결론부터 말하자면, 이번 리뷰 크롤링은 실패했다.
anti-bot 시스템에 막혀버렸다.
기존 벨로그 글들에서 소개된 다양한 우회 방법들을 시도해봤고, 1시간 내에 1500개 이상을 수집할 수 있도록 평균 요청 간격을 2.4초 이하로 맞추되 랜덤 대기시간을 주는 등의 나름 창의적인 전략(?)도 세웠다.
그래도 단순히 새로운 라이브러리를 가져다 쓰기보다는 왜 그렇게 동작하는지에 대한 원리도 공부하면서 접근했기 때문에, 실패했지만 후회는 없다.
다만, 과거에 비슷한 프로젝트를 진행했던 경험에 너무 의존한 나머지 시간 배분에 실패했고, 캡차(CAPTCHA) 우회에 충분한 시간을 들이지 못한 것이 아쉬움으로 남는다.
📦 1. 쿠팡 리뷰 데이터 구조 분석 및 정제
쿠팡 리뷰는 CSR 방식으로 렌더링되며, 리뷰 데이터는 DOM 요소 내에 포함되어 있다.
Puppeteer로 무한스크롤을 완료한 뒤, 다음과 같은 구조로 리뷰 데이터를 추출할 수 있다.

🧩 주요 필드 정의
| 필드명 | 예시 | 추출 방식 |
|---|---|---|
| reviewId | "158062641" | li[data-review-id] 속성 |
| productId | "7059056549" | URL에서 추출 (/products/:id) |
| productName | "Apple 아이폰 12 mini 자급제" | .prod-buy-header__title |
| options | ["128GB", "레드"] | .product-info__option → .split('/') |
| userName | "김*표" | .user |
| rating | 4 | data-rating 속성 |
| date | "2021-04-06" | .reg-date → new Date().toISOString().slice(0, 10) |
| title | "7년만의 핸드폰 교체" | 없으면 content 앞부분 활용 |
| content | "배송은 하루만에..." | .review__content |
🛠️ DOM 파싱 예시 (Puppeteer)
const reviews = await page.$$eval('li[data-review-id]', nodes =>
nodes.map(el => ({
reviewId: el.getAttribute('data-review-id'),
userName: el.querySelector('.user')?.innerText.trim(),
rating: Number(el.querySelector('[data-rating]')?.getAttribute('data-rating')),
date: new Date(el.querySelector('.reg-date')?.innerText).toISOString().slice(0, 10),
content: el.querySelector('.review__content')?.innerText.trim(),
options: el.querySelector('.product-info__option')?.innerText.split('/').map(s => s.trim()),
}))
);📄 CSV로 저장하기
Node.js 환경에서 json2csv와 fs를 사용하면 간단하게 CSV 저장이 가능하다.
import { Parser } from 'json2csv';
import fs from 'fs';
const parser = new Parser({ withBOM: true });
const csv = parser.parse(reviews);
fs.writeFileSync('reviews.csv', csv, { encoding: 'utf8' });✅ 주의할 점:
- UTF-8 + BOM: Excel에서 한글 깨짐 방지
- 줄바꿈, 쉼표 포함된 문자열은
"..."로 감싸짐 \n,,,"등은 자동 escaping됨
🔐 2. CAPTCHA 자동 우회 전략 – 2Captcha
대형 커머스 사이트에서는 스크롤 끝에서 CAPTCHA가 등장하거나,
IP 감지 이후 리뷰 목록 로딩 자체가 차단되기도 한다.
이를 해결하기 위해 다음과 같은 CAPTCHA 자동화 도구가 활용된다.
🧠 CAPTCHA의 종류
| 유형 | 설명 |
|---|---|
| reCAPTCHA v2 | “자동이 아닙니다” → 이미지 클릭 or 체크박스 |
| reCAPTCHA v3 | 스코어 기반 탐지 (0~1 사이) |
| hCaptcha | Cloudflare 채택, 이미지 중심 |
| 이미지/텍스트 CAPTCHA | 왜곡된 문자를 입력하게 하는 방식 |
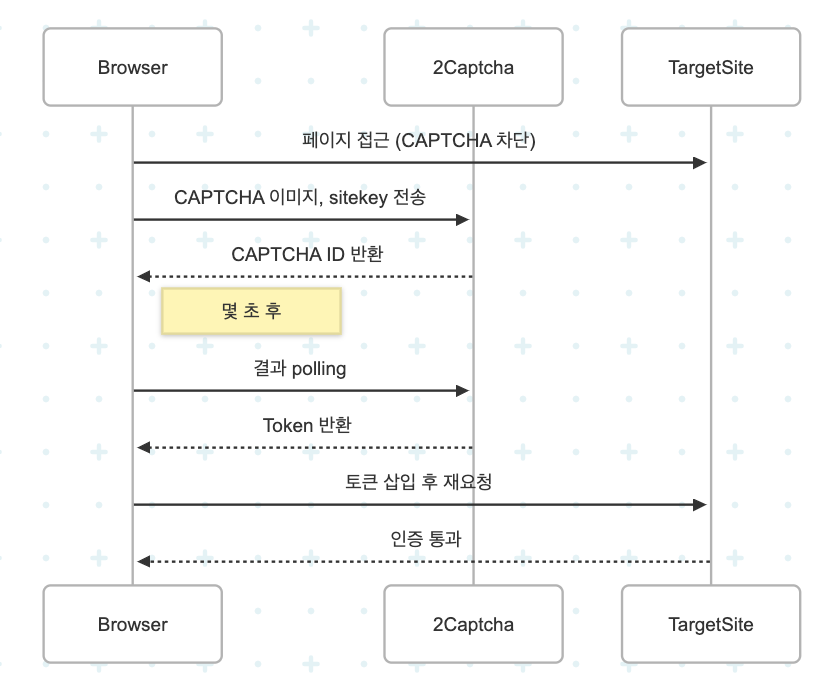
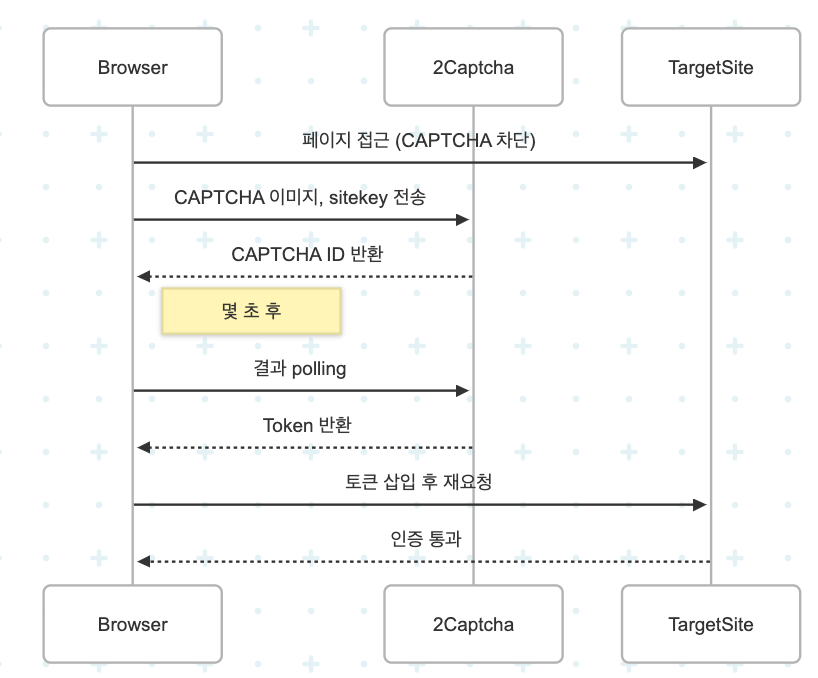
🔧 2Captcha 사용 흐름
- 이미지/HTML/CAPTCHA 유형 수집
- 2Captcha 서버에 요청 (API Key 필요)
- 수초 후 결과 polling (token 반환)
- 페이지에 token 삽입 + 제출
예시 (Node.js)
// 요청
const response = await fetch(`http://2captcha.com/in.php?key=API_KEY&method=userrecaptcha&googlekey=${sitekey}&pageurl=${url}`);
// 응답 polling
const result = await fetch(`http://2captcha.com/res.php?key=API_KEY&action=get&id=CAPTCHA_ID`);✅ 주의:
- 보통 응답까지 5~30초 걸림
- token은 직접
input[name="g-recaptcha-response"]에 삽입해야 함
🌐 Proxy & VPN 기초 개념
🧠 프록시(Proxy): 실제 IP 대신 서버를 통해 요청을 보내는 중간 서버. 서버에게 ‘나 말고 얘가 보낸 것처럼’ 보이게 한다.
🔀 Proxy vs VPN
| 항목 | Proxy | VPN |
|---|---|---|
| 적용 범위 | 단일 프로그램 (e.g., Puppeteer) | 전체 시스템 |
| 속도 | 빠름 | 느릴 수 있음 |
| 보안성 | 낮음 (암호화 없음) | 높음 (전체 트래픽 암호화) |
| 용도 | 크롤링, IP 회전 | 보안 접속, 지역 제한 해제 |
🧩 Proxy 종류
| 유형 | 설명 |
|---|---|
| Datacenter Proxy | 가장 저렴, 차단 위험 높음 |
| Residential Proxy | 가정용 IP → 사람처럼 보임 |
| Mobile Proxy | LTE/5G 네트워크 → 최고 위장성 |
✅ 쿠팡은 Datacenter IP를 빠르게 차단함 → Residential Proxy 또는 VPN이 더 적합
🛠️ Puppeteer에서 프록시 적용
const browser = await puppeteer.launch({
args: ['--proxy-server=http://username:password@proxy-ip:port']
});- IP 회전을 위해 여러 개의 프록시를 순환할 수 있는 구조 필요
- 각 요청마다 프록시를 바꾸려면 브라우저 새로 띄워야 함
💡 VPN 자동화?
# 예시: NordVPN CLI, openvpn
nordvpn connect Korea- 전체 트래픽을 VPN을 통해 보낼 수 있지만,
- Puppeteer는 VPN보단 Proxy 기반 회전 구조가 더 실용적
🚀 프로젝트 접목 시 고려사항
| 고려 항목 | 전략 |
|---|---|
| CAPTCHA 등장 시 | 2Captcha 연동 자동화 |
| IP 차단 우려 | Residential Proxy 도입 |
| 크롤링 속도 | 일정량 이하로 분산 요청 (rate limit) |
| 지역 제한 | 한국 VPN 우회 또는 한국 IP 기반 Proxy |
| 멀티상품 수집 | 각 상품마다 proxy 교체 or 브라우저 분리 |
