안된다고 계속 붙잡지말고 되는 것부터 하자
현재 쿼리문으로 검색하는 기능을 도대체 해결을 어떻게 해야할지 몰라서 정말 너무 답답한 상황이였다.
게시글의 구조는 아래 사진과 같다.
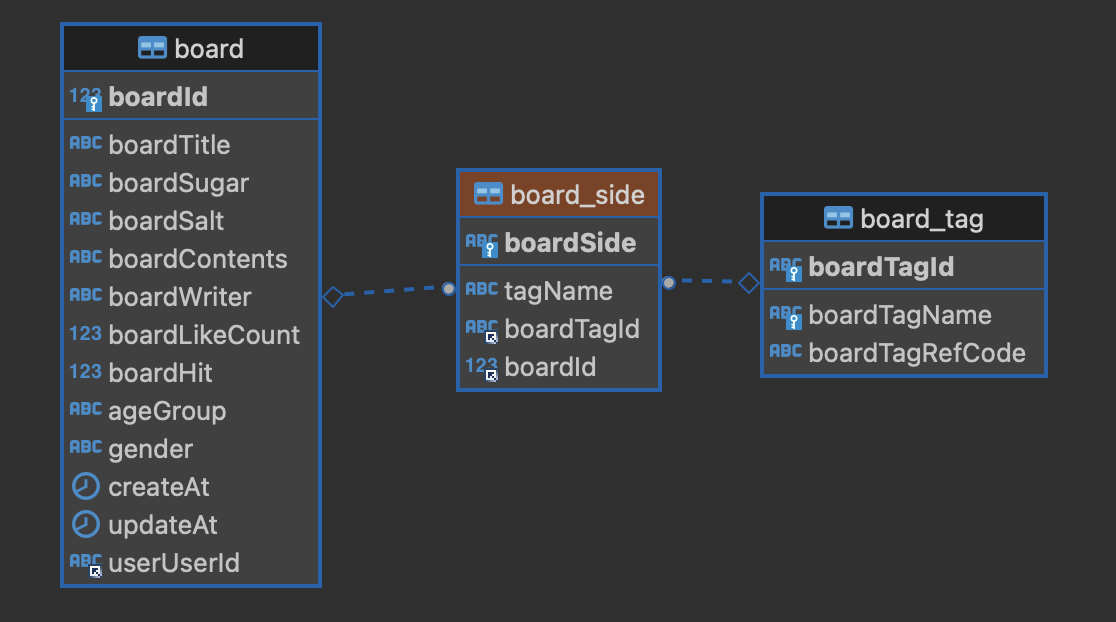
이렇게 되었을 경우, 태그가 N개가 들어가있는 게시글을 검색해오는 쿼리문을 TypeORM으로 짜야하는데
태그의 갯수가 고정적일 때는 문제가 없었지만
태그의 갯수가 유동적이라면 어떻게 해야하는가? 에 대해서 고민을 하다가 지금 내 수준에서는 할 수 없다! 라고 판단을 바로 했다.
그래서 방향성을 돌려서 NoSQL와도 비슷한 역할을 하는 Elasticsearch의 도움을 받기로 결정했다.
너가 하고싶다고 하면 문제가 없게?
지금까지 했던 회고에 언급을 했던 기억이 있는 것 같은데 아무튼..
원래는 ELK 스택 배포 가이드가 나왔었지만, 현재 그것을 사용할 수 없는 상태가 되어 그냥 처음부터 일일히 모조리 해볼 수 밖에 없었다.
그래서 집의 데스크탑에 VM으로 우분투를 설치하여 컴퓨터를 끄지 않은 상태라면 문제가 되지 않을 것 같고
9700K 2080Ti 32GB가 박혀있기에 어느정도 비중을 둬도 문제가 없을 것이라고 생각해서 바로 작업을 시작했다.
내가 사용한 우분투 버전은 18.04 LTS으로 진행을 하였다.
일단 apt부터 업데이트를 해야하기 때문에 이것부터 고쳐주자.
기존에 누군가 사용하던 것이라면 함부로 할 수 없겠지만, 새것이라 문제가 없다.
- sudo apt update
- sudo apt upgrade
만약 여기서 nginx nginx.service: Failed with result 'exit-code' 에러가 발생한다면
루트파일로 돌아가서
etc/nginx sudo vi nginx.conf에 보면 [::] 라고 적혀있는 부분이 있는데
이부분이 https 설정을 해주는 값이라, 인증서 관련으로 문제가 발생할 수 있어서 주석처리를 해주면 해결된다.
도커를 사용하여 올려놓을 것이기 때문에 도커를 깔아준다.
- sudo apt install docker.io
나눠서 사용하는 사람이라면 괜찮겠지만, 나는 그냥 ELK를 하나로 묶어서 사용할 작정이기에
docker-compose를 깔아야한다.
apt를 통해서 설치를 할 경우에는 예전 버전이 설치되는 문제가 현재 있어서 다른 방법으로 설치를 해줘야한다.
- mkdir -p ~/.docker/cli-plugins/ <- 그냥 폴더 만들기
- curl -SL https://github.com/docker/compose/releases/download/v2.2.3/docker-compose-linux-x86_64 -o ~/.docker/cli-plugins/docker-compose <- 다운로드
- chmod +x ~/.docker/cli-plugins/docker-compose <- 접근 권한 부여
- docker compose version <- 잘 깔렸는지 확인
- sudo usermod -aG docker 현재 작업하는 우분투 계정 이름 <- root 권한 부여
이제 docker-compose yaml 파일과
logstash에서 사용할 logstash.conf 파일을 만들어야한다.
굳이 어렵게 다 타이핑하지말고 미리 만들어놨던 것을 깃허브에 올려서 끌어오는 방식이 제일 현명하다.
깃이 깔려있지 않을 수 있는데 안깔려있으면 새로 깔자
- sudo apt-get install git
- sudo apt install git
- git clone 가져올 url (프라이빗이면 토큰 받아서 로그인해가지고 가져오면 된다.)
그리고 docker-compose build -> up을 하면 사용할 수 있게 된다.
만약 skip이 발생할 경우에는 강제로 실행시켜버리는 방법이 있다.
sudo docker-compose up --force-recreate
이제 우분투에서 작업하는 것은 대부분 해결이 됐는데, 아직 처리를 해야할 것이 남아있다.
그 부분을 하나하나 바로잡아가보도록 하자.
GCP에서 해야하는 일
일단 GCP에서는 SQL을 공개설정을 해줘야한다.
공개설정을 하지 않으면 프로젝트 내부에서 작업하는 것이 아니고
외부 컴퓨터에서 접근을 할 수 있어야 하기 때문이다.
공개 설정을 한다고 해서 아무나 접근을 할 수 있는 것은 또 아니기에 걱정은 하지 않아도 된다.
(아마도, 설정을 하지 않으면 DBevaer로 접근이 되지 않았기 때문에 확실하다고 생각한다.)
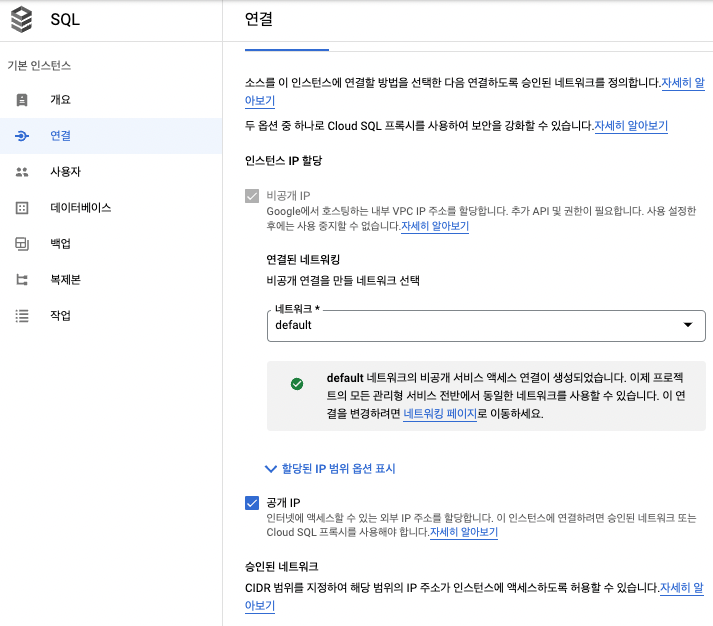
아래 보면 승인된 네트워크라고 적혀있는데, 이 부분에서 접근을 하려는 IP 주소를 넣어주면 된다.
0.0.0.0/0 넣으면 진짜 아무나 다 들어올 수 있으니까 절대로 설정하지 않도록 하자.
우분투의 IP를 확인해보자.
hostname -I (대문자임)
확인된 IP를 승인된 네트워크에 넣고 저장하자.
만약 GCP가 아닌 내 컴퓨터에서 디비를 읽어보고 싶다면 본인의 IP도 넣으면 접근 권한을 얻게 된다.
그 다음은 우분투의 lostash.conf 파일을 수정해주는 작업을 진행하자.
수정을 하는데 문제가 발생한다면
sudo vi lostash.conf 로 들어가서
i를 눌러 수정모드로 들어가고
나올때는 :wq! 로 나오면 된다.
input {
jdbc {
jdbc_driver_library => "/usr/share/logstash/mysql-connector-java-8.0.28.jar" <- 도커 컴포즈에서 설치한 경로
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://공개주소 아이피:3306/gcp sql 디비에 생성한 디비 이름"
jdbc_user => "DB 아이디"
jdbc_password => "DB 비번"
}
}
output {
elasticsearch {
hosts => ["elasticsearch:9200"]
}
}이러면 해당하는 우분투의 ip + :9200을 했을 경우 엘라스틱서치를 확인할 수 있게 된다.
이제 우분투 엘라스틱 서치에 올라가있는 정보를 긁어오기 위하여 코드도 수정작업을 해주도록 하자.
코드 수정
@Module({
imports: [
TypeOrmModule.forFeature([Board, BoardTag, BoardSide]),
ElasticsearchModule.register({
node: 'http://우분투 IP 주소:9200',
}),
],
providers: [
//
BoardResolver,
BoardService,
],
})
export class BoardModule {}이러면 모든 연동이 끝났다.
이제 기본적인 엘라스틱 서치의 메소드를 활용하여 검색을 해보면 된다.
여기까지는 처리하는 방법론이였고 또 다시 문제가 발생한 이야기
엘라스틱서치는 기본적으로 역인덱싱을 하기 때문에 띄어쓰기가 존재하는 것 만으로도 검색을 할 수 있는 구조다.
그래서 조금 더 디테일한 검색을 하기 위해서는 type을 지정해준다거나 (Text,Keyword)
커스텀 아날라이저를 만들어서 사용해주는 작업이 필요하다.
아무튼 또 다시 문제가 되었던 것은 다양한 컬럼에서의 검색이 문제가 되었다.
내가 맨 처음 이식을 하였을때는 아래의 쿼리문처럼
# GROUP_CONCAT(case when bt.boardTagRefCode = 'MENU' then bt.boardTagName end SEPARATOR ' ') as MENU,
# GROUP_CONCAT(case when bt.boardTagRefCode = 'REGION' then bt.boardTagName end SEPARATOR ' ') as REGION,
# GROUP_CONCAT(case when bt.boardTagRefCode = 'MOOD' then bt.boardTagName end SEPARATOR ' ') as MOOD지역의 정보를 지역 : "정보 정보 정보"
메뉴의 정보를 메뉴 : "메뉴 메뉴 메뉴"
분위기의 정보를 분위기 : "분위기 분위기 분위기" 이렇게 설정을 해놓았는데
쿼리문 작성을 도와주신 지웅님께 감사를 표합니다
태그의 숫자가 지 마음대로 나오다보니 빈 값이 존재하면 고장이 난다는 것을 확인하게 되었다(....)
그래서 그냥 한개로 합쳐버렸다, 굳이 분리해놨는데 정말(....)
그리고 그 값으로 AND 조건을 걸어서 검색하는 기능을 구현해놨다.
해당하는 qruey의 코드
@Query(() => GraphQLJSONObject)
async fetchBoardWithTags(
//
@Args('tags') tags: Tags,
) {
const tagsData = tags.names.reduce((acc, cur) => {
const tag = cur.substring(1);
return acc === '' ? acc + tag : acc + ' ' + tag;
}, '');
const redisInData = await this.cacheManager.get(tagsData);
if (redisInData) {
return redisInData;
} else {
const data = await this.elasticsearchService.search({
index: 'board',
size: 100,
sort: 'createat', // <- 이거 지금 정렬을 거꾸로 해야하는데 어떻게 해야하는지 확인이 안되고 있어서 지금 고민이다
_source: [ // 보고싶은 테이블만 적어놓기
'boardtitle',
'boardwriter',
'boardlikecount',
'boardhit',
'createat',
],
query: {
match: {
tags: {
query: tagsData,
operator: 'and', // and 조건걸기
},
},
},
});
await this.cacheManager.set(tagsData, data, { ttl: 30 });
return data;
}
}여기서도 살짝 문제가 발생했는데, 검색을 할 경우에 띄어쓰기가 존재한 형태로 검색어를 설정해야한다는 것이였다. (역인덱싱때문에)
프론트에 "태그 태그 태그" 의 형태로 보내줄 수 있냐? 라고 물어봤더니 그건 안될 것 같다면서 배열로 보내주는 것으로 이야기가 됐다.
태그는 기본적으로 #이 붙어있을테니 #을 떼버리고, 사이에 공백을 추가하는 식으로 reduce를 돌려놨고
한번 검색한 내용에 한해서는 빠른 검색을 지원할 계획이였기에 redis에 캐싱을 설정해놓았다.
아무튼 일단, 정말 1단(...) 어느정도 해결이 되었고 다른 부분의 작업이 완료가 되면 조금 리팩토링 과정을 거쳐야할 것이라고 생각하고 있다.
일단 역정렬부터... 지금 최신글부터 줘야하는데 과거 글부터 주고 있다(....)
또한 더더더더더더더더욱 SQL이 불편할 경우도 있다는 것을 몸으로 체감하게 되는 날이였다.
배열만 사용할 수 있으면 쿼리문이 복잡하지 않았을텐데
배열을 사용할 수 없다보니 1:N 관계가 생성되어 테이블이 low로 쌓이게 되어 정보를 가져오는데 큰 애를 먹었다.
해결도 못하고 옆으로 돌아가서 참...
어떻게든 되기야하면 됐다고 생각할 수도 있는데 3일 4일 넘게 고민하다가 내린 해답이 도망치기라서 좀 아쉽다.
