해당 게시글은 세명컴퓨터고등학교 보안과 동아리 세미나 발표 내용을 블로그 형식으로 정리한 글로, 본 글의 저작권은 yulmwu (김준영)에게 있습니다. 개인적인 용도로만 사용 가능하며, 상업적 목적의 무단 복제, 배포, 또는 변형을 금지합니다.
글에 오류가 댓글로 남겨주시거나 피드백해주시면 감사드리겠습니다.
포스팅에서 사용한 소스코드는 깃허브에 올려두었습니다. 아래의 링크에 방문하여 확인하실 수 있습니다.
https://github.com/yulmwu/aws-image-resize-lambda
발표에 사용된 프레젠테이션(PPT)는 완성되는 대로 해당 포스팅에 첨부하겠습니다.
...
0. Overview
웹 최적화의 요소엔 여러가지가 있다. 대표적으로 성능 최적화, 검색 엔진 최적화(SEO), 웹 표준성, 접근성 등이 있을 것이다.
이 중 성능 최적화에서 페이지 로딩 속도를 늦추는 대표적인 요소가 있는데, 바로 이미지이다.
물론 작은 사이즈의 이미지라면 봐줄만한 속도로 로딩되겠지만, 사진의 크기가 커진다면 로딩 속도 또한 매우 느려질 것이다. 예를 들어 아래의 경우를 보도록 하자.
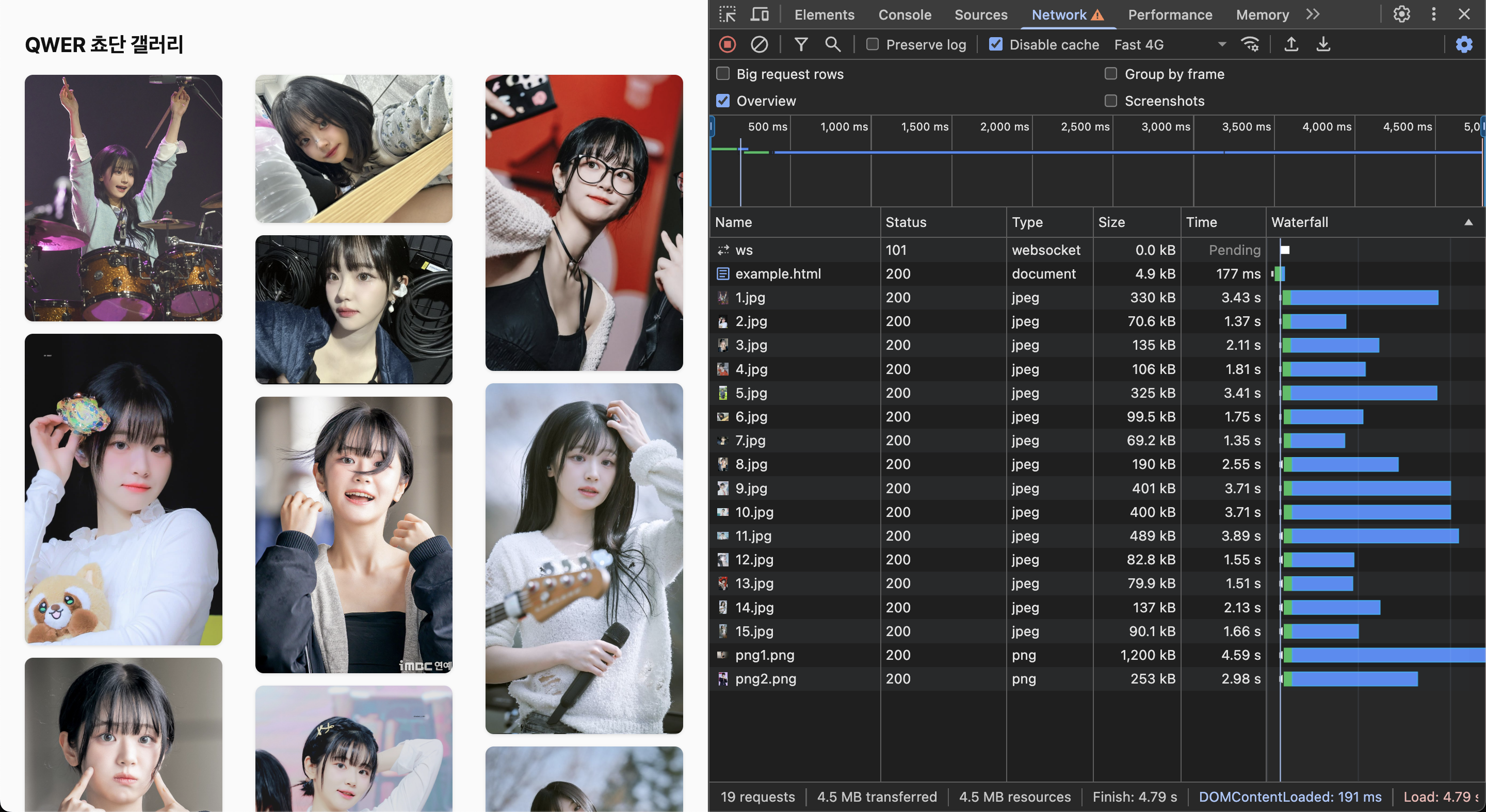
S3 + CloudFront를 통해 CDN을 만들고, 이미지들을 나열하는 단순한 페이지이다.
테스트를 위해 DevTools에서 Fast 4G로 쓰로틀링 해주었는데, 약 4.8초가 걸리며 리소스의 사이즈는 약 4.5MB 정도 되는것을 볼 수 있다.
Testing with LightHouse
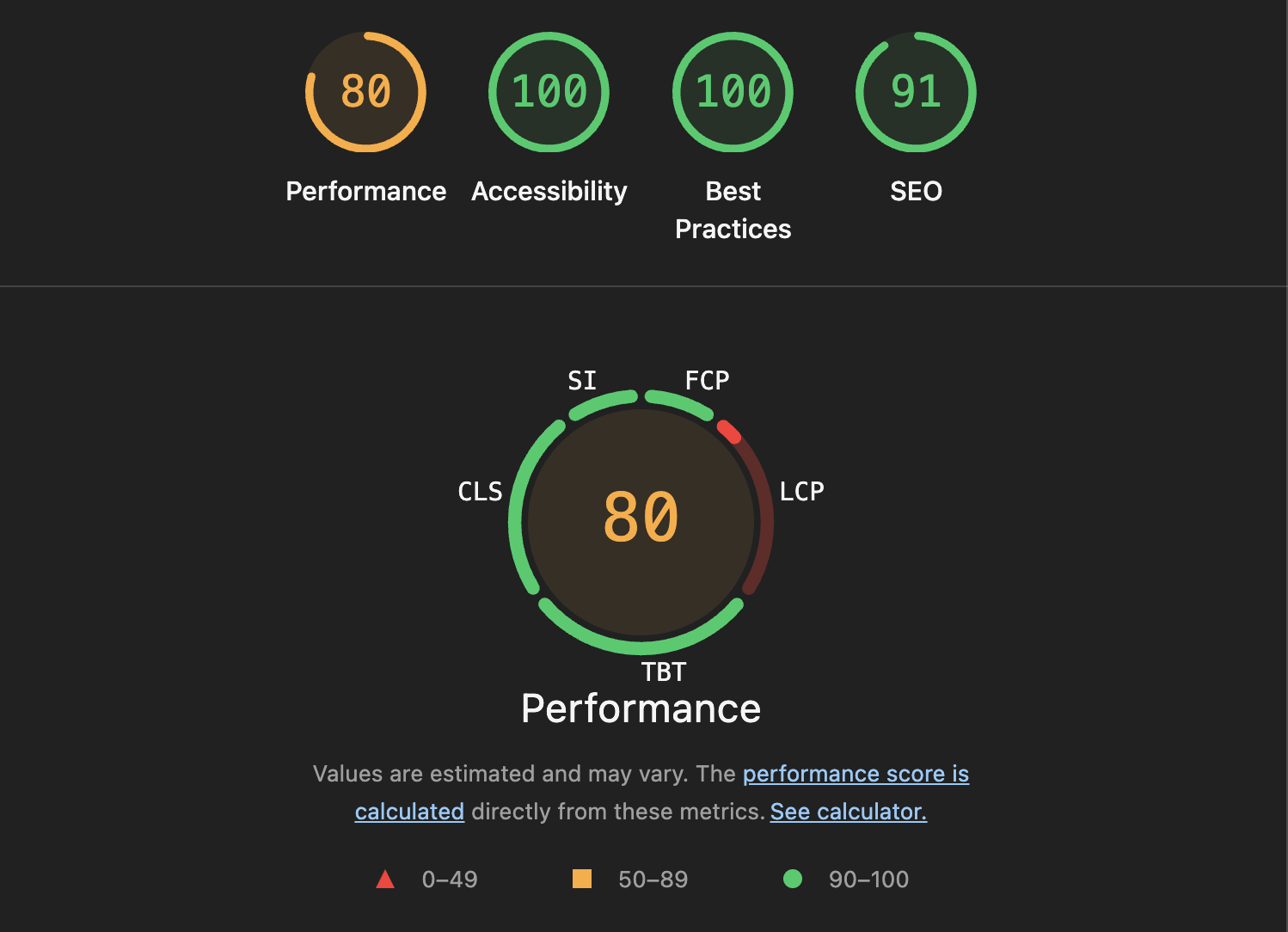
크롬 DevTools LightHouse에서 테스트해보면 데스크탑 환경에서 LCP(Largest Contentful Paint)가 높은 것을 볼 수 있다.
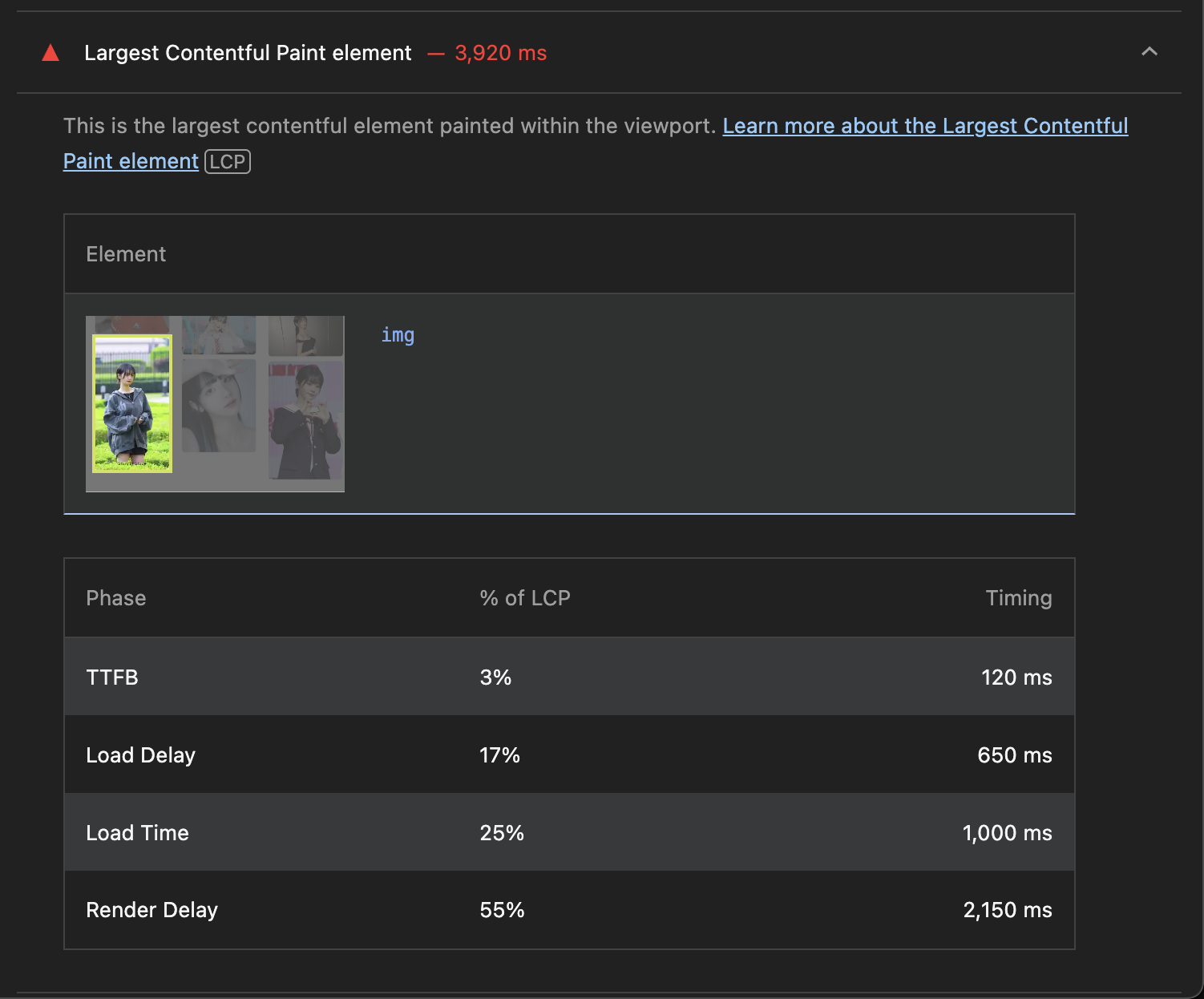
일반적으로 LCP는 2.5초 미만이여야 "좋음"으로 본다. 그런데 데이터를 가져오고 랜더링하기 까지 약 4초가 걸려서 저러한 처참한 결과가 나타난 것이다. (이미지 사이즈가 커서 랜더링 또한 오래 걸린다.)
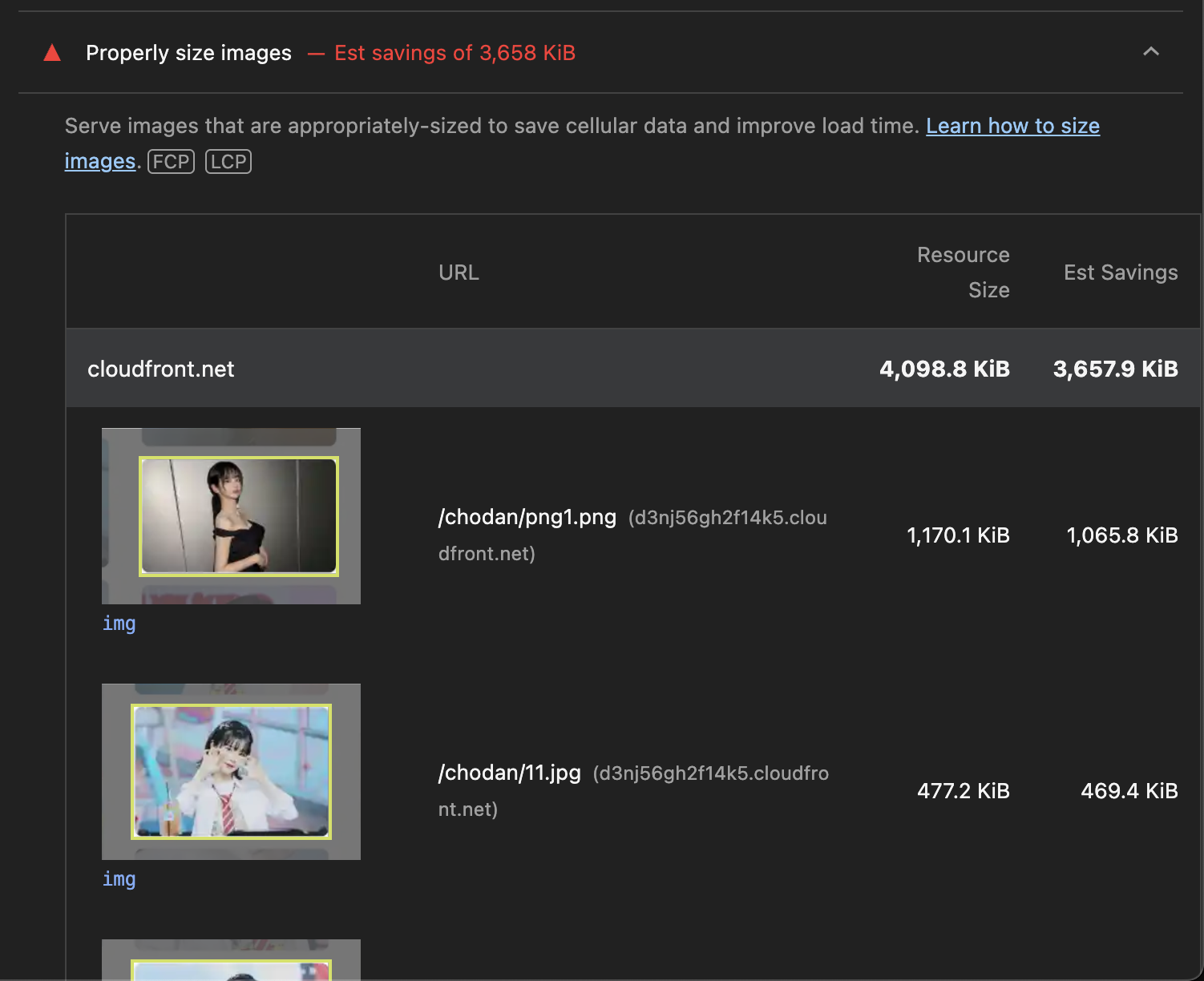
그리고 LightHouse에서 절감할 수 있는 이미지 용량을 추정해준다. 랜더링된 요소에서 불필요한 용량을 추정해주는 것이다.
How to solve a problem?
이 문제를 해결할 방법은 간단하다. 서버에서 제공해주는 이미지의 크기를 적절하게 줄이면 된다. 그러면 용량도 줄어들테고, 랜더링 시간도 줄어들어 LCP 또한 낮아져 최적화를 할 수 있다.
또한 굳이 고화질이 아니여도 표시될 이미지가 잘 보여지기만 하면 되고, 고화질의 이미지가 필요한 경우는 해당 이미지를 상세히 보는 등의 경우이기 때문에 작게 표시될 이미지의 사이즈는 작아도 된다.
리사이징된 이미지의 크기는 표시 크기(CSS width/height) * DPR(Display Pixel Raito)로 계산한다. 일반적으로 DPR은 1~1.5 정도이지만, 애플의 Retina 디스플레이 등의 고밀도 디스플레이의 경우 DPR이 2 이상일 수 있다고 한다.
Image Resizing
본 포스팅에선 이미지 리사이징 기능을 CDN 서비스인 CloudFront와 Lambda@Edge를 사용하여 구현해볼 것이다. 이미지 리사이징의 구현 방식엔 여러가지가 있다. 필자가 생각하는 방식엔 크게 2가지가 있을 것이다.
- 이미지 업로드 후 S3 버킷에 리사이징된 이미지 저장
- 이미지 요청 시 즉석에서 리사이징 후 응답(On the Fly)
첫번째의 경우 캐싱이 되지 않을 경우 유리하다. 버킷에 리사이징된 이미지가 저장되어 있기 때문에 해당 이미지를 가져오면 된다.
하지만 미리 정해진 사이즈로 리사이징된 이미지만 저장된다는 점과 버킷 저장 용량이 증가한다는 단점이 있다.
두번째의 경우는 CloudFront와 같이 캐싱이 되는 경우 유리한데, 이미지를 동적으로 리사이징 후 캐싱하기 때문에 한번 처리하고 나면 빠르게 캐싱 + 리사이징된 이미지를 가져올 수 있다. (S3 버킷 저장 없음)
다만 캐싱이 되기 전(Cache Miss) 첫번째 요청에 대해선 이미지 리사이징을 실시간으로 해야하기 때문에 그에 따른 레이턴시가 생기게 된다.
본 포스팅에선 2번째 방식을 사용한다.
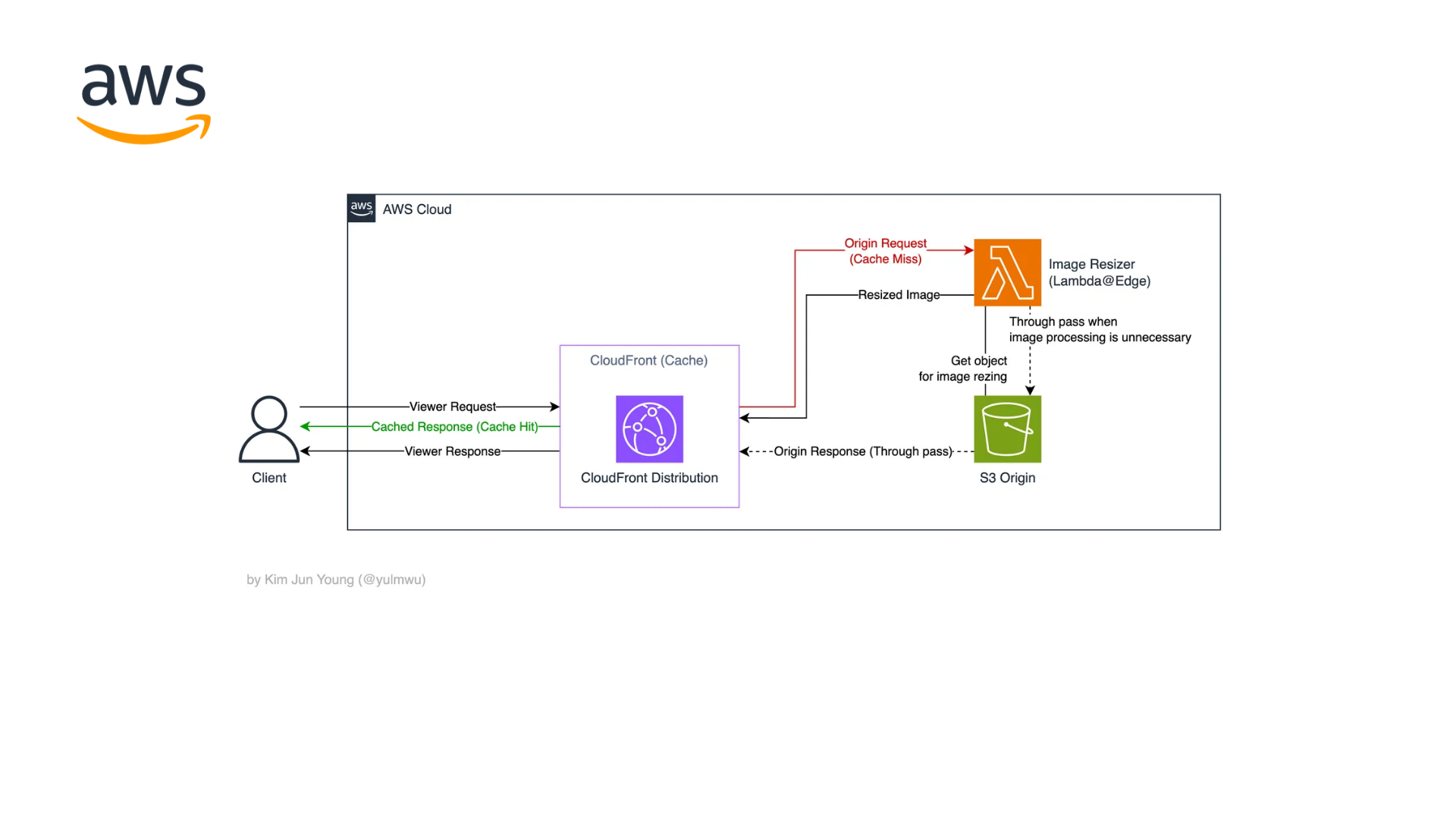
1. AWS Architecture
먼저 전체적인 아키텍처를 보기 전, CloudFront의 요청-응답 과정을 보도록 하자.
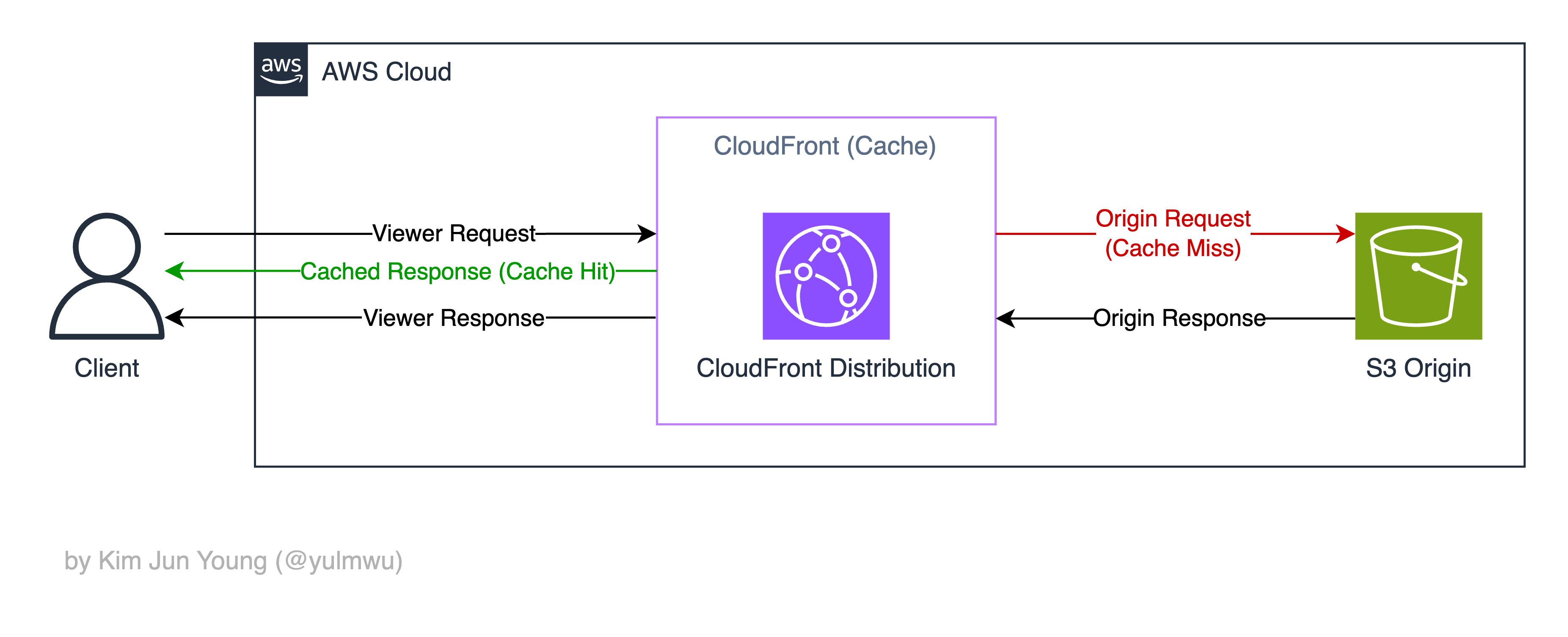
클라이언트가 CloudFront에 어느 이미지를 요청한다고 가정하자. 그러면 View Request로 CloudFront에 요청이 가게 된다.
이후 CloudFront에서 해당 이미지가 캐싱되어 있다면 Cache Hit로 해당 이미지를 바로 응답한다.

그런데 만약 캐싱된게 없다면 오리진(원본) 서버(S3 Origin)에서 해당 이미지를 가져오게 된다. 이때 오리진 서버에 CloudFront가 요청하는데, 이를 Origin Request라고 한다.
오리진 서버의 응답(Origin Response)은 CloudFront로 돌아가 캐싱되고, 클라이언트에 최종적으로 응답한다. (Viewer Response)
그럼 여기서 이미지 리사이징을 구현하려면 어디에서 작업해야 할까? 일단 Viewer Request/Response는 CloudFront 캐싱의 이점을 잃기 때문에 사용하지 않고, Origin Request 또는 Origin Response에서 작업한다.
Response에서 S3 결과물을 가져오는 방식으로 사용할 수 있다면 좋겠지만, 람다 이벤트 페이로드로 CloudFront Origin Response 바디는 포함하지 않기 때문에 Origin Request에서 동작하도록 하였다. 즉 구축해볼 아키텍처는 아래와 같다.
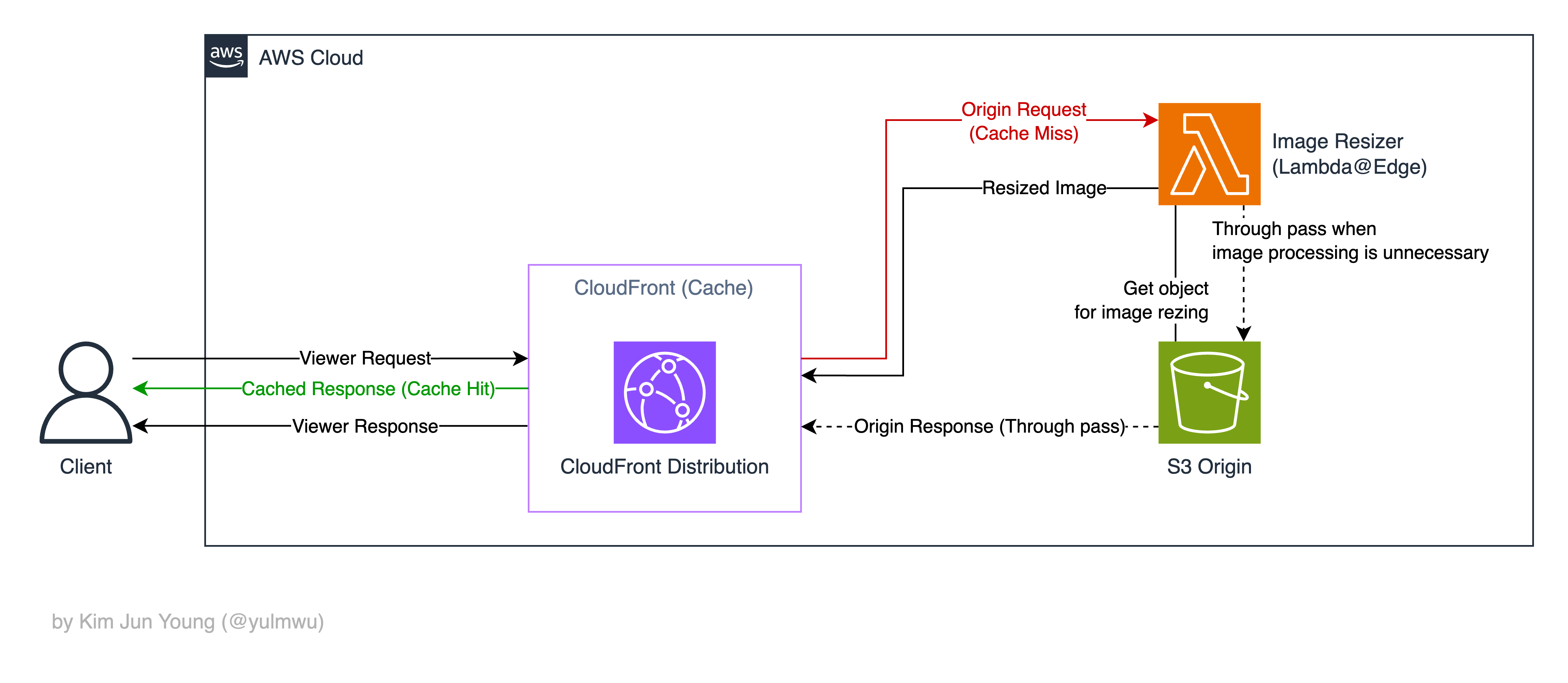
Origin Request를 Lambda@Edge로 보낸 다음, 이미지를 S3 버킷에서 가져온 뒤 리사이징 후 반환한다.
이때 Base64로 인코딩되어 반환되는데, Base64로 인코딩 되면 데이터의 크기가 약 1.33배(4/3배) 증가한다. 하지만 Lambda@Edge를 사용한 Origin Request 응답엔 Base64로 인코딩 시 1.33MB(인코딩 전 1MB)으로 바디 크기 제한이 존재한다. (참고 1: AWS 공식 문서, 참고 2: AWS 공식 문서)
만약 이 제한을 피하려면 구조 자체를 바꿔 S3에 리사이징된 결과를 저장하고, S3로 리다이렉션을 하는 등의 구조가 필요하다. 하지만 이미지 크기와 사이즈를 줄이는 것이 목표였으므로 크게 신경 쓸 부분은 아닌 것 같다.
그리고 파라미터가 제공되지 않았거나 파일 확장자가 지원하는 포맷이 아니라면 람다를 경유하여 지나가도록 하였다. (Through pass)
다음으로 Lambda@Edge 함수 코드를 살펴보자.
2. Let's write the Code
코드를 살펴보기 앞서, 사용한 라이브러리는 sharp, @aws-sdk/client-s3이며, 타입스크립트로 작성되었기 때문에 타입 라이브러리도 설치해주자.
"devDependencies": {
"@types/aws-lambda": "^8.10.152",
"@types/node": "^24.3.0",
"@smithy/types": "^4.3.2",
"esbuild": "^0.20.0",
"aws-lambda": "^1.0.7",
"typescript": "^5.4.0"
},
"dependencies": {
"@aws-sdk/client-s3": "^3.864.0",
"sharp": "^0.34.3"
}여기서 sharp 라이브러리는 OS 네이티브 바이너리(libvips)를 사용한다. 때문에 AWS Lambda@Edge 환경(Amazon Linux 2)에서 빌드해야 확실하게 작동할 수 있다.
로컬에서 도커 등으로 빌드해서 사용할 수 있겠지만, 확실하게 플랫폼을 맞춰주기 위해 추후 CloudShell에서 빌드 후 람다 함수에 배포할 것이다.
코드는 아래와 같다.
import type { CloudFrontRequestEvent, CloudFrontRequest, CloudFrontResultResponse, CloudFrontHeaders } from 'aws-lambda'
import { S3Client, GetObjectCommand, type GetObjectCommandOutput } from '@aws-sdk/client-s3'
import sharp from 'sharp'
import { Readable } from 'stream'
import { ReadableStream as WebReadableStream } from 'stream/web'
import { StreamingBlobPayloadOutputTypes } from '@smithy/types'
type ImageExtension = 'png' | 'jpg' | 'jpeg' | 'webp' | 'gif'
interface ParsedParams {
width?: number
height?: number
quality?: number
extension?: ImageExtension
}
const S3_BUCKET = 'cf-image-resize-test-bucket'
const S3_BUCKET_REGION = 'ap-northeast-2'
const S3_OBJECT_MAX_BYTES = 1000 * 1000 * 3 // 3MB
const OUTPUT_MAX_BYTES = 1000 * 1000 // 1MB
const ALLOWED_EXTENSIONS: ImageExtension[] = ['png', 'jpg', 'jpeg', 'webp', 'gif']
class ImageResizeEdge {
private readonly s3: S3Client
constructor() {
this.s3 = new S3Client({ region: S3_BUCKET_REGION })
}
async handle(event: CloudFrontRequestEvent): Promise<CloudFrontResultResponse> {
const request = event.Records[0].cf.request
const params = this.parseParams(request)
if (!this.shouldProcess(params)) {
return this.passThrough(request)
}
const key = this.keyFromUri(request.uri)
if (!key) {
return this.badRequest('Invalid path.')
}
let s3object: GetObjectCommandOutput
try {
s3object = await this.getObject(key)
} catch (e: any) {
if (e.name === 'NoSuchKey') return this.notFound('Original image not found')
return this.serverError('Error fetching image from S3', e)
}
if (typeof s3object.ContentLength === 'number' && s3object.ContentLength > S3_OBJECT_MAX_BYTES) {
return this.payloadTooLarge('Original image too large.')
}
try {
const buffer = await this.bufferFromBody(s3object.Body!)
const output = await this.transform(buffer, params)
if (output.byteLength > OUTPUT_MAX_BYTES) {
return this.payloadTooLarge('Image exceeds 1MB limit.')
}
return this.ok(output, this.contentTypeByExt(params.extension!))
} catch (e) {
return this.serverError('Image processing failed', e)
}
}
private parseParams(req: CloudFrontRequest): ParsedParams {
const query = new URLSearchParams(req.querystring ?? '')
return {
width: this.toInt(query.get('w') ?? undefined),
height: this.toInt(query.get('h') ?? undefined),
quality: this.toInt(query.get('q') ?? undefined, 1, 100),
extension: this.extensionFromUri(req.uri),
}
}
private shouldProcess(params: ParsedParams): boolean {
if (!params.extension || !ALLOWED_EXTENSIONS.includes(params.extension)) return false
return Boolean(params.width || params.height || params.quality)
}
private extensionFromUri(uri: string): ImageExtension | undefined {
const match = uri.match(/\.([a-zA-Z0-9]+)$/)
const raw = (match?.[1] || '').toLowerCase()
return ALLOWED_EXTENSIONS.includes(raw as ImageExtension) ? (raw as ImageExtension) : undefined
}
private keyFromUri(uri: string): string | null {
let key = decodeURIComponent(uri)
if (key.startsWith('/')) key = key.slice(1)
if (key.includes('..')) return null
key = key.replace(/\/{2,}/g, '/')
return key.length ? key : null
}
private async getObject(key: string): Promise<GetObjectCommandOutput> {
return this.s3.send(new GetObjectCommand({ Bucket: S3_BUCKET, Key: key }))
}
private async transform(input: Buffer, p: ParsedParams): Promise<Buffer> {
const img = sharp(input, { animated: p.extension === 'gif', limitInputPixels: 100_000_000 })
let stream = img
if (p.width || p.height) {
stream = stream.resize({ width: p.width, height: p.height, fit: 'inside', withoutEnlargement: true })
}
switch (p.extension) {
case 'jpg':
case 'jpeg':
stream = p.quality ? stream.jpeg({ quality: p.quality }) : stream.jpeg()
break
case 'png': {
stream = p.quality
? stream.png({ compressionLevel: this.pngCompressionLevel(p.quality) })
: stream.png()
break
}
case 'webp':
stream = p.quality ? stream.webp({ quality: p.quality }) : stream.webp()
break
case 'gif':
stream = stream.gif()
break
}
return stream.toBuffer()
}
private pngCompressionLevel(quality?: number): number {
if (typeof quality !== 'number') return 6
return Math.max(0, Math.min(9, Math.round((100 - quality) / 11)))
}
private toInt(value?: string, min = 1, max = 8192): number | undefined {
if (!value) return undefined
const parsed = Number.parseInt(value, 10)
if (Number.isNaN(parsed)) return undefined
return Math.min(Math.max(parsed, min), max)
}
private contentTypeByExt(ext: ImageExtension): string {
switch (ext) {
case 'jpg':
case 'jpeg':
return 'image/jpeg'
case 'png':
return 'image/png'
case 'webp':
return 'image/webp'
case 'gif':
return 'image/gif'
}
}
private async bufferFromBody(body: StreamingBlobPayloadOutputTypes): Promise<Buffer> {
if (this.isBlobLike(body)) {
const ab = await (body as Blob).arrayBuffer()
return Buffer.from(ab)
}
if (this.isWebReadableStream(body)) {
const nodeReadable = Readable.fromWeb(body as WebReadableStream)
return this.streamToBuffer(nodeReadable)
}
return this.streamToBuffer(body as Readable)
}
private isBlobLike(x: unknown): x is Blob {
return typeof x === 'object' && x !== null && 'arrayBuffer' in (x as Record<string, unknown>)
}
private isWebReadableStream(x: unknown): x is WebReadableStream {
return typeof x === 'object' && x !== null && 'getReader' in (x as Record<string, unknown>)
}
private async streamToBuffer(stream: Readable): Promise<Buffer> {
return new Promise<Buffer>((resolve, reject) => {
const chunks: Buffer[] = []
stream.on('data', (c) => chunks.push(Buffer.isBuffer(c) ? c : Buffer.from(c as ArrayBufferLike)))
stream.on('end', () => resolve(Buffer.concat(chunks)))
stream.on('error', reject)
})
}
private headers(contentType?: string): CloudFrontHeaders {
const maxAge = 30 * 24 * 60 * 60
const h: CloudFrontHeaders = {
'cache-control': [{ value: `public, max-age=${maxAge}, immutable` }],
vary: [{ value: 'Accept,Accept-Encoding' }],
}
if (contentType) h['content-type'] = [{ value: contentType }]
return h
}
private ok(body: Buffer, contentType: string): CloudFrontResultResponse {
return {
status: '200',
statusDescription: 'OK',
bodyEncoding: 'base64',
body: body.toString('base64'),
headers: this.headers(contentType),
}
}
private badRequest(msg: string): CloudFrontResultResponse {
return {
status: '400',
statusDescription: 'Bad Request',
body: msg,
headers: this.headers('text/plain; charset=utf-8'),
}
}
private notFound(msg: string): CloudFrontResultResponse {
return {
status: '404',
statusDescription: 'Not Found',
body: msg,
headers: this.headers('text/plain; charset=utf-8'),
}
}
private payloadTooLarge(msg: string): CloudFrontResultResponse {
return {
status: '413',
statusDescription: 'Payload Too Large',
body: msg,
headers: this.headers('text/plain; charset=utf-8'),
}
}
private serverError(msg: string, error: any): CloudFrontResultResponse {
console.error(msg, error)
return {
status: '500',
statusDescription: 'Server Error',
body: msg,
headers: this.headers('text/plain; charset=utf-8'),
}
}
private passThrough(req: CloudFrontRequest): CloudFrontResultResponse {
return req as unknown as CloudFrontResultResponse
}
}
export const handler = async (event: CloudFrontRequestEvent): Promise<CloudFrontResultResponse> => {
const service = new ImageResizeEdge()
return service.handle(event)
}참고로 Lambda@Edge는 환경변수를 지원하지 않기 때문에 코드 내에 필요한 값을 넣어줘야 한다. 위 코드에선 버킷 이름(S3_BUCKET)과 버킷 리전(S3_BUCKET_REGION)을 알맞게 넣어주자.
코드에서 w, h 파라미터를 통해 가로/세로 사이즈를 조절할 수 있고, q 파라미터를 통해 이미지의 퀄리티를 조절할 수 있다. GIF에선 적용되지 않고, PNG에선 퀄리티가 아닌 압축 강도만 조절할 수 있도록 하였다.
원한다면 팔레트 옵션 등으로 처리할 수 있으나, 이 작업에서 CPU 사용률이 꽤나 높아지기 때문에 처리 시간이 길어지거나 람다 함수에서 502나 503 에러가 뜰 수 있다.
코드는 아래의 깃허브 레포지토리에 올려두었다. (예시의 이미지들 또한 포함되어 있다.)
https://github.com/yulmwu/aws-image-resize-lambda
3. Let's build the Infra
이제 AWS 아키텍처를 만들어보자.
여기서 S3 버킷과 CloudFront 배포를 만들고, OAC(Origin Access Control)를 통해 연동해보겠다. 이후 람다 함수를 배포하고 CloudFront 오리진 동작에서 작동하도록 설정해보자.
(1) IAM
먼저 Lambda@Edge가 실행 시 필요한 정책들을 포함한 IAM 역할을 만들어주자. 람다 함수를 만들면 자동으로 생성되는 IAM을 사용해도 되지만 편의상 직접 만들어보자.
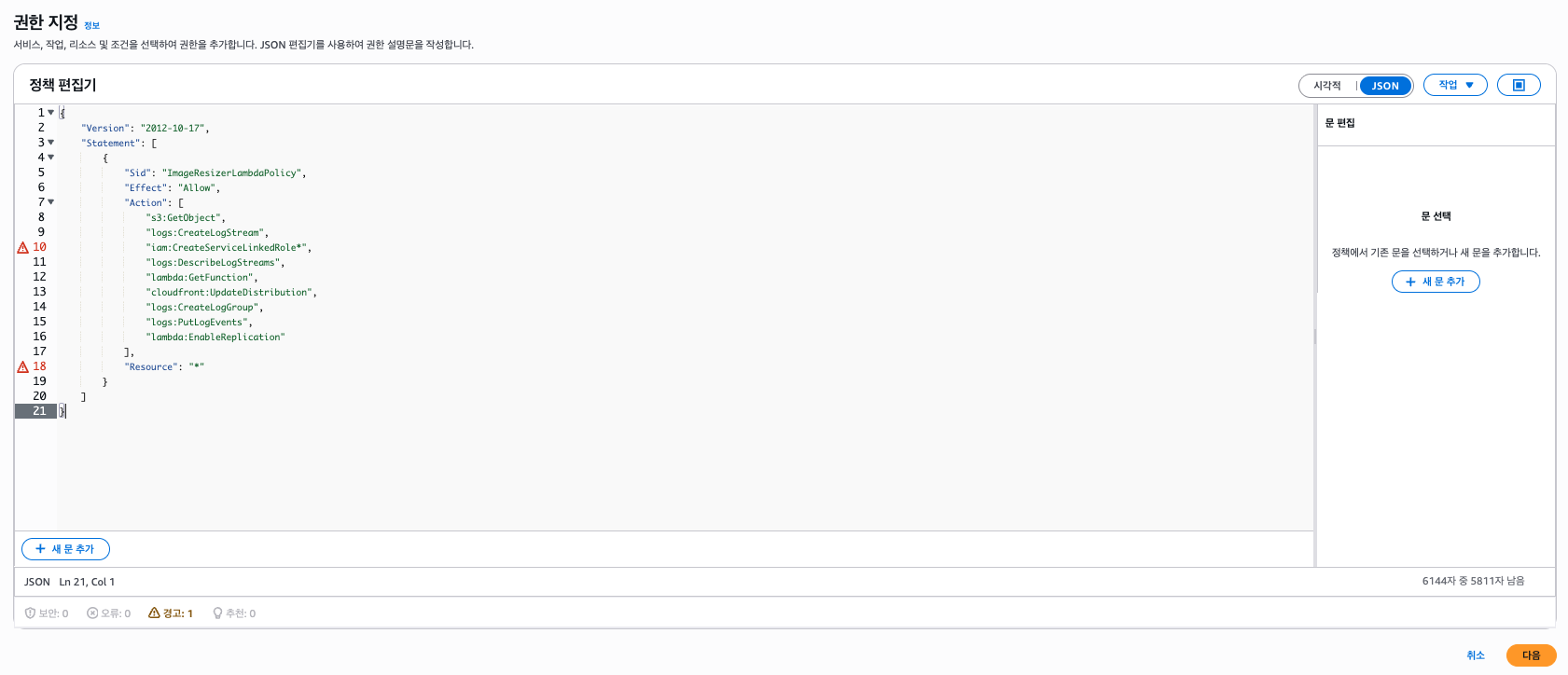
먼저 역할에 적용할 ImageResizerLambdaPolicy 정책을 만들어보자.

정책 생성을 클릭하고 아래와 같은 JSON으로 정책을 만들자.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ImageResizerLambdaPolicy",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"logs:CreateLogStream",
"iam:CreateServiceLinkedRole*",
"logs:DescribeLogStreams",
"lambda:GetFunction",
"cloudfront:UpdateDistribution",
"logs:CreateLogGroup",
"logs:PutLogEvents",
"lambda:EnableReplication"
],
"Resource": "*"
}
]
}

정책을 생성해주었다면 람다 실행에 적용할 역할을 만들어보자.

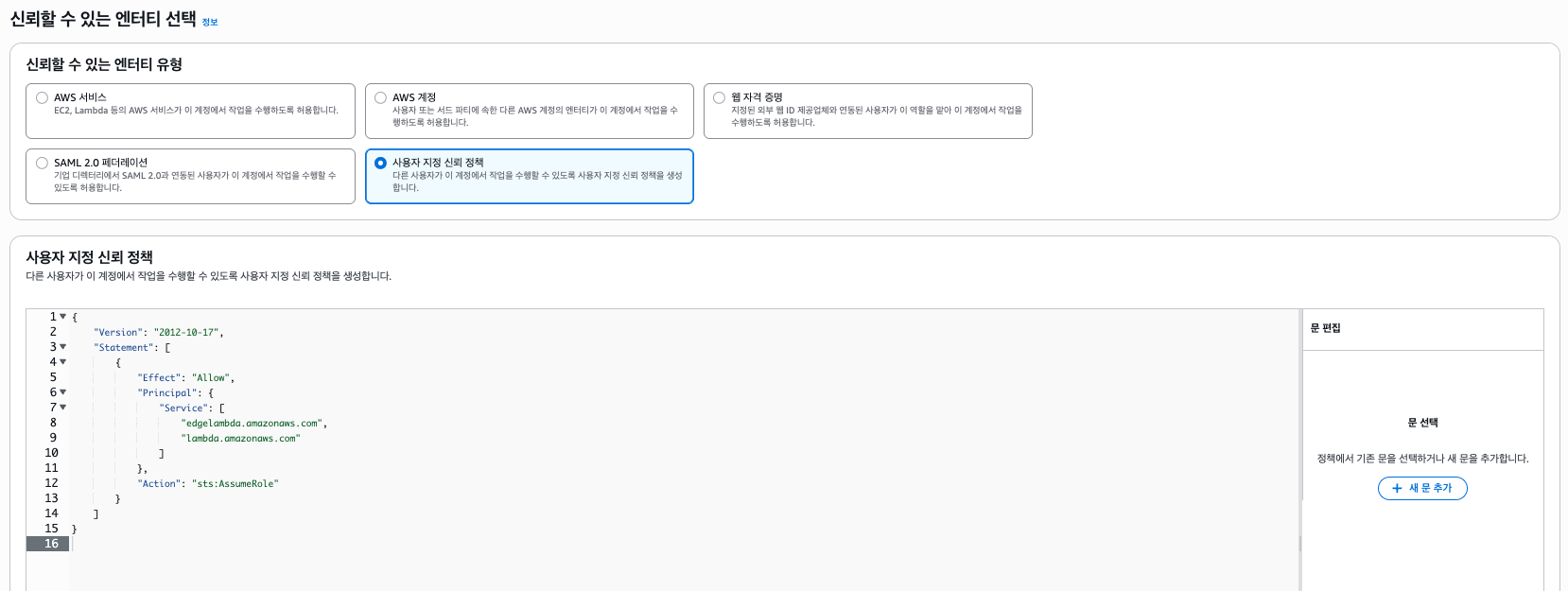
역할 생성을 클릭하자. 일반 람다 함수였다면 사용 사례에서 람다를 선택하면 되지만, Lambda@Edge로 동작하기 때문에 신뢰 정책을 커스텀해야 한다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"edgelambda.amazonaws.com",
"lambda.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}
그리고 정책은 만들어둔 ImageResizerLambdaPolicy를 선택한다.
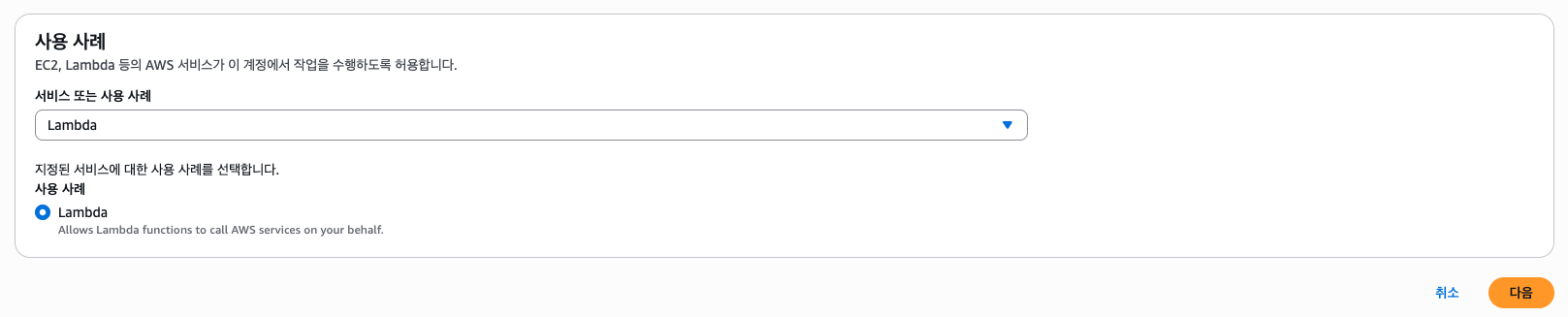


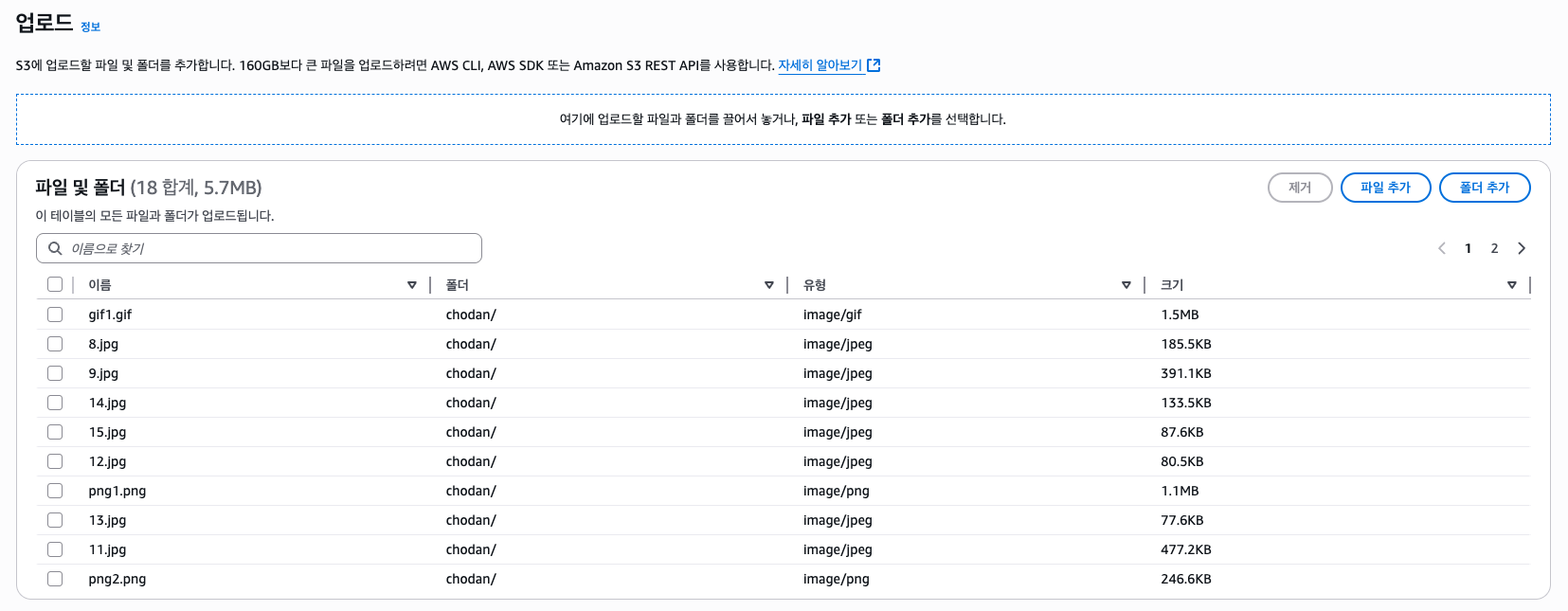
IAM 설정은 끝났다. 다음으로 테스트 이미지들이 업로드될 S3 버킷을 하나 만들자.
(2) S3 Bucket
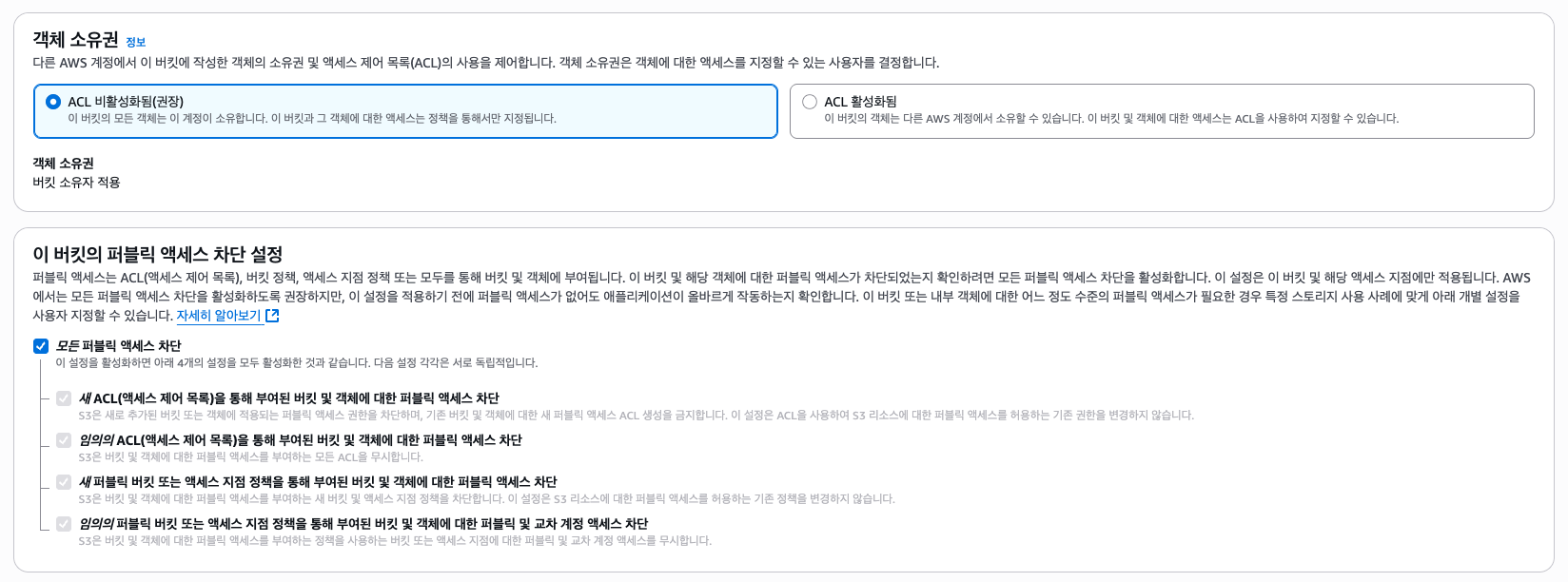
그리고 퍼블릭 엑세스는 차단한다. 이후 CloudFront에서 OAC를 만들고 버킷 정책을 변경할 것이다.
그리고 테스트용 이미지를 S3 버킷에 업로드해보자. 테스트용 이미지는 깃허브 레포지토리에 포함되어 있다.

(3) CloudFront
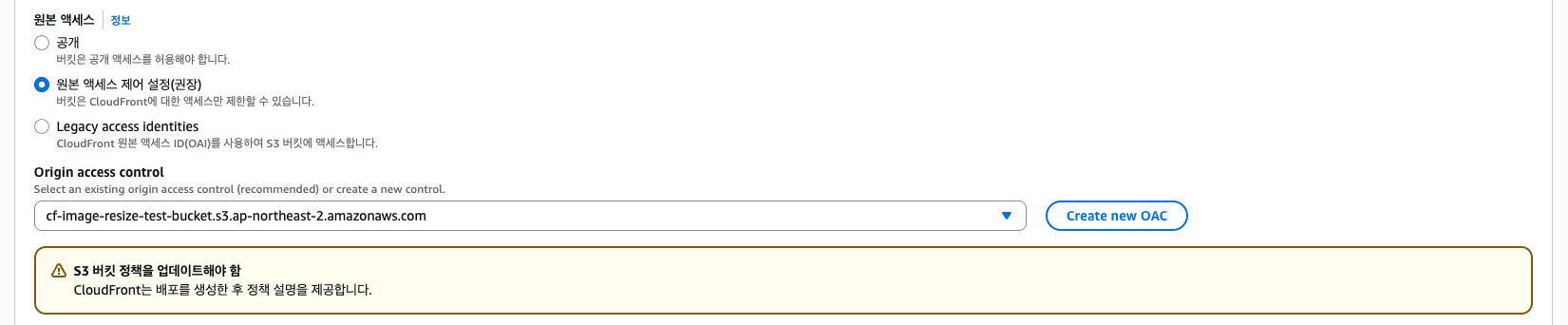
그리고 CloudFront 배포를 설정하자.

오리진은 만들어둔 S3 버킷을 선택한다. 그리고 원본 엑세스는 "원본 엑세스 제어(OAC) 설정"을 선택하고 Create new OAC를 통해 OAC를 하나 만들자.
나머지 설정은 일단 생략하고 배포를 만들자.

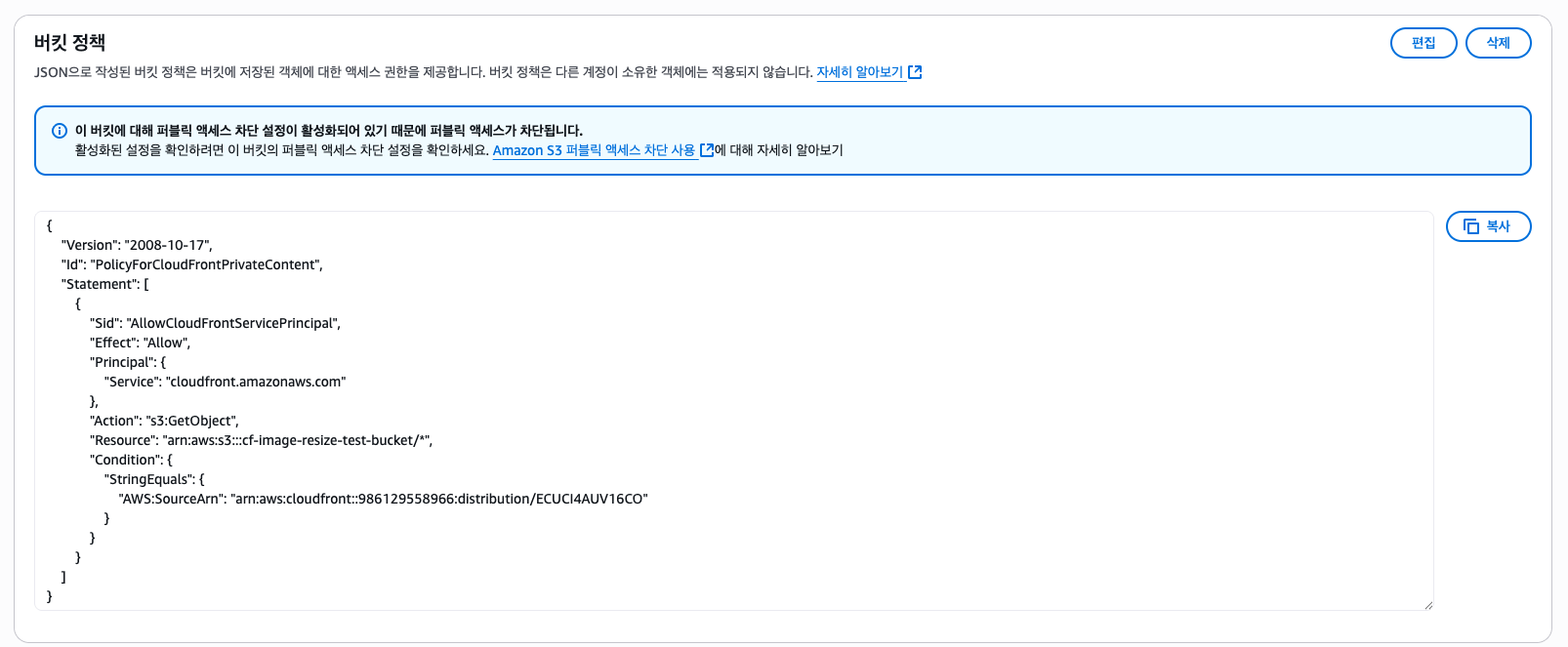
그러면 S3 버킷 정책을 업데이트해야 한다고 알림이 뜬다. "정책 복사" 버튼을 누르거나 아래의 버킷 정책을 복사하여 S3 버킷 정책을 업데이트하자.
{
"Version": "2008-10-17",
"Id": "PolicyForCloudFrontPrivateContent",
"Statement": [
{
"Sid": "AllowCloudFrontServicePrincipal",
"Effect": "Allow",
"Principal": {
"Service": "cloudfront.amazonaws.com"
},
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::bucket-name/*",
"Condition": {
"StringEquals": {
"AWS:SourceArn": "arn:aws:cloudfront::123456789012:distribution/AABBCCDDEEFFG"
}
}
}
]
}
그럼 이제 CloudFront를 통해 S3 버킷에 접근할 수 있다. 테스트로 이미지를 가져와보자.
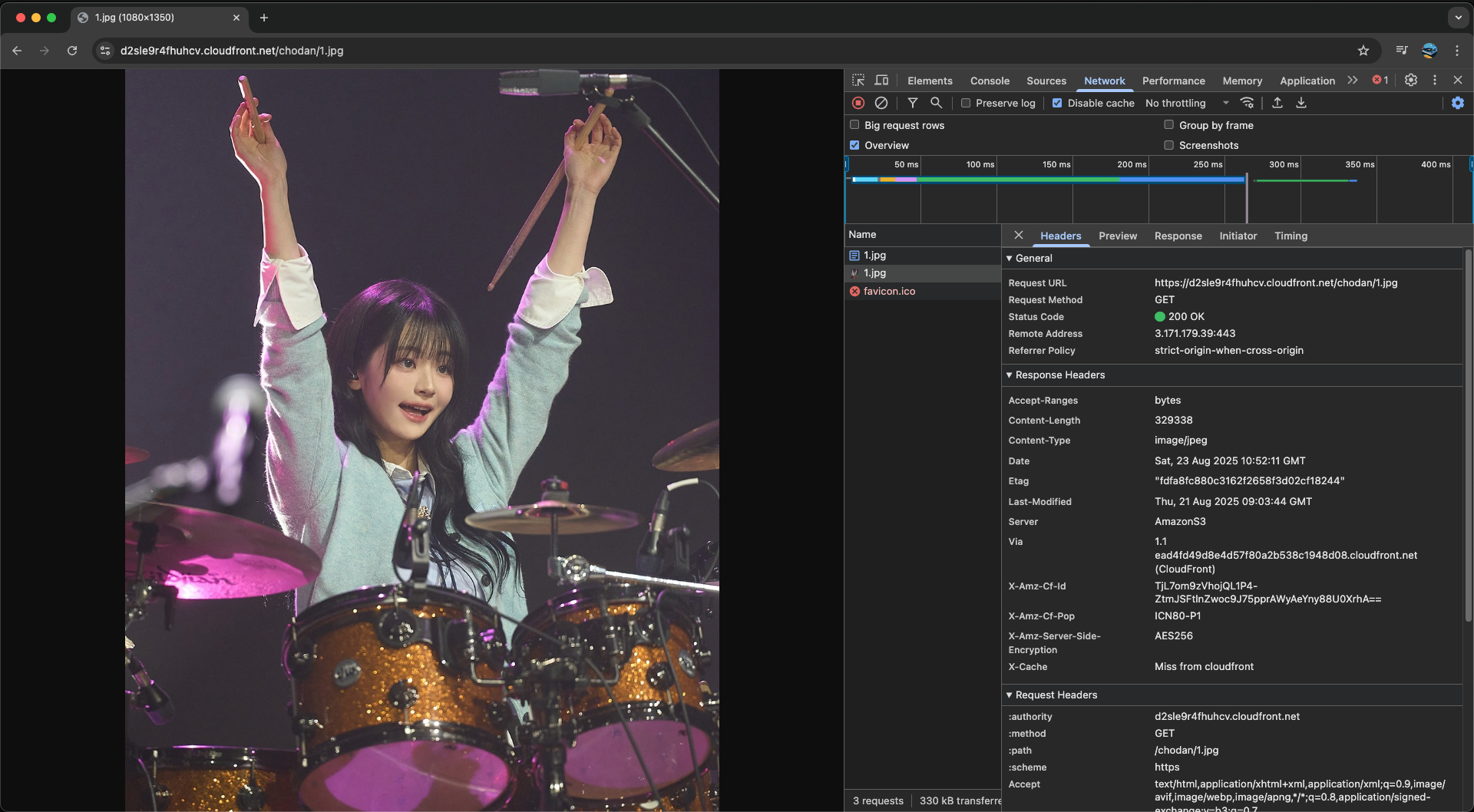

처음 접속했을 때 Miss가 뜨는 것도 볼 수 있다. 그 다음엔 Hit으로 뜰 것이다.

(4) Lambda@Edge
이름만 Lambda@Edge이지 생성 방법이나 배포 방법은 일반 람다 함수랑 똑같다. 다만 중요한 점이 있는데, Lambda@Edge는 기본적으로 us-east-1(버지니아 북부) 리전에서 생성된 람다 함수만 사용할 수 있다.
때문에 us-east-1으로 리전을 변경한 뒤 람다 함수를 생성해주자.

실행 역할은 아까 생성해두었던 IAM 역할을 선택한다.

함수가 생성되었다면 설정에서 메모리와 제한 시간을 좀 늘려주자.
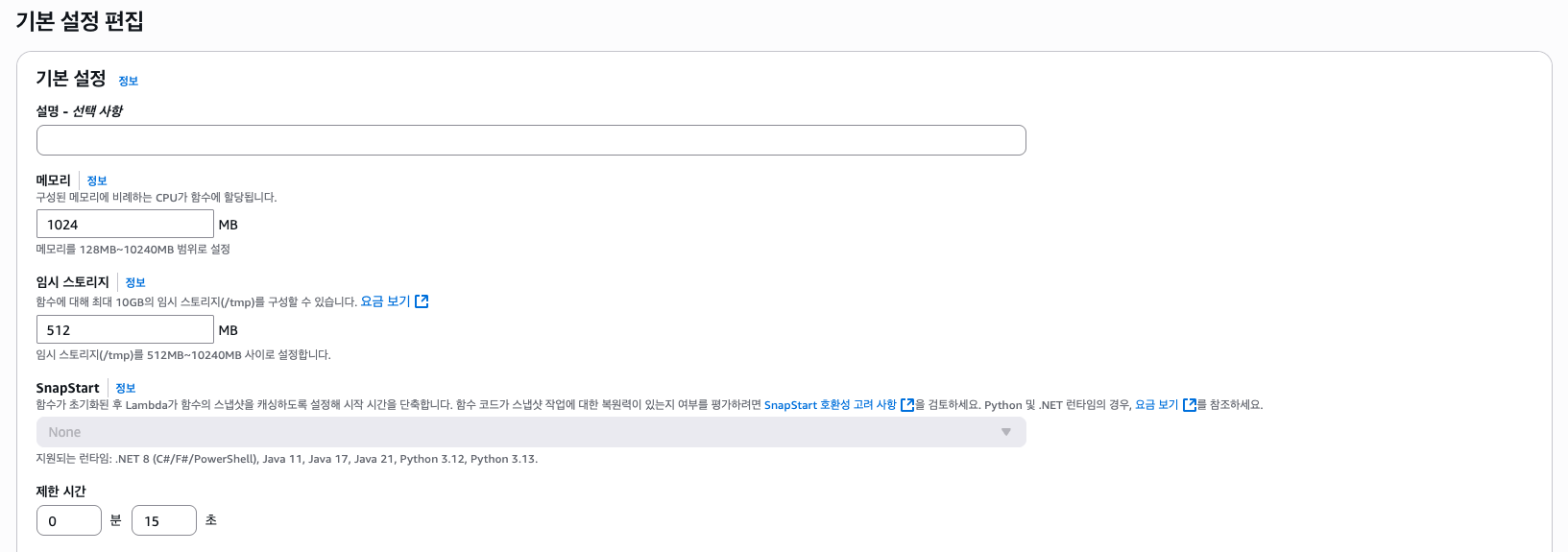
제한 시간 안에 이미지 처리가 끝나지 않을 경우 502 또는 503 에러가 뜨게 된다. 코드 상으로 버킷으로 부터 가져올 수 있는 이미지의 최대 크기는 3MB이므로 1GB 메모리에 제한 시간 15초 정도면 괜찮을 것이다. (이 경우엔 적절한 스윗 스팟을 찾아야 한다.)
그리고 이제 소스코드를 람다 함수에 배포해야 하는데, 아까 말했듯이 sharp 라이브러리가 네이티브 라이브러리를 포함하고 있어 Amazon Linux 2 환경에서 빌드해야 한다.
예전엔 Cloud9을 통해 온라인으로 코드를 수정하고 터미널을 열어 빌드할 수 있었으나, 서비스가 종료되어 그 대신 CloudShell을 이용하기로 하였다. 기본적인 AWS CLI, NodeJS 등은 설치되어 있으니 문제 없다.

헤더에 있는 터미널 아이콘을 클릭하면 CloudShell을 사용할 수 있다.
Open us-east-1 environment를 클릭하여 환경을 만든다.

CloudShell에 소스코드를 가져오자. 필자는 깃허브에 소스코드가 있으므로 git clone 명령어를 통해 가져와보겠다.
git clone https://github.com/yulmwu/aws-image-resize-lambda.git
그리고 npm i 또는 npm ci를 통해 의존성을 설치하고, node esbuild.config.js 명령어를 통해 타입스크립트를 빌드하자.
이제 람다 함수에 배포하기 위해 압축하고 배포해보겠다. 50MB를 넘길 경우 S3 버킷에 아키팩트를 업로드한 뒤 람다 함수에서 사용하도록 해야겠지만 다행히 50MB를 넘기지 않으므로(48.7MB) 그냥 압축해서 바로 배포해보겠다.
cd dist
zip -r ../dist.zip . ../node_modules
cd ..그리고 AWS CLI를 사용하여 배포한다.
aws lambda update-function-code \
--function-name ImageResizer \
--region us-east-1 \
--zip-file fileb://dist.zip
잘 배포된 것을 볼 수 있다. 이제 CloudShell은 필요가 없으므로 종료시키자. 켜두면 요금이 나간다.
그리고 CloudFront 오리진 동작에 Lambda@Edge를 사용하려면 버전 명시가 필요하므로 버전을 생성해주자.

이제 CloudFront와 연결해보자. 람다 함수 대시보드에서 직접 트리거를 추가할 수 도 있고, CloudFront에서 설정할 수 도 있다. 필자는 후자로 해보겠다.

여기서 "편집"을 클릭한다. 그리고 해줘야 할 작업은 2개이다. 먼저 캐시 키 설정을 해주자.
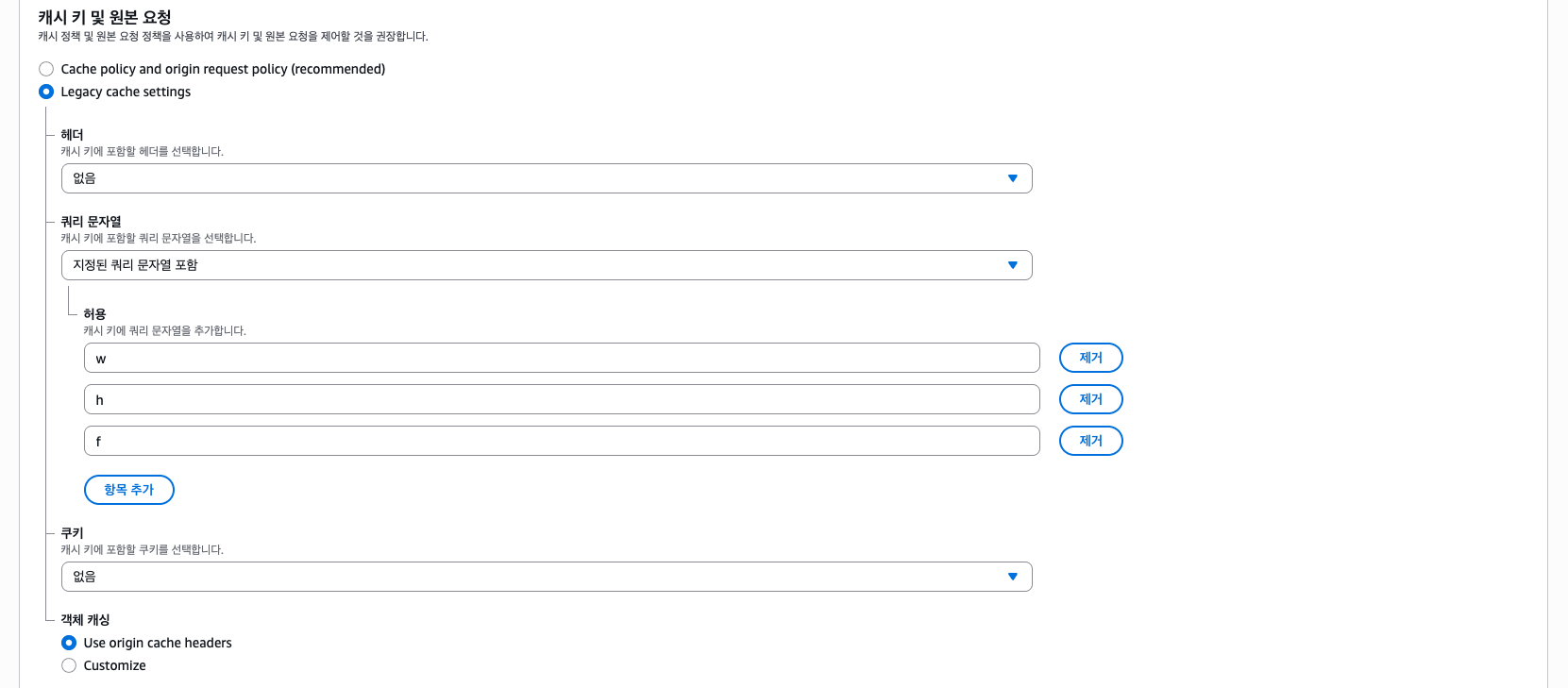
위 사진 처럼 파라미터(쿼리) w, h, f를 추가해주자. 그렇게 해야 해당 파라미터에 맞게 캐싱된다.
그리고 함수 연결에서 만들어둔 람다를 연결한다.

원본 요청으로 설정하는데, 바디에 대한 정보는 필요하지 않으므로 체크하지 않는다. 오히려 체크 시 데이터 크기가 커져 불리하다.
4. Testing
이제 CloudFront URL 뒤에 ?w=300 등의 쿼리를 붙여 잘 동작하는지 확인해보자. (Lambda@Edge가 적용되는데 시간이 걸릴 수 있다.)
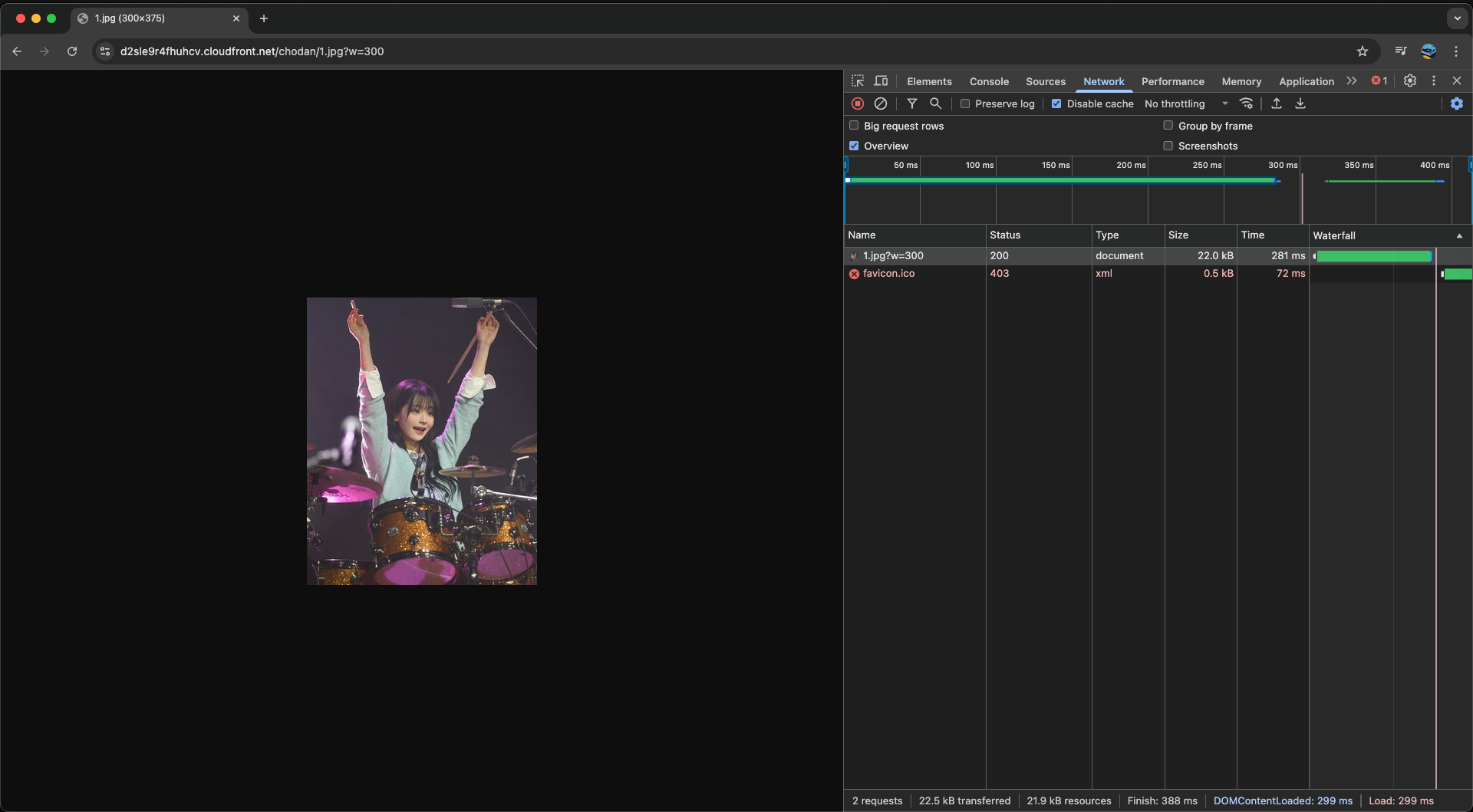

첫 로딩에 대해선 이미지 리사이징 프로세스 때문에 레이턴시가 있긴 한데, 새로고침해서 캐싱된 이미지를 가져와보면 매우 짧아진 모습을 볼 수 있다.

이제 맨 처음 문제가 됐었던 QWER 쵸단 갤러리에서 테스트해보자. 아까는 4G 쓰로틀링 환경에서 4.8초, 리소스 사이즈는 약 4.5MB에 LightHouse에선 LCP 수치에서 랜더링까지 약 4초가 걸렸었다.
이제 ?w=600 정도로 리사이징 후 불러와보면 어떨까? (각 이미지의 CSS width가 300px 정도니 넉넉하게 ?w=600로 설정하였다.)
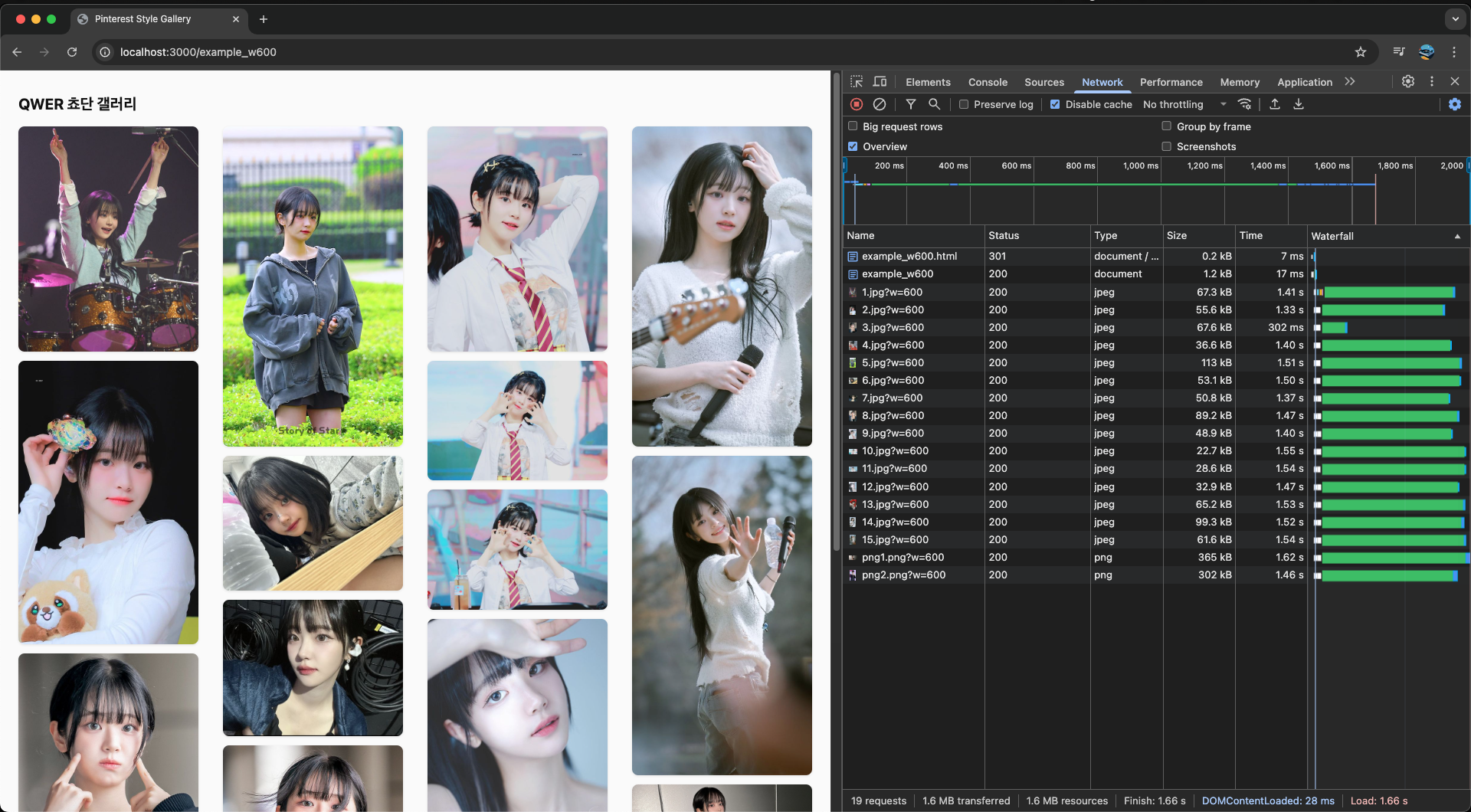
먼저 처음으로 접속했을 때(Cache Miss) 모습이다. 테스트로 인해 캐싱된 1.jpg를 제외하면 1초 대로 불러와진다. 이제 새로고침해서 캐싱이 되었을 때 성능을 보자. (크롬 메모리 캐시는 꺼야 제대로 테스트할 수 있다.)
아까와 동일한 조건(4G 쓰로틀링)으로 테스트해보자.

리사이징 적용 전엔 4.8초 만에 리소스를 불러왔으나, 적용 후 1.9초 정도로 2배 이상 줄어든 것을 볼 수 있다.
또한 불러온 데이터의 크기 또한 4.5MB에서 1.6MB로 2~3배 가량 줄어든 것을 볼 수 있다.
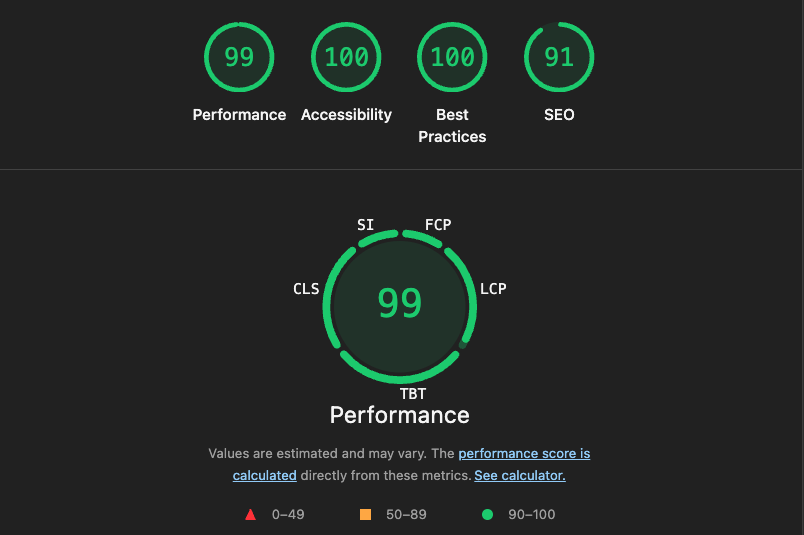
LightHouse 또한 처참했던 LCP가 매우 정상 범위로 들어섰으며, 자세히 확인해봐도 전혀 문제가 없다.
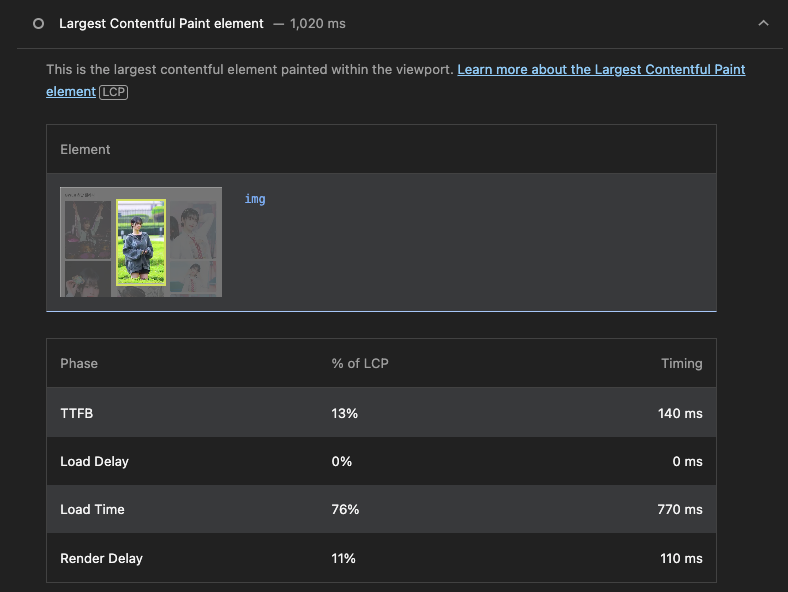
리사이징 적용 전엔 랜더링까지 LCP로 4초 정도가 걸렸다면, 적용 후 1초 정도로 매우 빨라졌다. 특히 이미지 크기가 작으니 랜더링 레이턴시 또한 매우 줄어든 것을 볼 수 있다.
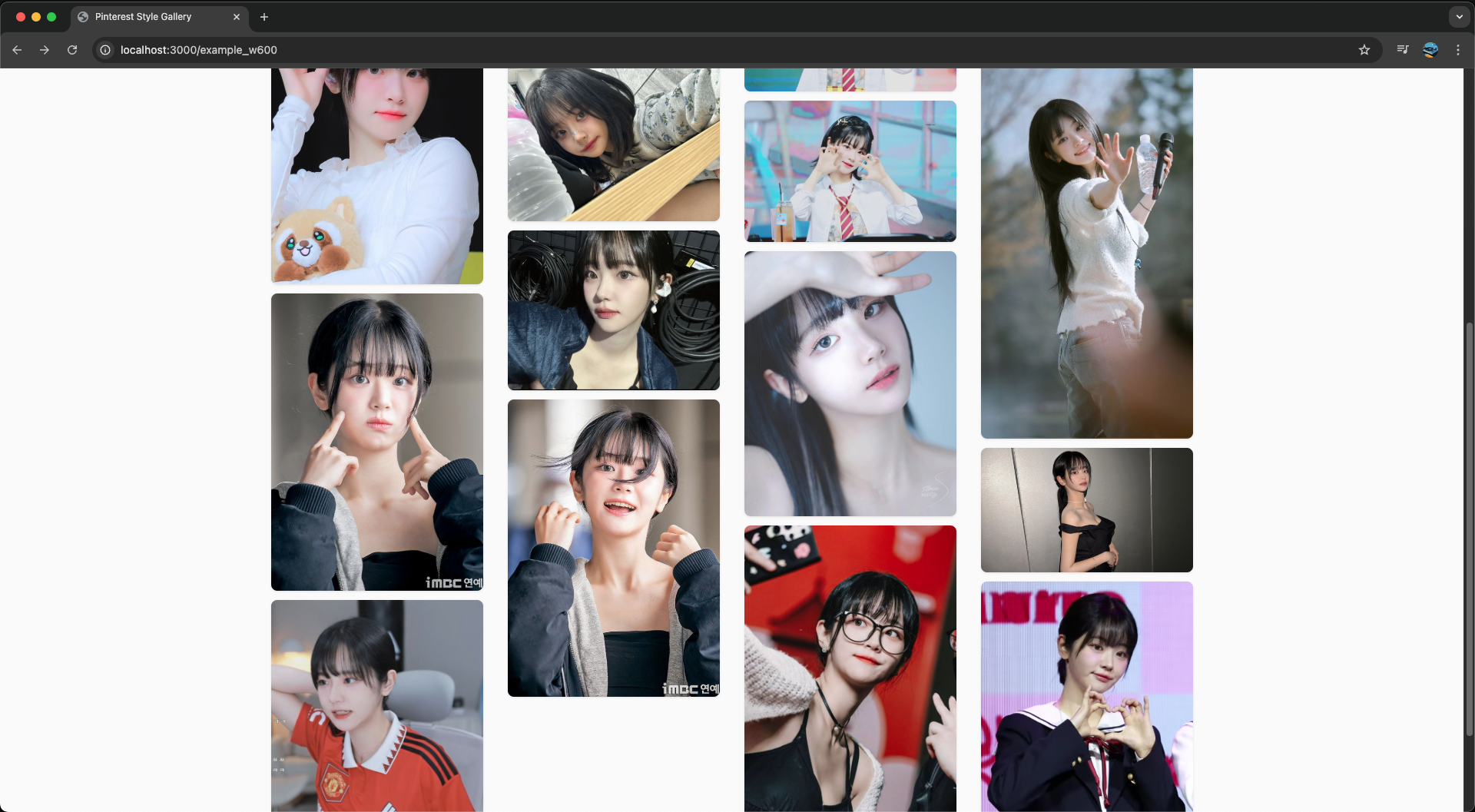
그렇게 사진이 리사이징되어 줄어들었어도 유저가 육안으로 보기엔 화질이 깨지거나 흐릿해지는 부분은 없다.

심지어 이미지 사이즈를 더 줄여도 문제가 없다고 하는데, 이건 CSS width/height와 DPR을 잘 따져가며 스윗 스팟을 찾아 적용하면 될 듯 하다.
5. Calculate Price
다음으로 요금 계산을 해보자. 이 아키텍처에선 크게 S3 GET 요청 요금, CloudFront 요금, 람다 요금으로 부과된다.
또한 CloudShell 실행 요금과 같은 부가적으로 발생할 수 있는 요금은 생각하지 않으며, CloudFront에서 Origin Shield와 같은 기능은 사용하지 않았다. 또한 S3 스토리지 용량 비용은 포함하지 않았다.
그리고 계산에 사용한 더미 값은 아래와 같다. (월 기준)
- 월
1,000,000회의 이미지 요청(CloudFront 요청) - 클라이언트에게 응답되는 이미지의 평균 크기:
200KB - CloudFront 캐시 히트 비율:
80%(200,000회의 S3 GET, 람다 실행) - 람다 메모리:
1GB(1024MB) - 람다 평균 실행 시간:
1초
AWS Pricing Calculator와 같은 도구를 사용하여 계산할 수 도 있지만, 간단한 계산이므로 요금 표를 참고하면서 계산해보겠다.
리전은 Lambda@Edge(버지니아 북부(us-east-1))를 제외한 나머지 서비스는 서울(ap-northeast-1)을 기준으로 하며, 프리티어의 범위는 포함하지 않았다.
S3 GET Request Price (Standard)
원래 AWS 서비스(S3 등)에서 CloudFront로 Transfer되는 데이터는 요금이 부과되지 않는다.
하지만 코드에선 어쩔 수 없이 AWS SDK를 사용하여 S3 Bucket에 직접 GET을 통해 이미지를 가져오는 로직이므로 GET 요청에 대한 요금이 부과된다.

참고: https://aws.amazon.com/ko/s3/pricing
S3 Standard에서 GET 요청은 1,000개의 요청 당 0.00035$가 부과된다. GET 요청이 일어나는 경우는 CloudFront에서 캐시 미스로 이미지 리사이징 람다가 실행될 때, 즉 200,000회이다.
계산해보면 이므로 총 0.07$가 부과된다.
CloudFront Price
CloudFront는 크게 2가지로 요금이 부과된다.
- 데이터 Transfer 비용: Edge Location에서 인터넷(클라이언트)으로 Transfer되는 데이터의 전송량
- CloudFront HTTP/HTTPS 요청 수: 여기선 HTTPS 요청 수로 계산함
먼저 인터넷으로 Transfer되는 비용을 보자.
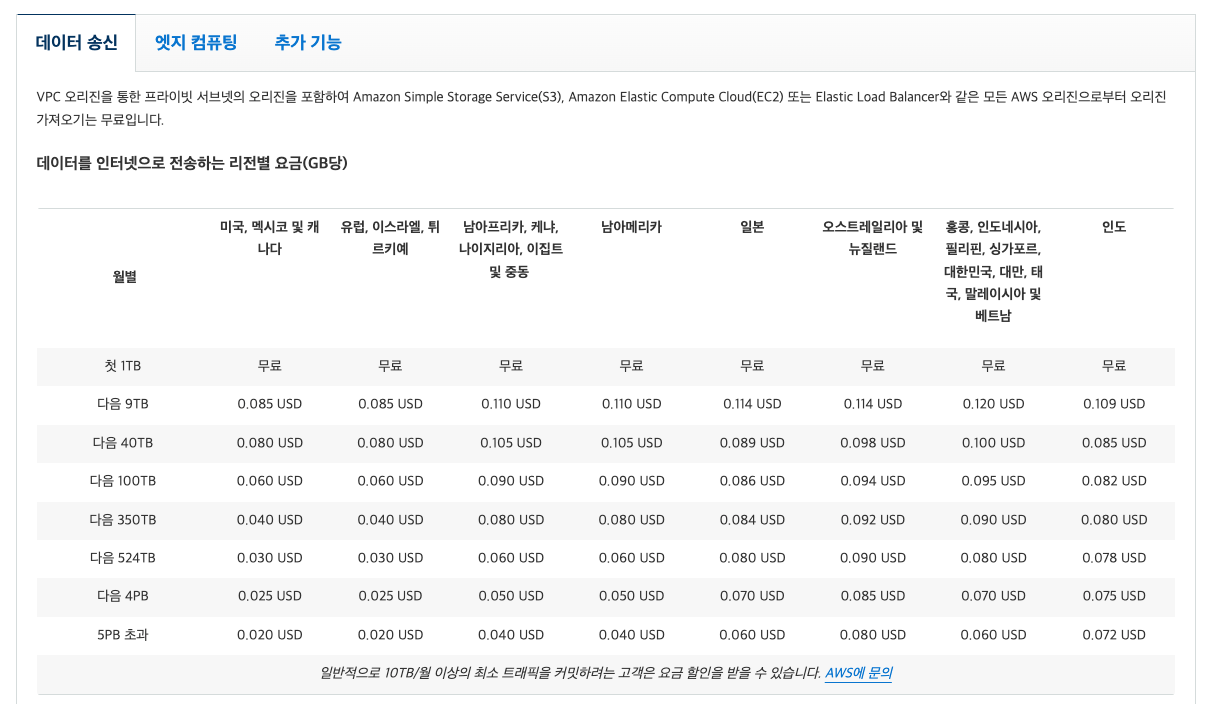
참고: https://aws.amazon.com/ko/cloudfront/pricing
첫 1TB는 까지는 무료인데, 예시로 계산하기 위해 의 대한민국 요금을 기준으로 하겠다. 요금은 1GB 당 0.120$가 부과된다.
평균 이미지 크기 200KB를 GB로 환산하면 약 0.0002GB가 된다. 계산해보면 로 계산되므로 월 전송량은 200GB이다.
(정확힌 이지만 계산의 편의상 200GB로 가정한다.)
그리고 GB 당 요금이 0.120$ 였으므로 , 즉 인터넷으로 데이터가 Transfer되는데 24$의 요금이 부과된다.
다음으로 CloudFront HTTPS 요청 수는 동일하게 1,000,000회가 된다.
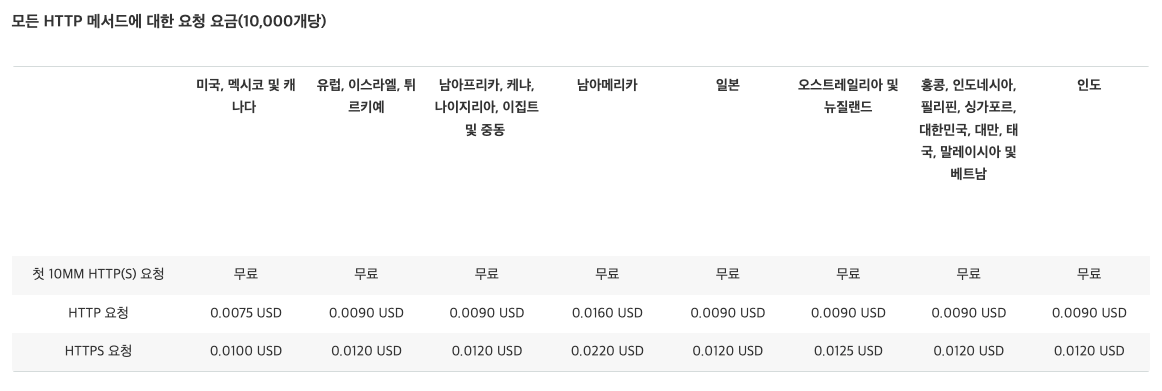
요금 표에선 10,000개의 요청을 기준으로 대한민국엔 0.0120$가 부과된다. 즉 , CloudFront HTTPS 요청 비용으론 1.2$가 부과된다.
Lambda@Edge Price
참고로 2025년 8월 1일부터 람다 실행 시간 요금에서 INIT 단계도 포함된다.
이로 인해 Cold Start가 많아질수록 요금이 더욱 부과될 수 있으니 참고하자.
참고: https://aws.amazon.com/ko/blogs/compute/aws-lambda-standardizes-billing-for-init-phase

Lambda@Edge 경우 기존의 람다와는 살짝 다르며, 요금이 살짝 더 비싸다. Lambda@Edge도 마찬가지로 2가지의 요소로 요금이 부과된다.
- 람다 실행 시간: 메모리 GB/초를 기준으로 계산함
- 람다 요청 수: 1백만의 요청을 기준으로 계산함
요금 표를 보자. (CloudFront 요금 표에 있다.)
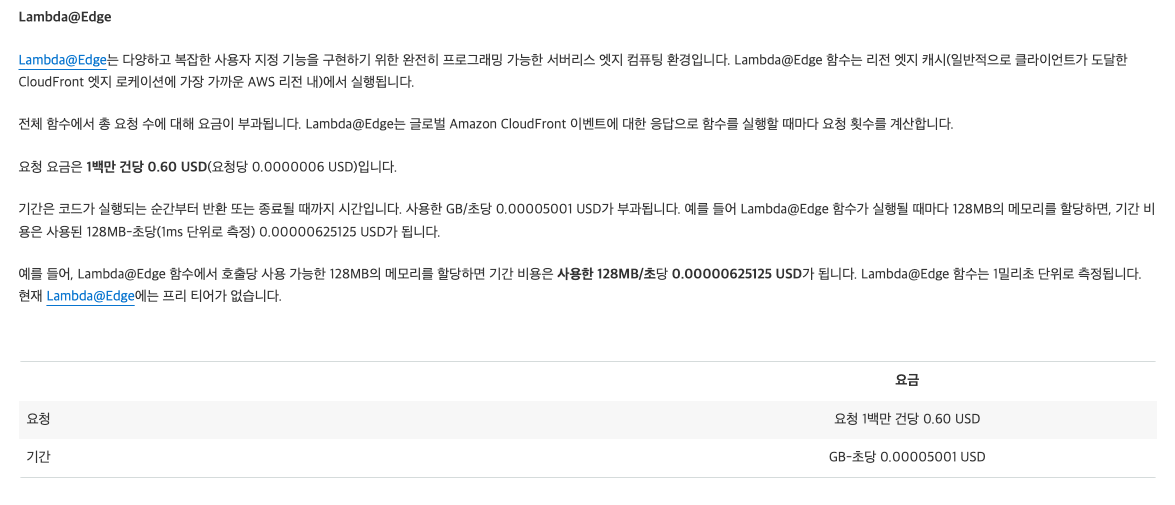
먼저 우리는 메모리는 1GB(1024MB), 평균 실행 시간을 1초로 설정하였고, GB-초당 0.00005001$가 부과되므로 아래와 같이 계산할 수 있다.
즉 람다 실행 시간 요금은 월 10$가 부과된다.
다음으로 람다 요청 수는 1백만 건당 계산되므로 , 즉 월 0.12$가 부과된다.
여태 발생했던 비용들을 요약하자면 아래와 같다.
- S3 GET Request: 0.07$
- CloudFront Internet Data Transfer: 24$
- CloudFront HTTPS Request: 1.2$
- Lambda@Edge Execution: 10$
- Lambda@Edge Request: 0.12$
그래서 모두 합산한다면 월 35.39$의 요금이 부과되게 된다.
(+) without Image Resizing
만약 이미지 리사이징 없이 원본 이미지를 반환한다고 하면 어떨까? 일단 리사이징 전 원본 이미지의 평균 크기는 2배인 400KB라고 가정하자.
그대로 CloudFront 요금을 계산해보면 아래와 같다.
즉 이미지 리사이징 적용 후 CloudFront 비용의 2배가 되는 것이다. 클라이언트 입장에서도 LCP가 높아지고, 요금도 더욱 발생하게 되니 적용하는 것이 여러므로 유리한 것이다.
6. Troubleshooting
마지막으로 구축하면서 발생했던 문제들에 대해 다뤄볼까 한다.
503 Lambda Limit Exceeded from Cloudfront
먼저 CloudFront에서 무효화를 진행 후 이미지들을 불러왔을 때 일부가 불러와지지 않는 문제가 있었다.

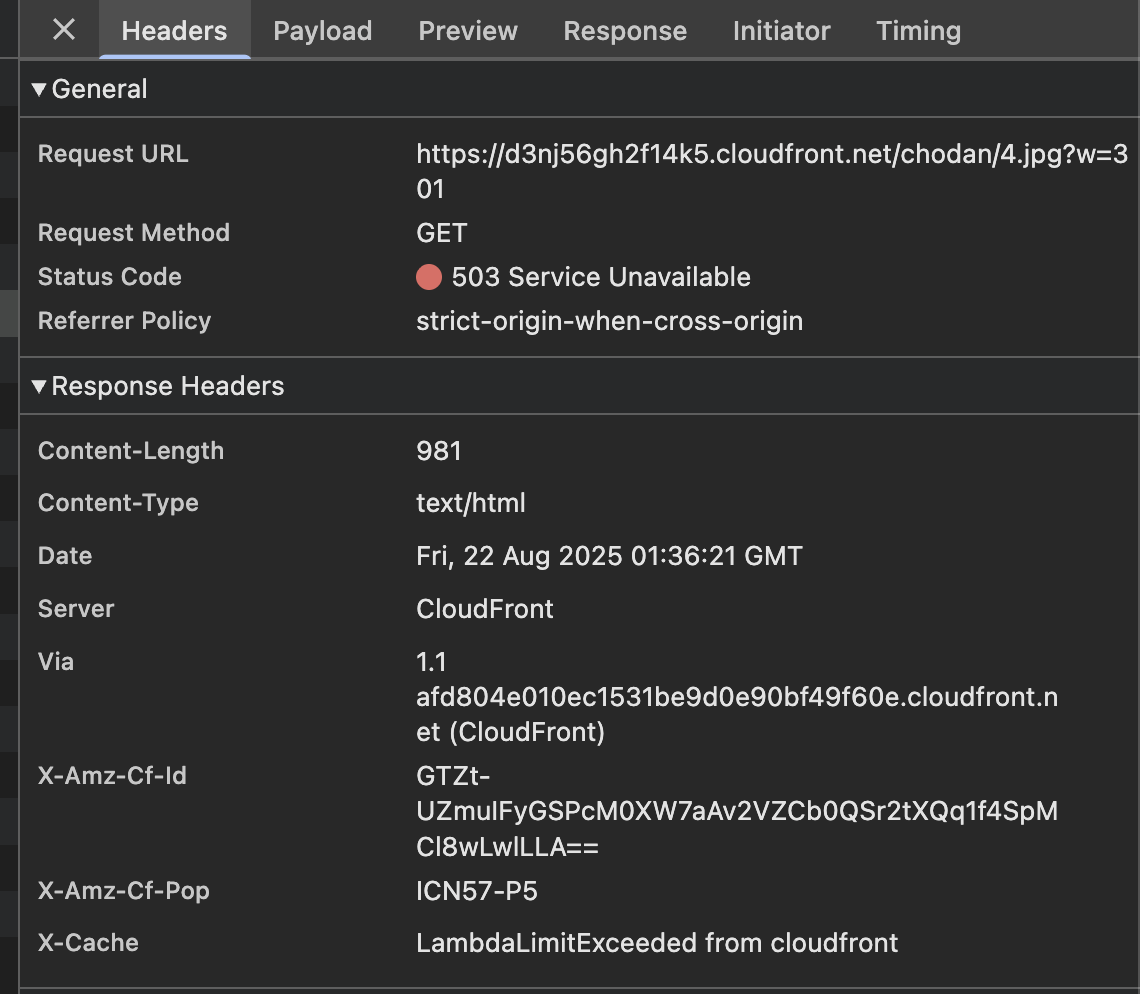
사진과 같이 Lambda Limit Exceeded from Cloudfront라는 메세지와 함께 503 Service Unavailable 에러가 발생하였다.
처음엔 람다 함수의 성능이 부족한게 아닐까 생각이 되었지만 그 문제는 아니였다. (메모리 1GB, 애초에 테스트마다 랜덤하게 되고 안되고가 달랐음)
그렇게 30분 정도 삽질하다가 항상 10개의 이미지만 처리된다는 것을 눈치챘는데, 바로 AWS Service Quotas에 들어가 Lambda Concurrent Executions 항목을 살펴보았다.

(7 count는 무시하자.)
기억 상으론 분명 1000개의 동시 실행 제한이 있었던 걸로 기억하는데, 현재 계정엔 10개로 제한되어 있었다. 해외 포럼을 찾아보는데 아마 해킹으로 피해를 줄이고자 기본적으로 10개로 제한해둔 것 같다.
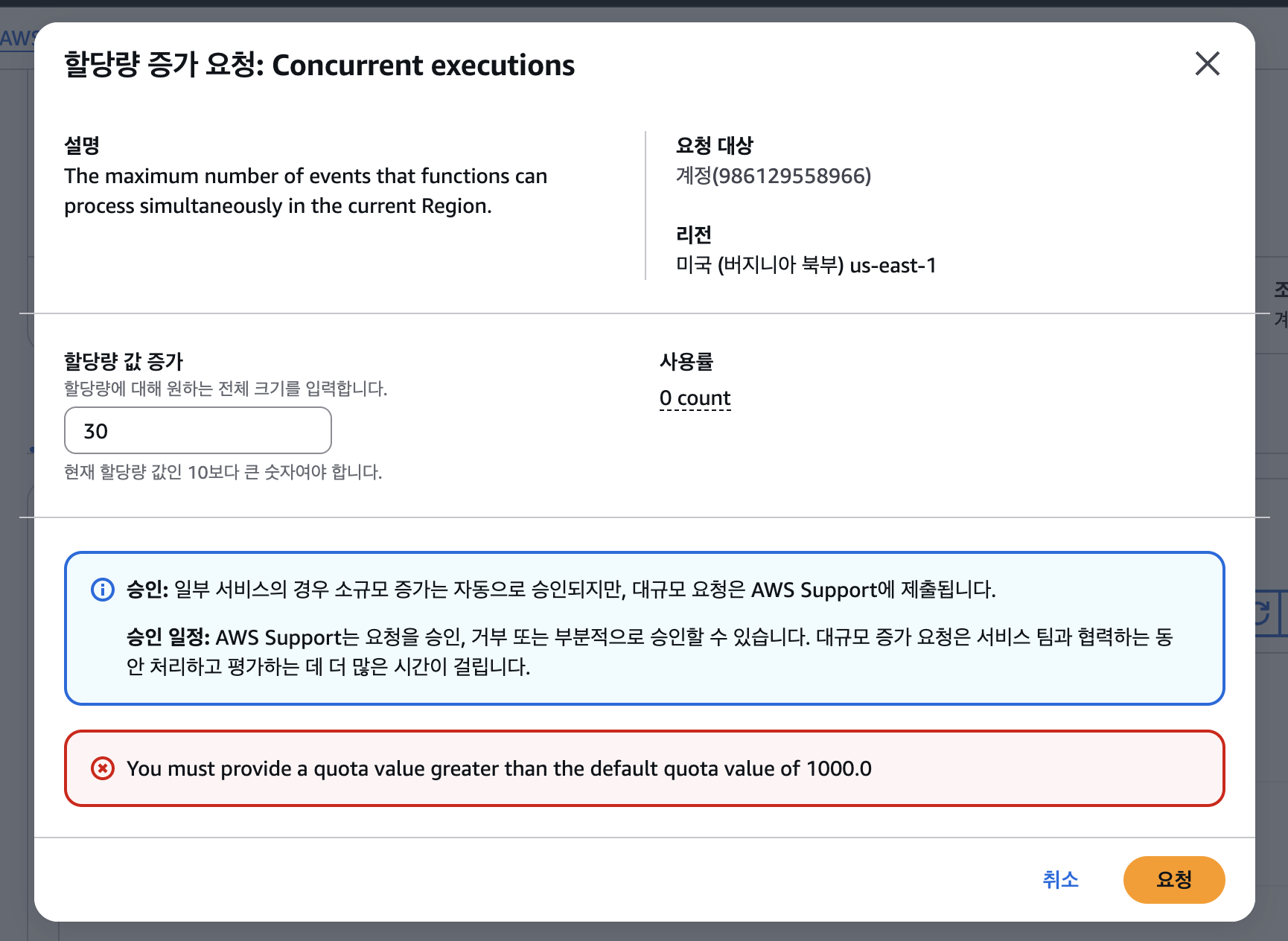
Lambda Concurrent Execution Quota
그래서 테스트로 30개 정도로 늘려보려고 했는데, 기본이 1000개라며 1000개 이상으로 설정하라고 에러를 띄웠다.
일단 애초에 이게 Lambda@Edge에도 적용이 되는지 확실하게 알기 위해 re:Post에 질문을 남겼다.
https://repost.aws/ko/questions/QUV9m5TMQCQCG5bimoYCLM7A/aws-lambda-edge-execution-limits-quota
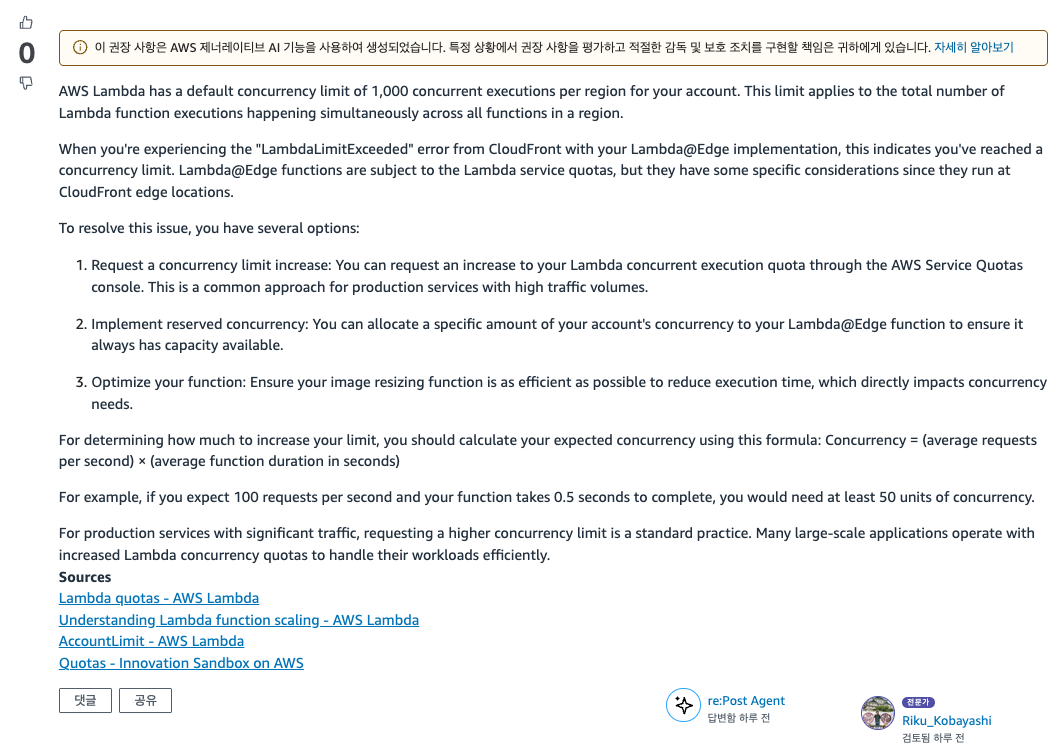
요약: Lambda@Edge도 람다 할당량(동시성 제한)을 따른다.
지금 생각해보면 당연한 이야기지만 검색해도 확실하진 않아 질문했었다. 추가적으로 꼭 동시성 제한을 1000개 이상 설정해야 되는지도 문의했었다.
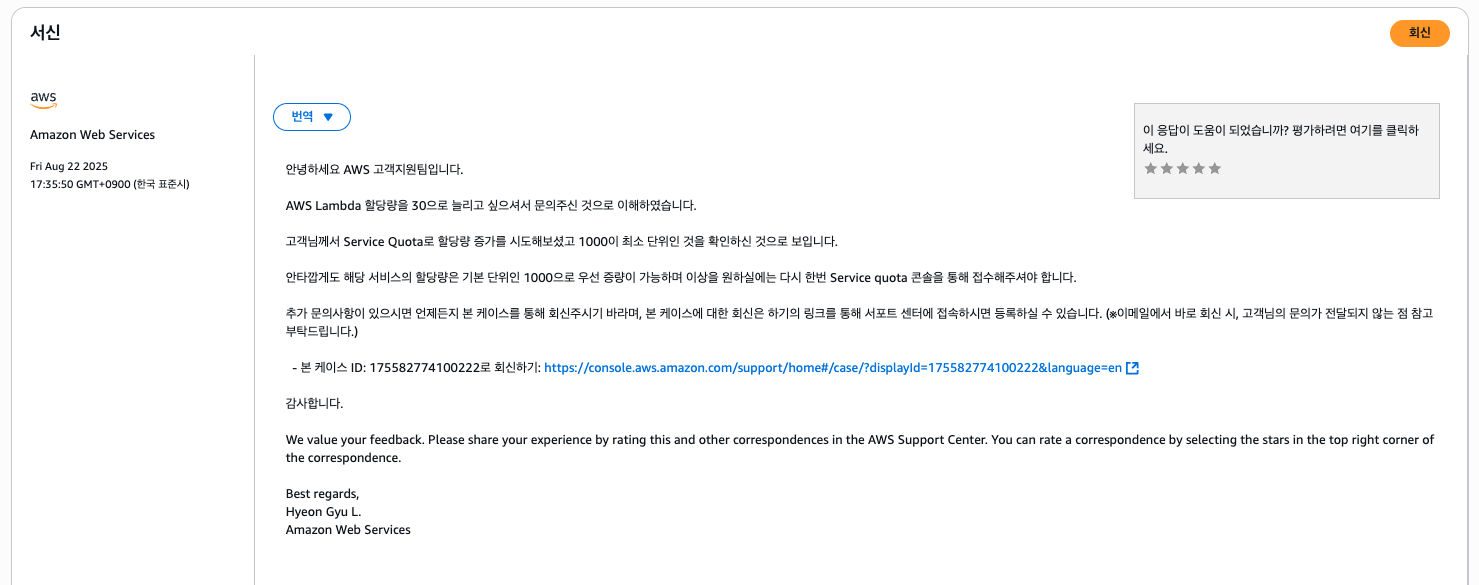
요약: ㅇㅇ
그래서 람다 동시성 제한을 1000개로 늘려주었다.
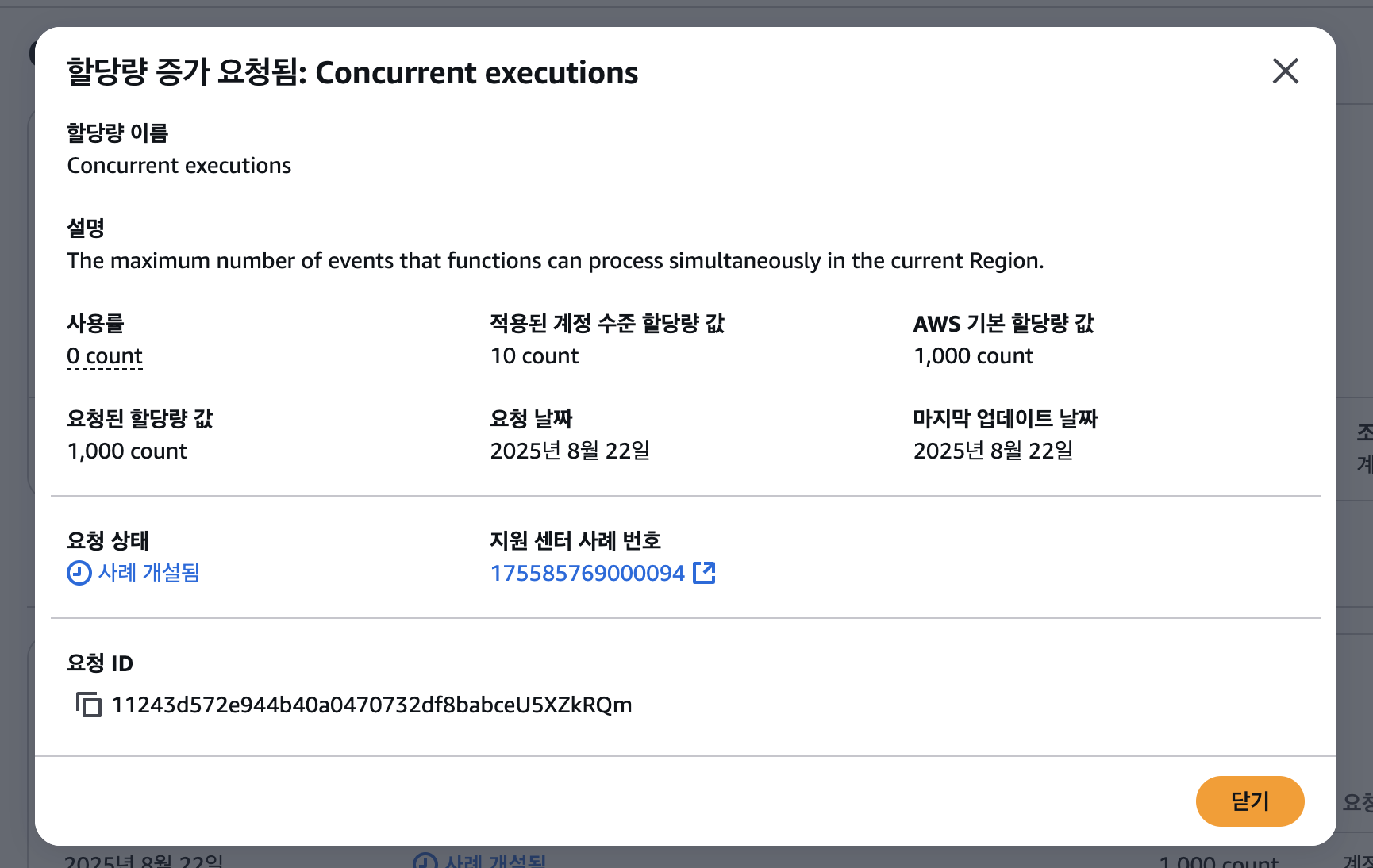
요청 후 12시간 정도 지나니 동시성 제한 할당량이 1000개로 늘어났다.

이로써 503 Lambda Limit Exceeded from Cloudfront 에러를 해결할 수 있었다. 혹시 같은 문제가 있다면 참고하자.
끝.
