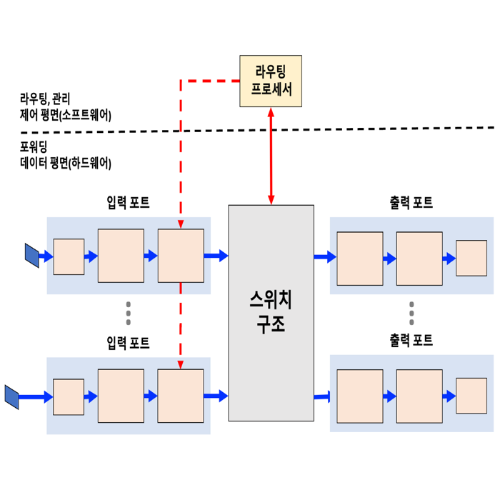
❓ 4.2 라우터 내부에는 무엇이 있을까?
- 입력 포트(input port)
- 포트 : 물리적인 입출력 라우터 인터페이스
- 네트워크 애플리케이션 및 소켓과 관련된 소프트웨어 포트와 다른 것
- 맨 왼쪽 박스와 출력 포트의 맨 오른쪽 박스 : 라우터로 들어오는 입력 링크를 통해 물리 계층 기능 수행
- 들어오는 링크의 반대편에 있는 링크 계층과 상호 운용을 하기 위해 필요한 링크 계층 기능을 수행
- ㄴ 입력 및 출력 포트에서 미들박스로 표시
- 검색 기능 수행
- 가장 오른쪽 박스에서 발생
- 포워딩 테이블을 참조하여 도착된 패킷이 스위치 구조를 통해 라우터 출력 포트를 결정
- 제어 패킷은 입력 포트 -> 라우팅 프로세서로 전달
- 포트 : 물리적인 입출력 라우터 인터페이스
- 스위치 구조
- 라우터의 입력 포트와 출력 포트를 연결
- 라우터 내부에 포함됨.(네트워크 라우터의 내부 네트워크)
- 출력 포트(output port)
- 스위치 구조로 부터 수신한 패킷을 저장하고 필요한 링크 계층 및 물리 계층 기능 수행하여 출력 링크로 패킷을 전송
- 링크가 양방향인 경우(양방향으로 트래픽을 전달하는 경우)
출력 포트는 일반적으로 동일한 링크의 입력 포트와 한 쌍을 이룸
- 라우팅 프로세서
- 제어 평면 기능을 수행
- 기존의 라우터
- 라우팅 프로토콜을 실행
- 라우팅 테이블과 연결된 링크상태 정보를 유지 관리
- 라우터의 포워딩 테이블을 계산
- SDN 라우터
- 원격 컨트롤러와 통신
- 원격 컨트롤러에서 계산된 포워딩 테이블 엔트리를 수신
- 라우터의 입력 포트에 이러한 엔트리를 설치
- 네트워크 관리 기능 수행
- 입력 포트,출력 포트, 스위치 구조 : 하드웨어로 구현 (개 빨라야함)
- 라우팅 프로세서 : 제어 평면 기능은 일반적으로 소프트웨어로 구현(위 보단 느림)
- `목적지 기반 포워딩` : 최종 목적지만을 검색하고 최종 목적지로 연결되는 교차로 출구를 결정 한 후 출구를 알려줌 - `일반화된 포워딩` : 목적지 외 많은 요인을 토대로 출구 결정 (원점, 느린도로 빠른 도로, 모델, 제조사, 연도 등) - 라우터 구성요소를 자동차가 원형 교차로에 진입하는 것 비유 - 진입로, 진입 장소 - 입력 포트 - 원형 교차로 - 스위치 구조 - 원형 교차로 출구 도로 - 출력포트 
🚚4.2.1 입력 포트 처리 및 목적지 기반 전송
- 입력 포트의 라인 종단 기능과 링크 계층 처리 : 라우터의 개별 입력 링크와 관련된 물리 계층 및 데이터 링크 계층을 구현
- 입력 포트의 검색 : 라우터 동작의 핵심
- 라우터 : 포워딩 테이블을 사용하여 도착 패킷이 스위치 구조를 통해 전달되는 출력 포트를 검색
- 포워딩 테이블 : 라우팅 프로세서에서 계산되거나 갱신되거나 원격 SDN 컨트롤러에서 수신됨
- 라우팅 프로세서에서 라우터 구조 그림의 입력 라인 카드(hw)로 복사됨.
- 각 라인 카드에서 이와 같은 섀도 복사본을 사용하면 패킷 단위로 중앙 집중식 라우팅 프로세서를 호출하지 않게됨
=> 병목현상 피함
- 32비트 IP 주소 : 40억개 이상의 엔트리를 가진 주소 포워딩 테이블 만들어야함 -> 말도안됨
- 오른쪽 처럼 4개의 엔트리를 갖는 포워딩 테이블이면 됨.
- 오른쪽 포워딩 테이블에서 라우터는 패킷의 목적지 주소의 프리픽스(prefix)를 테이블의 엔트리와 매치
- 매치되는 엔트리가 존재하면 라우터는 패킷을 그 매치에 연관된 링크로 전송
- ex) 패킷의 주소 : 11001000 00010111 00010110 10100001
주소 앞 21개 비트 프리픽스는 테이블의 첫번째 엔틜와 매치
-> 링크 인터페이스 0으로 전송 - 만약 다중 매치 된다면
최장 프리픽스 매치 규칙사용
- = 테이블에서 가장 긴 매치 엔트리를 찾고, 여기에 연관된 링크 인터페이스로 패킷 전송- ex 11001000 0001011 00011000 10101010 처럼 각 처음 24비트 21비트에 따라 링크 인터페이스 바뀜
- ex) 패킷의 주소 : 11001000 00010111 00010110 10100001

빨리 검색해야함
- 포워딩 테이블의 존재를 감안할 때 검색은 개념적으로 간단
- 하드웨어 로직은 포워딩 테이블을 검색하여 가장 긴 프리픽스와 매치되는 것을 찾움
- 그러나 기가바이트 전송률에서 이 검색은 나노초 단위로 수행 = 졸라 빨라야함
- 빠른 검색 알고리즘 필요
- 빠른 메모리 접속 시간 필요 -> 내장형 DRAM 빠른 SRAM(DRAM 캐시로 사용되는 것) 메모리가 있는 설계 필요
검색외 다른 옵션들
- 검색을 통해 패킷의 출력 포트가 결정되면 패킷을 스위치 구조로 전송 가능
- 일부 설계에서는 다른 입력 포트로부터 패킷이 현재 구조를 사용하고 있다면 패킷이 스위칭
구조에 들어가는 것을 일시적으로 차단가능- 차단된 패킷은 입력 포트에 대기한 다음 나중에 구조를 교체하도록 예약
- 검색도 중요한데 다른 조치도 있어야함
- 물리 및 링크 계층 처리가 되어야 한다.
- 패깃의 버전 번호, 체크섬, TTL(timc-to-live)필드를 확인하고 이후 두 필드를 다시 사용해야 한다.
- 네트워크 관리에 사용되는 카운터(수신된 IP 데이터그램 수)를 갱신해야 한다.
매치 플러스 액션: 목적지 IP 주소 찾기('매치’)-> 패킷을 스위치 구조로 지정된 출력 포트로 전송(‘액션’)- 라우터뿐만 아니라 많은 네트워크 장치에서 수행
- 오늘날 네트워크 장치에서 매우 효과적이고 일반적인 개념
- 포워딩 개념의 핵심
🔄 4.2.2 스위칭
- 스위치 구조는 패킷이 입력 포트에서 출력 포트로 실제로 스위칭(즉,포워딩)되는 구조를 통과하므로 라우터의 핵심
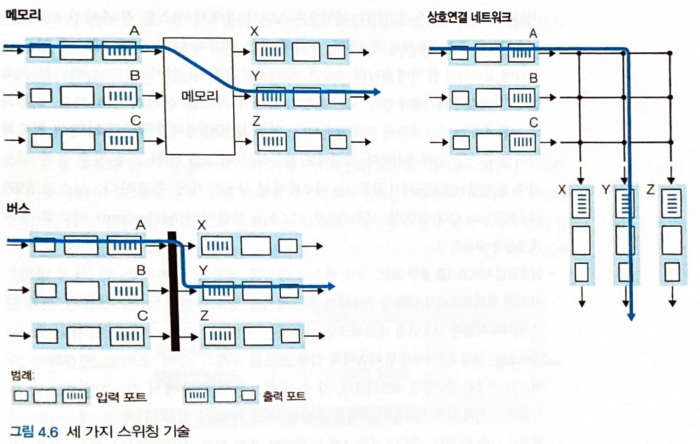
- 아래 3가지 방법~ 그림 보는게 훨 쉬움~
메모리를 통한 교환- 가장 단순한 초기의 라우터 : CPU(라우팅 프로세서)를 직접 제어해서 입력 포트와 출력 포트 사이에서 패킷을 스위칭하는 전통적인 컴퓨터
- 입력 포트와 출력 포트는 전통적인 운영체제에서 전통적인 I/O 장치처럼 작동
- 입력 포트 : 패킷이 도착 -> 라우팅 프로세서에 인터럽트 전송 -> 프로세서는 패킷을 메모리에 복사
- 라우팅 프로세서 : 헤더에서 목적지 주소 추출 -> 포워딩 테이블에서 적절한 출력 포트를 찾기 -> 출력 포트의 버퍼에 패킷을 복사
- 메모리 대역폭이 초당 최대 B인 패킷을 메모리 읽기/쓰기 가능한 경우
- 전체 전달 처리량 < B/2을 만족해야함.
- 두 패킷 동시 전달X
- 목적지 포트가 달라도 공유 시스템버스를 통해 한 번에 하나의 메모리 읽기/쓰기 작업을 수행할 수 있기 때문에
- 최근에도 일부 라우터는 메모리를 통해 스위칭
- but 초기와 달리 목적지 주소를 검색하고 해당 메모리 위치에 패킷을 저장하는 것이 입력 라인 카드에서 처리함으로써 수행
- 라인 카드에서 패킷을 처리하여 적절한 출력 포트의 메모리로 스위칭(쓰기)
- 공유 메모리 멀티프로세서와 매우 흡사
버스를 통한 교환- 입력 포트 : 라우팅 프로세서의 개입 없이 공유 버스를 통해 직접 출력 포트로 패킷을 전송
- 일반적으로 미리 준비된 입력포트 스위치 내부 레이블(헤더)이 로컬 출력 포트를 나타내는 패킷에게 전송되거나 버스에 패킷을 전송하여 수행
- 모든 출력 포트에 패킷이 수신되지만 레이블과 매치되는 포트만 패킷을 유지
- 레이블(헤더)은 스위치 내에서 버스를 통과하기 위해서만 사용되므로 출력 포트에서 제거
- 동시에 여러 패킷이 다른 입력 포트에 있는 라우터에 도착하면 하나를 제외한 모든 패킷이 대기 = 패킷 동시 전달X
- 한 번에 하나의 패킷만 버스를 통과할 수 있기 때문에 라우터의 교환 속도는 버스 속도에 의해 제한
- 종종 작은지역 및 기업 네트워크에서 작동하는 라우터에서 사용
- 입력 포트 : 라우팅 프로세서의 개입 없이 공유 버스를 통해 직접 출력 포트로 패킷을 전송
상호연결 네트워크를 통한 교환- 공유 버스의 대역폭 제한 극복 방법 : 멀티프로세서 컴퓨터 구조에서 프로세서를 상호연결하는 데 사용된 것보다 더 복잡한 상호연결 네트워크를 사용하는 것
크로스바 스위치: N개의 입력 포트를 N개의 출력 포트에 연결하는 2N버스로 구성된 상호연결 네트워크- 여러 패킷을 병렬로 전달 = 동시 전달 가능
- 서로 다른 입력포트 각각의 2개의 패킷이 같은 출력 포트로 전달되면 입력 대기
- 한 번에 하나의 패킷만 특정 버스에서 전송될 수 있기 때문에
- ㄴ 이때(같은 출력포트)만 아니면 해당 출력 포트에 도달하는 것을 막지 않음
- 각 수직 버스는 교차점에서 각 수평 버스와 교차 + 스위치 구조 컨트롤러에 의해 언제든지 여닫기 가능
- 패킷이 포트 A에 도착하여 포트 Y로 전달되어야 하는 경우
- 스위치 컨트롤러는 A와 Y 버스들과 포트 A의 교차로에서 교차점 닫기
-> 버스로 패킷 전달 : Y 버스만으로 픽업 - A에서 Y로,B에서 X로의 패킷들은 다른 입출력 버스를 사용하므로 B 포트에서의 패킷은 동시에 X로 전달될 수 있음
- 스위치 컨트롤러는 A와 Y 버스들과 포트 A의 교차로에서 교차점 닫기
- +)
3단계 논블로킹(n에-bkKking) 스위칭 전략- 좀 더 정교한 상호연결 네트워크는 : 다단계 스위치 구조를 통해 여러 단계의 스위칭 요소를 사용 -> 서로 다른 입력포트 각각의 2개의 패킷이 같은 출력 포트로 향해 동시에 전달
- 라우터의 스위칭 용량은 다중 스위치 구조를 병렬로 실행하여 확장 가능
- 입력 포트와 출력 포트가 병렬로 작동하는 N개의 스위치 구조에 연결
- 입력 포트는 패킷을 K개의 작은 청크로 분해 -> N개 스위치 구조의 K를 통해 청크를 선택한 출력 포트로 전송 -> 이 출력 포트는 K개의 청크를 다시 원래의 패킷으로 재조합
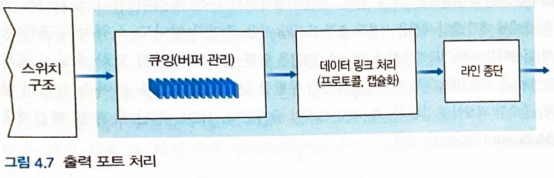
👩🏻💻 4.2.3 출력 포트 처리
- 그림 4.7의 출력 포트 처리는 출력 포트의 메모리에 저장된 패킷을 가져와서 출력 링크를 통해 전송
- 전송을 위한 패킷 선택(=스케줄링), 큐 제거,필요한 링크 계층 및 물리 계층 전송 기능을 수행하는 것이 포함
📚 4.2.4 어디에서 큐잉이 일어날까?
- 패킷 큐는 입 력 포트와 출력 포트 모두에서 형성
- 큐의 위치와 범위(입/출력 포트 큐)는 트래픽 로드, 스위치 구조의 상대 속도 및 라인 속도에 따라 달라진다.
- 패킷 손실 : 큐가 더 커져서 라우터의 메모리가 부족할 때 발생
- 스위치 구조 전송률이 전송률보다 N배 빠르면, 입력 포트에서 발생하는 큐잉은 무시됨
- = 최악의 경우에도 모든 N 입력 라인이 패킷들을 수신
- ㄴ 패킷이 입력포트로 들어와서 냅다 출력 포트로 빠르게 나가니까
- 전송률(Rline) : 입력 및 출력 라인의 속도
- 스위치 구조 전송률(Rswitch) : 패킷이 입력 포트에서 출력 포트로 이동할 수 있는 속도
입력 큐잉
- 위랑 달리 스위치 구조가 느리다면? -> 패킷은 대기해야 함.
- 크로스바 스위치 구조 가정
- 출력 포트가 다르다면 여러 패킷이 병렬로 전달 가능
- but 두 패킷이 같은 출력포트를 가지며면, 하나는 패킷은 차단 + 입력 큐에서 대기
- ㄴ= 스위치 구조는 한 번에 하나의 패킷만 지정된 출력포트로 전송됨.
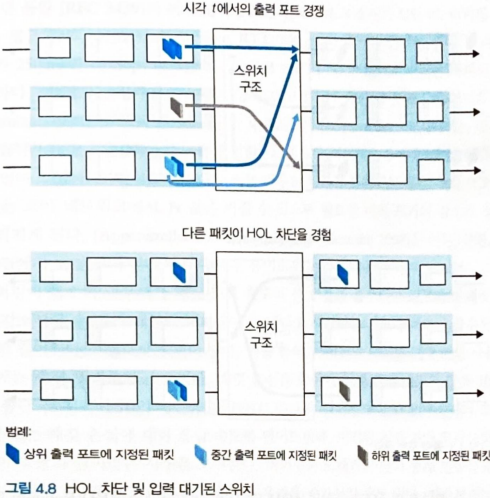
- 아래 그림 4.8
- 스위치 구조가 왼쪽 상단 큐의 앞쪽에서 패킷을 전송한다고 가정
- 왼쪽 하단 큐의 파란색인 두 번째 패킷은 대기
- 하늘 색 패킷은 이동하려는 출력 링크(목적지)가 경쟁이 없는 상태이지만 바로 앞의 진한 파란 패킷 때문에 대기
- ㄴ=> 입력 대기 중인 스위치에서의
HOL(head-of-the-line)블로킹 HOL(head-of-the-line)블로킹: 라인의 앞쪽에서 다른 패킷이 막고 있어서 입력 큐에서 대기 중인 패킷은 사용할 출력 포트가 사용 중이지 않아도 스위치 구조를 통해 전송되기 위해 대기- [Karol 1987] : 입력 링크에서 패킷 도착 속도가 용량의 58%가 되면 HOL 차단 때문에 입력 큐가 무한정 길이로 증가함 -> 중요한 패킷이 손실 = 패킷 손실 증가
- 스위치 구조가 왼쪽 상단 큐의 앞쪽에서 패킷을 전송한다고 가정
출력 큐잉
-
출력 포트에서의 큐잉 발생 ㅇㅇ
-
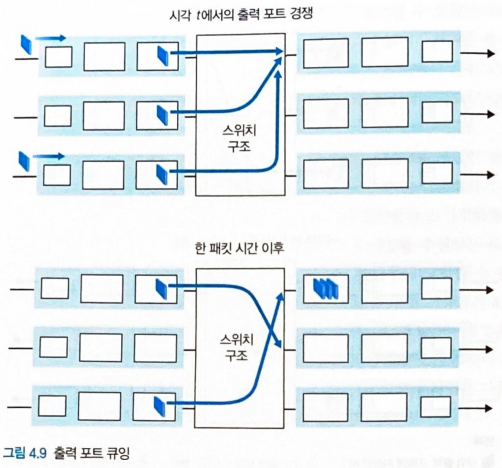
R 스위치가 다시 Rline보다 N배 빠르며 N개의 입력 포트 각각에 도착하는 패킷이 동일한 출력 포트로 향하는 것을 가정
- 출력 링크에 단일 패킷을 보내는 중에 N개의 새로운 패킷이 출력 포트에 도착
-> 출력 포트는 패킷 전송 시간에 단일 패킷만을 전송
= N개의 도착 패킷은 출력 링크를 통한 전송 큐에서 대기
= 대기 중인 N개의 패킷 중에서 하나를 전송할 때 다시 N개의 새로운 패킷이 도착할 수 있음
-> '대기 중인 패킷의 수 >> 출력 포트에서 사용 가능한 메모리' 상황이 될 수 있음
- 출력 링크에 단일 패킷을 보내는 중에 N개의 새로운 패킷이 출력 포트에 도착
-
위 처럼 메모리가 충분하지 않을 때, 아래중 하나 수행 가능
- 도착 패킷 삭제(drop-tail 정책)
- 이미 대기 중인 패킷들 제거
- 버퍼가 가득 차기 전, 패킷 삭제(or 헤더 마킹)하여 송신자에게 혼잡 신호 제공
- 이 마킹은 명시적 혼잡 알림(ECN) 비트를 사용하여 수행 (3.7.2 에서 학습했음)
- AQM(active queue management) 알고리즘 -> 패킷 삭제, 마킹 정책 제안
- RED(Random EarlyDetoction) ALG
- PIE(Proportional Integral controller Enhanced)[RFC 8033]
- CoDel[Nichols 2012]
-
패킷 스케줄러 : 출력 포트의 패킷 스케줄러(packet scheduler)가 전송 대기 중인 패킷 중 하나의 패킷을 선택
-
아래 그림에서는 아래 스위치의 수신 측에 도착한 패킷 2개 중 택 1
-
얼마나 많은 버퍼가 요구되는가 ?
- 불일치가 지속되는 시간이 길어질수록 큐는 더 길어짐 -> 포트의 버퍼가 가득 참 -> 패킷 삭제
- 그렇다면 포트에 얼마나 많은 버퍼링이 제공되어야 하는가 ?
- 네트어크 코어 내 라우터 가정 : 많은 독립적인 송신자들이 혼잡한 링크에서 대역폭과 버퍼를 놓고 경쟁하고 있다고 암시적으로 가정
- 링크 용량이 c일때, 많은 수의 독립적인 TCP 흐름(N)이 링크를 통과할 때,제안하는 버퍼링은
B = RTT* C/root(N) - 코어 네트워크에서, N 값은 커질 수 있으며 필요한 버퍼 크기의 감소가 상당히 두드러짐
- 버퍼링이 큼 -> 라우터가 패킷 도착 속도의 큰 변동을 흡수-> 라우터의 패킷 손실률 감소
=> 버퍼가 클수록 큐잉 지연이 길어짐. - 버퍼링 장점 : 트래픽의 단기 통계 변동을 흡수
- 버퍼링 단점 : 지연과 그에 따른 우려를 증가
- 링크 용량이 c일때, 많은 수의 독립적인 TCP 흐름(N)이 링크를 통과할 때,제안하는 버퍼링은
- 네트워크 가장자리 (홈 네트워크)
- 그림 4.10(a) : TCP 세그먼트를 원격 게임 서버로 보내는 홈 라우터
- 게이머의 TCP 세그먼트를 포함하는 패킷을 전송하는 데 20 ms가 소요
- t = 200ms에서 첫 번째 ACK도착 = TCP 송신자가 다른 패킷 전송,이것은 다음과 같이 대기 어쩌구저쩌구
-> 대기 중인 패킷이 있을 때마다 새 패킷이 큐에 도착, 전송
-> 홈 라우터의 송신 링크에서 큐 크기가 항상 5패킷
= 종단 간 파이프는 꽉 찼지만 큐잉 지연의 양은 일정하고 지속적 - 게이머 입장에선 다른 트래픽이 없는데도 지연이 계속됨
- 이를 버퍼블로트라고 함
- 그림 4.10(a) : TCP 세그먼트를 원격 게임 서버로 보내는 홈 라우터
버퍼블로트(bufferbloat): 패킷의 과도한 버퍼링으로 인해 생기는 패킷 교환 네트워크의 높은 대기 시간의 원인- = 처리량뿐만 아니라 최소 지연도 중요
🚥 4.2.5 패킷 스케줄링
FIFO(FCFS)
- 그림 4.11 : FIFO 링크 스케줄링 분야의 큐 모델의 개념도
- 링크가 현재 다른 패킷을 전송 중이면,출력 링크 큐에 도착한 패킷은 전송을 기다림.
- 버퍼 공간이 충분하지 않은 경우 : 큐의 패킷 폐기정책 실행
- 패킷 손실 여부 또는 다른 패킷을 큐에서 제거할 것인지 여부
- 패킷이 출력되는 링크를 통해 완전히 전송되면(=서비스를 받는 경우) 큐에서 제거
- 출력 링크 큐에 도착한 순서와 동일한 순서로 출력 링크에서 전송할 패킷을 선택
= 패킷은 도착한 순서와 동일한 순서로 나감
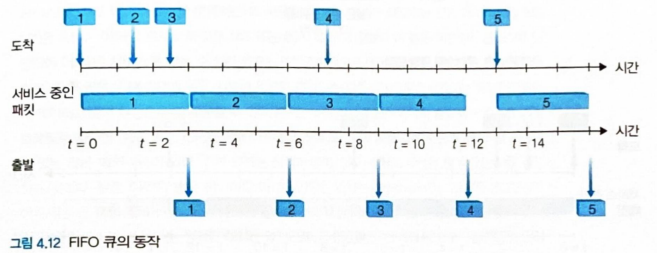
- 그림 4.12 FIFO 큐의 동작
- 도착한 패킷 : 도착한 순서를 나타내는 숫자와 함께 상단 타임라인 위에 번호가 매겨진 화살표로 표시
- 개별 패킷의 전송 : 하단 타임라인 아래 표시
- 패킷이 전송중에 소비하는 시간은 두 타임라인 사이의 사각형으로 표시
- 아래 그림에서는 패킷이 전송되는 데 세 단위의 시간이 걸린다고 가정
- 패킷 4를 전송한 이후에 링크는 패킷 5가 도착할 때까지 유휴 상태로 유지
- = 패킷1 에서 패킷 4까지가 모두 전송되고 큐에 남아 있는 패깃이 없는 상태
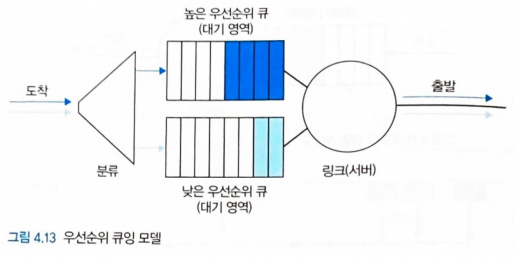
우선순위 큐잉
- 우선순위 큐잉에서 출력 링크에 도착한 패킷은 큐에 도착하면 우선순위 클래스로 분류됨
- 실제로 네트워크 오퍼레이터는 우선순위를 수신하도록 큐를 구성 가능
- 실시간 VoIP 패킷은 전자메일 패킷과 같은 트래픽보다 우선순위를 받을 수 있음
- 각 우선순위 클래스에는 일반적으로 고유한 큐가 있음.
-
전송할 패킷을 선택할 때 패킷이 있는 클래스 중 가장 높은 우선순위것 부터 패킷을 전송
-
우선순위가 동일한 패킷들 중에서의 선택은 전형적으로 FIFO 방식
-
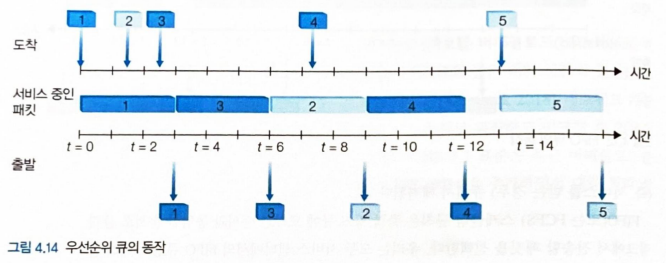
- 그림 4.14 : 우선순위 클래스가 2개인 경우의 큐 동작
- 패킷 1, 3, 4는 높은 우선순위 클래스
- 패킷 2, 5는 낮은 우선순위 클래스
- 패킷 1 이 도착하고 링크가 사용 중이지 않으면 전송을 시작
-> 패킷 1 이 전송되는 중에 패킷 2와 패킷3이 도착하고 각각 우선순위가 낮은 큐에 대기
-> 패킷 1 이 전송된 후 패킷 3이 패킷 2보다 먼저 전송
-> 패킷 3의 전송이 끝나면 패킷 2의 전송을 시작한다.
-> 패킷 2의 전송 중에 패킷 4가 도착
-> 패킷 4는 전송을 위해 대기
비선점 우선순위 큐잉 : 이때 패킷 4의 우선순위가 더 높더라도 패킷의 전송이 시작되면 중단X
-> 패킷 2의 전송이 종료된 이후 패킷 4의 전송 시작
라운드 로빈과 WFQ
- 패킷은 우선순위 큐잉과 같이 클래스로 분류
- 그러나 클래스 간에는 엄격한 서비스 우선순위X
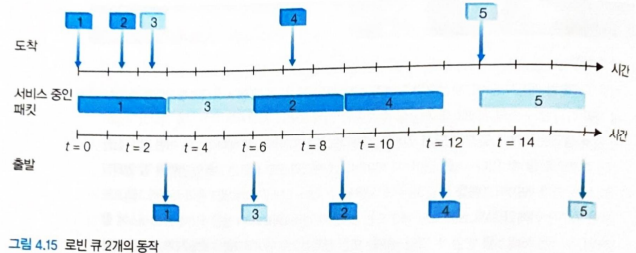
- 라운드 로빈 스케줄러가 클래스 간에 서비스를 번갈아서 제공
- 가장 단순한 라운드 로빈 스케줄링에서는 클래스1 <-> 클래스2 번갈아가면서 패킷 전송
- 작업 보존 큐잉 규칙
- 전송을 위해 큐에서 기다리는 패킷이 있다면 링크는 유휴 상태가 되는 것을 허용X
- = 클래스에서 패킷을 찾고 없으면, 다음 클래스를 즉시 검사
- 그림 4.15는 2개의 클래스 라운드 로빈 큐의 작동
- 패킷 1, 2,4는 클래스 1
- 패킷 3, 5는 클래스2
- 패킷 1 은 출력 큐에 도착하면 즉시 전송
-> 패킷 1 이 전송되는 동안 패킷 2와 3이 도착,전송을 대기
-> 패킷 1의 전송이 완료되면 링크 스케줄러는 클래스 2 패킷을 찾음
-> 패킷 3 전송
-> 패킷 3의 전송이 완료되면 스케줄러는 클래스 1 패킷을 찾음
-> 패킷 2를 전송
-> 패킷 2의 전송이 완료되면 패킷 4만이 큐에 있기 때문에 바로 패킷 4를 전송
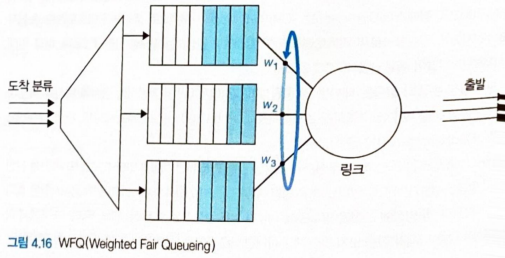
WFQ- 라우터에서 널리 구현된 라운드 로빈 큐잉의 일반화된 형태
- 도착하는 패킷은 적절한 클래스별 대기 영역에서 분류되며 대기
- 라운드 로빈 스케줄링에서처럼 WFQ 스케줄러는 순환 방식으로 동작
- 작업 보존 큐잉 규칙
- 클래스에서 패킷을 찾고 없으면, 다음 클래스를 즉시 검사
- 라운드 로빈과의 차이 : 각 클래스마다 다른 양의 서비스 시간을 부여받음
- 특히 각 클래스 i는 가중치(weight) wi를 할당받음
- 전송할 클래스 i 패킷이 있는 동안, 클래스 i는 wi/∑wj의 서비스 시간을 보장 받음
- 분모 : 전송을 위해 큐에 패킷이 있는 모든 클래스의 합
- = 최악의 경우에 모든 클래스의 큐에 패킷이 있을 때도 클래스 i는 대역폭 wi/∑wj 만큼을 사용할 수 있도록 보장
- ㄴ 이상적 : 패킷이 이상적인 단위 데이터라는 것과 패킷 전송이 다른 패킷을 전송
하기 위해 방해되지 않는다는 사실을 고려X

인생 살자.