HPC에서 처음 멘탈이 나가는 순간은 대부분 이 에러다.
CUDA out of memorybatch size 줄였는데 또 나고, 다시 줄였는데 또 난다. 그러다 이런 생각이 든다. “이거… GPU가 고장 난 거 아님?” 아니다. 대부분 구조 문제다. 그리고 더 짜증나는 건, OOM은 한 번 터지면 그다음부터 계속 터질 확률이 높아진다는 거다. 로그는 멀쩡한데, 갑자기 같은 자리에서 죽고, 재실행하면 더 빨리 죽고, 그러다 결국 “내 코드가 뭔가 잘못됐나?”로 빠진다.
1. GPU 메모리는 뭐가 잡아먹고 있을까
GPU 메모리를 쓰는 건 생각보다 많다. 대충 네 덩어리다. 모델 weight, activation(중간 결과), gradient, optimizer state. 여기서 Transformer는 특히 activation이 미친 듯이 크다. 입력 길이가 늘어나면 “조금 더 느려지는 정도”가 아니라, 어느 순간 메모리 사용량이 벽을 뚫고 바로 터진다. 그래서 회의록처럼 길이가 들쑥날쑥한 데이터는 더 위험하다. 평균 길이로는 버티는데, 한 번 길게 걸리면 바로 OOM 난다.
그리고 여기서 자주 놓치는 게 하나 있다. GPU 메모리는 “모델만” 먹는 게 아니다. DataLoader가 GPU로 올리는 텐서, tokenizer 결과를 미리 쌓아두는 버퍼, evaluation 단계에서 생성 결과를 저장하는 리스트 같은 것도 은근히 누적된다. 학습이 아니라 검증(eval)에서 터지는 OOM도 꽤 흔하다.
2. “batch 줄였는데 왜 안 되지?”
이게 제일 많이 나오는 질문이다. 이유는 간단하다. 모델 weight는 batch랑 무관하고, optimizer state도 batch랑 무관하다. 즉 모델 자체가 GPU에 안 올라가는 경우 batch를 1로 만들어도 OOM 난다. 특히 Adam/AdamW + 큰 모델 + 긴 입력 조합이면 거의 확정이다. 그리고 한 번 더 빡치는 경우가 있는데, “학습은 되는데 backward에서만 터지는 케이스”다. forward는 겨우 올라갔는데 gradient까지 만들려니까 뒤에서 터진다. 그래서 로그가 “몇 step 잘 돌다가” 죽는 것처럼 보인다.
3. 제일 많이 쓰는 해결책 Top 5
1) Batch size 줄이기
가장 먼저 해보는 거다. 근데 한계가 빠르다. batch 1까지 갔는데도 터지면 여기서 더 줄일 게 없다. 이때부터는 “batch만의 문제”가 아니라는 뜻이다.
2) Gradient Accumulation
실험으로 알아보는 LLM 파인튜닝 최적화 가이드 Part 1
배치를 쪼개서 여러 번 계산 후 한 번 업데이트하는 방식이다. 실질적으로 batch size를 키우는 효과를 주면서, 한 번에 들고 있는 메모리는 줄인다. HPC에서 제일 현실적인 타협안이다. 특히 “성능은 유지하고 싶고, VRAM은 부족한” 상황에서 거의 기본으로 들어간다.
3) Mixed Precision (fp16 / bf16)

https://introduce-ai.tistory.com/entry/FP32-TF32-FP16-BFLOAT16-Mixed-Precision%EC%97%90-%EB%8C%80%ED%95%9C-%EC%9D%B4%ED%95%B4
거의 필수다. 프레임워크에 따라 다르지만 대체로 이거 하나로 VRAM이 확 줄어든다. 다만 fp16은 가끔 수치 불안정으로 터질 때가 있고, bf16이 가능한 GPU면 bf16이 더 편한 경우가 많다. 물론 “켜면 무조건 해결”은 아니고, activation이 너무 크면 mixed precision을 켜도 터진다. 그래도 안 켜는 게 더 이상하다.
4) LoRA / QLoRA
- https://velog.io/@kim_taixi/LoRA-QLoRA-DoRA-QDoRA
- https://ai.plainenglish.io/a-practical-guide-to-advanced-llm-fine-tuning-from-lora-to-qlora-462b01f44022
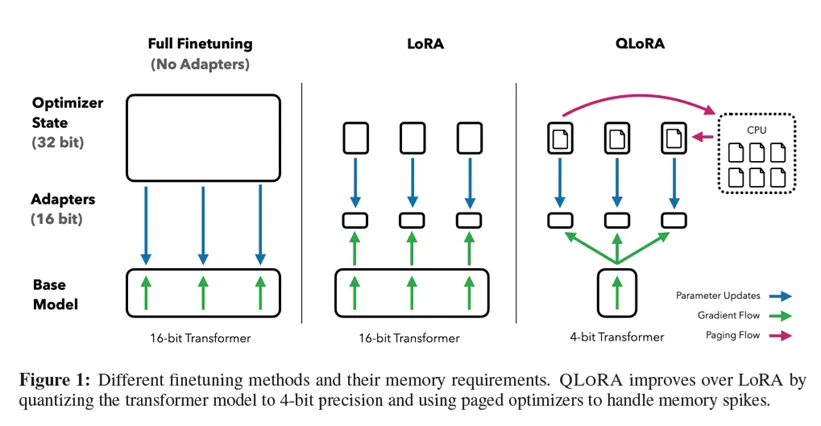
모델 전체를 학습하지 않는다. weight 대부분 freeze하고 일부 파라미터만 학습한다. LLM 계열에서는 사실상 표준이다. 그리고 여기서 진짜 중요한 건 “메모리가 줄어드는 이유”가 단순히 파라미터가 적어서가 아니라, optimizer state가 확 줄어드는 효과가 크다는 점이다. Adam 계열은 상태를 엄청 들고 있기 때문에, LoRA만으로도 체감이 크게 난다.
5) 입력 길이 줄이기
전처리랑 직결된다. 불필요한 발언 제거, 안건 단위 split.
이게 제일 싸고 확실하다!!!!!!!
그리고 국회 회의록 요약은 사실 이게 제일 정답에 가깝다. 모델을 바꾸는 것보다, 입력에서 의미 없는 부분을 덜어내는 게 더 잘 먹힌다. 특히 “긴 입력이 가끔 등장하는 케이스”를 잘라내면 OOM이 확 줄어든다.
4. “고급”이라고 불리는 것들
이건 진짜 막혔을 때 쓴다. Activation Checkpointing, CPU Offload, ZeRO(DeepSpeed), FSDP, 8-bit Optimizer. 효과는 확실한데 설정 난이도가 급상승한다. 그리고 HPC에서 이걸 쓰면 또 다른 문제가 생긴다. 설정은 됐는데 성능이 급격히 느려져서, “OOM은 해결했는데 학습 시간이 3배” 같은 상황이 나온다. 특히 CPU offload는 VRAM은 살리지만 I/O나 PCIe 병목이 생기면 체감이 확 난다. 그래서 이건 마지막 카드로 남겨두는 게 정신 건강에 좋다.
5. 모델 크기별 체감 VRAM
대충 감만 잡자. 그리고 이건 항상 “모델만 올렸을 때”가 아니라, 학습까지 포함하면 얘기가 달라진다.
| 모델 | 1×A6000 (48GB) |
|---|---|
| LLaMA 7B | 학습 가능(조건 맞으면) |
| LLaMA 13B | 빡빡 |
| LLaMA 33B | 거의 불가 |
| Diffusion | 상대적으로 여유 |
여기서 포인트는 “이론상 된다”와 “실제로 된다”는 다르다는 거다. 학습은 optimizer까지 포함이라 메모리 먹는 게 다르고, 입력 길이까지 얹히면 더 달라진다. 그리고 분산 학습이나 DDP 들어가면 또 달라진다. 그래서 표만 보고 확신하면 안 된다. 그냥 감만 잡는 용도다.
6. ipynb가 서버에서 자꾸 죽는 이유
이건 OOM이랑 자주 묶인다. 커널이 GPU 메모리를 못 돌려주고, 셀 단위 실행으로 메모리 파편화가 생기고, ssh 세션 끊기면 같이 죽는다. 특히 “한 번 OOM 났는데 커널이 살아있는 척만 하는 상태”가 제일 최악이다. 다시 돌리면 더 빨리 터지고, nvidia-smi 보면 메모리는 계속 잡혀 있고, 근데 프로세스는 애매하게 남아 있다. 그러면 결국 커널 재시작하거나 job 자체를 새로 띄워야 한다.
그래서 HPC에선 이게 거의 불문율이다. ipynb는 실험 메모용이고, 학습은 .py + Slurm이다. ipynb로 학습을 끝까지 끌고 가려 하면, 언젠가 한 번은 크게 데인다.
7. 그래서 실제 추천 조합
학습은 .py, 실험/기록은 Jupytext, 실행은 sbatch, 테스트는 srun. 이 조합이 제일 덜 아프다. 특히 “테스트는 srun으로 짧게, 학습은 sbatch로 길게” 이 흐름이 잡히면 OOM뿐 아니라 서버 사용 자체가 안정된다. 그리고 실패했을 때도 복구가 쉽다. 로그 파일 하나만 보면 되니까.
8. 정리
OOM은 GPU가 약해서가 아니라 설계가 안 맞아서 난다. 모델 크기, 입력 길이, optimizer, 학습 방식. 이 네 개가 맞아야 한다. batch 줄였는데도 계속 터진다면, 그건 “batch가 문제”가 아니라 “나머지 셋 중 하나가 너무 무거운 상태”라는 신호다. 그리고 회의록 요약 같은 긴 입력 문제에서는 결국 입력 구조를 손보는 게 제일 빠르고 확실하게 먹힌다.
