오늘은 지금까지 작업을 했던 검색에 관련된 모든 로직을 설명하는 회고를 해보려고 한다.
현재 작업중인 페이지는 망고플레이트, 다이닝코드와 비슷하지만
결이 약간 다른 형태의 식당 리뷰 사이트 를 구현하고 있으며 특정 사이트를 크롤링하여 정보를 가져오거나
가게를 기반으로 리뷰가 작성되는 것이 아닌
사용자에 의하여 작성된 리뷰를 바탕으로 돌아가는 사이트를 구상하고 진행하고 있는 상태다.
그렇기에 사용자가 많아야지만 빛을 볼 수 있는 구조지만, 서비스 런칭을 계산하고 기획을 한 것이 아니라서
이 부분은 생각에서 조금 미뤄놓은 상태랄까.
아무튼
검색이 중요한 이유
검색은 정말 많은 경우의 수를 계산해서 작업해야한다.
구글에서도 맨날 난 A의 내용만 보고 싶은데 A의 내용이 있는 B라던가
A인 것처럼 보이는 C같은 검색내용이 나오는 경우가 있고
키워드가 길어질 경우 이것은 꼭 들어가야함! 이라는 조건이 달리는 것을 본 적이 있을 것이다.
이처럼 검색은 데이터를 다룸에 있어 고민을 할수록 정교하게 짜여질 수 있다.
Elasticsearch에서의 검색이란
엘라스틱서치는 강력한 검색엔진으로 다양한 옵션을 제공해주고 있다.
기본적으로 NoSQL처럼 사용할 수 있으며 역인덱싱을 지원하여
문자열이 들어갈 경우 띄어쓰기 간격으로 토큰화시키는 것을 특징으로 가지고 있다.
"벨로그 팀프로젝트 16일차 기술 회고" 로 저장을 할 경우 매핑을 지정하는 것이 아닌 다이나믹 매핑이 적용된다면
벨로그 / 팀프로젝트 / 16일차 / 기술 / 회고 이런식으로 분리되어 검색이 가능케한다.
또한 스코어라는 것이 존재하여 조금 더 검색한 키워드에 밀접한 것을 골라서 사용자에게 돌려주는 기능도 존재한다.
나는 여기서 아직까지는 복잡한 것은 사용을 하지 않았고, 간단한 것으로 작업을 진행했다.
제목을 기반으로 한 Elasticsearch 코드 with nestjs
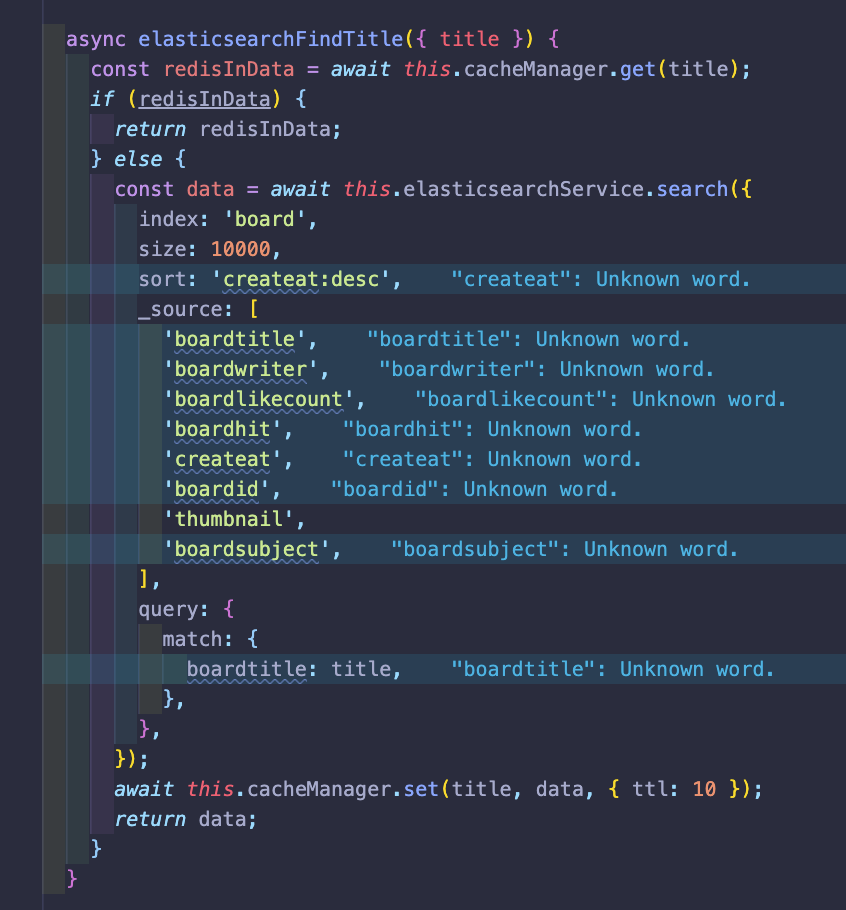
사실 typeorm(sql)에서도 like문을 사용한 검색을 할 수 있지만 그것은 풀텍스트 검색이라 속도가 느리고
그것보다는 이쪽이 속도가 훨씬 빠르기에 조건의 일부가 들어가는 경우에는 모조리 ELK를 사용하기로 했다.
또한 검색을 위하여 모든 정보를 logstash로 하여금 저장하지만, 실제로 검색을 해서 보여주는 것에는
내용이라던가 업데이트시간같은 불필요 요소들을 제거하기 위하여
_source:[] 속에 보여주고 싶은 것만 담아놓았다.
추가로 anlyzer와 mapping을 위하여 커스텀 템플릿도 적용을 해놓았고, 아래는 템플릿의 일부다.
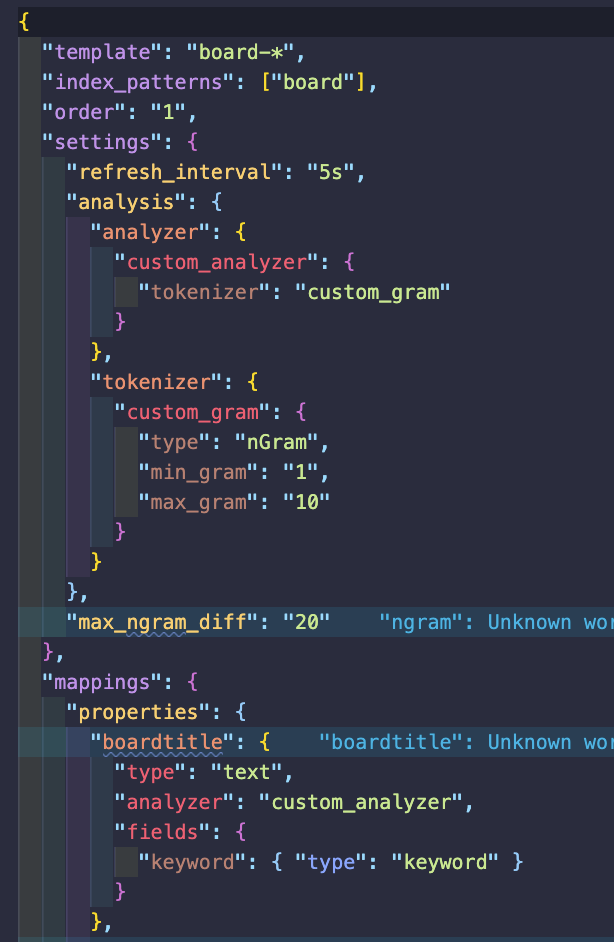
nGram은 모든 문자를 모조리 다 잘라버려서 좋은 성능을 내긴 힘들지만 차후 개선을 하기로 하고
min 10 - max 10으로 조정을 해놓은 상태다.
사실 와일드카드로 nGram을 적용하지 않고 사용하는 방법도 존재하긴 하지만
와일드카드쓰는건 바보라는 이야기를 어디서 본 것 같아서(....) 그냥 아날라이저를 적용시켜봤다.
태그를 기반으로 한 Elasticsearch 코드 with nestjs

우리 사이트에는 검색을 할 수 있는 카테고리가 총 5개가 존재한다.
- 지역
- 메뉴
- 분위기
- 성별
- 연령대
하지만 지역,메뉴,분위기는 1개의 테이블에 모든 것을 구현하는 형식으로 되어있는데
사실 Typeorm으로 where + andWhere 조건을 걸어서 검색을 할 수 있다는 것은 알고 있지만
orWhere까지는 하겠는데 도대체가 어떻게 코드를 짜야할지 모르겠어서 (접근은 할 줄 알겠는데)
배포가이드도 안나온 상황에 무작정 Elk 배포를 우선으로 작업하여 코드를 구현해놓았다.
검색과정은 다양한 태그가 분리되어있는 것을 GROUP_CONCAT을 사용하여 한개로 다 합쳐버린 후
그것으로 검색을 하게끔 코드를 구현해놓았다.
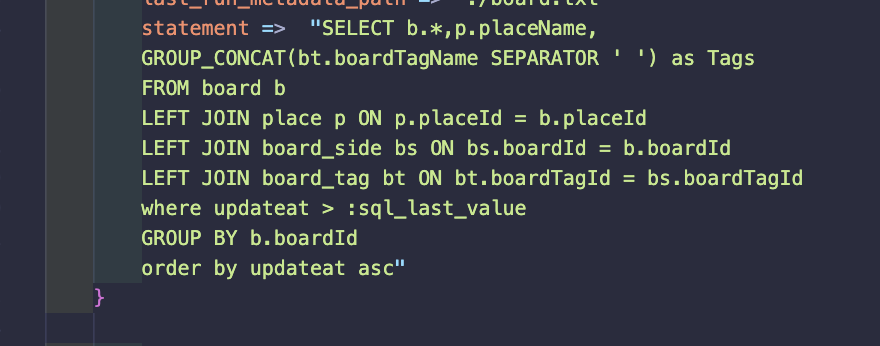
여기서 내 나름대로 짱구를 많이 굴렸다고 생각하는 것은 바로 구분자를 공백으로 놨다는 것이다.
왜냐하면 엘라스틱서치는 공백을 기준으로 토큰화를 시키기 때문에 검색 키워드도 배열로 받지만,
그것을 공백으로 분리해서 검색조건으로 사용할 경우 AND 조건처럼 사용할 수 있게 만들 수 있다는 것이였다.

(엘라스틱서치에 저장되어있는 tags의 데이터 모양)
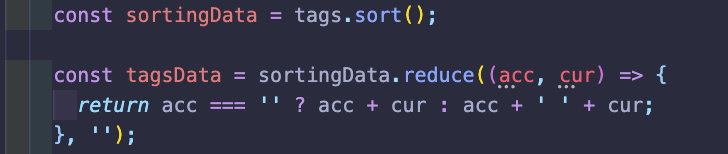
추가로 검색 조건에 정렬 기능을 추가했다.
다이닝코드같은 경우 같은 것을 두번 누르면 캐시가 적용이 되서 빠르게 나오는 것을 확인할 수 있었다.
하지만 10대 -> 20대를 누른 것과 20대 -> 10대를 누른 것은 분명 동일한 정보임에도 불구하고
캐시적용이 되지 않는 것을 확인하고, 검색의 입력값이 들어왔을 경우 정렬을 하게끔 적용을 해놓았다.
물론 이미 이것들을 모두 지나쳐온 선배 개발자분들이라면 대단한게 아닌데 라고 할 수도 있겠지만
이런 소소한 차이때문에 큰 즐거움을 얻으며 프로젝트를 진행하고 있다.
1개의 키워드를 기반으로 한 typeorm 코드
음식 리뷰 사이트답게 각각의 유저들이 선호하는 성향을 보여주기 위하여
본인이 좋아하는 메뉴, 본인의 성별, 본인의 연령대를 작성하는 것이 회원가입 란에 존재하는데
(선택을 안해도 된다고 옵션을 넣어놓긴 했다.)
그것을 게시판에 Entity에 넣어놓은 후 작업이 진행되었다.
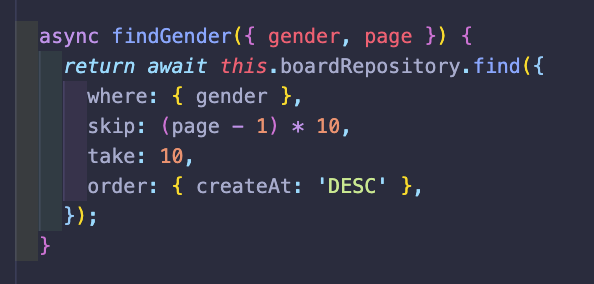
페이지네이션 옵션도 걸려있는데, 이것은 메인 페이지에 옆으로 미는 스크롤 형태로 존재하고
모든 것을 보여줄 생각이 없어서 걸어놓았다. 생각해보면 skip은 필요 없을지도 모르겠다.
한달간의 best 글 찾는 typeorm 코드
보통 커뮤니티 사이트를 보면 어지간하면 다 들어가있는 것이
좋아요를 제일 많이 받은 글이 어딘가에 다른 탭으로 보여져있는 것인데, 이것을 구현하고 싶어서 추가를 해보았다.
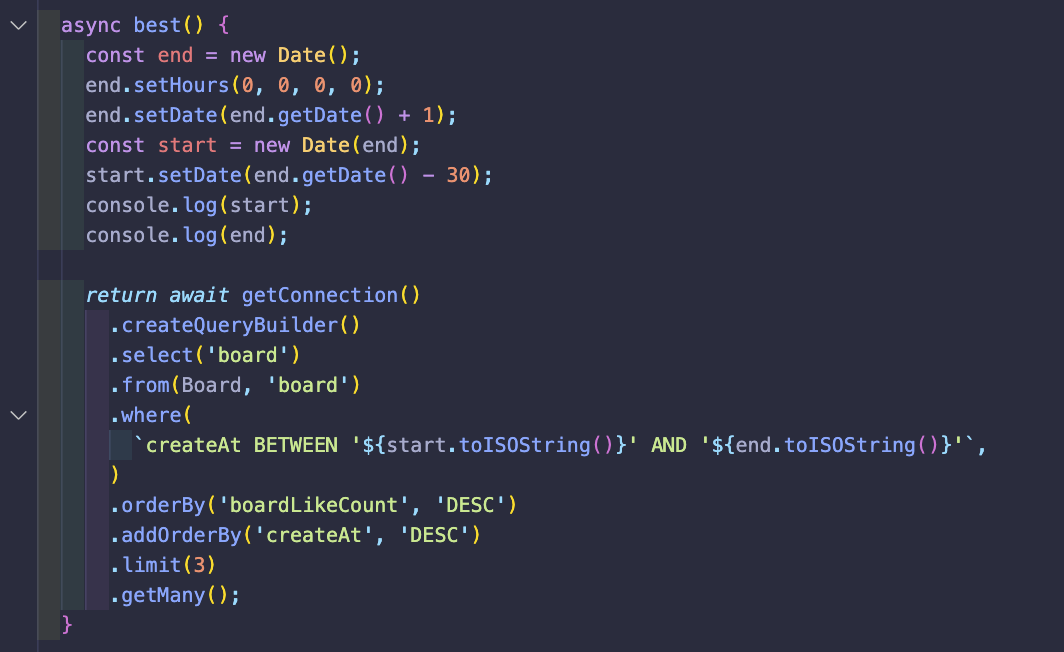
오늘로부터 과거 1달간 좋아요를 제일 많이 받은 글을 검색하기 위하여 위의 사진과 같은 코드를 적용시켰다.
날짜 객체를 거의 처음 써보았고, BETWEEN이라는 SQL 구문도 처음 사용해봐서 엄청 새로웠는데
일단 new Date()로 서버시간을 따오고, 기본 시간 세팅을 0시 0분 0초 00으로 적용한 후 날짜를 +1
24일에 저것을 사용하면 25일 00시 00분 00초 00이 end에 지정되게 된다.
그리고 start는 end 시간을 기반으로, 30일을 빼버린다.
그렇다면 5월 24일이라면 4월 25일 00시 00분 00초로 지정이 되게 되는 것이다.
이렇게 시간을 지정해놨고, createAt이 생성날짜임으로 생성날짜를 조건을 걸어서
4월 25일부터 5월 25일까지 생성된 글 중에서
orderBy 좋아요 갯수가 제일 많은 글이 우선적으로 보이게 끔 하고
동일한 좋아요를 받았을 경우, 최근에 작성된 글이 우선순위가 높도록
addOrderBy로 2중 정렬을 걸어놓은 후
3개만 보여주는 것이 UX상으로도 금,은,동 메달(?)처럼 예쁘게 보이기 때문에
limit(3)을 걸어줌으로써 내가 원하는 조건에 딱 맞는 코드를 만들 수 있게 됐다.
계속 느끼고 있는게 무엇이냐면, 나는 정말 데이터를 다루는 것이 재밌다는 것이다.
논리를 복잡하게 해야하기 때문에 다양한 조건을 기반으로 데이터를 뽑아내고,
여러가지 조건에 맞게 정렬을 하는 그 과정 자체가 너무 즐거운데
내가 현재 배우고 있는 nestjs는 현재 신사업에서나 사용을 하고 있으며
nodejs는 백엔드의 주축이 아니고, 데이터를 다루는 직군에서는 Ruby와 python을 많이 쓴다는 것이 아쉬울 따름이다.
가능하다면, 만약 가능하다면 나는 조금 더 검색이라던지 데이터를 유저에게 보여주는 일을 해보고 싶기에 노력을 더 많이 해봐야할 것 같다.
