파이썬의 연산을 위해 사용하는 라이브러리 Numpy에서는 condition을 충족하는 인덱스를 알게 하는 where() 함수도 제공한다.
구조가 어떻게 되어 있을까?
# where를 사용할 다음과 같은 데이터가 있다고 하자.
condition = [True, False, False]
x = [1, 2, 3]
y = [10, 20, 30]
# np.where(condition, x, y) 형태로 사용하면
# condition이 True인 인덱스에는 x값, False인 인덱스에는 y값이 출력된다.
# 즉, [1, 20, 30] 형태이다.
# 직접 구현하려면 아마 이런 형태려나?
def where_diy(cond: list, var1: list, var2: list):
new_arr = []
for i, v in enumerate(cond):
if cond[i]:
new_arr.append(var1[i])
else:
new_arr.append(var2[i])
return new_arr
# 결과값은 [1, 20, 30]으로 출력된다
where_diy(condition, x, y)
공식 문서를 보니, 1차원 배열 형태라면 다음과 같은 연산을 수행한다고 한다.

numpy의 where문은 python에서 for문을 직접 구현하는 것보다 더 빠르다고 한다.
정말 그런가? 코랩으로 테스트 해 보았다.
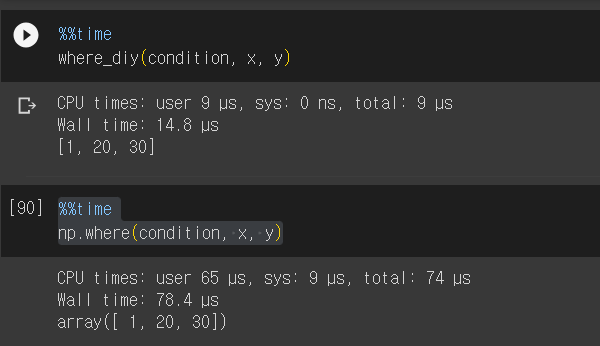
길이가 3인 배열로 테스트 했을 때는 where가 더 느린 것처럼 보인다.
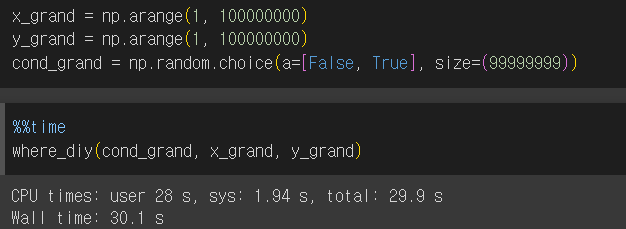
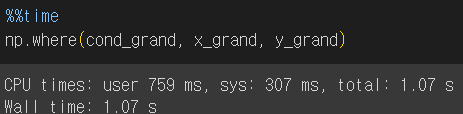
속도 차이는 데이터가 클 때 나타나는 것이므로 배열 크기를 늘려서 다시 테스트 해 보았다.

*임의의 True, False값으로 채운 배열을 만들기 위해 np.random.choice 함수 활용
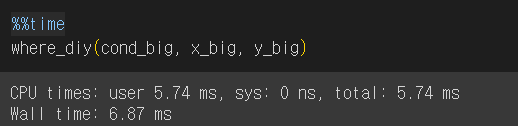
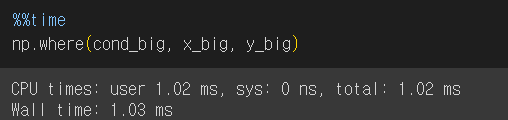
데이터 크기가 클수록 속도 차이가 크다.