AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control
Paper: https://arxiv.org/abs/2104.02180
OVERVIEW
참조 모션 데이터셋과 보상 함수로 정의된 작업 목표가 주어지면, 시스템은 데이터셋에 있는 동작과 유사한 행동을 사용하는 캐릭터의 제어 정책을 합성하여, 물리적으로 시뮬레이션된 환경에서 목표를 달성할 수 있도록 합니다.
중요한 점은 캐릭터의 행동이 데이터셋의 특정 모션과 정확히 일치할 필요는 없으며, 대신 데이터셋에서 나타나는 일반적인 특성을 채택하는 것입니다.
참조 모션들은 행동 스타일에 대한 예시를 제공합니다. 시스템에 서로 다른 모션 데이터셋을 제공하면 캐릭터는 다양한 스타일로 작업을 수행하도록 훈련될 수 있습니다.
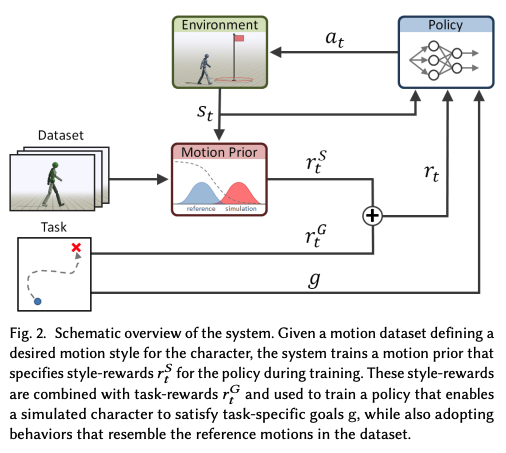
Figure 2는 시스템의 개요를 도식화한 것입니다.
모션 데이터셋 M : 참조 모션들의 집합
각 모션 m_i={q^_it} : 포즈의 연속
모션 클립은 실제 배우의 모션 캡처 데이터나 예술가가 제작한 키프레임 애니메이션에서 수집될 수 있습니다.
이전 프레임워크와는 달리, 이 시스템은 클립을 개별 스킬로 구분하거나 태스크에 특화된 주석 없이도 원시 모션 데이터에 직접 적용할 수 있습니다.
시스템의 작동 방식:
-
정책(Policy) 모델 π(a_t∣s_t, g): 캐릭터의 상태 s_t와 주어진 목표 g를 기반으로 행동 a_t에 대한 분포를 생성합니다.
-
PD 제어기(Proportional-Derivative Controller): 정책이 제시한 행동이 각 관절에 배치된 PD 제어기의 목표 위치로 작동하여 캐릭터의 움직임을 제어하는 힘을 생성합니다.
-
목표 (Goal) g: 주어진 목표는 보상 함수 r^G로 표현되며, 캐릭터가 만족해야 할 고수준의 목표를 정의합니다. 예를 들어, 목표 방향으로 걷거나 특정 대상을 공격하는 등의 동작이 포함됩니다.
-
스타일 목표 (Style Objective) r^S: 스타일 목표는 생성된 모션과 데이터셋의 모션을 구분하기 위해 학습된 적대적 판별기(adversarial discriminator)에 의해 정의됩니다.
스타일 목표는 태스크에 구애받지 않는 모션 선호 방식으로 작동하여, 특정 작업과 무관하게 자연스럽고 스타일리시한 모션을 유도합니다.
BACKGROUND
Goal-Conditioned Reinforcement Learning과 Generative Adversarial Imitation Learning 기술을 결합하여, 원하는 행동 스타일로 도전적인 작업을 수행하는 캐릭터 제어 정책을 훈련합니다.
Goal-Conditioned Reinforcement Learning
Goal-Conditioned Reinforcement Learning 프레임워크에서, 에이전트는 주어진 목표 g ∈ G를 달성하기 위해 정책 π에 따라 환경과 상호작용하며 훈련됩니다. 목표는 목표 분포 g∼p(g)로부터 샘플링됩니다.
각 시간 단계 t에서 에이전트는 시스템의 상태 s_t ∈ S를 관찰한 후, 정책을 통해 행동 a_t ∈ A를 샘플링합니다:
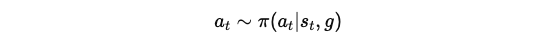
에이전트는 이 행동을 적용하여 새로운 상태 s_t+1를 얻고, 스칼라 보상 r_t = r(s_t, a_t, s_t+1, g)를 받습니다.
에이전트의 목표는 기대 할인된 반환 J(π)을 최대화하는 정책을 학습하는 것입니다.
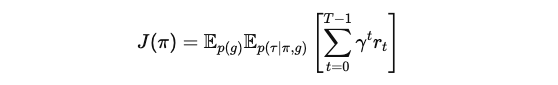
다음은 정책 π 하에서 목표 g에 대한 궤적τ의 확률을 나타냅니다:
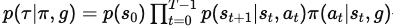
τ={(s_t, a_t, r_t) t=0~T−1, s_T} : 궤적
p(s_0) : 초기 상태 분포
p(s_t+1∣s_t,a_t) : 환경의 동역학
T : 궤적의 시간 범위
γ ∈ [0,1) : 할인 인자
Generative Adversarial Imitation Learning
생성적 적대 모방 학습(GAIL)은 생성적 적대 신경망(GAN)에서 개발된 기법을 모방 학습에 적용한 방법입니다. 설명을 간단히 하기 위해 목표 g를 제외하였지만, 논의는 목표 조건부 설정으로 쉽게 일반화할 수 있습니다.
목표 : 시연자의 행동을 모방하는 정책 π(a∣s)를 훈련
시연 데이터셋 M={(s_i, a_i)}
- s_i : 알 수 없는 시연 정책에서 기록된 상태
- a_i : 행동
행동 복제(Behavioral Cloning)를 통해 지도 학습을 사용하여 상태에서 행동으로 직접 매핑할 수 있지만, 시연 데이터가 적을 경우 드리프트가 발생할 가능성이 큽니다. 또한 행동 복제는 시연 행동을 관찰할 수 없는 상황에서는 적용할 수 없습니다.
GAIL은 정책과 시연 사이의 유사성을 측정하는 목적 함수를 학습한 후, 강화 학습을 통해 목적을 최적화합니다.
이 목적 함수는 판별기 D(s,a)로 모델링되며, 주어진 상태 s와 행동 a가 시연에서 나왔는지 또는 정책에서 생성되었는지 예측하도록 훈련됩니다.
판별기 학습의 목적은 다음과 같습니다:
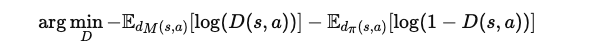
여기서 d_M(s,a)와 d_π(s,a)는 각각 시연 데이터와 정책의 상태-행동 분포를 나타냅니다.
정책은 강화 학습 목표에 따라 훈련되며, 보상은 다음과 같이 정의됩니다:
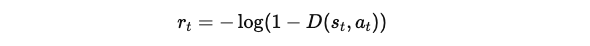
이 적대적 학습 절차는 판별기가 시연과 정책의 상태 및 행동을 구별할 수 없도록 학습하는 것으로 해석될 수 있습니다.
이 목표는 시연 데이터와 정책 간의 젠슨-섀넌 발산(Jensen-Shannon divergence)을 최소화하는 것으로 설명할 수 있습니다.
ADVERSARIAL MOTION PRIOR
이 연구에서는 캐릭터가 수행해야 할 작업과 캐릭터가 작업을 수행하는 방식을 명시하는 두 가지 구성 요소로 구성된 보상 함수를 고려합니다:
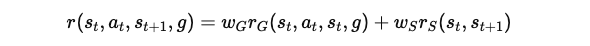
r^G(s_t, a_t, s_t, g) : 캐릭터가 어떤 작업을 수행해야 하는지를 정의하는 작업 관련 보상입니다. 예를 들어, 목표 지점으로 이동하는 것과 같은 높은 수준의 목표를 나타냅니다.
r^S(s_t ,s_t+1) : 캐릭터가 작업을 수행하는 동안 채택해야 하는 행동 스타일을 정의하는 스타일 보상입니다. 예를 들어, 목표 지점으로 달리거나 걷는 방식의 차이를 나타냅니다.
w_G와 w_S는 각각 작업 보상과 스타일 보상의 가중치를 조정하는 변수입니다.
작업 보상은 설계가 비교적 직관적이고 간단할 수 있지만, 스타일 보상을 설계하는 것은 캐릭터가 자연스러운 행동을 학습하도록 하는 데 매우 어렵습니다. 따라서 효과적인 스타일 목표를 학습하는 것이 이 연구의 주요 초점입니다.
-
이 모션 프라이어는 작업과 무관하게 동작의 자연스러움을 평가할 수 있어, 한 번 학습된 모션 프라이어를 여러 작업에 적용할 수 있습니다.
-
이를 통해 작업과 스타일 사양을 분리하여, 캐릭터가 원래 시연에서 나타나지 않은 작업도 수행할 수 있도록 만듭니다.
Imitation from Observations
기존 GAIL은 시연자의 행동을 알아야 학습할 수 있습니다. 하지만 모션 클립 형태의 시연에서는 행동이 아닌 상태만 관찰할 수 있습니다.
이를 해결하기 위해, 판별기는 상태-행동 대신 상태 전이 D(s,s′)에 대해 학습합니다:
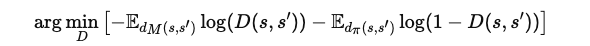
d_M(s,s′) : 데이터셋에서 관찰된 상태 전이의 확률 분포
d_π(s,s′) : 정책을 통해 생성된 상태 전이의 확률 분포를 나타냅니다.
Least-Squares Discriminator
기존의 GAN에서 사용되는 시그모이드 교차 엔트로피 손실 함수는 기울기 소실 문제가 발생할 수 있습니다.
이를 해결하기 위해 최소 제곱 GAN(LSGAN)에서 제안된 손실 함수를 사용합니다:
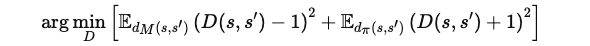
이 손실 함수는 데이터셋에서 샘플링된 전이에는 1, 정책에서 생성된 전이에는 -1의 점수를 예측하도록 판별기를 학습시킵니다.
정책 학습을 위한 보상 함수:
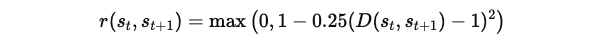
이 보상 함수는 [0,1] 범위로 제한됩니다.
Discriminator Observations
판별기는 정책 학습 시 보상을 제공하므로, 적절한 피처 세트를 선택하여 판별기가 올바른 예측을 할 수 있게 하는 것이 중요합니다.
상태 전이가 판별기의 입력으로 제공되기 전에, 먼저 관찰 맵 Φ(sₜ)을 적용하여 주어진 모션의 특성을 결정하는 데 중요한 피처를 추출합니다. 그런 다음, 추출된 피처들이 판별기의 입력으로 사용됩니다 𝐷(Φ(s), Φ(s′)).
이 피처 세트에는 다음이 포함됩니다:
캐릭터의 루트의 선속도와 각속도는 캐릭터의 로컬 좌표계로 표현됩니다.
- 각 관절의 로컬 회전
- 각 관절의 로컬 속도
- 캐릭터의 로컬 좌표계로 표현된 말단부(손, 발 등)의 3D 위치
여기서 루트(root)는 캐릭터의 골반을 의미합니다. 캐릭터의 로컬 좌표계는 루트가 원점에 위치하고, x축은 루트 링크의 전방 방향, y축은 전역의 상향 벡터와 일치하는 방향으로 정의됩니다.
각 스페리컬 조인트(spherical joint)의 3D 회전은 법선 벡터와 접선 벡터로 표현되며, 이는 특정 회전의 부드럽고 고유한 표현을 제공합니다.
이 관찰 피처 세트는 하나의 상태 전이에서 모션을 컴팩트하게 표현하기 위해 선택되었습니다. 또한, 이 피처들은 작업 관련 특징을 포함하지 않기 때문에, 작업에 특화된 주석 없이 모션 프라이어를 학습할 수 있으며, 동일한 데이터셋으로 학습된 모션 프라이어를 다양한 작업에 적용할 수 있습니다.
Gradient Penalty
GAN에서 판별기와 생성기 간의 상호작용은 종종 불안정한 학습 동작을 초래합니다. 불안정성의 한 가지 원인은 판별기의 함수 근사화 오류로 인해, 실제 데이터 샘플의 manifold 상에서 0이 아닌 그래디언트를 할당하는 경우입니다.
이러한 그래디언트는 생성기가 manifold로 수렴하지 않고 과도한 변화를 일으켜 학습 과정에서 진동과 불안정성을 유발할 수 있습니다. 이를 완화하기 위해, 데이터셋에서 샘플링된 0이 아닌 그래디언트를 페널티로 적용하는 기법을 도입합니다.
그래디언트 페널티를 적용한 판별기 목표 함수는 다음과 같이 정의됩니다:
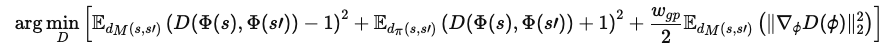
𝑤_{gp} : 수동으로 지정된 계수
Φ(s), Φ(s′) : 관찰 피처들
이 페널티는 전체 상태 피처가 아닌 관찰 피처에 대해 계산됩니다.
실험 결과, 그래디언트 페널티는 안정적인 학습과 효과적인 성능을 위해 필수적임이 확인되었습니다.
MODEL REPRESENTATION
이 섹션에서는 고수준의 작업 목표와 참조 모션 데이터셋을 주어졌을 때, 에이전트가 어떻게 정책을 학습하여 작업 목표를 달성하고, 데이터셋에 있는 모션과 유사한 동작을 수행하는지 설명합니다.

States and Actions
상태 s_t는 캐릭터의 몸 구성을 설명하는 여러 피처들로 구성됩니다. 이 피처들은 Peng et al. [2018a]에서 사용한 것과 유사하며, 루트를 기준으로 각 링크의 상대 위치, 각 링크의 6차원 회전 표현(법선-접선 인코딩), 그리고 각 링크의 선형 속도와 각속도를 포함합니다. 이 모든 피처는 캐릭터의 로컬 좌표계에서 기록됩니다.
기존의 시스템들과는 달리, 본 시스템에서는 추가적인 동기화 정보(예: 위상 변수 또는 목표 자세)를 상태에 포함하지 않으며, 특정 모션을 명시적으로 모방하도록 학습하지 않습니다. 따라서 별도의 동기화 정보가 필요 없습니다.
행동 a_t 는 각 관절에 배치된 PD 컨트롤러의 목표 위치를 지정합니다. 스페리컬 관절의 목표는 3D 지수 맵 q ∈ R3 로 표현되며, 회전 축 v와 회전 각도 θ는 다음과 같이 계산됩니다:
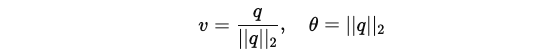
이 표현 방식은 이전 시스템에서 사용한 4D 축-각도 또는 쿼터니언 표현보다 더 컴팩트한 매개변수화를 제공하며, 오일러 각도의 짐볼 락 문제를 피할 수 있습니다. 회전 관절의 목표 회전은 1차원 회전 각도로 q=θ로 지정됩니다.
Network Architecture
각 정책 π는 주어진 상태 s_t 와 목표 g를 입력받아, 행동에 대한 가우시안 분포 π(a_t∣s_t,g)=N(μ(s_t,g),Σ)를 출력하는 신경망으로 모델링됩니다.
여기서 평균 μ(s_t ,g)는 상태와 목표에 따라 달라지고, 공분산 행렬 Σ는 대각 행렬로 고정되어 있습니다.
신경망 구조:
- 은닉층 : 첫 번째 은닉층은 1024개의 뉴런, 두 번째 은닉층은 512개의 뉴런으로 구성되며, 각 층에는 ReLU 활성화 함수가 사용됩니다.
- 출력층 : 선형 출력층을 사용하여 평균값을 출력합니다.
- 공분산 행렬 Σ는 고정된 값으로 훈련 중 변경되지 않습니다.
가치 함수 V(s_t,g)와 판별기 D(s_t,s_t+1)도 정책과 동일한 신경망 구조를 사용합니다.
Training
정책 학습은 GAIL (Generative Adversarial Imitation Learning)과 PPO (Proximal Policy Optimization) 방법을 결합하여 수행됩니다. 학습 과정은 알고리즘 1에 설명된 대로 진행됩니다.
-
매 시간 단계에서 에이전트는 환경으로부터 작업 보상 r^G 와 스타일 보상 r^S를 받습니다.
-
이 두 보상은 결합되어, 최종 보상을 만듭니다.
-
참조 상태 초기화와 조기 종료가 학습에 적용됩니다.
- 참조 상태 초기화는 캐릭터를 데이터셋에서 무작위로 선택된 상태로 초기화하는 방식입니다.
- 조기 종료는 대부분의 작업에서 캐릭터의 몸이 땅에 닿으면 발생하며, 접촉이 많은 작업에서는 비활성화됩니다.
학습 업데이트
-
정책이 수집한 데이터로부터 경로를 기록한 후, 가치 함수와 정책을 업데이트합니다.
-
가치 함수는 TD(λ) 방법을 사용해 업데이트되며, 정책은 GAE(λ)로 계산된 이점을 사용하여 업데이트됩니다.
-
기록된 경로는 리플레이 버퍼 B에 저장되며, 판별기는 참조 모션 데이터셋 M과 리플레이 버퍼 B에서 샘플링된 데이터로 업데이트됩니다.
TASKS
AMP의 효과를 평가하기 위해 다양한 캐릭터와 함께 여러 모션 제어 작업을 수행했습니다. 주요 작업은 다음과 같습니다:
-
목표 방향(Target Heading) : 캐릭터가 주어진 방향 d∗으로 목표 속도 v∗로 이동합니다.
-
목표 위치(Target Location) : 캐릭터가 목표 위치 x∗로 이동하는 과제입니다.
-
드리블(Dribbling) : 캐릭터가 축구공을 목표 위치로 드리블하는 복잡한 작업을 수행합니다.
-
타격(Strike) : 캐릭터가 목표를 향해 타격을 수행하는 작업입니다.
-
장애물 통과(Obstacles) : 장애물이 있는 지형을 통과하면서 목표 속도를 유지하는 과제입니다.
RESULTS
AMP는 다양한 동작 클립이 포함된 대규모 비구조화 데이터셋을 활용하여, 자연스럽고 현실감 있는 동작을 학습할 수 있습니다. AMP는 명시적인 모션 선택 없이도 다양한 기술을 자동으로 조합하여 작업 목표를 달성합니다.
