로보틱스에 대한 열정으로 차근차근 나아가보려고 한다!
그 첫걸음으로 강화학습에 대해 알아가보고자 한다.
그 이유는 최근 관심을 가지게 된 뛰어난 성능을 보이는 DreamWaQ가 Deep reinforcement learning을 통해 만들어졌기 때문이다.
왕초보로서 강화학습에 첫단계부터 나아가고자 한다.
강화학습
강화학습에서는 에이전트가 주변 환경을 observe하고 Policy에 따라 행동을 하게 되며 그 결과로 보상(+/-)을 받는다.
(+)의 보상이 최대가 되도록 학습한다.
OpenAI GYM 환경 만들기
virtualenv 설치하고 환경 활성화하기
자신이 원하는 폴더를 만들어 그 안에서 환경을 활성화
그 후 OpenAI GYM을 만들어주면 된다
sudo apt install python3-virtualenv virtualenv env source env/bin/activate pip install gym==0.23.1 ```
그 후 Python 파일에 아래 코드를 넣어주면 된다
import gym env = gym.make('CartPole-v1') for i_episode in range(20): observation = env.reset() for t in range(100): env.render() print(observation) action = env.action_space.sample() observation, reward, done, info = env.step(action) if done: print("Episode finished after {} timesteps".format(t+1)) break env.close()```
진행하면서 이 링크를 참고했다// OpenAI gym Cartpole
이 python 파일을 실행하면 이렇게 막대를 쓰러뜨리지 않기 위한 스텝을 진행하게 된다.
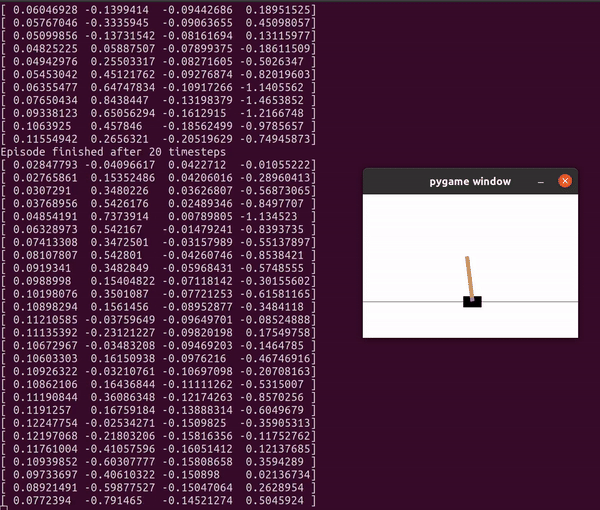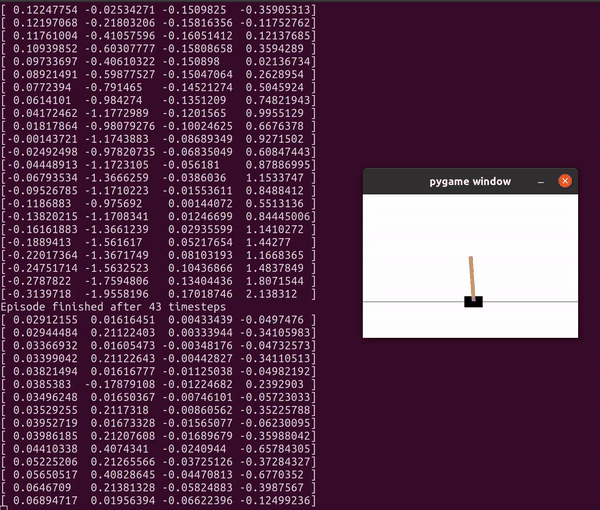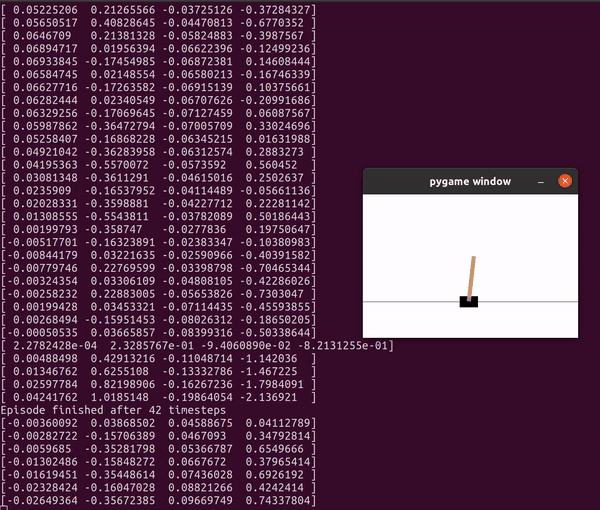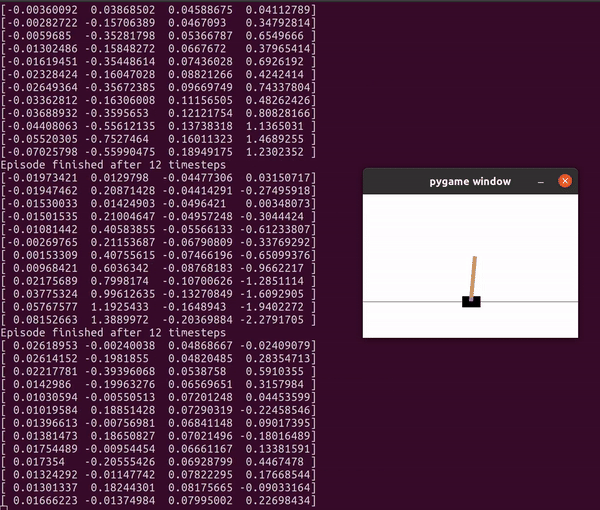
실행해보고 나면 마지막에 얼마나 많은 스텝을 진행했는지 알 수 있는데 내가 실행한 파일에서는 46 step밖에 진행하지 못했다.
그렇다면 계속되는 시리즈동안 신경망으로 더 좋은 정책(Policy)을 만들 수 있는지 알아가보자
