NLP/LLM
1.SSH, SFTP 간단히 이해하기

세라프를 어떻게 쓰더라,,,
2.국립국어원 말평 도전
말평 과제란? 국립국어원의 인공지능 말평(Korean Language Intelligence Benchmark)은 한국어 인공지능 기술의 성능을 객관적으로 평가하기 위해 마련된 국가 공인 벤치마크입니다. 형태소 분석, 품사 태깅, 개체명 인식, 문장 관계 추론, 감정
3.HPC(고성능 클러스터) 기본 구조
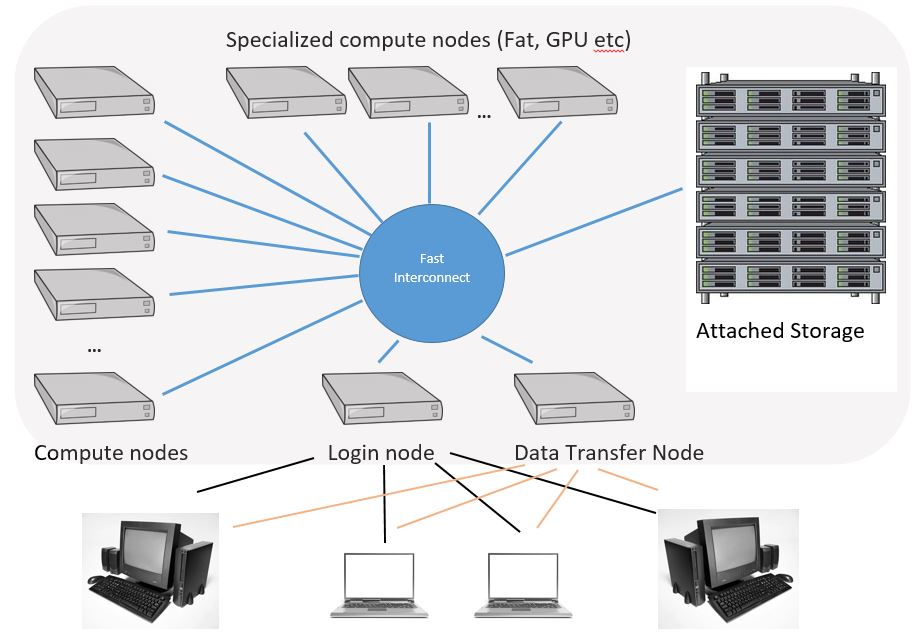
진짜 나는 Aurora Ariel 차이만 설명하고 싶었고...
4.Slurm과 작업 스케줄링

HPC를 쓰기 시작하면 아무리 늦어도 결국 마주치게 되는 게 Slurm이다.
5.그럼, 베이스라인 모델부터 돌려보자

Slurm까지 왔으면 이제 진짜 “모델 하나를 서버에서 끝까지 돌려보는 경험”을 해야 한다.
6.베이스라인 이후, 뭘 바꿔야 할까
베이스라인을 한 번이라도 끝까지 돌려봤다면 아마 이런 생각이 들 거다. 점수가 생각보다 안 나온다, 문장이 좀 이상하다, 중요한 발언을 놓친다, 길면 아예 잘린다.
7.GPU OOM — 왜 나는지, 왜 줄여도 안 되는지
HPC에서 처음 멘탈이 나가는 순간은 대부분 이 에러다.
8.서버 처음 쓰는 사람은 왜 MobaXterm을 쓰게 될까

HPC 시리즈를 여기까지 따라왔다면 이제 딱 이 상태다. SSH/SFTP 개념은 알겠고, Slurm도 이해했고, 베이스라인도 한 번은 돌려봤다. 근데 막상 “서버에 접속해서 실험을 계속 굴리는 생활”을 하려니까 갑자기 너무 불편해진다.
9.HPC 실수 12가지
HPC는 익숙해지면 강력한데, 모르면 진짜 불친절하다. 아래는 “모르면 꼭 한 번은 당하는 실수들”이다. 나도 다 해봤고, 주변에서도 계속 본다.하나의 env에 이것저것 설치하다가 어느 날 갑자기 import 에러가 난다. 버전 충돌이 터지면 원인 추적이 거의 불가능해
10.[4편 보강 예제] Slurm으로 “진짜 LLM 추론” 한 번 돌려보기 (phi-2)
아닙니다. Slurm 개념을 이해했으면, 이제는 진짜로 GPU 잡아서 뭔가 돌아가는 경험을 한 번 해야 한다. 근데 여기서 gpt2 같은 걸 돌리면 솔직히 감이 안 옴...!
11.llama.cpp vs vLLM/TGI 같은 LLM 실행인데 왜 완전히 다른 선택인가?

로컬 모델을 활용해 챗봇을 구성하는 방식은 이제 더 이상 낯선 주제가 아니다.
12.서빙 이전에 반드시 검증해야 할 것들, 그리고 로컬 튜닝 실패 패턴
앞선 글이 “왜 도구가 다른가”를 정리했다면, 이 글은 실제로 로컬에서 손을 더럽히며 겪었던 판단 기준과 실패 패턴을 정리한 기록이다.
13.관련 용어 정리
관련 용어 정리입니다요