경험정리
1.DOM과 SPA, 그리고 CSR vs SSR - 웹 크롤링 전에 꼭 알아야 할 구조 이야기
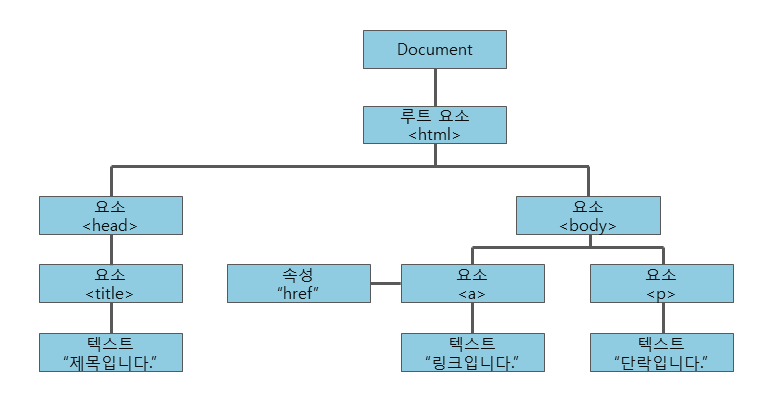
웹 크롤링을 할 때 단순히 URL만 분석해서 데이터를 긁어오면 끝일 줄 알았지만… 막상 해보면 그렇지 않다.
2025년 5월 19일
2.Web Crawling, Web Scraping, 그리고 Headless Browser - 직접 브라우저를 돌리기
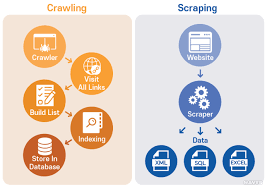
처음엔 단순히 생각했다."쿠팡 리뷰만 좀 긁어오면 되지, 그냥 requests.get()하고 BeautifulSoup 쓰면 끝 아냐?"하지만 막상 해보니 아무 데이터도 안 나왔다.
2025년 5월 19일
3.Puppeteer에서 무한스크롤 구현하기 – 끝까지 내려가는 법

SPA 구조로 된 웹사이트에서 데이터를 크롤링할 때 흔히 마주치는 문제 바로 무한스크롤(infinite scroll)!!
2025년 5월 19일
4.크롤러가 차단되는 이유: Puppeteer와 User-Agent, 그리고 봇 감지 우회 전략 ①
Puppeteer로 스크롤까지는 잘 작동하는데, 갑자기 브라우저가 꺼진다?
2025년 5월 19일
5.리뷰 크롤링 CAPTCHA 우회부터 CSV 저장까지, 실전 구조 완전 정리 [실패]
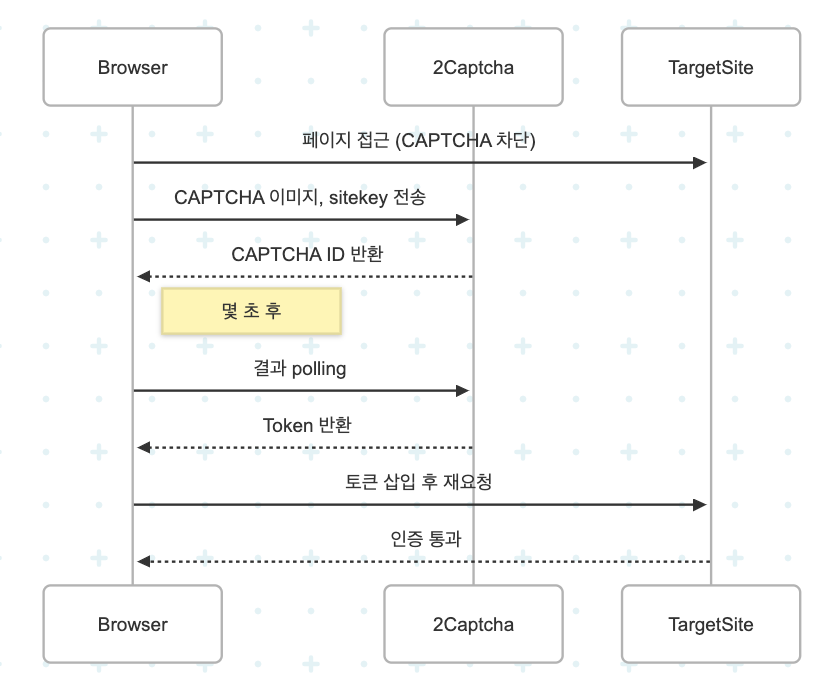
결론부터 말하자면, 이번 리뷰 크롤링은 실패했다.anti-bot 시스템에 막혀버렸다.
2025년 5월 19일
6.쿠팡 상품페이지는 SPA일까?
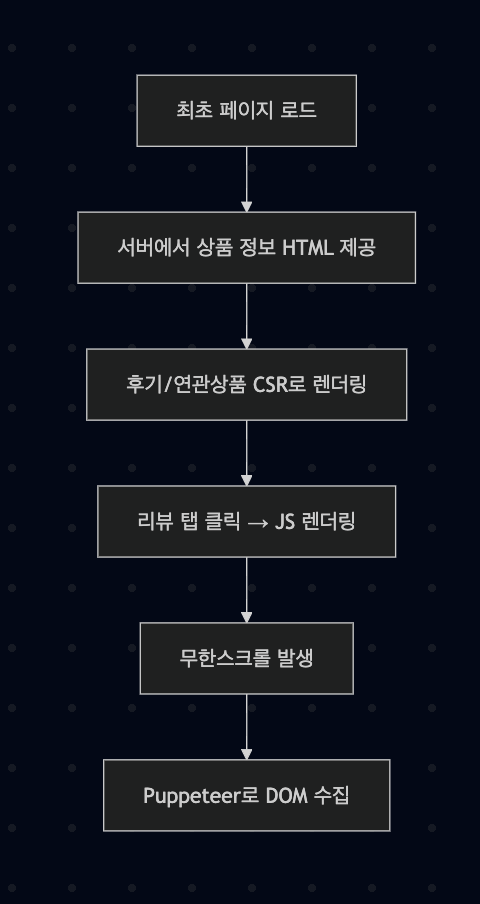
Puppeteer를 이용해 쿠팡 상품 페이지에서 리뷰를 수집하려 했는데, 페이지의 구조가 예상보다 복잡했다."이 페이지, 혹시 SPA인가?"라는 의문이 생겼고, 실제로 크롤링을 시도하면서 CSR/SSR의 경계에서 작동하는 하이브리드 구조라는 걸 체감했다.이 글에서는 쿠
2025년 5월 19일
7.MOVIE SHELF | AI로 영화플리 서비스 만들어본 후기
MOVIESHELF 서비스 바로 가기https://movieshelf.store/
2025년 6월 29일