Puppeteer를 이용해 쿠팡 상품 페이지에서 리뷰를 수집하려 했는데, 페이지의 구조가 예상보다 복잡했다.
"이 페이지, 혹시 SPA인가?"라는 의문이 생겼고, 실제로 크롤링을 시도하면서 CSR/SSR의 경계에서 작동하는 하이브리드 구조라는 걸 체감했다.
이 글에서는 쿠팡 상품페이지의 렌더링 구조를 분석하고, CSR/SSR의 차이를 정리한 뒤, 실제 크롤링 전략까지 정리해본다.
🧱 쿠팡 상품페이지는 SPA인가?
결론적으로, 완전한 SPA는 아니지만 일부 SPA적 요소를 포함한 SSR 기반 하이브리드 구조다.
| 구성 요소 | 구조 | 설명 |
|---|---|---|
| 상품명 / 이미지 / 가격 | SSR | 초기 HTML에 포함됨 |
| 리뷰 탭 / 연관 상품 / 실시간 가격 | CSR | 자바스크립트로 렌더링됨 |
| URL 전환 시 동작 | SSR | 새로고침 발생 |
✅ 즉, 쿠팡은 SSR 페이지를 기본으로 하되, 일부 영역을 CSR 방식으로 동적으로 로드한다.
🧠 SPA / SSR / CSR 개념 요약
SPA (Single Page Application)
자바스크립트를 통해 전체 페이지를 한 번만 로드하고, 이후에는 부분 화면만 갱신하는 방식
- 대표 예시: Gmail, Netflix, Facebook
- 장점: 빠른 전환, 앱 같은 UX
- 단점: 느린 초기 로딩, SEO 불리
SSR (Server Side Rendering)
페이지를 서버에서 미리 렌더링하여 HTML 형태로 제공하는 방식
- 장점: SEO 최적화, 빠른 첫 로딩
- 단점: 페이지 전환 시 새로고침 필요
CSR (Client Side Rendering)
콘텐츠를 브라우저에서 렌더링. 서버는 JS/CSS/HTML만 전달
- 장점: 풍부한 UX, 빠른 페이지 전환
- 단점: SEO 약함, 초기 로딩 느림
📐 구조 시각화
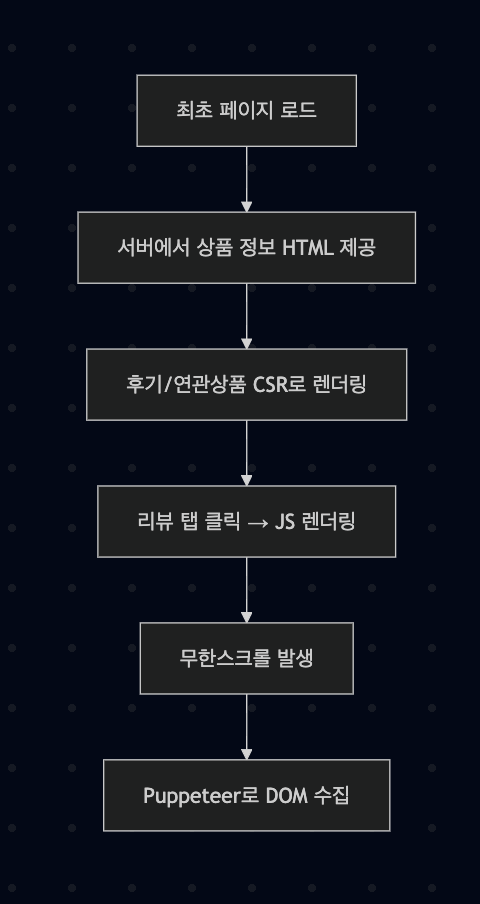
🛠 쿠팡 크롤링 시 유의사항
✅ 반드시 robots.txt 확인하기
https://www.coupang.com/robots.txt 에 따르면:
/vp/products/등 일부 경로만 크롤링 허용- 대부분의 API 및 내부 요청은 크롤링 금지
User-agent: *에 대한 제한이 많음
✅ 리뷰 영역은 CSR 기반 → Headless 브라우저 필요
리뷰 영역은 CSR 방식으로 작동하므로, 단순 requests, cheerio만으로는 수집 불가.
Puppeteer / Selenium 등 브라우저 자동화 도구 필수
✅ 리뷰 영역은 CSR 기반 → Headless 브라우저 환경 필수
쿠팡 상품페이지에서 리뷰 영역은 Client-side Rendering(CSR) 방식으로 작동한다.
즉, 초기 HTML에는 리뷰 내용이 전혀 포함되어 있지 않고, 사용자가 페이지를 열고 리뷰 탭을 클릭한 후에야 JavaScript가 동작하여 동적으로 DOM을 구성한다.
이 때문에 requests, axios, cheerio 등과 같은 단순 HTTP 요청 기반 파서는 리뷰 내용을 얻을 수 없다.
초기 HTML에는 <div class="sdp-review__article__list">와 같은 리뷰 리스트의 구조조차 존재하지 않기 때문이다.
✅ 리뷰 탭(클래스) 진입 → JS 실행 → Ajax 요청 → DOM 렌더링
이 일련의 과정을 거쳐야만 실제 리뷰 데이터가 화면에 나타난다.
이를 크롤링하려면 자바스크립트를 해석하고 실행할 수 있는 브라우저 시뮬레이션 환경이 필요하며, 대표적으로 다음과 같은 도구가 사용된다:
- Puppeteer: Headless Chrome 기반, Node.js 환경에서 널리 사용됨
- Selenium: 다양한 언어 지원, 테스트 자동화에도 자주 활용됨
- Playwright: Puppeteer보다 더 정교한 컨트롤이 가능한 최신 도구
이들 도구를 사용하면 다음과 같은 작업이 가능해진다:
- 리뷰 탭을 클릭하는 사용자 행동을 시뮬레이션
waitForSelector()로 DOM 렌더링 완료 여부를 감지evaluate()로 JS 실행 환경에서 데이터 추출
결론적으로, 쿠팡 리뷰 영역은 단순 크롤러로는 접근이 불가능하며, 브라우저 자체를 구동해 실제 사용자가 보는 것처럼 접근하는 headless 크롤링 전략이 필수적이다.
🧪 전략 요약
| 항목 | 전략 |
|---|---|
| 리뷰 탭 렌더링 대기 | page.waitForSelector() |
| 무한 스크롤 처리 | scrollTo() + scrollHeight 비교 |
| 봇 감지 우회 | User-Agent 조작, navigator.webdriver 우회 |
| CAPTCHA 대응 | 2Captcha 연동 고려 |
| 저장 포맷 | json2csv로 CSV 저장 (BOM 포함) |
📘 참고자료
| 주제 | 링크 |
|---|---|
| SPA / SSR 개념 정리 | Hygraph 블로그 |
| 쿠팡 robots.txt 정책 | 쿠팡 robots.txt |
| 크롤링 전략 정리 | Flyrank - Crawling SPA |
✍️ 마무리
크롤링을 하면서 기술적으로 가장 중요한 건 “그 페이지가 언제, 어디서 데이터를 렌더링하느냐”를 이해하는 것이다.
쿠팡처럼 SSR과 CSR이 혼합된 페이지를 다룰 땐, 이 두 가지 렌더링 구조에 대한 이해가 크롤링 성공 여부를 좌우한다.
SPA처럼 보이는 페이지라도 초기 HTML 구조를 살펴보는 습관,
CSR이면 브라우저 시뮬레이션 환경을 구축하는 실전 역량이 꼭 필요하다.
