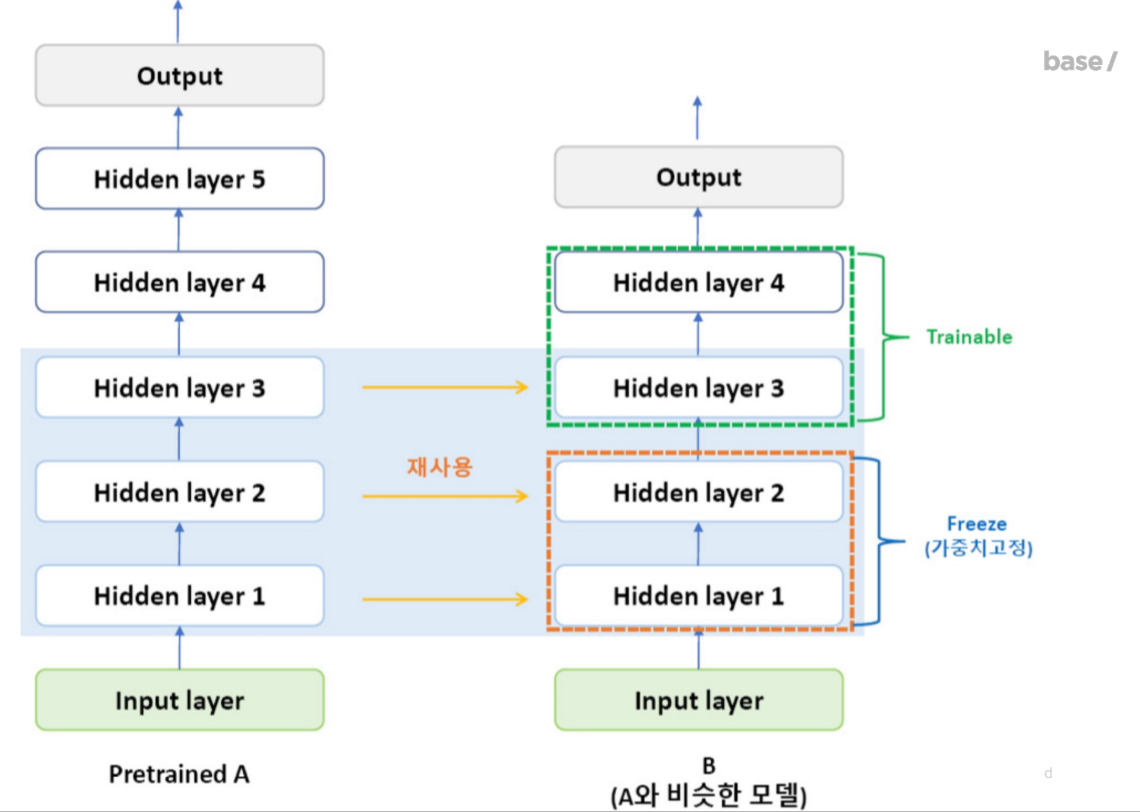
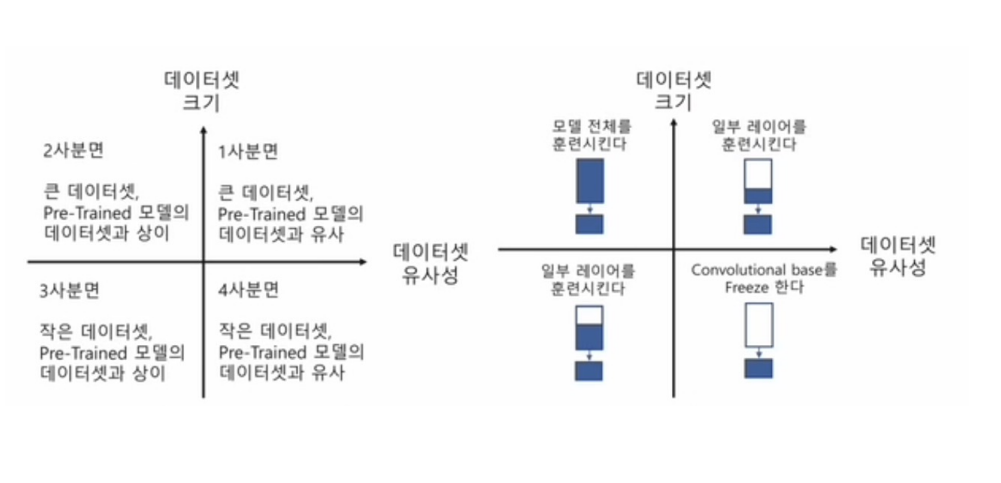
아래 그림을 참고하면 모델을 어떻게 가져올지에 대한 결정을 내릴 수 있다.
data_transforms = {
'train' : transforms.Compose([transforms.Resize([64,64]),
#과적합 방지를 위해 위배되지 않는 선에서 flip(뒤집기), crop(자르기)
transforms.RandomHorizontalFlip(), transforms.RandomVerticalFlip(),
transforms.RandomCrop(52), transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]),
'val' : transforms.Compose([transforms.Resize([64,64]),
transforms.RandomCrop(52), transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]),
}data_dir = './splitted'
image_datasets = {x : ImageFolder(root=os.path.join(data_dir, x),
transform=data_transforms[x]) for x in ['train', 'val']}
#배치나누기
dataloaders = {x : torch.utils.data.DataLoader(image_datasets[x],
batch_size = BATCH_SIZE,
shuffle=True,
num_workers=4) for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes전이학습 모델 불러오기
파이토치에서 from torchvision import models 를 이용하면
여러 모델들을 불러올 수 있다.
from torchvision import models
#pretrained=True 학습이 완료된 가중치를 받아오고, False면 구조만 가져옴
resnet = models.resnet50(pretrained=True)
#resnet50의 class수와 우리가 예측할 class 수가 다르다
#따라서 개수를 맞춰야 함
num_ftrs = resnet.fc.in_features #in_feature - 마지막 layer의 채널수
resnet.fc = nn.Linear(num_ftrs, 33) #33개로 수정
resnet = resnet.to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.Adam(filter(lambda p: p.requires_grad, resnet.parameters()), lr=0.001)
#p.requires_grad, resnet.parameters() : 마지막에 수정한 33개는 학습이 안됐으므로
#lr_scheduler : epoch에 따라 lr를 바꾸는 작업
#step_size=7, gamma=0.1 : epoch 7마다 0.1씩 lr를 바꿈
from torch.optim import lr_scheduler
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)모델 수정 후 학습시키기
학습하지 않을 레이어는 고정하고 학습할 레이어는 그대로 둔다.
ct = 0
#children(): 모델에 속해있는 하위레이어 정보들을 가져옴
for child in resnet.children():
ct += 1
if ct < 6:
for param in child.parameters():
param.requires_grad = False
#resnet이 10개 레이어를 갖고 있는데 0~5번까지는 학습하지 않도록 함
#입력에 가까운 5개 레이어는 고정시키고 6~9번만 학습을 하라는 것고정되지 않은 레이어들 학습
def train_resnet(model, criterion, optimizer, scheduler, num_epochs=25):
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('-----------------epoch {} -----------------'.format(epoch+1))
since = time.time()
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
#각 epoch마다 loss, corrects 초기화
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(DEVICE)
labels = labels.to(DEVICE)
optimizer.zero_grad()
#train 데이터일때 gradients 업데이트
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1) #가장 높은 값의 index를 preds에 저장
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward() #순방향연산
optimizer.step() #가중치 업데이트
#inputs.size(0): 배치사이즈
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} ACC: {:.4f}'.format(phase, epoch_loss, epoch_acc))
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print('Complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
model.load_state_dict(best_model_wts)
return modelmodel_resnet50 = train_resnet(resnet, criterion, optimizer_ft,
exp_lr_scheduler, num_epochs=EPOCH)
torch.save(model_resnet50, 'resnet50.pt')출력

평가
#과적합 방지 transform
transform_resNet = transforms.Compose([
transforms.Resize([64,64]),
transforms.RandomCrop(52),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
test_resNet = ImageFolder(root='./splitted/test', transform=transform_resNet)
test_loader_resNet = torch.utils.data.DataLoader(test_resNet,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4)#저장된 모델 불러오기
resnet50 = torch.load('resnet50.pt')
resnet50.eval()
test_loss, test_accuracy = evaluate(resnet50, test_loader_resNet)
print('ResNet test acc: ', test_accuracy)출력
ResNet test acc: 98.96107147327575
tensorflow_datasets을 이용한 전이학습과 미세조정
데이터 준비
from __future__ import absolute_import, division, print_function, unicode_literals
import os
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
keras = tf.keras
#데이터 준비
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
#데이터 받기
(raw_train, raw_validation, raw_test), metadata = tfds.load(
'cats_vs_dogs',
#train:val:test = 8:1:1
split = ['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
#as_supervised=True : 데이터가 라벨과 함께 tuple형태로 저장
as_supervised=True,
)
전처리
#이미지 전처리 함수
IMG_SIZE = 160 #모든 이미지 사이즈 160 x 160
def format_example(image, label):
image = tf.cast(image, tf.float32)
image = (image/127.5) - 1 # 0~255-> 0~2-> -1~1 일종의 scaling
image = tf.image.resize(image, (IMG_SIZE, IMG_SIZE))
return image, label
#map 함수로 빠르게 적용
train = raw_train.map(format_example)
validation = raw_validation.map(format_example)
test = raw_test.map(format_example)
#batch size 적용, shuffle
BATCH_SIZE = 32
SHUFFLE_BUFFER_SIZE = 1000
train_batches = train.shuffle(SHUFFLE_BUFFER_SIZE).batch(BATCH_SIZE)
validation_batches = validation.batch(BATCH_SIZE)
test_batches = test.batch(BATCH_SIZE)
#확인
for image_batch, label_batch in train_batches.take(1):
pass
image_batch.shape출력 TensorShape([32, 160, 160, 3])
MobileNet V2 모델
#MobileNet V2 모델
IMG_SHAPE = (IMG_SIZE, IMG_SIZE, 3)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')위 코드에서 살펴보면,
include_top=False
: 모델의 맨 위(마지막 레이어)는 원 핫 인코딩이 적용되어있을 것이다.
이는 우리가 학습할 데이터의 수와 다르기 때문에 맨 위층을 빼고가져온다.
weights='imagenet'
: 어떤 데이터로 학습된 모델인지? imagenet으로 학습된 모델을 불러옴
#feature_batch
feature_batch = base_model(image_batch)
print(feature_batch.shape)출력 : (32, 5, 5, 1280)
이 특징 추출기는 160 160 3 이미지를 5 5 1280개 특징블록으로 변환
1280이 채널수
가중치는 그대로 가져간다.
#가중치 그대로
base_model.trainable = False
base_model.summary()
#GlobalAveragePooling2D 층
#채널 마다 평균값을 이용
#GlobalAveragePooling2D 층을 사용하여 특징 이미지 한 개당 1280개의 요소 벡터로 변환
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)
#출력 (32, 1280)
#dense층을 사용하여 특정 이미지당 단일 예측
prediction_layer = keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)
#출력 (32, 1)전체 모델 구성
#전체 모델 구성
model = tf.keras.Sequential([
base_model,
global_average_layer,
prediction_layer
])
#모델 컴파일
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])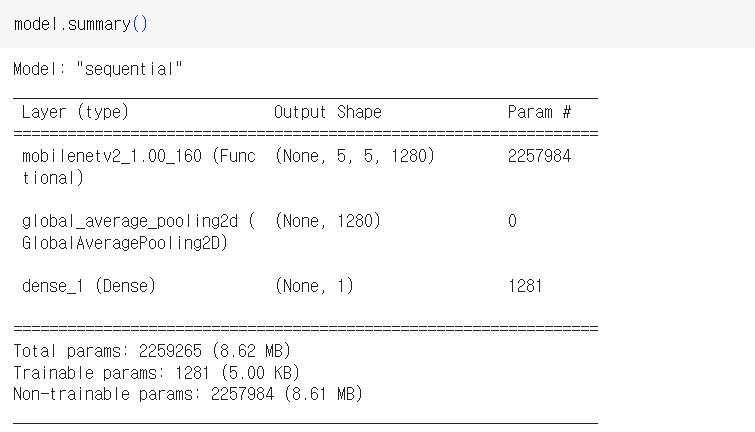
학습
#학습
history = model.fit(train_batches,
epochs=initial_epochs,
validation_data=validation_batches)평가
#평가
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8,8))
plt.subplot(2,1,1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2,1,2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()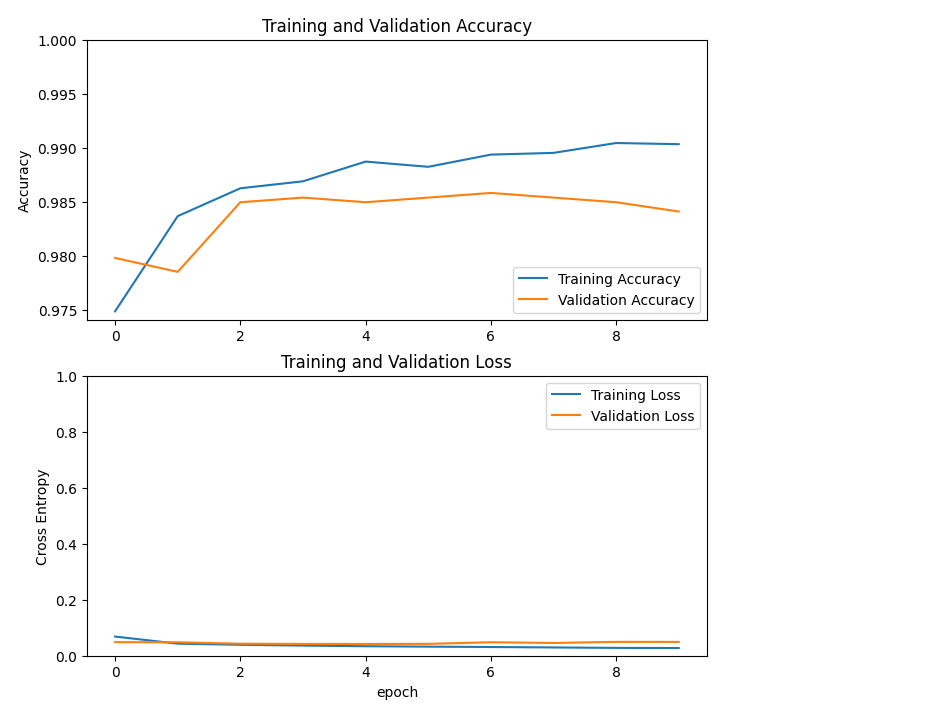
loss는 점점 떨어지고 있고 acc는 점점 상승하고 있다.
이번에는 일부만 학습된 모델의 가중치를 사용하고 일부는 튜닝을 해보도록 설정해보자.
미세조정
#모두 trainable하게 변경
base_model.trainable = True
print('Number of layers in the base model: ', len(base_model.layers))출력: Number of layers in the base model: 154
#100번째 층부터 튜닝가능하게 설정
fine_tune_at = 100
#fine_tune_at : 층 이전의 모든 층을 고정
for layer in base_model.layers[:fine_tune_at]:
layer.trainable=False
#학습 비율을 낮춤
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.RMSprop(lr=base_learning_rate/10),
metrics=['accuracy'])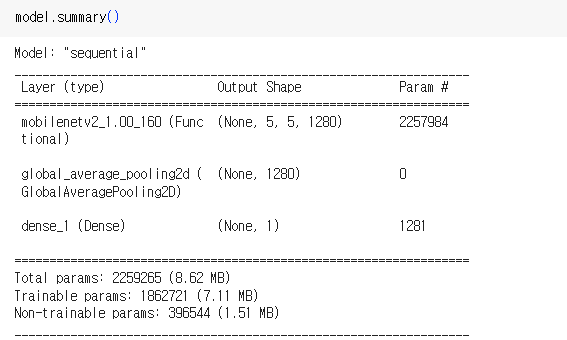 전에 1280보다 훨씬 늘어났다.
전에 1280보다 훨씬 늘어났다.
#총 20번의 epoch
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_batches,
epochs = total_epochs,
initial_epoch = history.epoch[-1],
validation_data=validation_batches)
이전 history에 이어서 학습하라는 의미로 history.epoch[-1]을 처음 시작하는 epoch로 두면 아래와 같이 10 epoch부터 시작하여 20 epoch까지 도는 것을 확인할 수 있다.
#최초 history에 방금 학습결과를 추가
acc += history_fine.history['accuracy']
val_acc += history_fine.history['val_accuracy']
loss += history_fine.history['loss']
val_loss += history_fine.history['val_loss']
#그래프
plt.figure(figsize=(8,8))
plt.subplot(2,1,1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([0.8,1])
plt.plot([initial_epochs-1, initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2,1,2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([0,1.0])
plt.plot([initial_epochs-1, initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()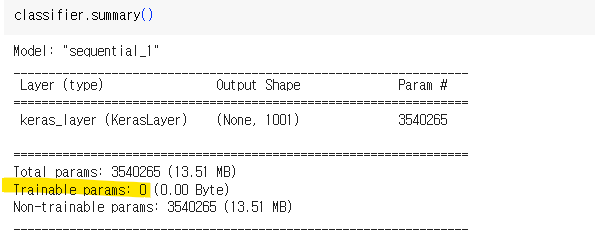
텐서플로 허브
텐서플로 허브에서도 모델,데이터를 가져와서 사용할 수 있다.
텐서플로 허브 공식 사이트의 코드를 따라하며 실습해보자.
import matplotlib.pylab as plt
import tensorflow as tf
import tensorflow_hub as hub
from tensorflow.keras import layers
url = 'https://tfhub.dev/google/tf2-preview/mobilenet_v2/classification/2'
classifier_url = url
#MobileNetV2
IMAGE_SHAPE = (224, 224)
classifier = tf.keras.Sequential([
hub.KerasLayer(classifier_url,
#Mobilenet은 224, 224, 3 형태
input_shape=IMAGE_SHAPE+(3,))
])
#이미지 하나 가져오기
import numpy as np
import PIL.Image as Image
url = 'https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg'
grace_hopper = tf.keras.utils.get_file('image.jpg', url)
grace_hopper = Image.open(grace_hopper).resize(IMAGE_SHAPE)
grace_hopper
학습
#정규화
grace_hopper = np.array(grace_hopper)/255.0
grace_hopper.shape #(224, 224, 3)
#예측
result = classifier.predict(grace_hopper[np.newaxis,...])
result.shape #(1, 1001)
#argmax로 인덱스 찾기
predicted_class = np.argmax(result[0], axis=-1)
predicted_class
from keras.src.applications.resnet_v2 import imagenet_utils
#label을 받아서
url = 'https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt'
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt', url)
imagenet_labels = np.array(open(labels_path).read().splitlines())
#확인
plt.imshow(grace_hopper)
plt.axis('off')
predicted_class_name = imagenet_labels[predicted_class]
_ = plt.title('Prediction: ' + predicted_class_name.title())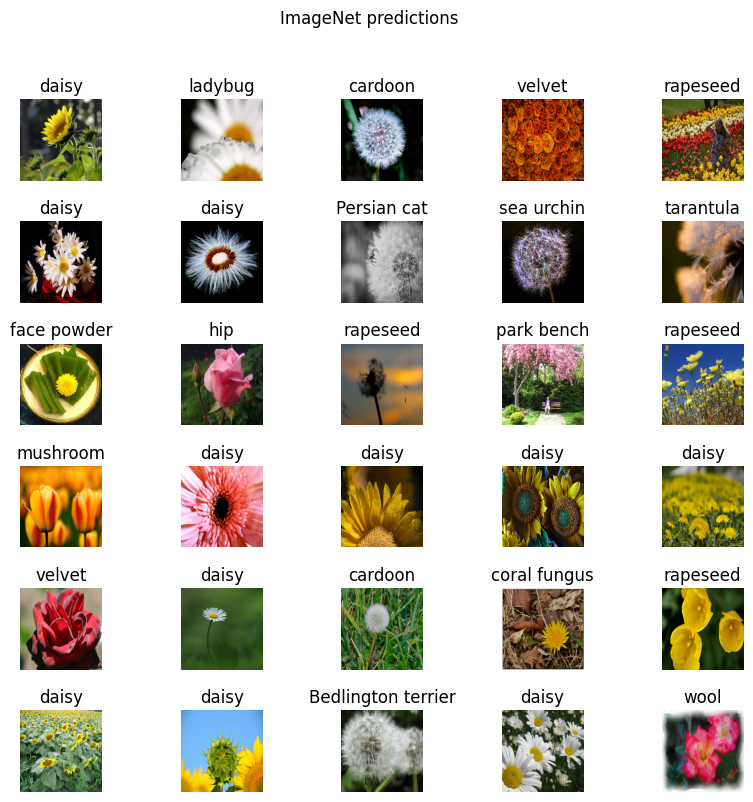
다음은 여러 꽃 데이터 이용해보자
데이터준비
url = 'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz'
data_root = tf.keras.utils.get_file(
'flower_photos', url,
untar=True
)
#rescale 라벨 인식
image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1/255)
image_data = image_generator.flow_from_directory(str(data_root), target_size=IMAGE_SHAPE)배치생성
#image batch 생성
for image_batch, label_batch in image_data:
print('Image batch shape: ', image_batch.shape)
print('Label batch shape: ', label_batch.shape)
break
#배치 한 셋에 대한 예측 결과
result_batch = classifier.predict(image_batch)
result_batch.shape #(32, 1001)
predicted_class_names = imagenet_labels[np.argmax(result_batch, axis=-1)]
#확인
plt.figure(figsize=(10,9))
plt.subplots_adjust(hspace=0.5)
for n in range(30):
plt.subplot(6,5,n+1)
plt.imshow(image_batch[n])
plt.title(predicted_class_names[n])
plt.axis('off')
_=plt.suptitle('ImageNet predictions')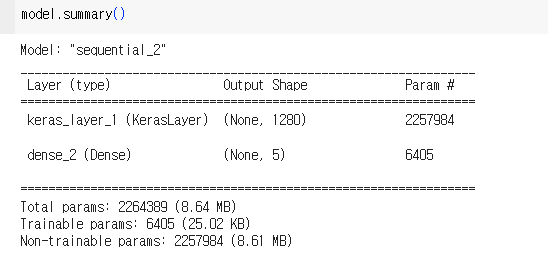
모델링
#특징 추출기
feature_extractor_url = 'https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/2'
feature_extractor_layer = hub.KerasLayer(feature_extractor_url,
input_shape=(224, 224, 3))
feature_batch = feature_extractor_layer(image_batch) #(32, 1280)
#dense 레이어 추가
feature_extractor_layer.trainable = False
model = tf.keras.Sequential([
feature_extractor_layer,
layers.Dense(image_data.num_classes, activation='softmax')
])
#마지막 층
predictions = model(image_batch)
predictions.shape #TensorShape([32, 5])
#컴파일
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss='categorical_crossentropy',
metrics=['acc']
)
#callback 정의
#callback : loss, acc를 배치 별로 뽑아냄
class CollectBatchStats(tf.keras.callbacks.Callback):
def __init__(self):
self.batch_losses = []
self.batch_acc = []
def on_train_batch_end(self, batch, logs=None):
self.batch_losses.append(logs['loss'])
self.batch_acc.append(logs['acc'])
self.model.reset_metrics()학습
#학습
steps_per_epoch = np.ceil(image_data.samples/image_data.batch_size)
batch_stats_callback = CollectBatchStats()
history = model.fit_generator(image_data, epochs=2,
steps_per_epoch=steps_per_epoch,
callbacks= [batch_stats_callback]) #callback 함수 지정
#class name 할당
class_names = sorted(image_data.class_indices.items(), key=lambda pair : pair[1])
class_names = np.array([key.title() for key, value in class_names])
#다시 예측
predicted_batch = model.predict(image_batch)
predicted_id = np.argmax(predicted_batch, axis=-1)
predicted_label_batch = class_names[predicted_id]
label_id = np.argmax(label_batch, axis=-1)평가
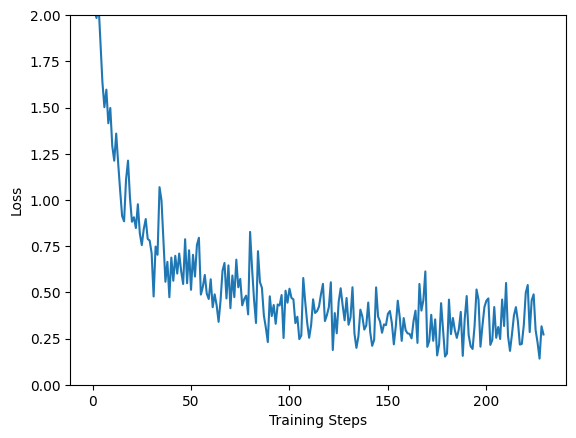
#결과 loss
plt.figure()
plt.ylabel('Loss')
plt.xlabel('Training Steps')
plt.ylim([0,2])
plt.plot(batch_stats_callback.batch_losses)
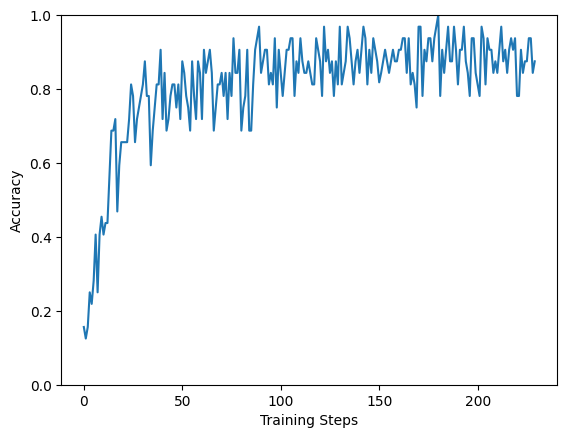
#결과 acc
#결과 loss
plt.figure()
plt.ylabel('Accuracy')
plt.xlabel('Training Steps')
plt.ylim([0,1])
plt.plot(batch_stats_callback.batch_acc)
#다시 확인
plt.figure(figsize=(10,9))
plt.subplots_adjust(hspace=0.5)
for n in range(30):
plt.subplot(6,5,n+1)
plt.imshow(image_batch[n])
color = 'green' if predicted_id[n] == label_id[n] else 'red'
plt.title(predicted_label_batch[n].title(), color=color)
plt.axis('off')
_=plt.suptitle('Model predictions (green: correct, red: incorrect)')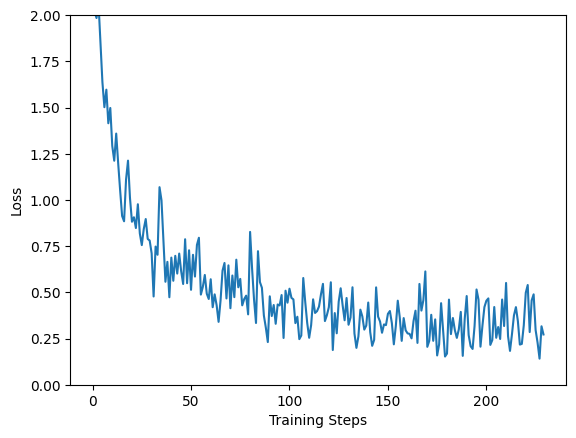
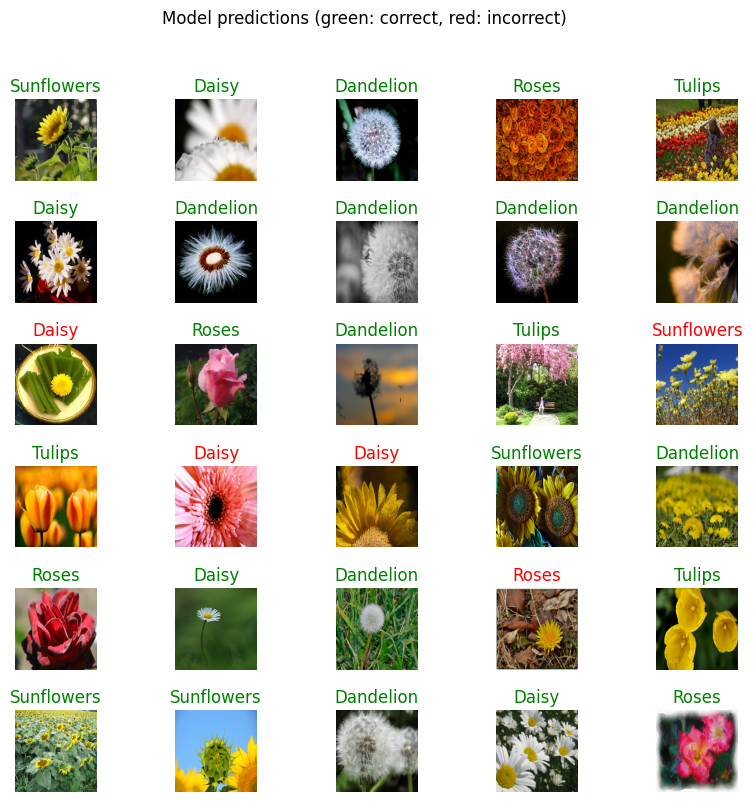
글자색을 정답은 초록, 오답은 빨강으로 표시했는데, 대부분 정답을 맞춘 것 같다.
