0. Overview
깔끔한 UI/UX와 마크다운 에디터 사용으로 velog를 애용하고 있다.
그런데 velog엔 백업 기능이 없고, 완벽주의자 + 안전과민증 성격이라 백업 기능이 없다면 불안함이 극대화된다.
또한 velog의 마크다운 사용으로 노션이나 Jekyll 블로그(Github Pages) 등의 플랫폼으로 쉽게 옮겨다닐 수 있기 때문에 글들을 내보내는 기능이 있다면 더욱 좋겠다고 생각하였다.
또한 주기적으로 자동으로 백업해준다면 더욱 좋을 것인데, 이것을 이 포스팅에서 구현해볼 것이다.
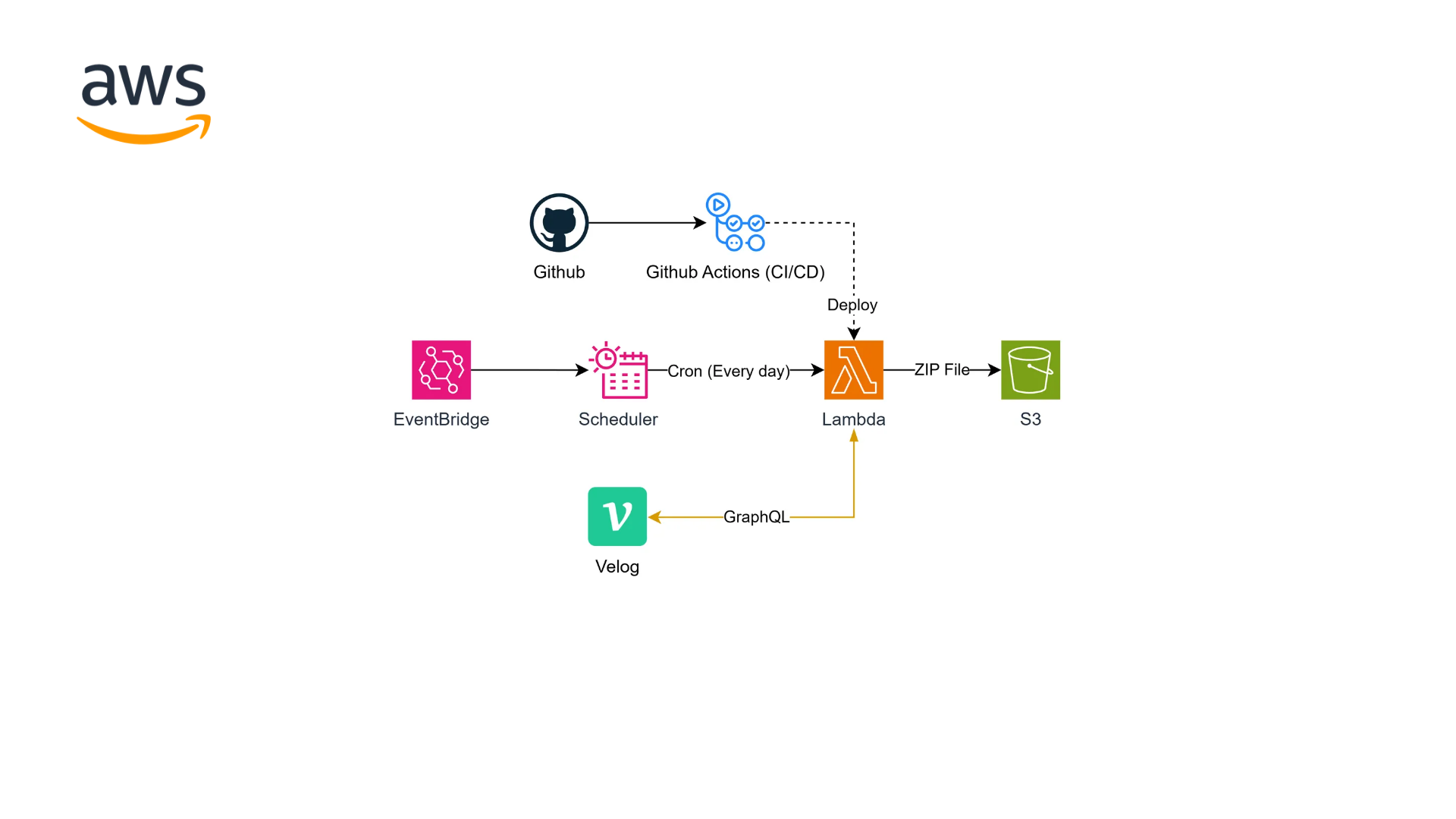
아키텍처를 미리 스포하자면 아래와 같다.
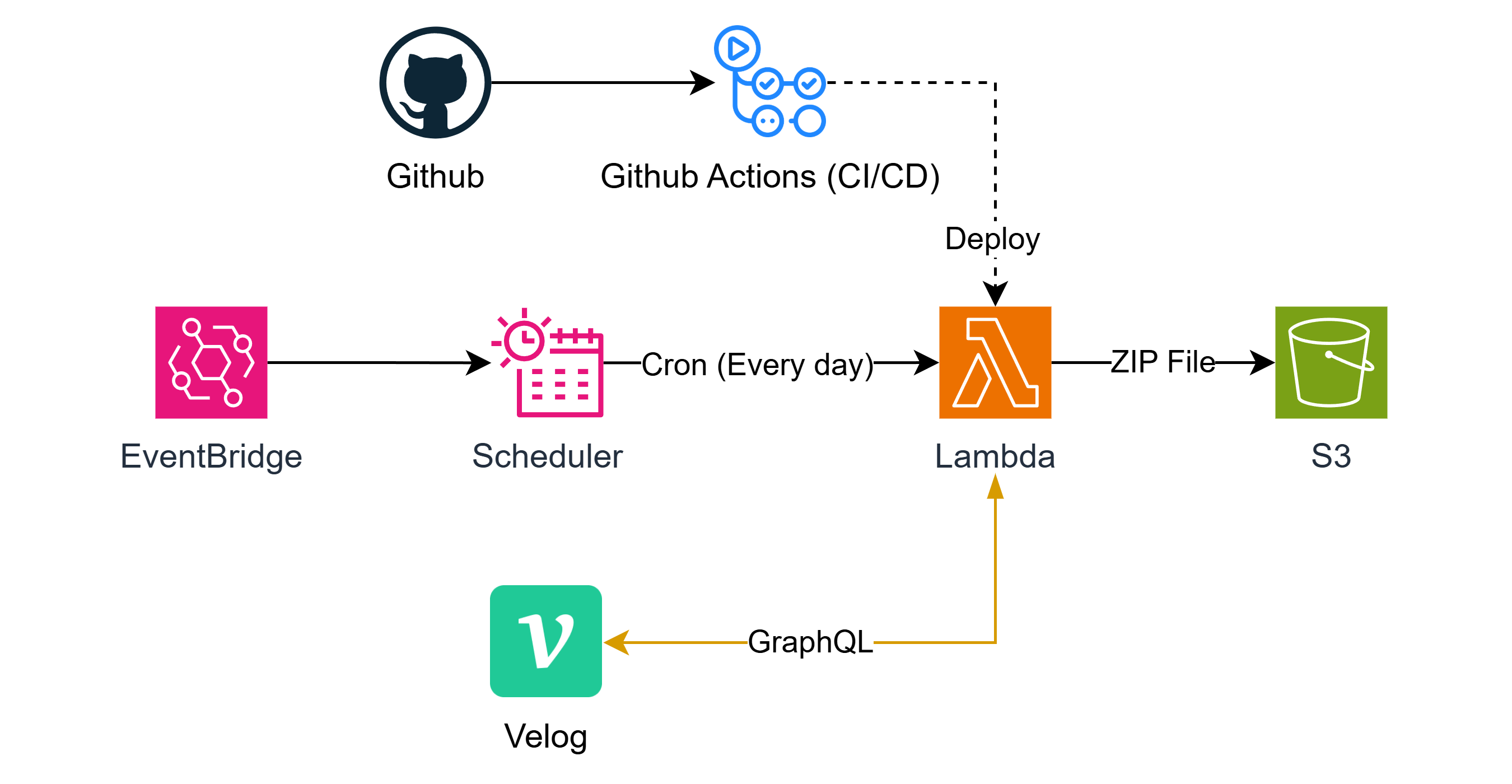
해당 포스팅에서 사용한 소스코드는 아래의 깃허브 레포지토리에서 확인할 수 있다.
1. Velog API
먼저 velog에서 공식적으로 API에 대한 정보를 제공해주지 않는다. 그러거나 말거나 브라우저의 DevTools로 velog의 API를 조사해보았다.
velog는 GraphQL API를 사용한다. 일반적인 REST API를 사용할 줄 알았는데 의외다.
혹여나 SSR(Server Side Rendering)되어 HTML 페이지만 보내와 직접 파싱하거나 크롤링으로 게시글 수정 -> 마크다운 가져오기 이런식으로 우회적인 방법을 써야할까 걱정이 되었으나, 다행이도 SSR된 페이지와 GraphQL 응답이 동시에 받아오는걸 확인할 수 있었다.
게시글 수정 버튼을 누르면 별다른 페이지 이동 없이 동적으로 처리되는 것을 보면 이러한 동적인 작업을 위해 GraphQL을 사용하여 따로 받아오는 것인 듯 하였다.
What is GraphQL?
GraphQL을 설명하기 전에 REST API가 무엇이고 어떠한 한계가 있었는지를 알아야 이해하기 쉽다.
REST API
사실상 표준으로 쓰이는 HTTP API의 대표적인 형태인 REST API는 HTTP 메서드(GET, POST 등)와 해당 리소스가 위치해 있다는 경로인 URI를 바탕으로 해당 리소스에 대해 CRUD(Create/Read/Update/Delete) 작업을 한다는 것이 원칙인 형태이다.
때문에 여러 엔드포인트를 가지며 각 엔드포인트는 처리하는 작업이 해당 리소스의 처리와 관련된 것도 REST API의 원칙 중 하나다.
쉽게 말해 HTTP를 사용하여 CRUD 작업을 처리하는 것이 REST API인데, REST API의 단점이 존재한다.
(1) Over Fetching
예를 들어 게시판을 만들었는데, 특정 유저의 정보 중 팔로워 수만 가져온다고 생각해보자.
그럼 아래와 같은 REST API 요청을 통해 유저의 데이터를 가져올 것이다.
GET /api/users/kim{
"username": "Kim Jun Young",
"createAt": "2025-07-05T13:03:43.099Z",
"email": "normal8781@gmail.com",
"phoneNumber": "010-XXXX-YYYY",
"role": "admin",
"followers": [ ... ],
... (중략)
}그런데 문제는 팔로워(followers)만 가져올건데, 필요 없는 속성도 같이 응답으로 받는다는 것이다.
요청이 많이 없는 경우엔 괜찮을 수 있으나, 서비스가의 규모가 커지면 이러한 사소한 문제도 큰 문제가 될 수 있다.
이렇게 불필요한 요청도 같이 응답으로 받는 문제를 Over Fetching이라 한다.
만약 해결책으로 팔로워만 따로 받는 API 엔드포인트(/api/users/{id}/followers)를 만들었다고 치면 어떨까? 그럼 아래와 같은 문제가 발생한다.
(2) Under Fetching
이는 Over Fetching과 정확히 반대인데, 어떠한 정보를 가져올 때 한번에 가져오지 못하고 여러 요청을 통해 가져와야 한다는 것이다.
그 예시가 위에서 얘기하였던 분리된 팔로워를 받는 API 엔드포인트인데, 특정 사용자에 대한 정보 표시를 위해 GET /api/users/kim과 GET /api/users/kim/followers를 같이 요청해야 한다.
다른 예시로 게시글을 가져오는데, 유저에 대한 자세한 정보도 필요하여 해당 게시글에 있는 유저 ID를 바탕으로 유저의 정보를 가져오는 API를 한번 더 호출하게 된다.
이 과정에서 Over Fetching도 발생할 수 있으며, 이렇게 문제가 지속되어 규모가 커지면 네트워크적 리소스 낭비도 심해지게 된다.
이러한 문제는 REST API의 한계점으로, 이를 보완하기 위해 GraphQL 형태의 API 구조가 생겨나게 됐다.
GraphQL API
그럼 Over/Under Fetching의 확실한 해결책은 무엇일까? 바로 한번의 요청으로 필요한 요소만 가져오면 된다.
그러한 방식을 사용하는 대표적이고 자주 사용하는 개념이 있는데, 바로 SQL이다. RDBMS에서 데이터를 관리하고 조작하기 위한 쿼리 언어이다.
그러한 쿼리 언어를 API에 적용한 것이 GraphQL이다.
GraphQL은 아래와 같이 자체적인 쿼리 언어를 사용하여 요청을 할 수 있다.
query GetUser($username: String) {
user(username: $username) {
username
followers
}
}이렇게 되면 특정 유저의 username과 followers만 가져올 수 있게 되는 것이다.
GraphQL API의 구현을 다루는 것이 아니기 때문에 본 포스팅에선 자세히는 다루지 않으나, 아래와 같은 주요 용어는 알아두도록 하자.
- 스키마(Schema): 쿼리문이나 타입 등을 정의함
- 타입(Type): GraphQL은 타입 기반의 쿼리 언어임. 스키마를 통해 사용자 지정 타입을 선언할 수 있음.
- 쿼리(Query): 읽기 전용으로 데이터를 읽을 때 사용하는 구문
- 뮤테이션(Mutation): 쓰기/변경/삭제 전용으로 데이터를 조작할 때 사용하는 구문
- 변수(Variables): 변수를 직접 리터럴로 하드코딩하면 쿼리문은 매번 다른 쿼리문으로 인식하여 캐싱과 로깅의 어려움이 있음. 때문에 GraphQL의 쿼리문 캐싱, 로깅의 편리함, 쿼리 인젝션의 방지 등을 할 수 있음.
다만 GraphQL의 특성 상 쿼리문 사용으로 바이너리 파일(blob) 전송의 어려움, 고정된 요청의 경우 REST API에 비해 오버헤드의 발생으로 성능이 저하될 수 있다는 점이 있다.
NodeJS의 GraphQL 요청 클라이언트 구현체 중 대표적으로 프론트엔드(특히 리액트)에서 자주 사용되는 apollo-client, 가볍고 심플한 graphql-request 등이 있다.
전자는 세부적인 설정을 지원하나, 본 포스팅에선 간편한 graphql-request 라이브러리를 사용할 것이다.
또한 타입스크립트와 함께 codegen 등의 도구를 사용하여 스키마를 미리 정의하고 타입 안전성을 챙길 수 있으며, 해당 포스팅에선 codegen도 같이 사용할 예정이다.
Testing Velog API
(1) Posts
사용자의 글 목록을 확인한다. 어떤 GraphQL 쿼리를 사용하는지 확인하기 위해 DevTools로 확인해보았다.

위 요청의 페이로드를 바탕으로 Postman에서 테스트를 진행해보았다.
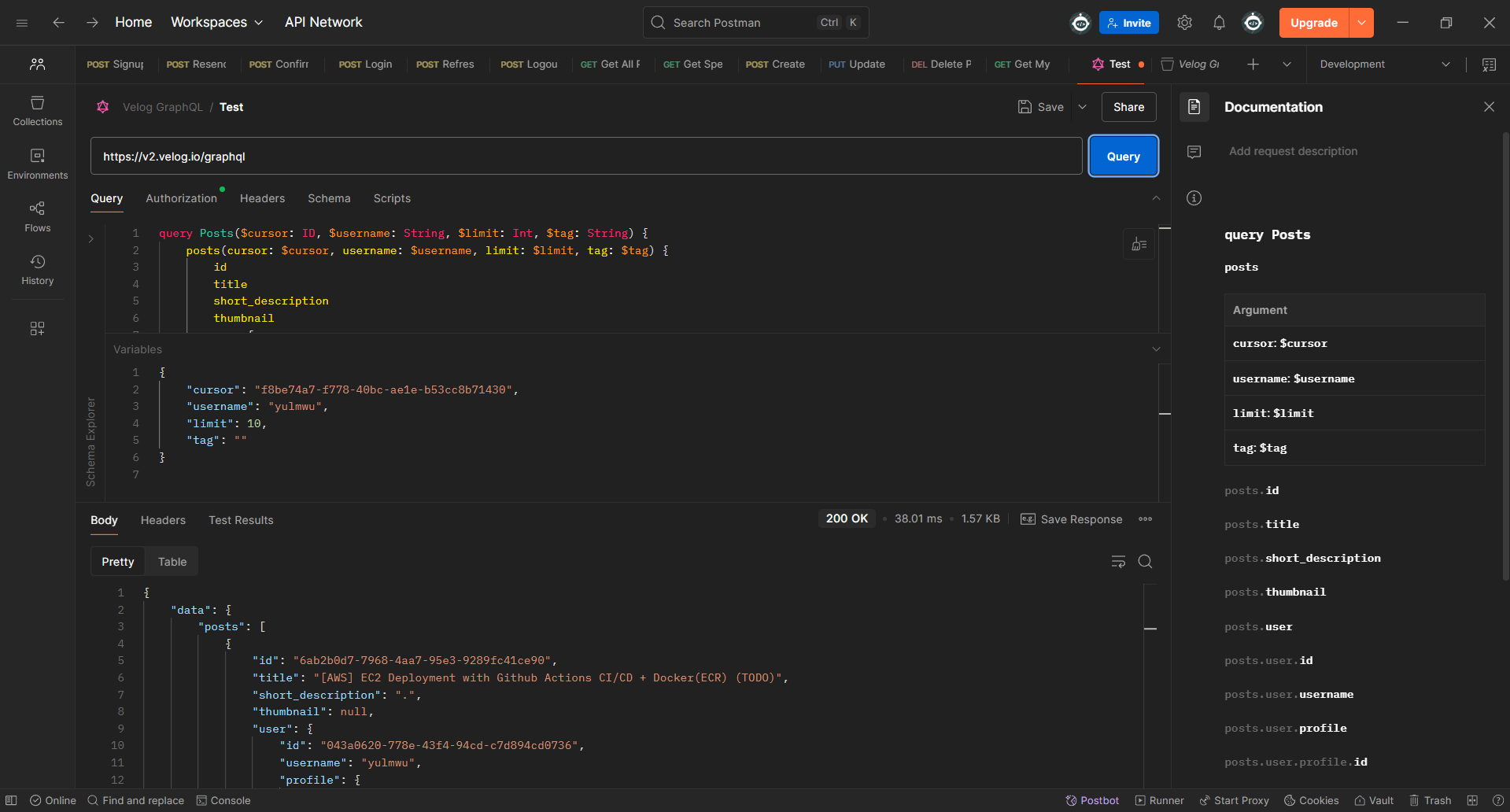
잘 작동하는 것이 보이며, limit은 cursor(글 ID)를 기준으로 하여 최근 몇개의 글을 가져올 것인지를 나타내고 최대 값은 100이다.
그런데 테스트해보니 최대 값은 로직 상 100으로 제한이 되어있으나, 실제 테스트에선 50개까지만 가져오는 것을 확인할 수 있었다.
때문에 안전하게 기본 값인 20개로 제한하도록 하였다.
cursor에 있는 글 ID는 포함하지 않고 그 최신 글들을 가져온다. 즉 페이지네이션을 위한 속성이다.
만약 cursor 속성에 값이 없다면 해당 유저의 가장 최신글들을 가져오는데, 그럼 백업 로직 구현 시 아래와 같이 작성하면 될 듯 하다.
cursor없이 최근 20개의 글을 가져온다.- 가져온 글들 중 맨 마지막 글의 ID를
cursor로 설정하여 다시 20개의 글들 가져온다. - 모든 글을 가져올 때 까지(가져온 글이 20개 미만이라면 종료) 2번을 반복한다.
더욱 더 확실하게 보자면 velog의 소스코드는 깃허브에 공개되어 있기 때문에 해당 소스코드를 참조하면 아래와 같은 GraphQL 스키마를 확인할 수 있다.
여담으로 한가지 특이한것은 Lambda + API Gateway를 사용한 서버리스 아키텍처라는 것이다.

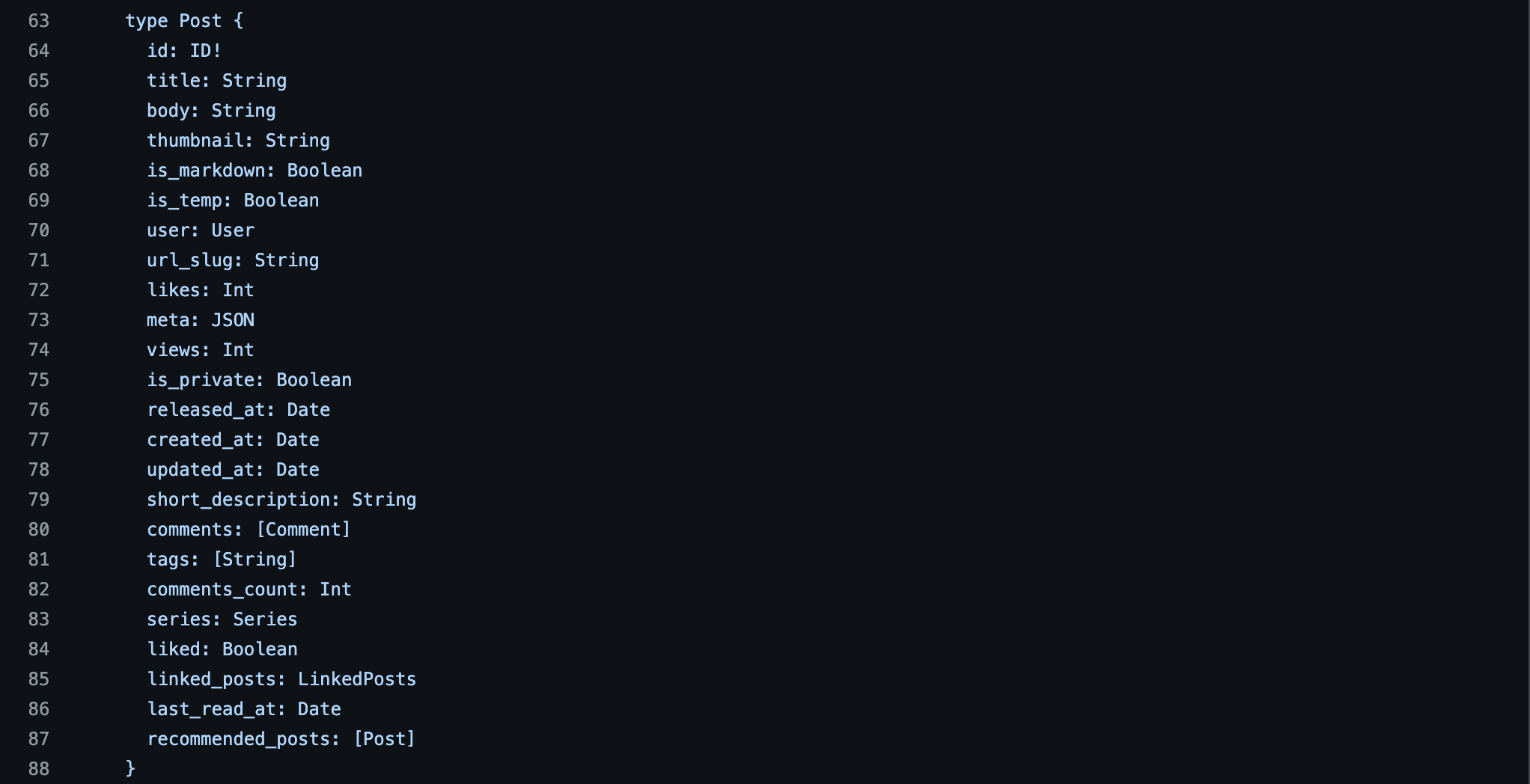
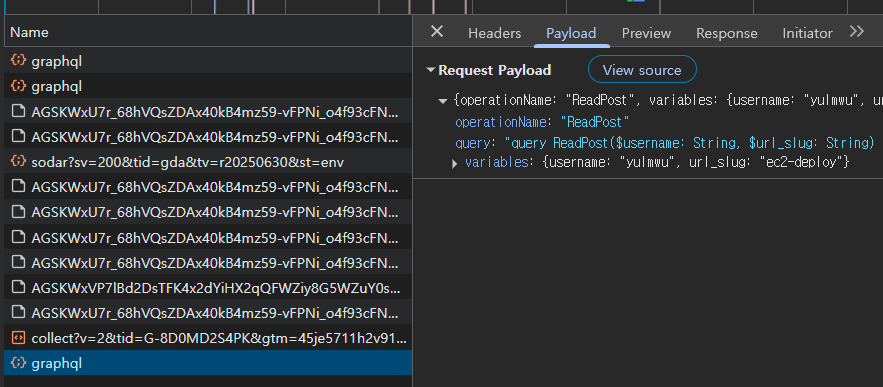
(2) ReadPost
특정한 글에 들어갔을 때 요청되는 GraphQL이다.
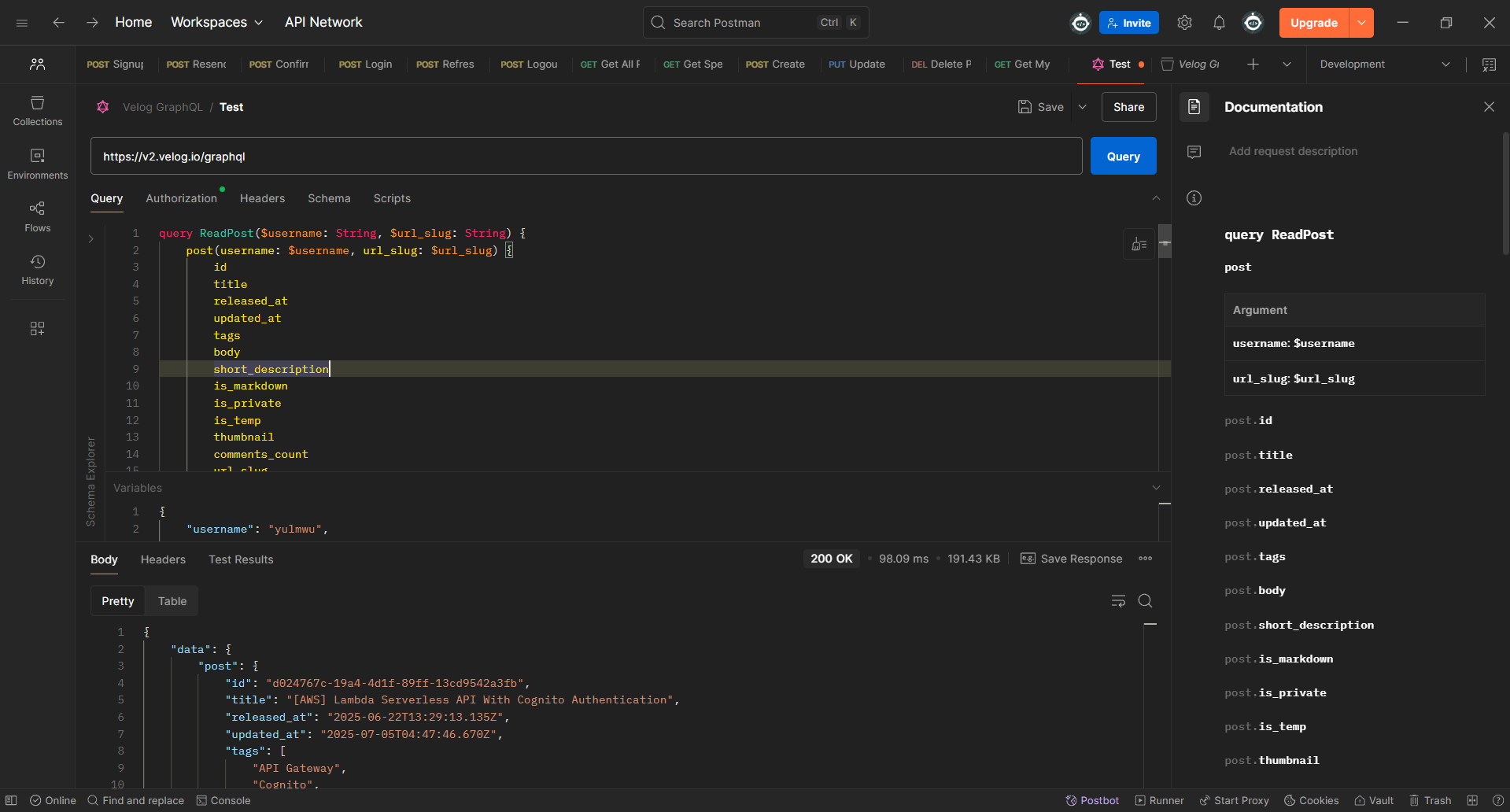
Postman을 사용하여 글에 들어갔을 때 호출되는 ReadPost에 대한 GraphQL 요청을 날려보았다.
만약 JWT 엑세스 토큰이 있다면 시리즈 등에 비공개 글이 표시되며, 검증되지 않았다면 공개 글만 표시된다.
원래라면 SSR으로 본문의 내용을 GraphQL 요청으로 날리지 않고 HTML로 보내져오는데, 전 게시글/다음 게시글을 표시하기 위해 GraphQL 요청을 통해 가져오는 것을 확인하였다.
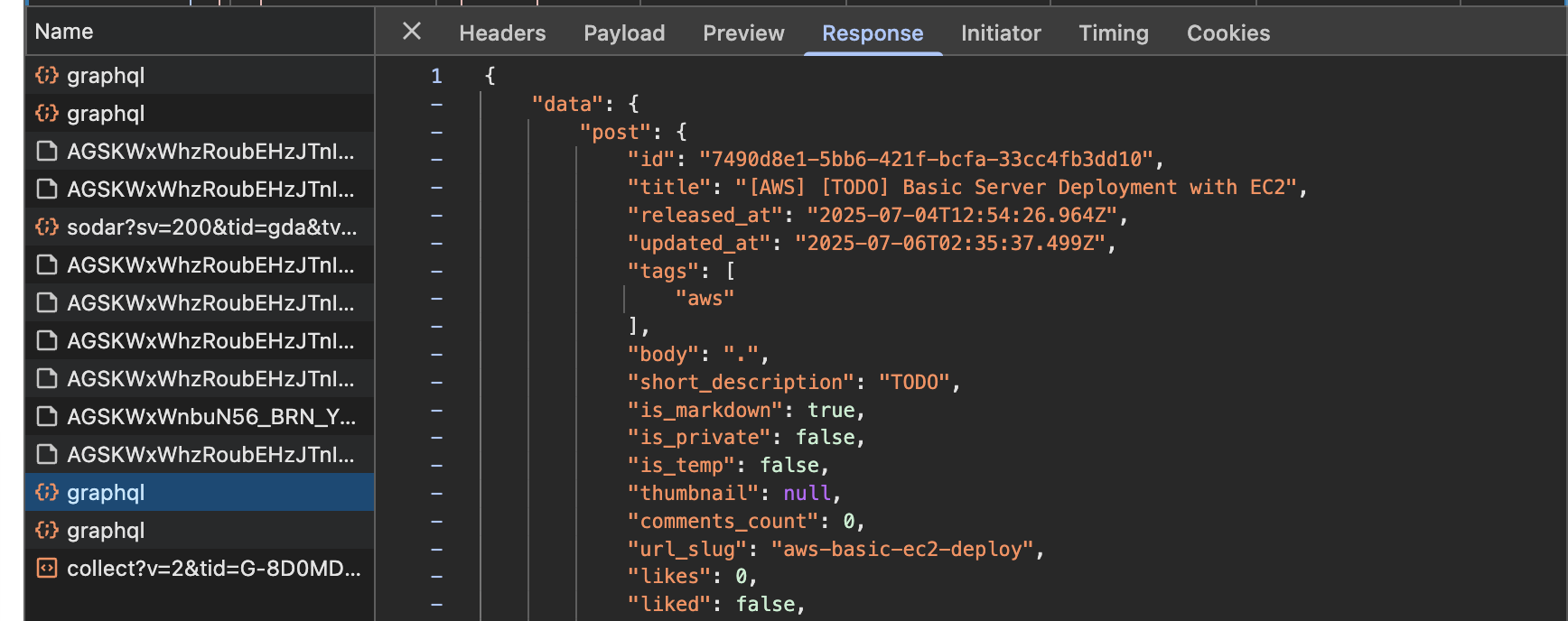

또한 velog 백엔드의 코드 상 URL Slug(페이지 식별에서 간결하고 이해하기 쉽게 표현된 문자, SEO에 유리함)를 바탕으로 가져오거나 게시글의 ID를 사용하여 가져올 수 있다.
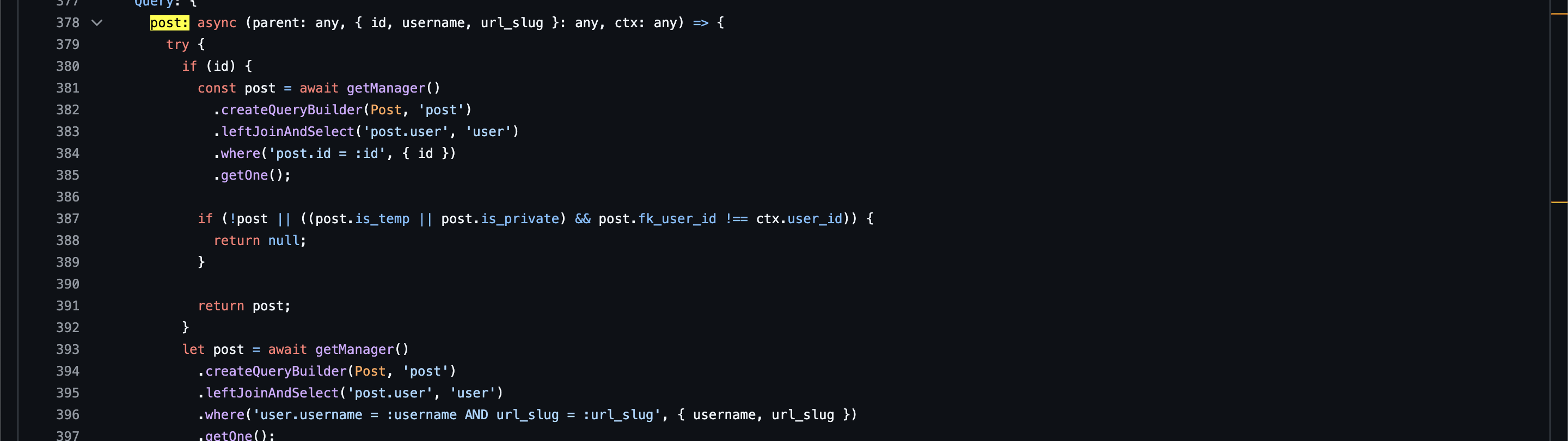

하지만 프론트엔드에선 URL Slug를 통해 게시글을 가져오니 필자도 URL Slug를 사용하여 가져오도록 하겠다.
2. Let's write the Code
GraphQL Request Testing
먼저 타입스크립트를 사용하여 타입 안전성을 챙길 것이기 때문에 velog 백엔드 소스코드에서 GraphQL 스키마를 찾아서 GraphQL 스키마와 Documents(실제 쿼리문이나 뮤테이션 등의 요청 쿼리문이 선언된 파일)를 만들어주었다.

그리고 npx를 통해 graphql-codegen을 실행하거나 npm scripts에 아래와 같이 명령어를 등록해두고 실행하면 정의해둔 스키마와 Documents를 바탕으로 자동으로 타입스크립트 타입과 요청 함수를 작성해준다.

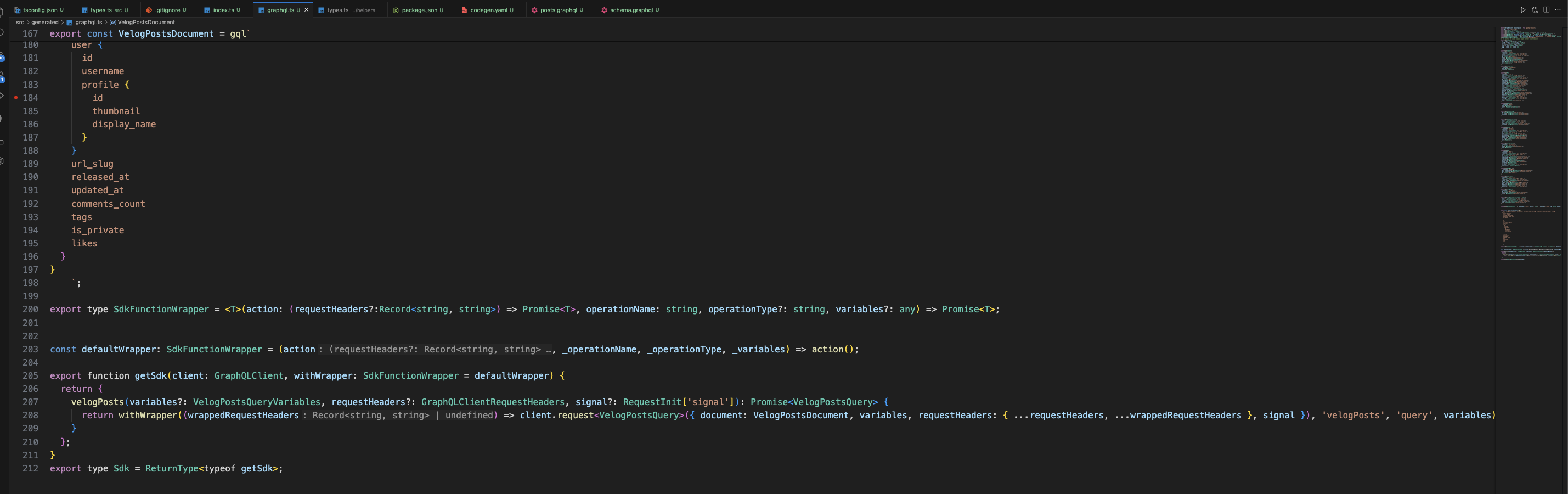
그러면 아래와 같이 간단한 코드를 통해 요청을 보낼 수 있다.
import { GraphQLClient } from 'graphql-request'
import { getSdk, VelogPostsQueryVariables } from './generated/graphql'
const client = new GraphQLClient('https://v2.velog.io/graphql')
const sdk = getSdk(client)
const variables: VelogPostsQueryVariables = {
cursor: '',
limit: 10,
username: 'yulmwu',
}
const fetchUser = async () => {
return await sdk.velogPosts(variables)
}
fetchUser()
.then((data) => {
console.log(data)
console.log('Total posts fetched:', data.posts?.length)
})
.catch((error) => console.error('Error fetching user:', error))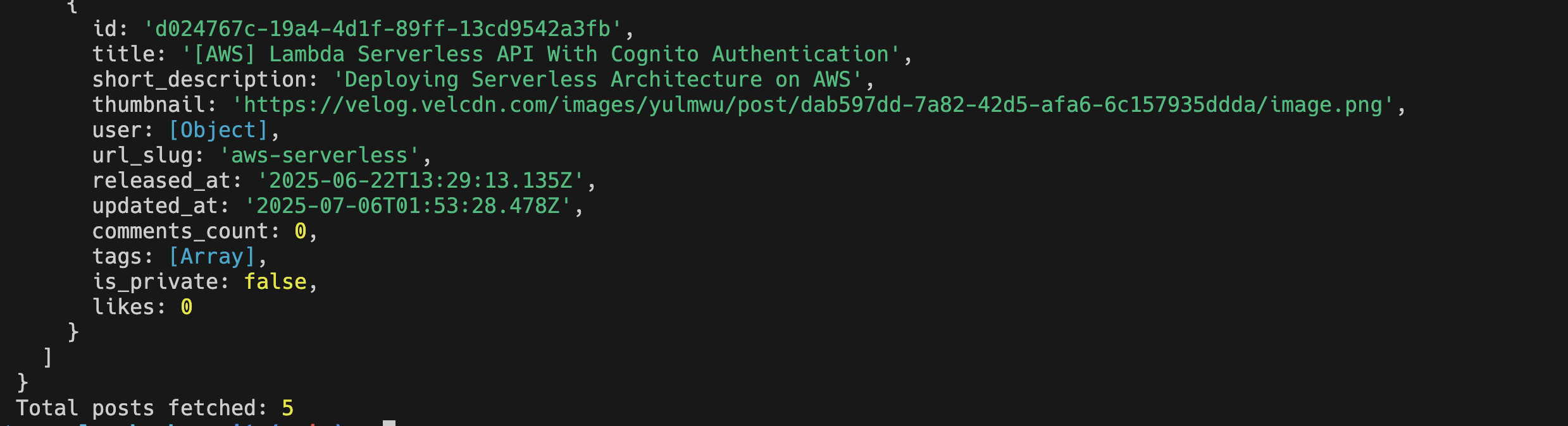
그럼 위와 같이 성공적으로 요청이 보내지며 로그가 찍히는 것을 볼 수 있다.

cursor를 설정하지 않은 상태의 글 목록인데, 위 코드를 기준으로 최신 10개의 글들을 가져온다. (현재 공개 상태의 글이 5개 밖에 없으므로 정상임)
만약 cursor를 Server Deployment with Docker, ECR, ECS and Fargate 글을 기준으로 설정하면 아래와 같이 출력된다.


페이지네이션으로 한번에 가져올 수 있는 글들의 최대 수를 20개로 제한하였으므로, limit을 20으로 설정하고 마지막 글을 기준으로 다음 최신 20개를 글을 가져오는 식으로 로직을 작성하면 된다.
GraphQL Request with Authorization
하지만 작은 문제가 있는데, 비공개 상태의 글은 헤더에 JWT 토큰을 넣어 인증을 해야 확인할 수 있다.
DevTools에서 JWT 엑세스 토큰을 추출한 뒤 GraphQL 클라이언트 헤더에 넣어 요청하면 비공개 글 까지 확인할 수 있다.

다만 모든걸 자동화를 할 예정이기 때문에 이 또한 자동으로 해야하는데, 자체적인 로그인 시스템을 사용했다면 쉽게 로직을 작성할 수 있었을 것이다.
하지만 velog는 OAuth를 사용하여 구글이나 깃허브 등의 서브파티 로그인을 사용하기 때문에 셀레니움과 같은 크롤러를 사용해야 될 듯 싶다.
너무 복잡해지고 귀찮아지므로 이 작업은 처리하지 않고, 환경 변수로 받아 수동으로 설정하게 하였다.
import dotenv from 'dotenv'
dotenv.config({ quiet: true })
const client = new GraphQLClient('https://v2.velog.io/graphql', {
headers: {
Authorization: `Bearer ${process.env.VELOG_JWT_ACCESS_TOKEN}`,
},
})Fetching All Posts
이제 위 GraphQL 요청(velogPosts Operation)을 바탕으로 모든 포스트를 가져오는 코드를 작성한다.
const LIMIT = 20
const fetchPosts = async (username: string, cursor?: string, posts: Post[] = []): Promise<Post[]> => {
const data = await sdk.velogPosts({
cursor,
limit: LIMIT,
username,
})
if (data.posts && data.posts.length > 0) {
posts.push(...data.posts.filter((post): post is Post => post !== null))
if (data.posts.length < LIMIT) return posts
const nextCursor = data.posts[data.posts.length - 1]?.id
if (nextCursor) await fetchPosts(username, nextCursor, posts)
}
return posts
}로직은 위에서 설명하였는데, 쉽게 말해 먼저 가장 최신의 게시글 20개를 가져오고 마지막 글(posts[length - 1])의 ID로 다시 다음 20개의 게시글을 가져온 다음 20개 미만이라면 함수를 끝낸다.


잘 작동한다.
Fetching Specific Post
특정 게시글에 대해 세부적인 내용을 가져오는 API로, 아래와 같은 GraphQL 스키마를 사용한다.
type Query {
post(id: ID, username: String!, url_slug: String): Post
}위 스키마와 실제 요청을 보냈을 때 요청되는 쿼리문을 바탕으로 Document를 작성하였다.
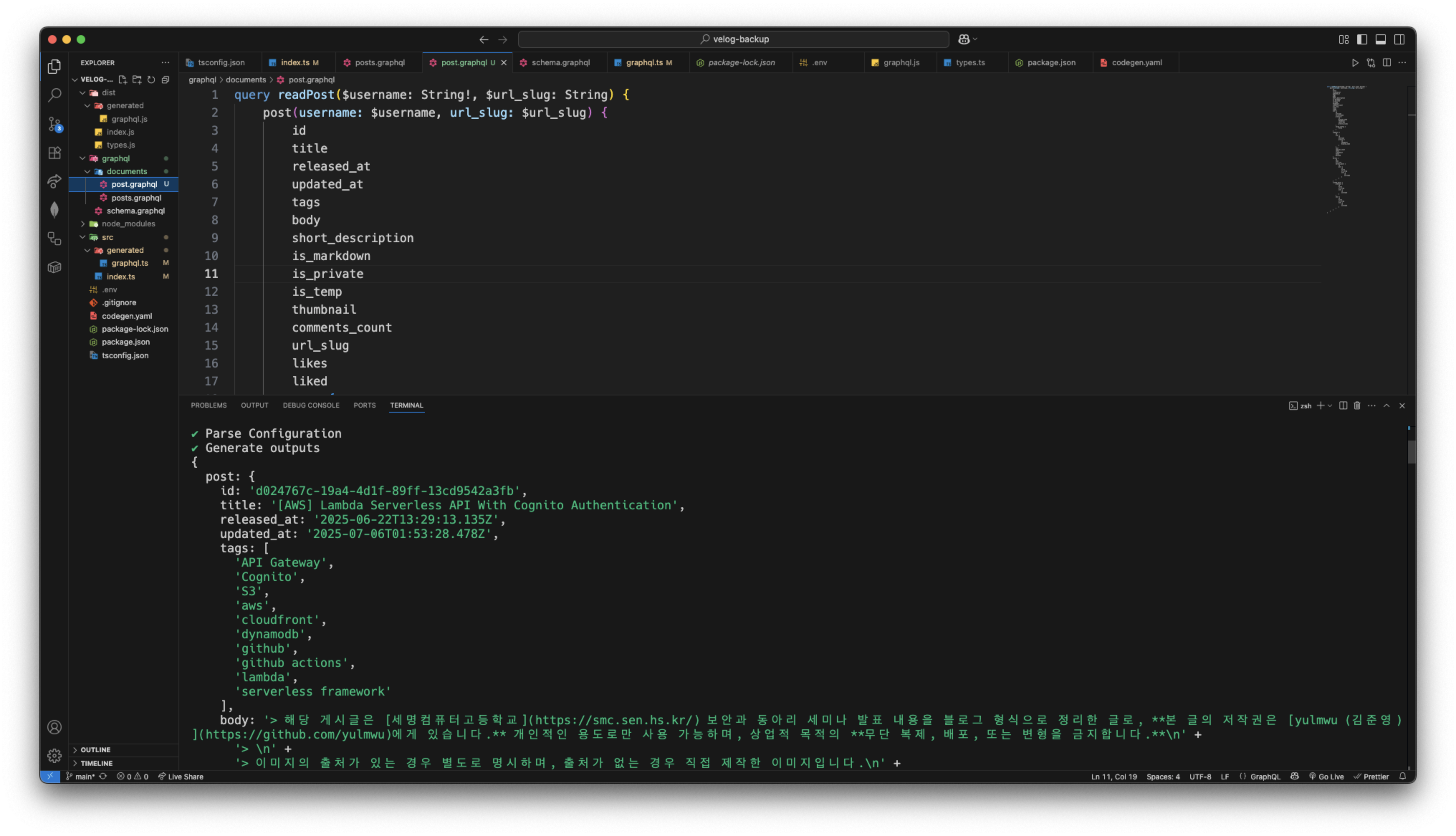
마찬가지로 잘 나타나는 것을 볼 수 있다. 이로써 백업 기능의 90%는 완성했다고 보면 된다.
이제 모든 리펙토링 후 각 게시글 별 마크다운 저장 및 Jeykll 블로그 형태의 메타데이터도 같이 작성되게 만들면 된다.
File Writer
마지막으로 개별 포스트를 바탕으로 파일을 작성하면 코드는 완성된다.
또한 ESBuild를 적용하여 번들링을 하였고, 다음으로 AWS 람다에서 실행하기 위해 코드를 약간 수정하였다.

먼저 AWS 람다에 실행하여 zip 파일로 S3에 저장할것이기 때문에 위와 같이 람다에서 /tmp 디렉토리를 사용한다.
또한 S3의 용량을 아끼기 위해 최근 5개의 백업본만 남겨두기 위해 아래와 같은 코드도 작성하였다.
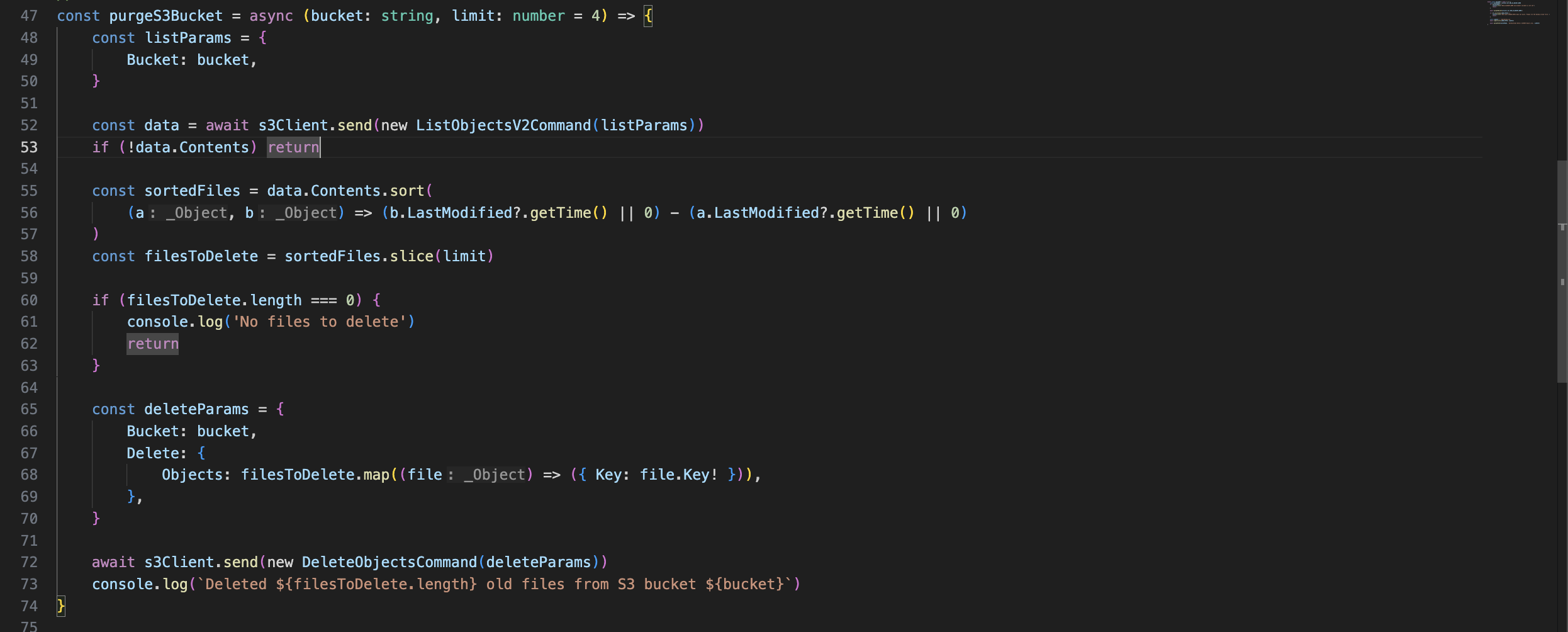
3. Let's build the AWS Infra
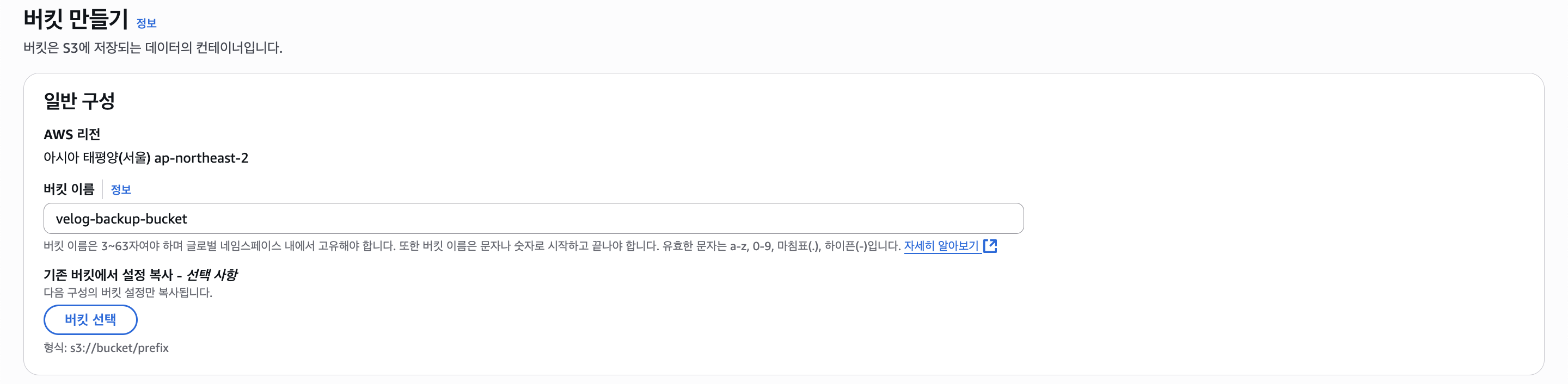
S3
백업 파일들을 저장할 버킷을 만든다.
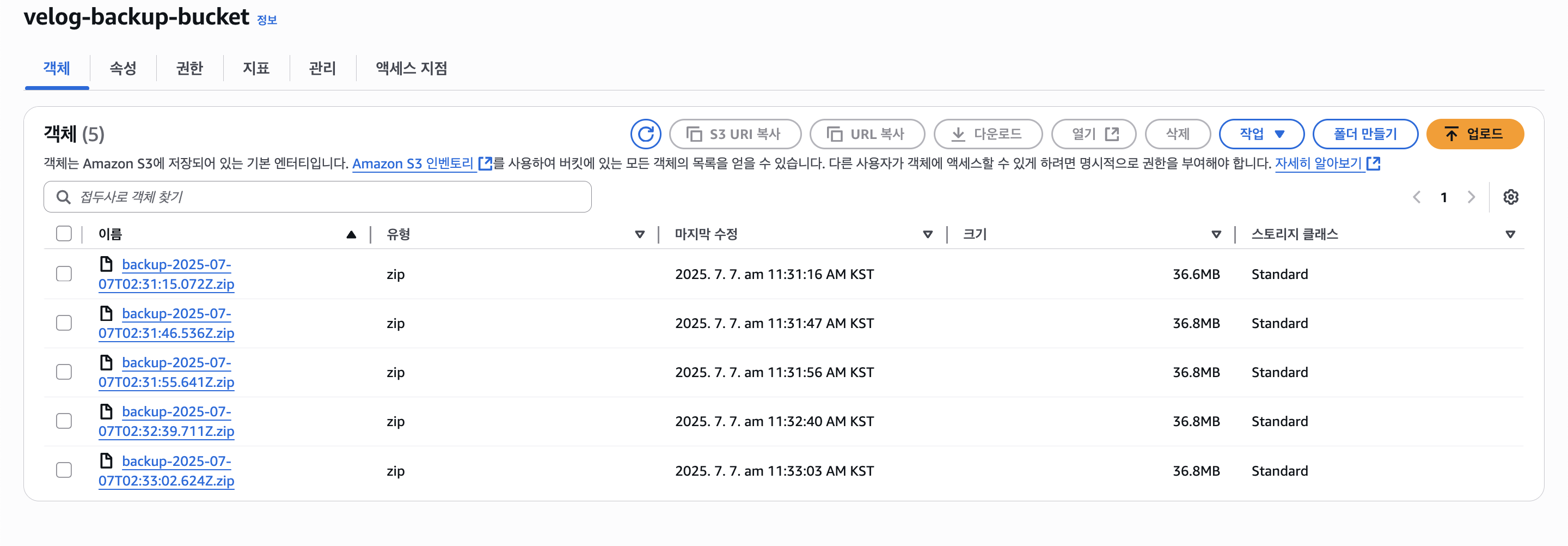
버킷을 만들고 환경 변수를 설정한 뒤 코드를 실행해보면 아래와 같이 잘 작동하는 모습을 볼 수 있다.

다음으로 람다에 업로드하여 나중에 EventBridge와 연동하도록 해보자.
Lambda
먼저 람다 함수를 만들고 코드를 업로드하여 테스트를 해보았다.
다음으로 S3에 접근할 수 있도록 IAM 정책을 수정해주었다.

또한 로컬에서 돌려도 3초는 턱없이 부족하니 아래와 같이 3분으로 타임아웃 설정을 해두었다.

이후 람다를 실행해보면 아래와 같이 잘 작동한다.
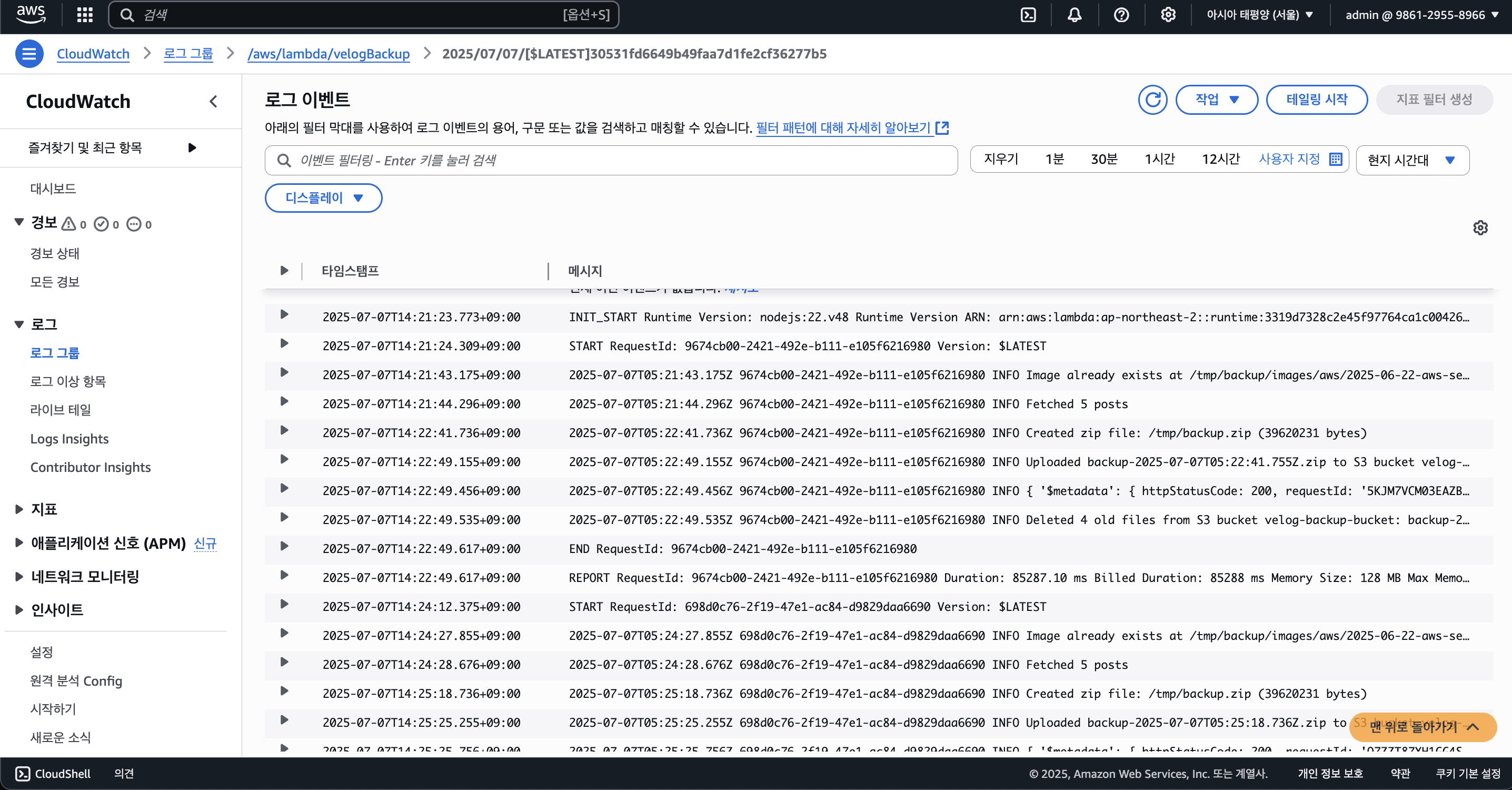
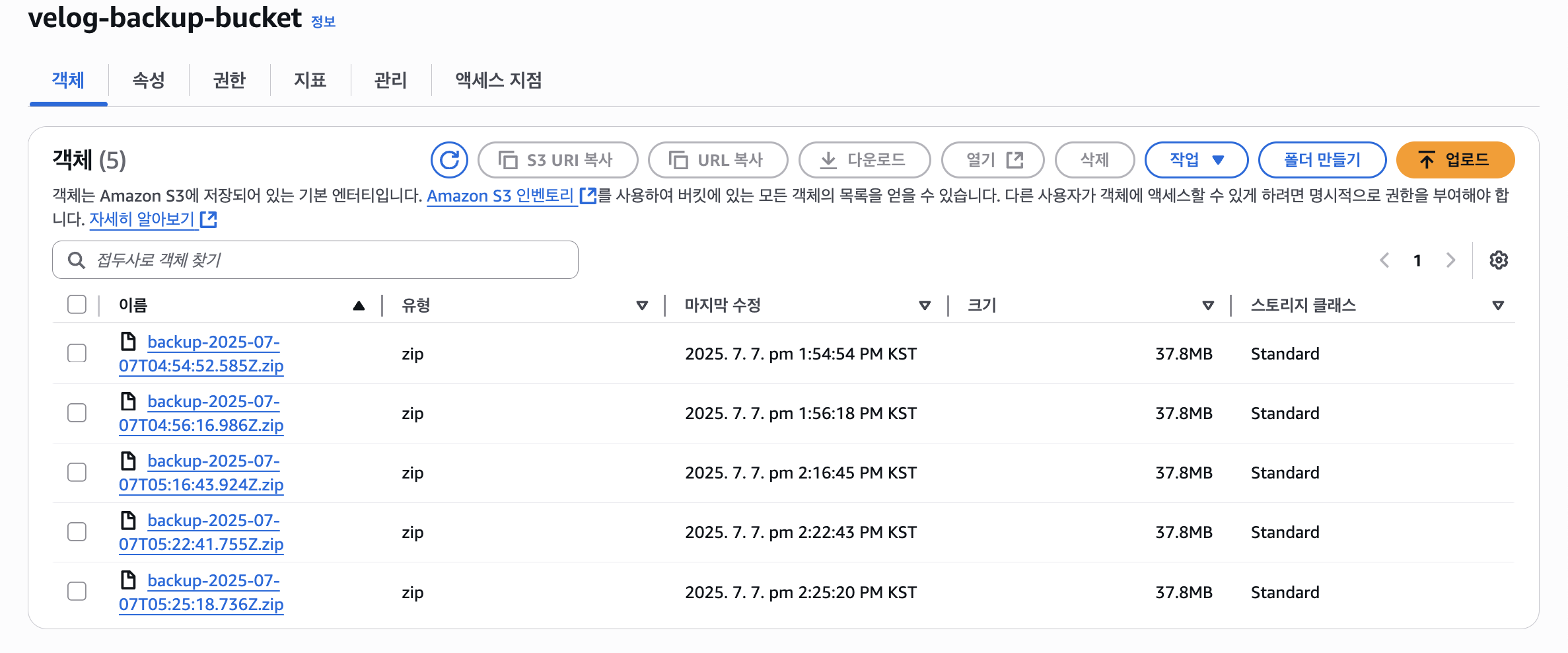
S3에도 백업본이 잘 저장되는 것을 볼 수 있다.
EventBridge + Scheduler
마지막으로 EventBridge 서비스의 Scheduler를 사용하여 매일마다 백업 람다 함수를 실행할 수 있도록 해보자.
먼저 EventBridge의 일정(Scheduler) 항목에 들어가 "일정 생성"을 클릭하자.
일정의 이름을 정하고 아래에 보면 "일정 패턴"이라는 항목이 있는데, 여기서 어느 주기로 반복할지(rate), 또는 언제 반복할지(cron)를 지정할 수 있다.
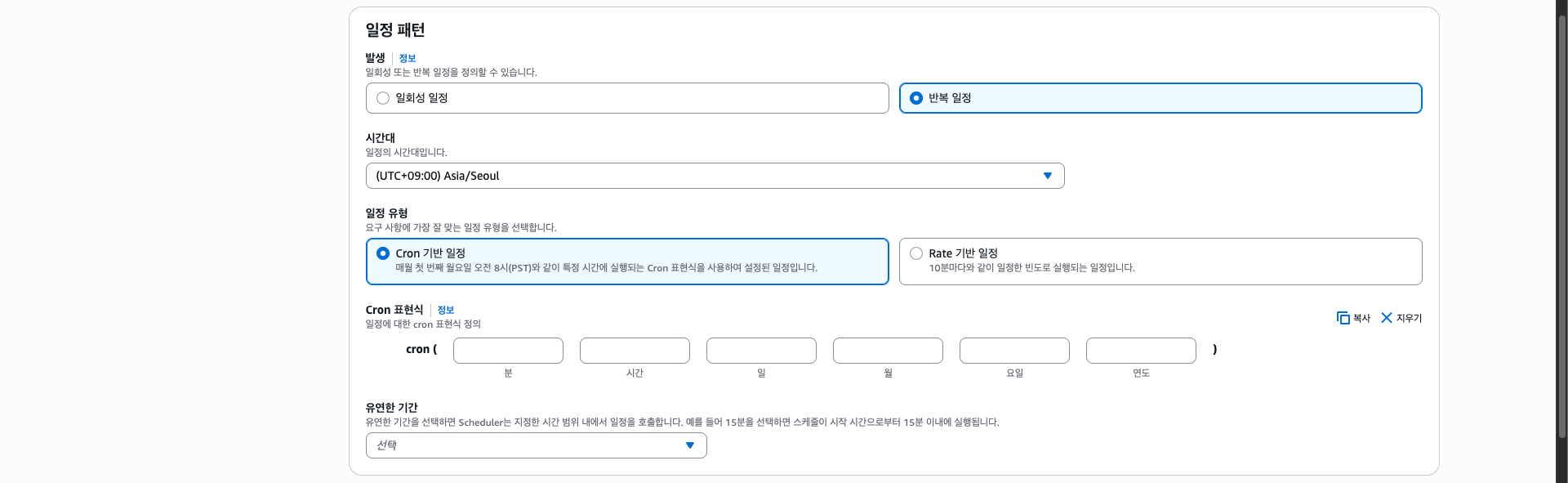
특정 시간마다 반복을 할것이기 때문에 cron을 선택하고, 아래와 같이 설정하였다.
cron(0 0 * * ? *)
cron 표현 식에서 *는 모두(예: 1월~12월), ?는 따로 지정하지 않음을 의미한다. (요일 등)
그리고 0시 0분으로 설정하여 오전 12시에만 작동하도록 하였고, "유연한 기간"은 해당 기간 사이에 실행되게 한다는 것인데 여기서는 사용하지 않는다.
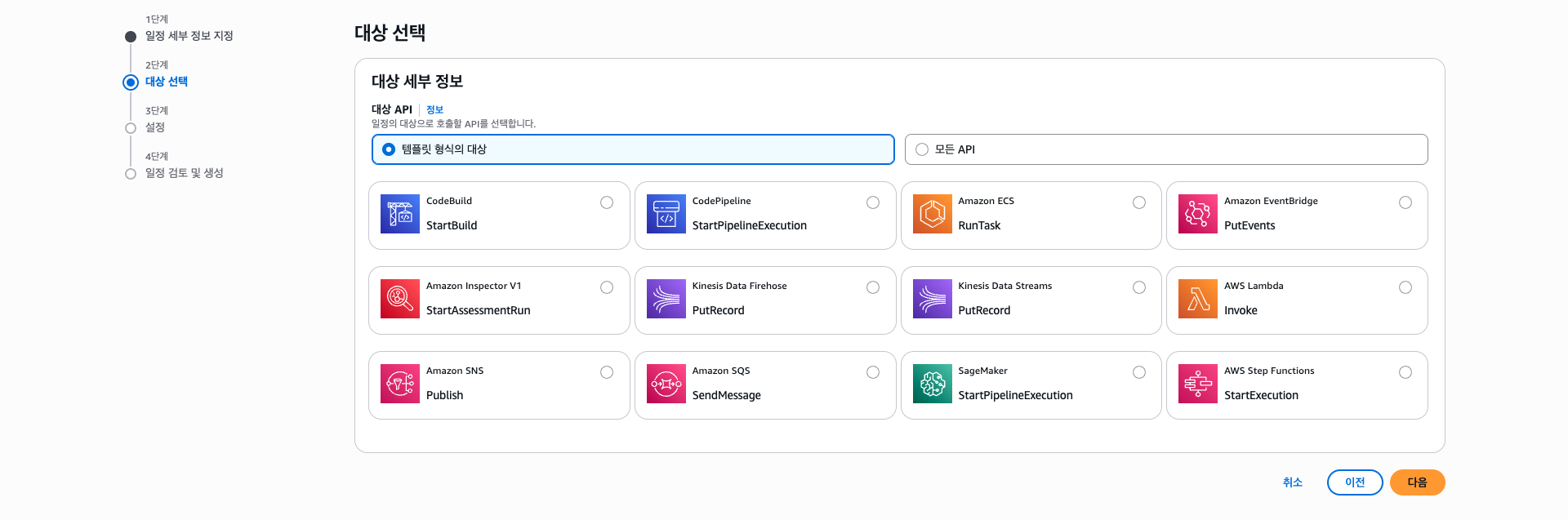
다음으로 대상을 선택하는데, 일정 시간마다 람다 함수를 실행하기 위해 람다 Invoke를 선택한다.

그리고 event 페이로드는 사용하지 않고, 설정을 완료하면 EventBridge Scheduler 설정이 끝난다.

요금의 경우 100만개의 이벤트 당 1달러로, 매달 최대 31개의 Scheduler를 사용하므로 사실상 무료라고 봐도 된다. (매달 거의 0.000031달러 수준)

람다 사용량도 거의 발생하지 않으며, S3 또한 넉넉하게 1GB로 잡아도 요금은 거의 발생하지 않는다.
4. Github Actions CI/CD
이 상태 그대로 사용해도 되지만, 추후 쉽게 코드를 수정하기 위해 Github Actions CI/CD를 사용하여 람다에 자동으로 배포되게 할 것이다.
먼저 빌드와 배포에 필요한 명령어는 아래와 같다.
> npm run esbuild
> rm -rf code.zip
> zip code.zip build/index.js
> aws lambda update-function-code \
--function-name velogBackup \
--zip-file fileb://code.zip \
--region ap-northeast-2이것을 Github Actions에서 작동할 수 있게 워크플로우를 작성한다.
간단하게 워크플로우를 작성할 수 있다.
name: Deploy Lambda
on:
push:
branches:
- main
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v3
with:
node-version: 18
- name: Install dependencies
run: npm ci
- name: Build with esbuild
run: npm run esbuild
- name: Zip the code
run: |
rm -rf code.zip
zip code.zip build/index.js
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v2
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ap-northeast-2
- name: Update Lambda function code
run: |
aws lambda update-function-code \
--function-name ${{ secrets.AWS_LAMBDA_FUNCTION_NAME }} \
--zip-file fileb://code.zip \
--region ap-northeast-2
- name: Update Lambda environment variables
run: |
aws lambda update-function-configuration \
--function-name ${{ secrets.AWS_LAMBDA_FUNCTION_NAME }} \
--environment "Variables={AWS_S3_BUCKET_NAME=${{ secrets.AWS_S3_BUCKET_NAME }}" \
--region ap-northeast-2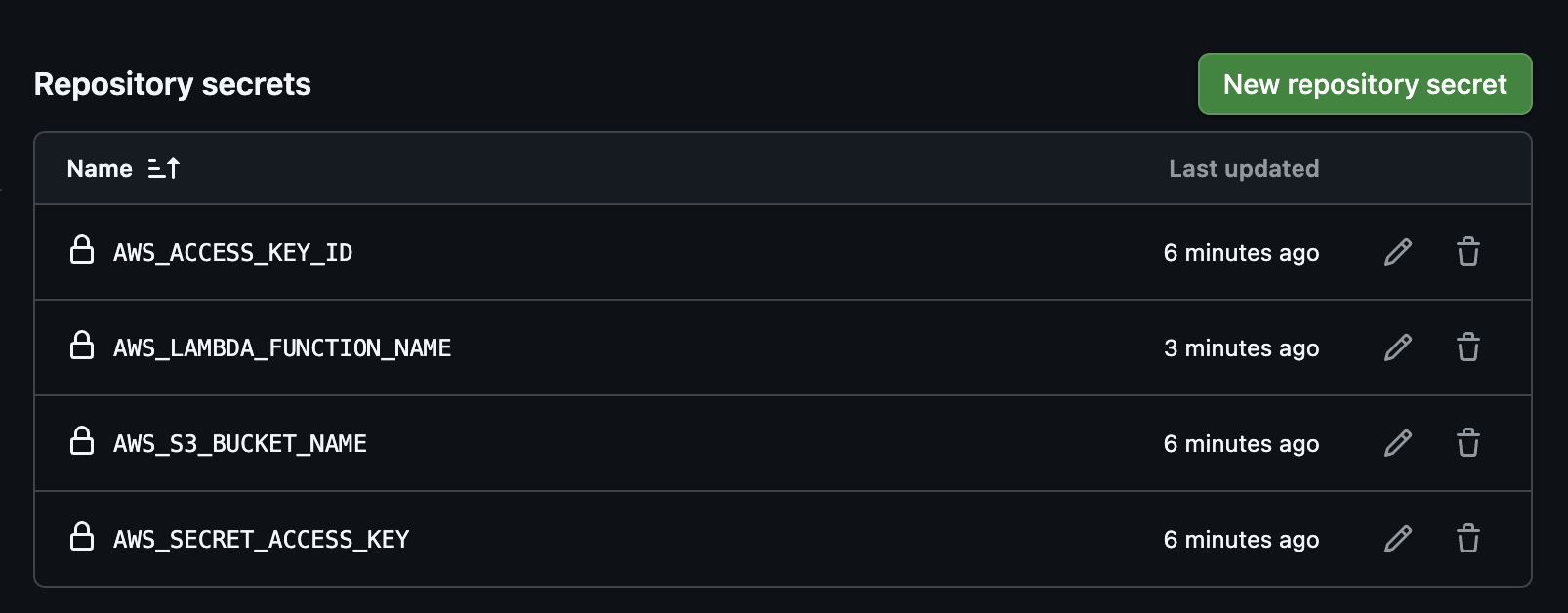
환경 변수까지 설정해두면 아래와 같이 Github Actions를 사용한 CI/CD도 잘 작동한다.
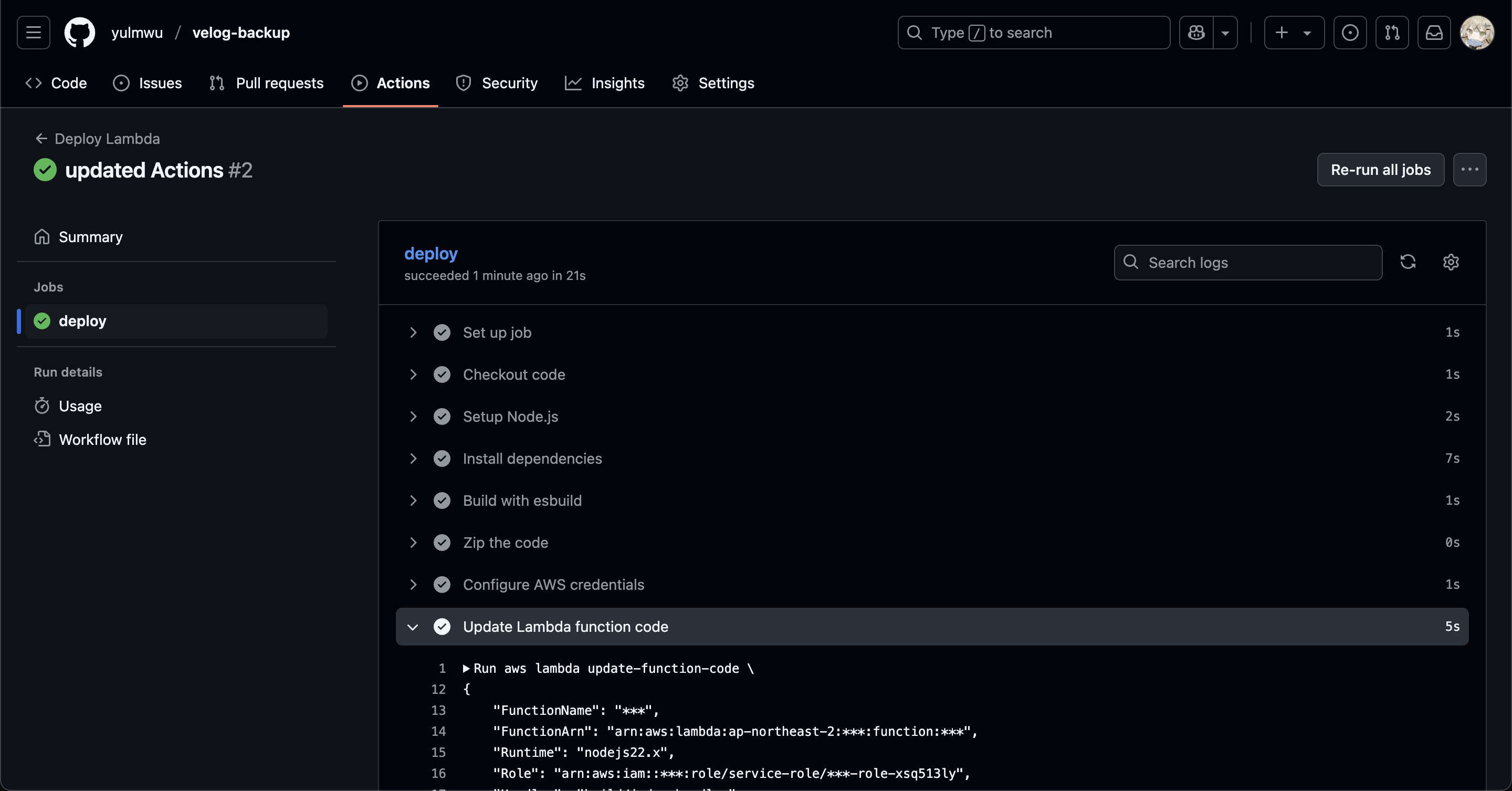
이상으로 velog 백업 기능을 간단하게 제작해보고 AWS 람다 + EventBridge Scheduler를 사용하여 매일마다 실행되게 해보았다.
한동안 사용해봤는데 생각해보니 람다 함수의 실행 시간이 최대 15분이고, 이미지가 많아질 경우 속도도 느려지고 /tmp 용량도 아슬아슬 해질 듯 싶긴 하다.

특히 이미지가 좀 많은 경우 더욱 심해질 듯 한데, 이미지는 CDN 링크 그대로 냅두고 글만 백업한다거나 방식을 바꿔 람다가 아닌 다른 EC2나 ECS와 같은 서비스를 이용하면 어떨까 싶다. (안쓸땐 꺼두고)
끝.
