MoAI: Mixture of All Intelligence for Large Language and Vision Models
Paper : https://arxiv.org/abs/2403.07508
Abstract
대형 언어 모델(LLM)과 명령 조정(instruction tuning)의 발전은 현재 명령 조정된 대형 언어 및 비전 모델(LLVM)의 트렌드를 이끌고 있다. 이 트렌드는 특정 목적에 맞춘 다양한 명령 조정 데이터셋을 정교하게 큐레이팅하거나, 방대한 양의 비전 언어(VL) 데이터를 처리하기 위해 LLVM의 규모를 확대하는 것을 포함한다.
그러나 현재의 LLVM은 분할, 검출, 장면 그래프 생성(SGG), 광학 문자 인식(OCR)과 같은 시각 인식 작업에서 전문적인 컴퓨터 비전(CV) 모델이 제공하는 상세하고 종합적인 실세계 장면 이해를 무시해왔다. 대신 기존 LLVM은 주로 LLM 백본의 큰 용량과 새로운 기능에 의존하고 있다.
따라서 본 논문에서는 새로운 LLVM인 MoAI(Mixture of All Intelligence)를 제안한다. MoAI는 외부 분할, 검출, SGG 및 OCR 모델의 출력을 통해 얻은 보조 시각 정보를 활용한다.
MoAI는 MoAI-Compressor와 MoAI-Mixer라는 두 가지 새 모듈을 통해 작동한다.
-
외부 CV 모델의 출력을 언어로 변환한 후, MoAI-Compressor는 VL 작업에 관련된 보조 시각 정보를 효율적으로 사용하기 위해 이를 정렬하고 압축한다.
-
그 후, MoAI-Mixer는 Mixture of Experts 개념을 활용하여 시각 기능, 외부 CV 모델의 보조 기능, 언어 기능의 세 가지 지능을 혼합한다.
이를 통해 MoAI는 모델 크기를 늘리거나 추가적인 시각 명령 조정 데이터셋을 큐레이팅하지 않고도 객체 존재, 위치, 관계, OCR과 같은 실세계 장면 이해와 관련된 여러 Zero-shot VL 작업에서 오픈소스 및 Closed Source LLVM을 크게 능가한다.
1. Introduction
PaLM 및 T5와 같은 대형 언어 모델(LLM)을 Flan의 명령 조정 데이터셋과 결합하여, Chung et al.은 명령 조정된 LLM인 Flan-PaLM 및 Flan-T5를 개발했다. 이러한 모델은 다양한 작업을 포괄하는 확장된 명령 조정 데이터셋을 활용하여, 많은 언어 작업에서 Zero-shot 성능이 크게 향상되었다.
명령 조정된 LLM의 성공과 함께, 여러 시각 명령 조정 데이터셋이 정교하게 큐레이팅되어 대형 언어 및 비전 모델(LLVM)의 Zero-shot 비전 언어(VL) 성능을 향상시키고자 했다. 또한, LLVM의 제로샷 VL 데이터셋에서 강력한 성능을 목표로 LLVM을 크게 확장하려는 노력이 있었다.
시각 명령 조정 데이터셋의 확장과 LLVM의 확장으로, 오픈소스 LLVM은 GPT-4V, Gemini-Pro, Qwen-VL-Plus와 같은 클로즈드소스 LLVM과의 Zero-shot VL 성능 격차를 좁히고 있다.
그러나 현재의 오픈소스 LLVM은 주로 LLM 백본의 큰 용량과 새로운 기능에 의존하며, 상세하고 종합적인 실세계 장면 이해를 명시적이거나 충분히 활용하지 않았다.
인지과학 및 기계 학습 분야의 여러 연구는 기본적인 장면 인식 능력이 객체 존재 인식, 위치 결정, 상태 식별, 관계 이해, 공간 장면 레이아웃 추출 및 텍스트를 포함한 비객체 개념 이해와 같은 다양한 인지 기능에서 비롯될 수 있음을 주장한다.
다행히도, 이러한 인지 기능은 분할, 검출, 장면 그래프 생성(SGG), 광학 문자 인식(OCR)과 같은 시각 인식 작업을 위해 수십 년 동안 연구되고 개발된 전문 컴퓨터 비전(CV) 모델을 통해 습득할 수 있다.
외부 CV 모델을 활용하여 실세계 장면 이해를 향상시키는 것이 LLVM의 객체 존재, 위치, 관계, 그리고 OCR을 포함한 이해를 강화할 것으로 예상된다.
-
객체와 위치 인식은 범용 분할(panoptic segmentation)과 open-world object detection 모델을 통해 용이하게 할 수 있다.
open-world object detection
: 특정 데이터셋으로 학습된 모델에게 새로운 클래스를 가르쳐주어 탐지할 수 있는 클래스의 종류를 늘리는 모델을 만드는 것
출처 : https://velog.io/@minkyu4506/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-DiffusionDet-Diffusion-Model-for-Object-Detection-%EB%A6%AC%EB%B7%B0 -
더 포괄적인 이해를 위해 객체 상태와 관계(즉, 조합적 추론)를 포함하는 장면 그래프 생성(SGG) 모델이 필요하다.
Scene Graph
: 주어진 장면에 대하여 객체뿐만 아니라, 객체들 간의 관계를 추론하는 방법으로 입력 영상으로부터 인스턴스(Instance)단위 객체를 분류하고, 연결 그래프를 이용하여 관계를 명시적으로 표현한다.
출처 : https://go-hard.tistory.com/8
-
또한, 이미지 내의 텍스트 설명과 같은 비객체 개념은 OCR 모델을 통해 인식할 수 있다.
이러한 점을 고려하여, 다양한 소스에서 보조 시각 정보를 활용하는 새로운 LLVM인 MoAI를 제안한다:
- panoptic segmentation
- open-world object detection
- SGG
- OCR
이 정보를 효과적으로 활용하기 위해 두 가지 새로운 모듈을 도입한다:
- MoAI-Compressor
- MoAI-Mixer.
MoAI-Compressor는 외부 CV 모델의 언어화된 출력을 정렬하고 압축하여 VL 작업에 관련된 정보를 효율적으로 사용할 수 있게 한다.
이후 MoAI-Mixer는 세 가지 지능을 하나의 통합된 형태로 혼합한다.
- 시각 기능
- 외부 CV 모델의 보조 기능
- 언어 기능
MoAI-Mixer를 구성하는 데 있어서 Mixture of Experts(MoE) 개념에서 영감을 받았다. 본 논문의 도전 과제는 MoAI의 멀티모달 언어 모델(MLM)에서 사용하는 원래 기능(즉, 시각 및 언어 기능)을 외부 CV 모델과 MoAI-Compressor에서 얻은 보조 기능과 원활하게 통합하는 것이다.
Cross-attention 및 Self-attention 모듈을 사용하여 여섯 개의 전문가 모듈을 MoAI-Mixer에 구축하며, 여기서 세 가지 지능 유형을 다룬다. 또한, 게이트 네트워크를 활용하여 이러한 전문가 모듈의 최적 조합 가중치를 결정한다.
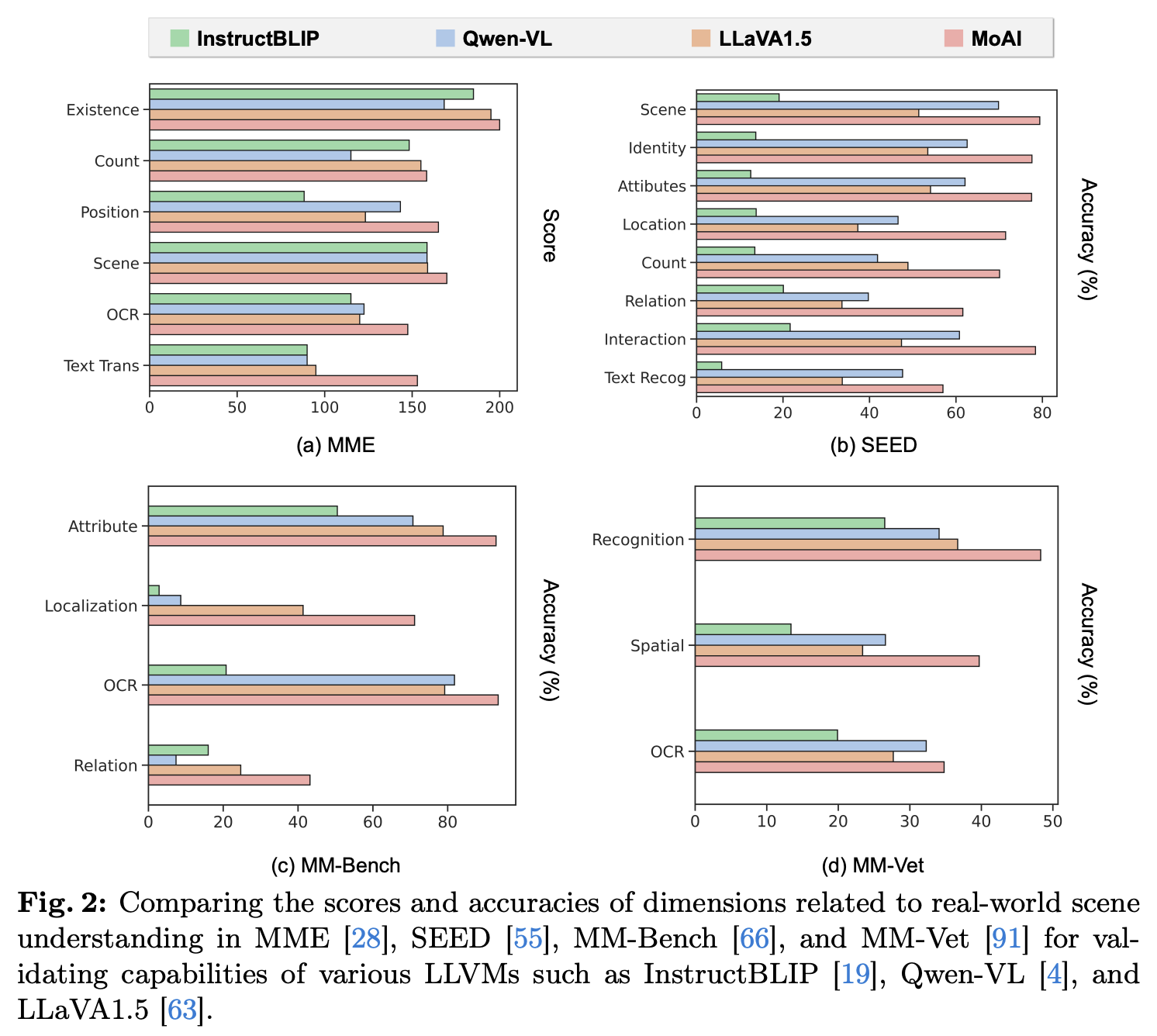
MoAI-Compressor와 MoAI-Mixer를 결합함으로써 MoAI는 외부 CV 모델의 출력을 효과적으로 활용하고 세 가지 지능 소스를 혼합하여 복잡한 질문 응답 작업에 대한 시각 인식 능력을 향상시킨다.
그림 2에서 보여지듯이, 본 논문의 결과는 MoAI가 InstructBLIP, Qwen-VL, LLaVA1.5라는 세 가지 강력한 LLVM 기준 모델을 시각 인식 점수에서 크게 능가했음을 보여준다. 이는 추가적인 시각 명령 조정 데이터셋 큐레이팅이나 LLVM 크기 확장 없이 이루어졌다.
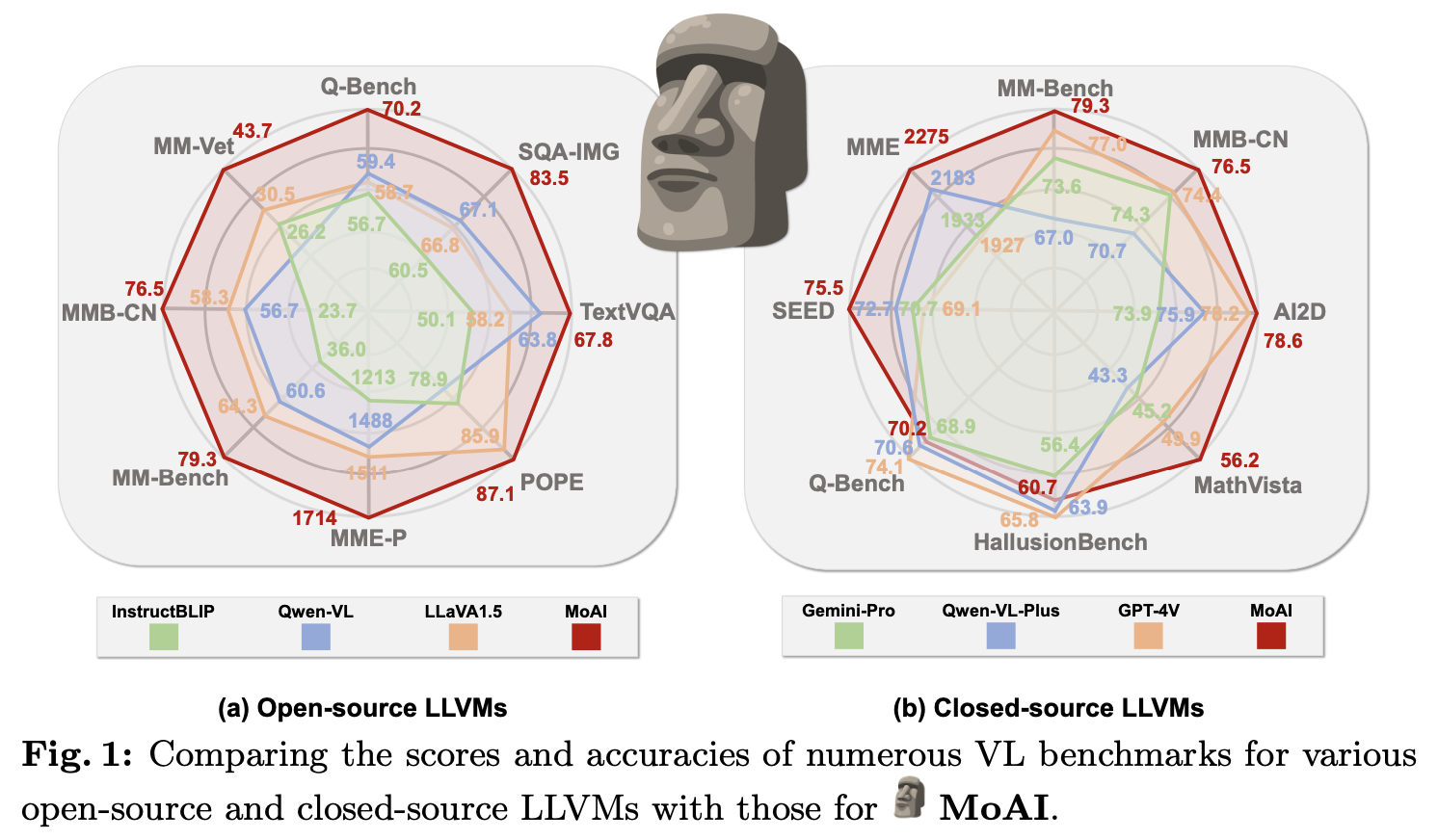
더욱이, 향상된 시각 인식 능력 덕분에 MoAI는 Zero-shot VL 작업에서 강력한 성능을 발휘하며, 이는 그림 1에서 볼 수 있듯이 Closed Source LLVM을 능가한다.
MoAI의 성공은 외부 CV 모델에서 다양한 보조 시각 정보를 활용하고 세 가지 지능 유형을 통합하여 VL 작업을 효과적으로 수행한 덕분이다.
기여는 두 가지 주요 측면으로 요약할 수 있다:
-
MoAI-Compressor를 통해 다양한 외부 CV 모델에서 보조 시각 정보를 처리하고, MoAI-Mixer를 통해 세 가지 지능 유형을 혼합하는 새로운 대형 언어 및 비전 모델, MoAI를 소개한다.
-
MoAI는 뛰어난 시각 인식 능력으로 VL 작업에서 Zero-shot 성능이 뛰어나며, 이는 모델 크기나 데이터셋 크기를 확장할 필요 없이 실세계 장면 이해를 고려한 덕분이다.
2. Related Works
LLMs and LLVMs
대형 언어 모델(LLM)은 그들의 뛰어난 일반화 능력과 instruction tuning 데이터셋의 효과와 함께 등장했다. GPT 시리즈는 다양한 언어 작업에서 강력한 Zero-shot 또는 Few-shot 성능을 보여주며 LLM의 길을 닦았다. 이러한 작업에는 텍스트 분류, 질문 응답, 기계 번역, 복잡한 추론 작업 등이 포함된다.
LLM의 이러한 일반화 능력은 T5, PaLM, OPT와 같은 작업에서 보듯이 모델 용량과 훈련 데이터셋을 크게 늘림으로써 달성되었다. 훈련 방법과 데이터셋의 진보는 대규모 사전 훈련 데이터셋에서 명령 조정 데이터셋으로의 전환을 통해 Zero-shot 일반화를 더욱 향상시켰다.
Instruction tuning은 LLM이 복잡한 실세계 시나리오에서 사람의 자연어 명령을 따를 수 있게 한다. Flan-T5, Flan-PaLM, OPT-IML, InstructGPT와 같은 명령 조정된 LLM은 명령 조정의 효과를 명확히 보여준다.
연구자들은 유사한 전략을 멀티모달 모델인 LLVM에도 적용하여, 시각 인코더와 백본 멀티모달 언어 모델(MLM)로 구성된 모델을 개발하였다.
예를 들어, LLaVA와 ShareGPT4V는 각각 GPT-4와 GPT-4V를 활용하여 시각 명령 조정 데이터셋을 생성하였으며, 다른 연구자들도 다양한 목적을 위해 시각 명령 조정 데이터셋을 개발하였다.
그러나 기존의 LLVM은 지난 수십 년 동안 큰 발전을 이룬 CV 모델에서 얻을 수 있는 상세하고 종합적인 실세계 장면 이해를 간과하였다. CV 모델은 LLVM의 확장된 용량과 시각 명령 조정 데이터셋에 가려졌다. 이러한 관점에서, MoAI는 외부 CV 모델에서 얻은 보조 시각 정보를 활용하는 효과를 강조하며, VL 벤치마크에서 향상된 시각 인식 능력을 보여준다.
Mixture of Experts
Jacobs et al. 는 처음으로 기계 학습에 Mixture of Experts(MoE) 개념을 도입하여, '전문가'라 불리는 별도의 네트워크가 입력 공간의 다른 부분을 처리하고 각 부분이 게이팅 네트워크에 의해 관련 전문가에게 안내되도록 하였다. 이 아이디어는 깊이 쌓인 MoE 레이어와 주어진 입력에 의해 조건적으로 몇몇 전문가만 활성화되는 조건부 계산에 의해 더욱 발전되었다.
현대의 딥러닝에서 Shazeer et al.는 MoE 레이어를 LSTM과 통합하여 게이팅 네트워크가 각각의 토큰을 선택적으로 활성화된 전문가에게 독립적으로 라우팅하도록 하였다. 이 통합은 언어 모델링 및 기계 번역 작업에서 성능을 향상시켰다.
더 나아가, Switch Transformers는 Transformer 레이어 내부의 Dense FFN를 여러 전문가와 게이팅 네트워크로 대체하여 MoE를 Transformer 기반 LLVM에 성공적으로 사용할 수 있는 길을 열었다. 이러한 예로는 MoE-LLaVA가 있다. 딥러닝에서 MoE의 철학은 계산 효율성을 희생하지 않고 모델 용량을 확장하는 것이다.
반면, 본 논문에서는 각 전문가가 특정 입력 세그먼트에 전문성을 갖추도록 설계된 MoE의 다른 중요한 측면에 초점을 맞춘다.
-
이전 MoE 방법은 개별 전문가에게 역할을 명시적으로 할당하지 않고 최적화 과정에서 전문성이 나타나기를 기대하는 반면,
-
MoAI는 전문가로서 교차 주의 및 자기 주의 모듈을 지정하고 이를 명시적으로 학습하여 모달리티 간의 정보를 혼합한다(즉, 시각, 보조, 언어 기능).
구체적으로, MoAI는 다음의 쌍을 촉진한다. 각 쌍은 해당 교차 주의 또는 자기 주의 모듈의 쿼리-키 쌍으로 간주되어 다양한 모달리티 간 정보 융합을 명확히 한다.
- 시각-보조 기능
- 시각-언어 기능
- 시각-시각 기능
- 언어-보조 기능
- 언어-시각 기능
- 언어-언어 기능
3. MoAI: Mixture of All Intelligence
Model Architecture
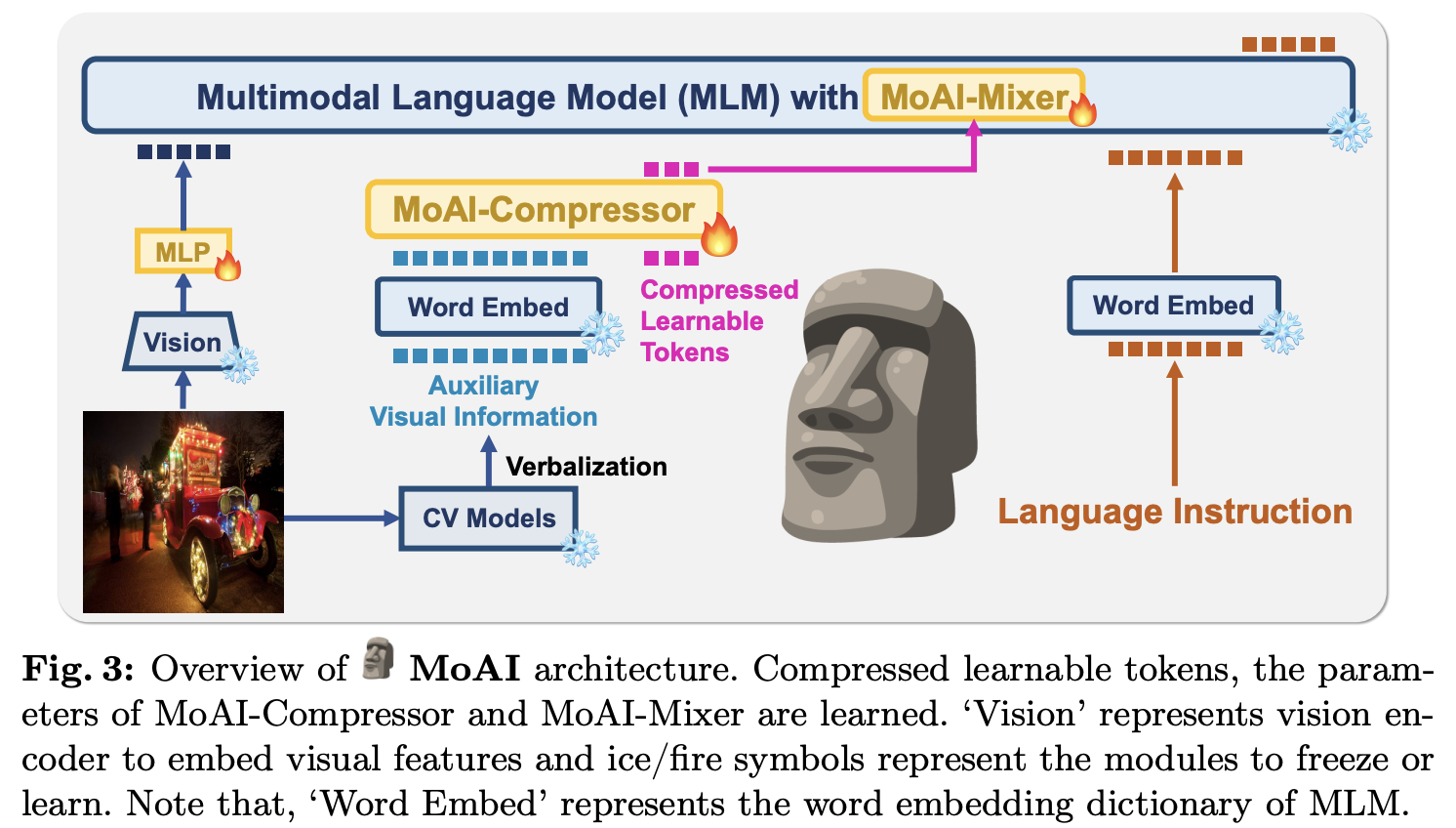
그림 3에 나타난 바와 같이, MoAI는 다음과 같이 구성된다.
-
비전 인코더
-
MoAI-Mixers가 장착된 백본 멀티모달 언어 모델(MLM)
-
비전 인코더와 MLM 사이의 중간 MLP 커넥터
-
범용 분할, 개방형 객체 검출, 장면 그래프 생성(SGG), OCR을 위한 네 개의 외부 컴퓨터 비전(CV) 모델을 활용하는 MoAI-Compressor
Vision and Language Backbone
MoAI의 비전 인코더로는 CLIP-L/14가 선택되었으며, 이는 비전 언어 작업을 위해 텍스트와 일치하는 이미지 이해에 뛰어나다고 보장되기 때문이다.
MoAI에서 사용되는 MLM은 InternLM2-7B를 기반으로 하며, 이는 1.6조 개의 토큰을 포함한 다국어 데이터셋을 통해 진행된 일련의 점진적 사전 훈련 단계와 인간 피드백으로부터 강화 학습(RLHF)을 통해 명령 조정된 다국어 기초 모델이다.
두 개의 GELU 활성화 함수를 가진 선형 계층이 비전과 언어 구성 요소 간의 연결 역할을 하며, 이는 그림 3에서 'MLP'로 표시된다.
Verbalization

멀티모달 언어 모델(MLM)이 MoAI를 구성하기 위해 채택되었으므로, CV 모델 출력을 자연어 형식으로 변환하여 MLM이 이해할 수 있도록 하는 과정인 언어화가 필요하다.
그림 4는 네 개의 CV 모델 출력이 언어화되는 과정과 MLM에 의미적으로 일치하는 보조 토큰을 생성하는 과정을 보여준다.
Panoptic segmentation model
범용 분할 모델은 이미지에서 전경과 배경 객체를 동시에 구별할 수 있게 해준다. 또한, 세그멘테이션 맵으로부터 경계 상자 좌표(예: [xmin, ymin, xmax, ymax])를 계산할 수 있다.
따라서 범용 분할(PS)의 출력을 언어화하는 것은 경계 상자 좌표와 객체 이름을 직렬화하는 것을 포함한다. 이러한 언어화된 설명은 MLM의 단어 임베딩을 통해 보조 토큰으로 변환된다.
추가적으로, PS map을 직접 활용하기 위해, MoAI에서는 비전 인코더와 MLP 커넥터를 사용하여 지역성을 보존하는 보조 토큰을 생성한다. 생성된 보조 토큰은 평탄화되어 직렬화된 경계 상자와 그 객체 이름으로부터 나온 토큰과 연결되어 최종 PS 보조 토큰 APS를 형성한다.
이들은 이러한 방식으로 연결되어 MoAI의 MLM이 문맥화를 통해 이를 호환 가능한 방식으로 연결할 수 있도록 한다. 이 절차는 PS로부터 시각 정보를 언어 정보로 포괄적으로 변환하면서 범용 분할 맵에 내재된 공간적 지역성을 보존하도록 보장한다.
범용 분할 모델이 MS-COCO 2017에서 133개의 객체 범주를 포함한 고정된 수의 범주 내에서 객체를 분류하지 못할 경우, 알 수 없는 클래스가 할당된다.
Open-world object detection model
개방형 객체 검출 모델은 PS 모델이 놓친 객체 클래스를 검출하는 역할을 한다. 이는 범용 분할 모델이 특정 데이터셋으로 훈련되어 고정된 수의 객체 범주를 가지고 있기 때문이다.
이미지에 대한 검출 결과가 생성되면, 경계 상자 좌표와 객체 이름이 다음 템플릿 형식에 따라 언어화된다:
- '이미지에는 경계 상자와 그 객체가 포함되어 있습니다 : {언어화된 개방형 객체 검출(OWOD) 결과}'.
그런 다음 결과는 MLM의 단어 임베딩에 의해 OWOD 보조 토큰 AOWOD로 변환된다.
마찬가지로, SGG 및 OCR 모델의 출력도 언어화되며, 해당 보조 토큰 ASGG 및 AOCR이 생성된다.
이를 위해 다음 언어화 템플릿을 사용한다:
-
'이미지에는 객체 간의 관계가 포함되어 있습니다: {언어화된 SGG 결과}'
-
'이미지에는 텍스트 설명이 포함되어 있습니다: {언어화된 OCR 결과}'.
MoAI-Compressor
CV 모델 출력이 언어화된 후, 네 개의 보조 토큰 APS, AOWOD, ASGG, AOCR이 생성되어 MoAI-Compressor에 입력된다.
MoAI-Compressor는 Perceiver Resampler의 구조를 빌려왔다. 모든 보조 토큰 [APS, AOWOD, ASGG, AOCR]은 고정된 수의 학습 가능한 토큰 Ainput과 함께 MoAI-Compressor에 입력되기 전에 연결된다.
MoAI-Compressor의 출력 A는 동일한 수의 고정된 길이로 압축되고 정렬된 보조 시각 정보를 나타낸다. 이는 다음과 같이 공식화된다:
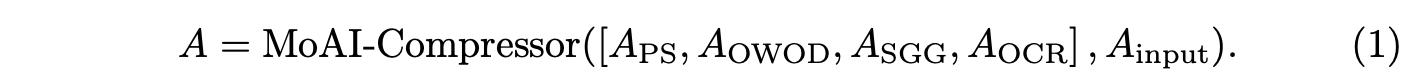
이미지마다 연결된 보조 토큰의 길이가 다르고, 연결 후 상당한 길이를 가지므로, MoAI-Compressor는 이러한 토큰들을 상대적으로 작은 고정 크기 64로 압축하도록 설계되었다.
결과적으로 A ∈ R^{d×64}로 생성되며, 여기서 d는 임베딩 차원을 나타낸다. 이 압축된 토큰들은 MoAI-Mixer에 의해 VL 작업에 필요한 관련 정보를 추출하는 데 사용된다. 이 압축 과정은 계산 효율성을 향상시킨다.
MoAI-Mixer
MoAI-Mixer는 MoAI의 각 MLM 계층에 포함된다. 이는 MoAI-Compressor로부터 보조 토큰 A, 시각 특징 I^(l) ∈ R^{d×N_I}, 그리고 언어 특징 L^(l) ∈ R^{d×N_L}를 받는다.
l = 0, 1, ..., N-1 : 계층 인덱스
d : 임베딩 차원
N_I : 시각 특징의 길이
N_L : 언어 특징의 길이
일반적으로 MLM 계층은 Transformer 디코더 블록 TransDec^(l)로만 구성되며, 이는 다음과 같이 표현된다:
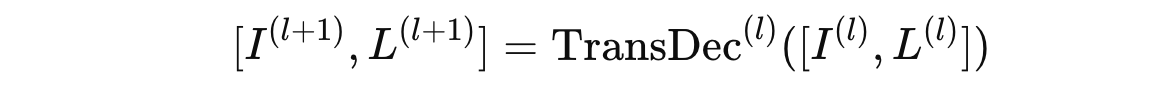
MoAI에서는, MoAI-Mixer가 포함된 l번째 MLM 계층이 다음과 같이 공식화된다:
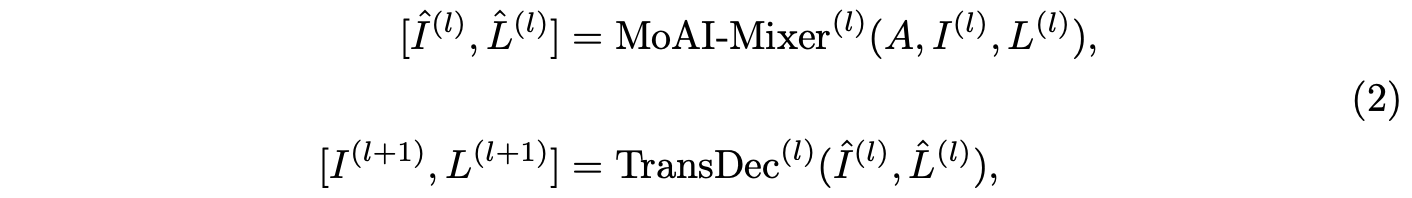
여기서 I^(l)와 L^(l)는 혼합된 시각 특징과 혼합된 언어 특징을 나타낸다. 각 MoAI-Mixer에는 시각 특징 I와 언어 특징 L을 위한 Cross 및 Self Attention 모듈로 구성된 여섯 개의 Expert 모듈이 설계되어 있다.
시각 특징을 위한 세 개의 전문가 모듈은 각각 I_AUX, I_LANG, I_SELF를 출력하며, 여기서 대문자는 쿼리 특징을, 하위 첨자는 키/값 특징을 나타낸다.
마찬가지로, 언어 특징을 위한 세 개의 전문가 모듈은 각각 LAUX, LIMG, LSELF를 출력한다. l번째 계층에서의 Cross Attention 연산은 다음과 같이 공식화된다:
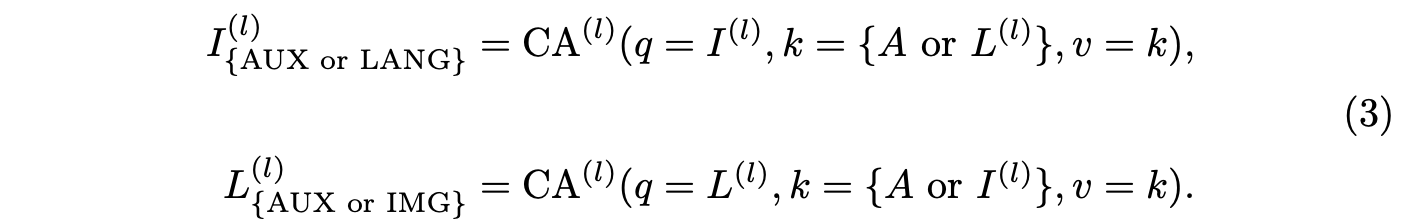
또한, Self Attention 연산은 I_SELF^(l)=SA^(l)(I^(l))와 L_SELF^(l)=SA^(l)(L^(l))로 공식화된다.
이 여섯 개의 Expert 모듈은 각각 다음 여섯 가지 지능 혼합 중 하나에 명확히 특화된다:
- I_AUX
- I_LANG
- I_SELF
- L_AUX
- L_IMG
- L_SELF
Expert 모듈을 훈련할 때, 계산 부담을 줄이기 위해 LoRA 개념을 차용한다. Multi Head Attention 모듈에서 Linear Projection 계층을 일반적으로 나타내는 W를 Wq, Wk, Wv 또는 Wo로 표시하지 않고 두 개의 Linear layer WA와 WB로 분해한다. W는 WAWB로 공식화된다.
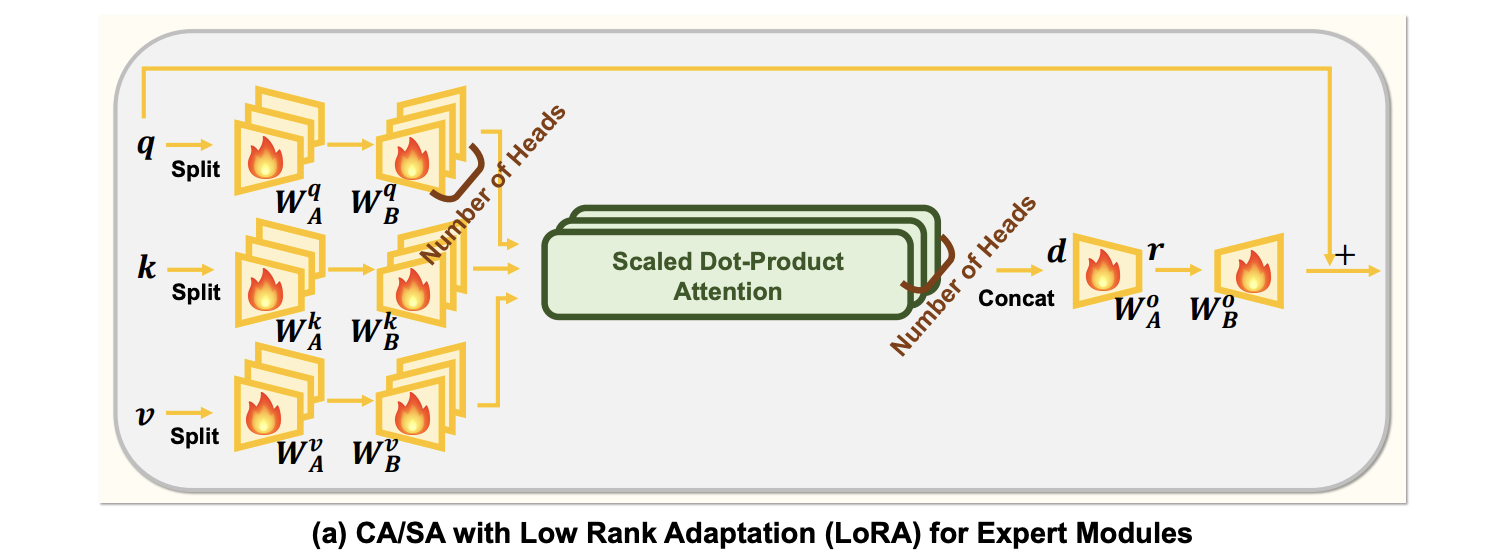
하이퍼파라미터 r은 축소된 차원을 나타내며, 이는 그림 6(a)에 나타나 있다. 주의 모듈의 계산 부담은 주로 높은 임베딩 차원에서 발생하므로, Projection Matrix의 이러한 공식화는 계산을 크게 줄인다.
또한, 입력 쿼리 특징은 출력 특징에 직접 추가되어 지능 혼합이 이전 MLM 계층의 출력을 크게 변경하지 않고 발생하도록 하여, 동결된 Transformer 디코더 블록으로 최적화 과정을 안정화시킨다.
First Training Step
첫 번째 단계에서는 MLP 커넥터와 함께 Ainput, MoAI-Compressor, 및 MoAI-Mixer를 시각적 지침 튜닝 데이터셋을 사용하여 훈련한다.
이 단계의 목적은 MoAI-Mixer의 여섯 개 전문가 모듈이 VL 작업을 수행하기에 적합한 의미 있는 특징을 생성하도록 하는 것이다.
이를 위해, 다음과 같이 세 개의 전문가 모듈 중 하나에서 무작위로 출력을 선택한다:
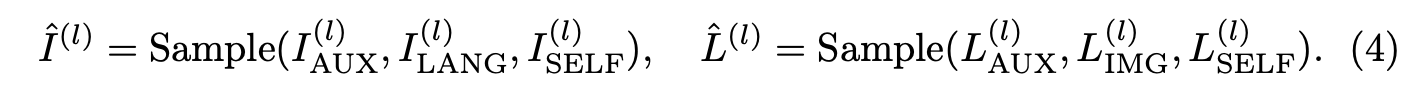
이후, 선택된 출력들이 Transformer 디코더 블록 TransDec(l)로 입력된다. 이 샘플링 과정은 각 전문가 모듈이 독립적으로 의미 있는 특징을 생성하도록 하는 것이 목적이다.
Second Training Step
두 번째 단계에서는 첫 번째 훈련 단계에서 학습된 파라미터를 넘어서 학습을 확장한다. 이 단계에서는 MoAI-Mixer의 각 모듈에 대해 두 개의 게이팅 네트워크를 학습한다.
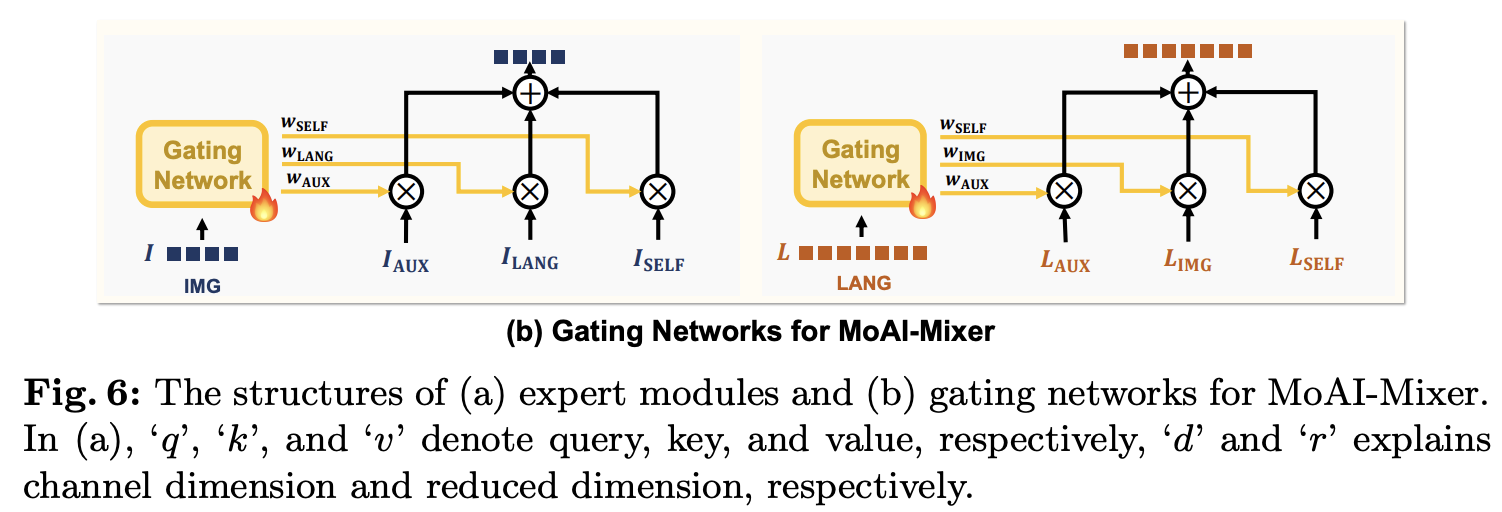
각각의 게이팅 네트워크는 시각적 및 언어적 특징을 위한 단일 선형 계층으로 구성된다:
- W_Gating I 및 W_Gating L ∈ R^(d×3), 그림 6(b) 참조.
게이팅 네트워크의 목적은 Linear layer 소프트맥스 함수를 사용하여 시각적 및 언어적 특징에 대한 세 개의 Expert 모듈의 최적 조합 가중치를 출력하는 것이다. 이 과정은 다음과 같이 표현된다:
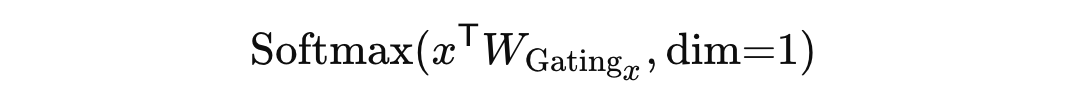
x ∈ R^{d×N_x}
x : 시각적 특징 I 또는 언어적 특징 L을 의미
N_x : 특징의 길이
결과적으로 x^T W_{Gating_x} ∈ R^{N_x × 3}가 된다.
이후, 소프트맥스 행렬을 세 개의 가중치 벡터로 분할한다:
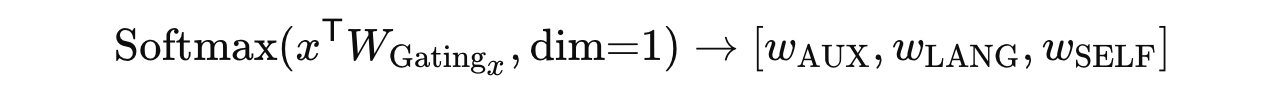
각 가중치는 R^N_x차원을 가지며, 각 전문가 모듈에서 정보를 사용할지를 결정하는 신뢰도 점수 역할을 한다.
게이팅 네트워크의 출력으로, 세 가지 지능 소스인 ‘AUX’, ‘IMG’, ‘LANG’의 전파 흐름은 다음과 같이 표현된다:
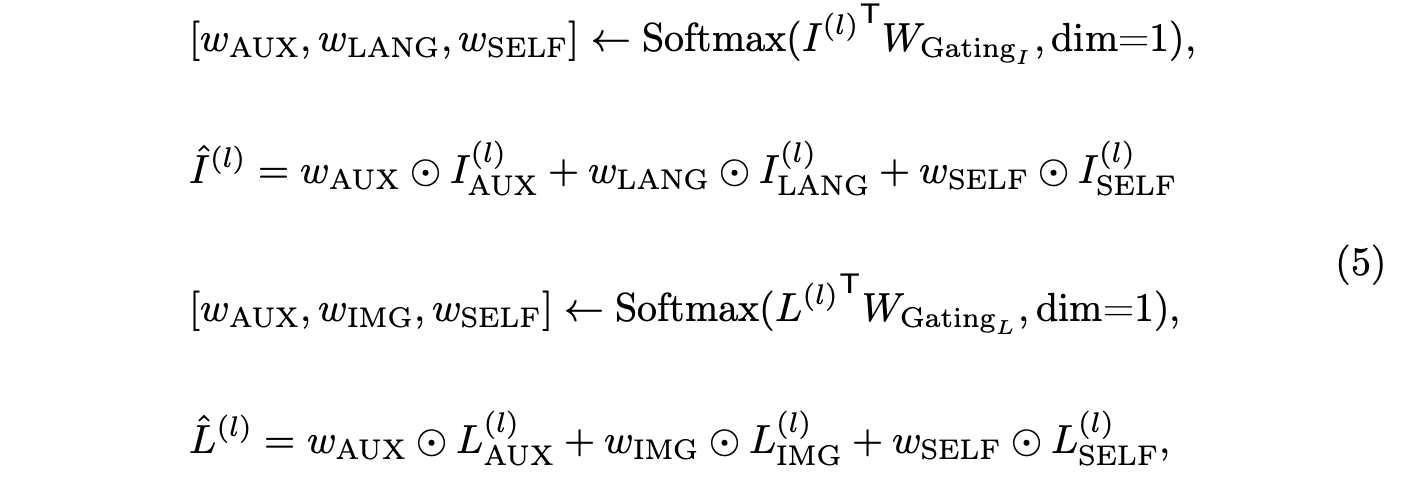
여기서 ⊙는 각 토큰의 요소별 곱을 나타낸다. 시각적 및 언어적 특징에 대한 게이팅 네트워크는 파라미터를 공유하지 않고 독립적으로 훈련되며, 이는 두 게이팅 네트워크가 세 가지 지능을 서로 다른 가중치로 혼합하도록 한다.
이러한 방식으로 MoAI-Mixer와 게이팅 네트워크는 세 가지 지능 소스 간의 상호작용을 촉진한다.
