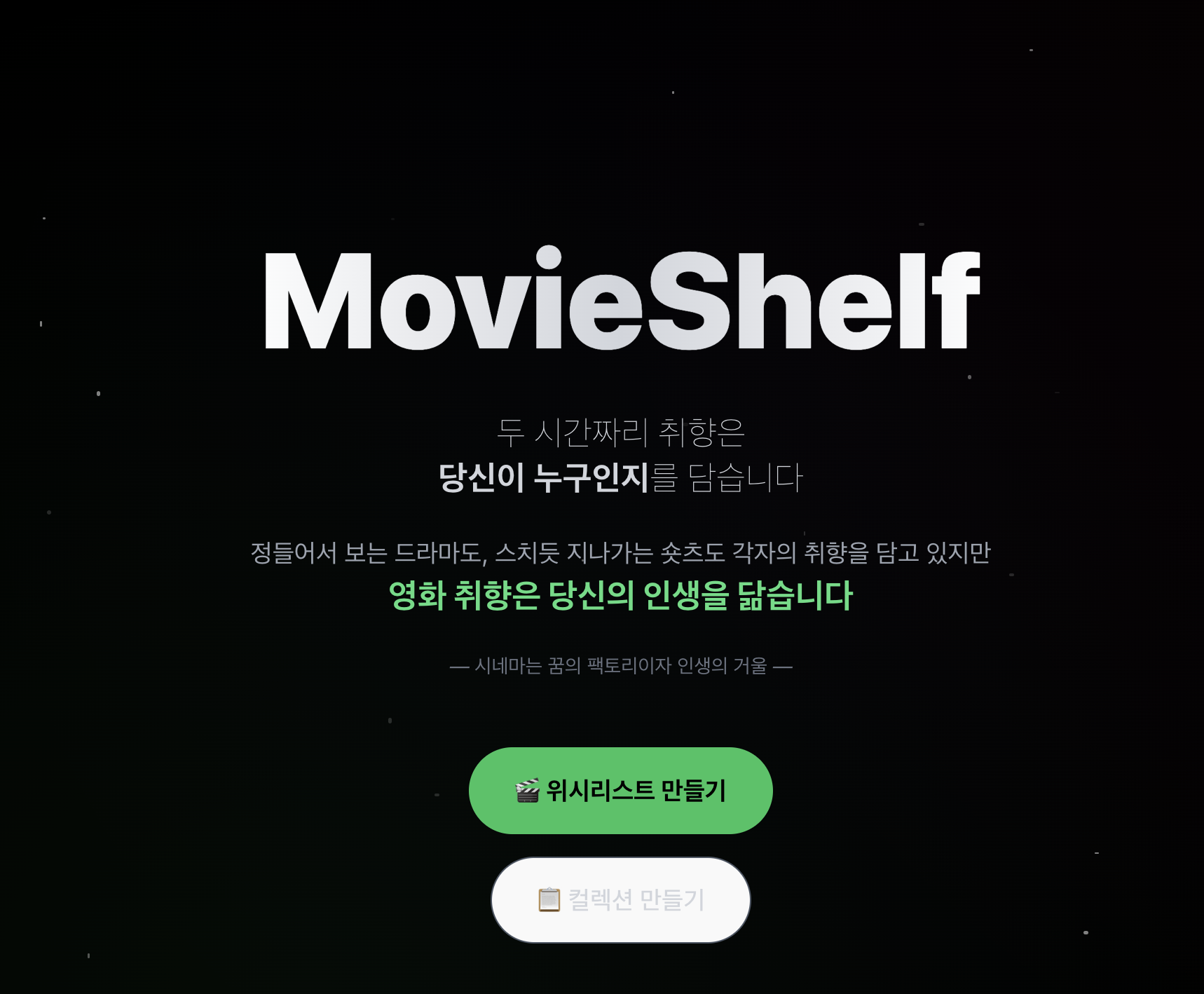
MOVIESHELF 서비스 바로 가기
https://movieshelf.store/
최근에 OTT 과소비하고 있다는 생각이 들었다. 아니? 했다. 딱 한달이긴 했지만 넷플릭스, 티빙, 유튭프리미엄, 쿠팡와우까지 구독하고 있는데 아까워서라도 영화를 많이 보자고 마음먹었다.
평소에 영화를 열심히 보진 않았어서 인스타그램의 영화 계정들을 많이 팔로우했다. 근데 단점이 있더라. 포스팅에 이끌려 다니는 느낌이랄까? 추천 영화들이 너무 겹치는 것도 많고, 나중에 보고 싶은 영화를 따로 리스트업할 수도 없었다.
또 부부부계(부계)에 저장해놨는데 나중에 찾아보려면 스크롤을 한참 내려야 하고 정리도 안 되어 있어서 불편했다. 그냥 내가 쓰고 싶은 걸 만들어보자 싶어서 시작했다.
요구사항은 간단했다.
로그인 없이 쓸 수 있고, 길게 리뷰 안 써도 되고, 내가 본 영화들을 깔끔하게 리스트로 정리할 수 있으면 됐다. 왓챠피디아처럼 길게 후기를 쓰고 싶지는 않았다.
기획

아이디어 자체는 복잡하지 않아서 초기 기획은 금방 끝났다.
영화 검색하고, 평점 매기고, 간단한 코멘트 남기고, 리스트로 보여주는 정도.
내가 만든 웹이 현재 MVP수준이라.. MMVP는 이번에도 두시간만에 끝났다.
TMDB api로 슥슥 만들었다.
문제는 구체적인 기술 요소들을 정하는 거였다. DB 스키마 어떻게 짤지, ID는 nanoid 쓸지 UUID 쓸지, 이런 것들 고민하는데 시간이 오래 걸렸다.
특히 MongoDB 스키마 설계에서 고민이 많았다. 사용자별로 영화 리스트를 어떻게 저장할지, 영화 정보는 TMDB에서 가져온 걸 그대로 저장할지 아니면 필요한 부분만 뽑아서 저장할지... 결국 사용자 컬렉션과 영화 컬렉션을 분리하고, 사용자 컬렉션에는 영화 ID와 개인 평점/코멘트만 저장하는 방식으로 정했다.
ID 생성은 nanoid로 결정했다. UUID보다 짧고 URL에 들어가도 깔끔해서.
근데 개발하다 보니까 스키마를 몇 번 바꿔야 하는 상황이 생겼다. 처음엔 단순하게 설계했는데 기능 추가하면서 필드를 더 넣어야 했고... 그래서 DB 마이그레이션 코드도 작성했다. MongoDB는 스키마가 유연하긴 하지만 그래도 기존 데이터 구조 바꾸려면 마이그레이션이 필요하더라.
문제는 마이그레이션 스크립트가 복잡해져서 그냥 기존 데이터를 날려버렸다는 거다. (인스타 올리고 나서라 중간에 서비스도 끊김ㅠ) 어차피 테스트 데이터니까 괜찮다고 생각했는데 나중에 좀 아쉬웠다. 하하, 이거 까먹을 뻔했네.
예상 밖의 반응
완성하고 나서 인스타 스토리에 올렸는데 반응이 생각보다 컸다. 한 시간 만에 유입 횟수가 1500번을 넘었다. 사람들이 생각보다 관심이 많았나 보다.
문제는 갑자기 트래픽이 몰리면서 로컬 테스트할 때 못 잡은 오류들이 터져나왔다는 거다. 동시 접속자가 많아지니까 API 응답 속도가 느려지고, 몇몇 엣지 케이스에서 에러가 발생했다. 특히 TMDB API 호출 제한에 걸리는 경우를 제대로 처리 안 해놔서 사용자들이 검색이 안됐고...
급하게 에러 핸들링 코드 추가하고 로딩 스테이트도 제대로 구현했다. 그리고 Google Analytics 4도 달아서 실제 사용 패턴을 분석할 수 있게 했다.
기술 스택 및 설계
프론트엔드는 Vite + React로 구성했다. Vite 쓰니까 개발 서버도 빠르고 빌드도 금방 끝나서 좋았다. 스타일링은 Tailwind CSS 사용했는데, 유틸리티 클래스 방식이 처음엔 어색했지만 익숙해지니까 CSS 파일 따로 안 만들어도 돼서 편했다.
사용자 플로우를 정리하려고 PlantUML로 다이어그램도 그려봤다.
그리다보니...

하... 이렇게 됐다.
디자인
처음에는 그냥 HTML/CSS로 대충 만들어보려고 했는데, 디자인 감각이 없다 보니까 시간만 날렸다. 그래서 Claude한테 도움을 요청했다. "스포티파이 느낌으로 만들어줘" 하니까 훨씬 깔끔하게 나왔다.
다크 테마 기반에 그라데이션 배경, 카드 스타일의 영화 리스트가 핵심이었다. Tailwind의 그라데이션 클래스들(bg-gradient-to-r from-purple-500 to-pink-500 같은)을 활용해서 스포티파이스러운 느낌을 냈다.
이게 AI 쓰는 가장 큰 장점인 것 같다. 내가 못하는 부분을 빠르게 보완할 수 있다는 것.
개발 및 배포
TMDB API 써서 영화 데이터 가져오고, Vercel로 프론트 배포하고, MongoDB Atlas랑 Cloudtype으로 백엔드 올렸다.

이게 Mogo Atlas
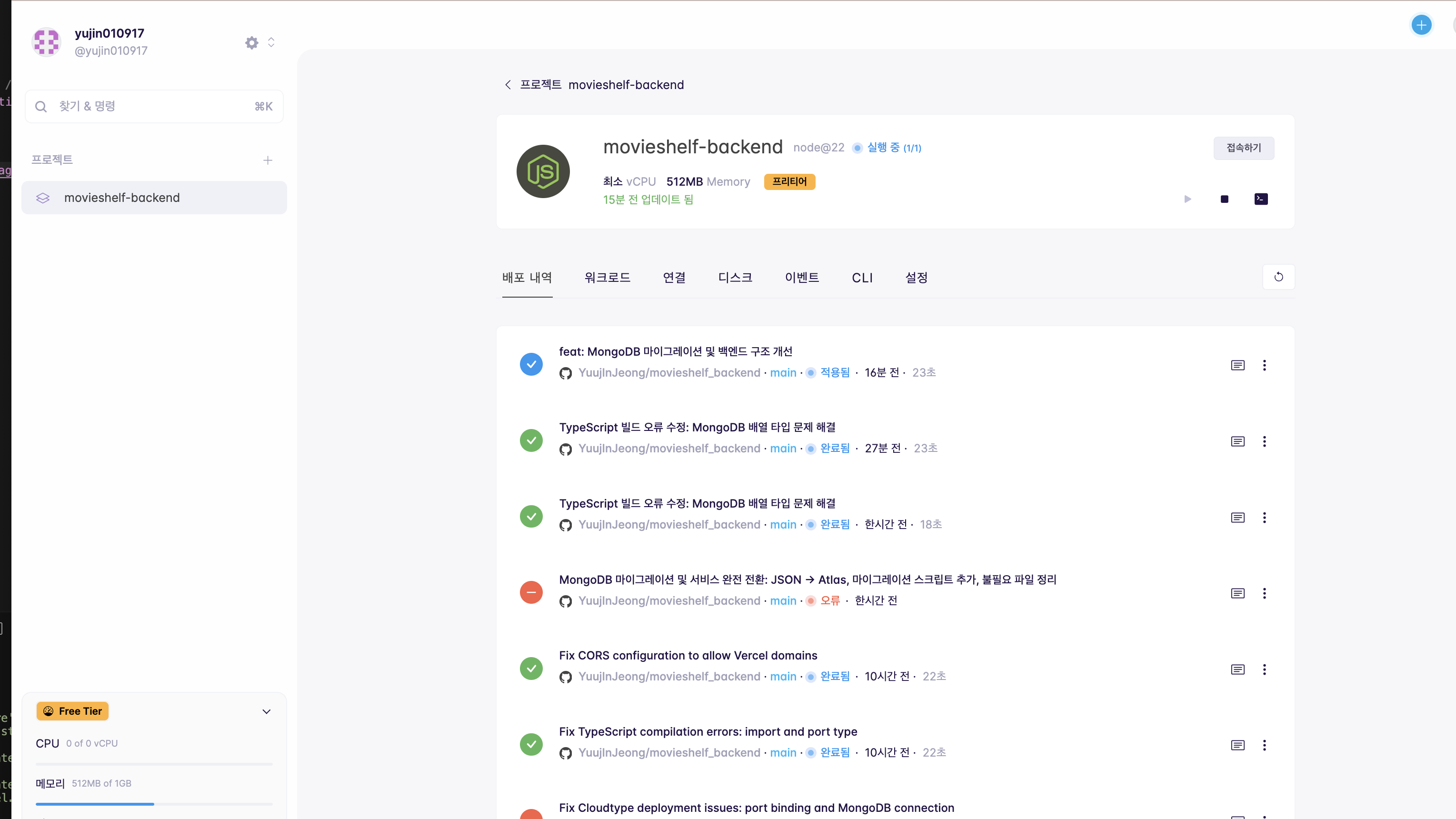
이게 cloudtype
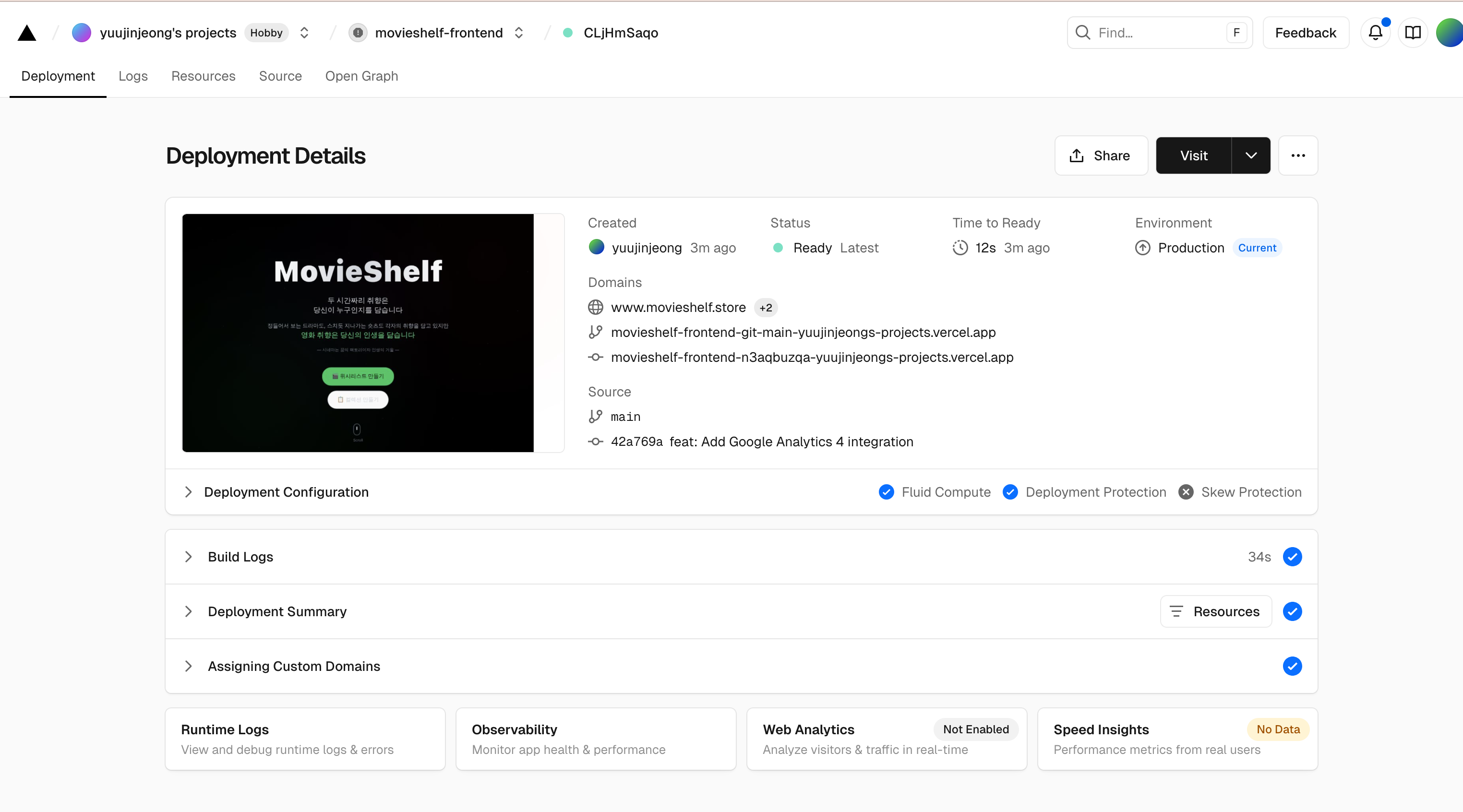
이게 vercel
백엔드는 Node.js + Express로 간단하게 구성했다. API 엔드포인트는 몇 개 안 되니까 복잡한 구조 없이 그냥 라우터 몇 개로 처리했다. TMDB API 호출하고, MongoDB에 사용자 데이터 저장하고, 프론트에서 요청한 데이터 리턴하는 정도.
배포 과정에서 CORS 에러가 몇 번 났는데, Vercel 도메인과 Cloudtype 도메인 간의 통신에서 문제가 생겼다. 백엔드에서 cors 미들웨어 설정할 때 origin을 제대로 안 적어서 그런 거였다. 이것만 해결하고 나니까 별 문제 없이 잘 돌아갔다. AWS 써봤을 때보다 훨씬 간단했다. 설정할 게 적고 무료 플랜도 넉넉해서 개인 프로젝트로는 충분했다.
AWS는 EC2 인스턴스 설정부터 시작해서 RDS, S3, CloudFront 등등 연결할 게 많고 복잡한데, 지금 쓴 서비스들은 그냥 몇 번 클릭하면 끝이다. 물론 AWS가 더 많은 기능을 제공하긴 하지만, 단순한 웹앱 하나 배포하는데는 오버스펙이다.
배운 점
AI를 개발에 활용하는 방법을 좀 더 구체적으로 알게 됐다. 코드 짜달라고 하는 것보다는 내가 고민하고 있는 기술적 선택지들에 대해 조언을 구하거나, 디자인 같은 내가 약한 부분을 보완하는 용도로 쓰는 게 효과적이었다.
그리고 요즘 나온 배포 플랫폼들이 정말 좋아졌다는 걸 실감했다. 예전에는 서버 하나 띄우려면 SSH 접속해서 nginx 설정하고 이것저것 해야 했는데, 지금은 그런 게 필요 없다.
로컬 환경과 실제 운영 환경의 차이도 다시 한번 느꼈다. 혼자 테스트할 때는 문제없던 게 실제 사용자가 몰리니까 여러 문제가 생기더라. 특히 외부 API 의존성이 있는 경우 에러 핸들링을 더 촘촘하게 해야겠다는 생각이 들었다.
아쉬운 점
처음에 기술 스택 고민하는데 시간을 너무 많이 썼다. 그냥 빨리 만들어보고 나중에 필요하면 바꾸는 게 나았을 것 같다. 완벽한 설계보다는 일단 돌아가는 걸 만드는 게 중요하다는 걸 또 한 번 느꼈다.
그리고 사용자 테스트를 제대로 안 해봐서 실제로 쓰기 편한지는 모르겠다. 나 혼자 쓰려고 만든 거지만 그래도 몇 명한테 써보라고 할 걸 그랬다.
마무리
결과적으로는 만족스럽다. 내가 원하던 기능은 다 구현했고, 배포도 잘 됐고, 실제로 쓰고 있다. AI 도움도 적절히 받으면서 혼자서도 충분히 괜찮은 서비스를 만들 수 있다는 걸 확인했다.
