🧭 들어가며
처음엔 단순히 생각했다.
"쿠팡 리뷰만 좀 긁어오면 되지, 그냥 requests.get()하고 BeautifulSoup 쓰면 끝 아냐?"
하지만 막상 해보니 아무 데이터도 안 나왔다.
그 이유는 내가 하고자 한 게 단순한 **스크래핑(scraping)**이 아니라, **브라우저 동작을 따라가야만 가능한 크롤링(crawling)**이었기 때문이다.
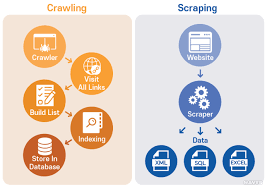
🕸️ Web Crawling vs Web Scraping – 뭐가 다를까?
| 구분 | Web Crawling | Web Scraping |
|---|---|---|
| 목적 | 여러 URL을 따라가며 자동 탐색 | 한 페이지 안에서 정보 추출 |
| 방식 | 링크 수집 → 페이지 이동 반복 | HTML에서 특정 태그 추출 |
| 사용 예 | 뉴스 사이트 전체 아카이브 수집 | 쿠팡 리뷰, 블로그 글 본문 추출 |
| 도구 | Selenium, Puppeteer, Apify 등 | requests, BeautifulSoup, lxml 등 |
실제로는 이 둘이 함께 사용된다.
- 크롤링: 리뷰 페이지들을 찾아가고
- 스크래핑: 그 안에서 정보를 추출하는 과정
이 프로젝트에선 한 페이지에 무한스크롤, 리뷰 탭 동적 렌더링, JavaScript 실행 필요 → 단순 scraping으로는 절대 불가능했다.
🧠 그래서 등장한 Headless Browser Crawling
💡 Headless란?
Headless Browser는 실제 브라우저처럼 동작하지만 **화면(UI)**을 보여주지 않는 브라우저다.
예: Chrome 브라우저를 터미널에서 UI 없이 띄워놓고 자바스크립트 실행 + 클릭 + 스크롤 등 모든 행동을 자동화하는 것.
왜 필요한가?
- JavaScript로 DOM이 동적으로 생성될 때
- SPA 구조로 HTML 안에 데이터가 없을 때
- 무한스크롤 로딩이 있을 때
- 버튼 클릭, 탭 전환 등의 상호작용이 필요할 때
실제 상황 – 쿠팡 리뷰
- HTML 소스 보니 리뷰 내용 없음 → JS로 나중에 생성됨
- 탭 전환(상품평 클릭) 없으면 리뷰 아예 안 보임
- 한 번에 10개씩 불러오고, 스크롤해야 다음 리뷰 나옴
- DOM이 완전히 그려질 때까지 기다려야
page.$eval이 먹힘
→ 이 모든 걸 처리하기 위해선 Puppeteer 같은 headless browser 기반 크롤러가 필수였다.
🧪 내가 시도한 Headless Crawling 구성
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.setUserAgent('...'); // 봇 감지 우회
await page.goto(url, { waitUntil: 'networkidle2' });
await page.click('.상품평 탭');
await page.waitForSelector('.리뷰 DOM 요소');
await page.evaluate(() => {
// 스크롤 반복
});- 이 구조 덕분에 CSR 렌더링까지 기다리고
- 동적 생성된 DOM에서 데이터를 추출하고
- 무한스크롤 끝까지 리뷰를 수집할 수 있었다
🔍 Headless Crawling의 장점
| 항목 | 설명 |
|---|---|
| 🧠 JS 렌더링 가능 | 실제 브라우저처럼 DOM 생성 가능 |
| 🎯 사용자 행동 자동화 | 클릭, 입력, 스크롤 등 제어 가능 |
| 🛡 봇 감지 회피 | User-Agent 조작 + human-like delay |
| 🧱 SPA 대응 | CSR 기반 페이지에도 완벽 대응 |
| 📷 디버깅 | page.screenshot()으로 UI 상태 확인 가능 |
📊 Headless Crawling의 실용적 가치
쿠팡 리뷰 데이터는 단순 텍스트가 아니라 동적 비정형 데이터다.
이를 수집하려면 단순 정적 HTML 파싱으로는 절대 부족하다.
그래서 내가 했던 일
- 데이터 자동 수집: 사용자가 보듯 리뷰를 탐색하며 자동 수집
- 사용자 리뷰 분석: content, rating, date, option 등을 CSV로 정제
- 비정형 → 정형: 자바스크립트 기반 DOM → Python/CSV 기반 구조화 데이터
이건 단순 크롤링이 아니라, 웹 브라우저 자동화 기반 데이터 엔지니어링에 가까운 작업이었다.
✍️ 마무리
쿠팡처럼 복잡한 구조의 사이트에선
정적 scraping만으론 절대 리뷰 수집이 불가능하다.
이럴 땐 Headless Browser Crawling이 필수다.
다음 글에서는
👉 무한스크롤 구현 방법,
👉 봇 감지 우회 전략,
👉 리뷰 필드 구조 정리 등
좀 더 실전적인 부분을 써보겠다.

일단 하고 보자 (펠리컨적 마인드 ㅠㅠ)