Audio Deepfake Detection : A Survey
Paper : https://arxiv.org/abs/2308.14970
2. 개요
오디오 딥페이크 탐지 분야는 딥페이크 기술, 대회, 데이터셋, 평가 지표 및 탐지 방법 측면에서 활발히 발전하고 있다.
2.1 딥페이크 오디오의 종류
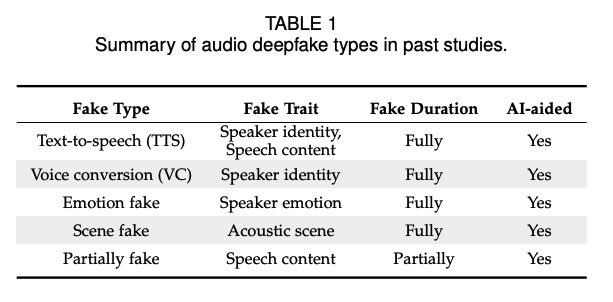
딥페이크 오디오는 AI 기술을 통해 중요한 속성이 조작되었지만, 여전히 자연스러움을 유지하는 모든 오디오를 일반적으로 의미한다.
2.1.1 텍스트-음성 변환
텍스트-음성 변환(TTS)은 음성 합성으로 잘 알려져 있으며, 그림 2 (a)에 표시된 바와 같이 임의의 텍스트를 주어 이해 가능하고 자연스러운 음성을 합성하는 것을 목표로 한다. TTS 모델은 심층 신경망의 발전으로 현실적이고 인간 같은 음성을 생성할 수 있다. TTS 시스템은 주로 텍스트 분석 및 음성 파형 생성 모듈로 구성된다.
음성 파형 생성에는 두 가지 주요 방법이 있다:
- concatenative
- statistical parametric TTS
후자는 종종 음향 모델과 보코더로 구성된다. 가장 최근에는 고품질의 음성을 생성하기 위해 Variational
Inference with adversarial learning을 사용하는 엔드-투-엔드 모델이 제안되었다. 예로는 VITS와 FastDiff-TTS가 있다.
2.1.2 음성 변환
음성 변환(VC)은 그림 2 (b)와 같이 디지털로 사람의 목소리를 복제하는 것을 의미한다. 이는 주어진 화자의 음성의 음색과 억양을 다른 화자의 것으로 바꾸는 것을 목표로 하며, 음성의 내용은 동일하게 유지된다. VC 시스템의 입력은 주어진 화자의 자연 발화다.
VC 기술에는 주로 세 가지 주요 접근 방식이 있다:
- statistical parametric
- frequency warping
- unit-selection
통계적 파라메트릭 모델에는 통계적 파라메트릭 TTS와 유사한 보코더가 포함된다. 최근에는 사람의 목소리 특성을 모방하기 위해 엔드-투-엔드 VC 모델도 제안되었다.
2.1.3 감정 페이크
감정 페이크는 음성의 다른 정보는 그대로 유지하면서 감정만을 변경하는 것을 목표로 한다. 예를 들어, 그림 2 (c)에 나와 있는 바와 같이, 화자 B가 행복한 감정으로 말한 원래 발화를 슬픈 감정으로 변경한 것이다. 감정 변환 방법은 평행 데이터 기반 및 비평행 데이터 기반 방법으로 나뉜다.
2.1.4 장면 페이크
장면 페이크는 원래 발화의 음향 장면을 다른 장면으로 변경하는 것을 포함하며, 이는 화자 신원 및 음성 내용을 변경하지 않는다. 예를 들어, 그림 2 (d)에 나와 있는 바와 같이, 실제 발화의 음향 장면이 "사무실"이고, 가짜 발화의 음향 장면이 "공항"인 경우다. 원래 오디오의 장면이 다른 것으로 조작되면, 오디오의 진위성 및 무결성 검증이 신뢰할 수 없게 되고, 원래 오디오의 의미조차 변경될 수 있다.
2.1.5 부분적 페이크
부분적 페이크는 발화 중 일부 단어만을 변경하는 것에 중점을 둔다. 가짜 발화는 원래 발화를 진짜 또는 합성된 오디오 클립으로 조작하여 생성된다. 원래 발화와 가짜 클립의 화자는 동일한 사람이다. 합성된 오디오 클립은 화자 신원을 변경하지 않는다. 예를 들어, 그림 2 (e)에 나와 있다.
다양한 딥페이크 오디오 유형의 특징
| 유형 | 설명 |
|---|---|
| 텍스트-음성 변환 | 임의의 텍스트를 자연스러운 음성으로 합성 |
| 음성 변환 | 한 화자의 음성을 다른 화자의 음성으로 변경 |
| 감정 페이크 | 음성의 감정을 변경 |
| 장면 페이크 | 발화의 음향 장면을 변경 |
| 부분적 페이크 | 발화 중 일부 단어만 변경 |
2.2 대회
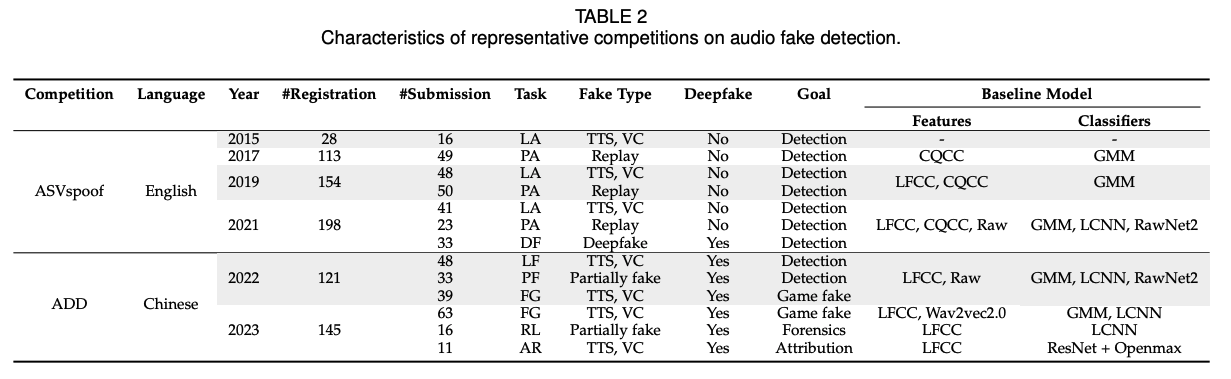
최근 몇 년 동안, 일련의 대회들이 오디오 딥페이크 탐지의 발전을 가속화하는 데 중요한 역할을 했다. 대표적인 대회로는 ASVspoof 및 ADD 챌린지가 있다.
ASVspoof 챌린지는 주로 ASV 시스템을 공격으로부터 보호하기 위해 스푸핑된 오디오를 탐지하는 데 중점을 둔다. ASVspoof 2015는 합성 및 변환된 발화를 탐지하는 논리 접근(LA) 작업을 포함한다. ASVspoof 2017은 리플레이 공격을 포함하는 물리 접근(PA) 작업만 포함하고 있다. ASVspoof 2019은 이전 두 챌린지에서 포함된 LA와 PA 작업을 모두 포함한다. ASVspoof 2021에는 LA, PA 및 음성 딥페이크(DF) 작업이 포함되어 있다. DF 작업은 LA 작업과 유사한 압축된 오디오를 포함한다.
ADD 2022 챌린지는 저품질 가짜 오디오 탐지(LF), 부분적 가짜 오디오 탐지(PF) 및 오디오 가짜 게임(FG) 작업을 포함하여 조직되었다. LF 작업은 다양한 실제 소음 및 간섭을 포함하는 진짜와 완전히 가짜 발화를 다루는 데 중점을 둔다. PF 작업은 부분적으로 가짜와 실제 오디오를 구별하는 것을 목표로 한다. FG 작업은 오디오 생성 작업과 오디오 가짜 탐지 작업을 포함하는 경쟁 게임으로, 생성 작업 참가자들은 탐지 시스템을 속일 수 있는 오디오를 생성하는 것을 목표로 한다.
ADD 2022의 결과는 모든 가짜 유형을 다루기 위해 동일한 모델을 사용하는 것이 어렵다는 것을 보여준다. 결과는 또한 탐지 기술의 일반화가 여전히 미해결 문제임을 보여준다. 이전 챌린지와 달리, ADD 2023은 단순한 진짜 또는 가짜 분류의 한계를 넘어서 부분적으로 가짜 발화의 조작된 구간을 실제로 찾아내고, 가짜 오디오를 생성한 소스를 정확히 지정하는 데 중점을 둔다. ADD 2023 챌린지는 오디오 가짜 게임(FG), 조작 구간 위치 파악(RL) 및 딥페이크 알고리즘 인식(AR) 세 가지 하위 챌린지를 포함한다.
대표적인 오디오 딥페이크 탐지 대회
| 대회 | 주요 작업 |
|---|---|
| ASVspoof 2015 | 논리 접근(LA): 합성 및 변환된 발화 탐지 |
| ASVspoof 2017 | 물리 접근(PA): 리플레이 공격 포함 |
| ASVspoof 2019 | 논리 접근(LA), 물리 접근(PA) |
| ASVspoof 2021 | 논리 접근(LA), 물리 접근(PA), 음성 딥페이크(DF) |
| ADD 2022 | 저품질 가짜 오디오 탐지(LF), 부분적 가짜 오디오 탐지(PF), 오디오 가짜 게임(FG) |
| ADD 2023 | 오디오 가짜 게임(FG), 조작 구간 위치 파악(RL), 딥페이크 알고리즘 인식(AR) |
2.3 벤치마크 데이터셋
오디오 딥페이크 탐지 기술의 발전은 다양한 가짜 유형과 다양한 음향 조건을 갖춘 잘 확립된 데이터셋에 크게 의존해 왔다. 다양한 데이터셋이 ASV 시스템 또는 인간 청취자를 스푸핑이나 기만으로부터 보호하기 위해 설계되었다. 표 3은 오디오 딥페이크 탐지에 대한 대표적인 데이터셋의 특성을 강조한다.
많은 초기 연구들은 ASV 시스템을 위한 스푸핑 대응책을 개발하기 위해 스푸핑된 데이터셋을 설계했다. 초기에는 특정 연구에서 가정한 특정 스푸핑 접근 방식에 크게 의존하는 데이터셋의 설계로 인해 다양한 스푸핑 데이터셋이 독점적이었다.
대표적인 오디오 딥페이크 탐지 데이터셋
| 데이터셋 | 특성 |
|---|---|
| ASVspoof 데이터셋 | 다양한 스푸핑 공격(논리 접근, 물리 접근, 딥페이크 등)을 포함한 대규모 데이터셋 |
| ADD 데이터셋 | 저품질 가짜 오디오, 부분적 가짜 오디오, 다양한 실제 소음 및 간섭을 포함한 다양한 데이터셋 |
| SAS | 다양한 TTS 및 VC 방법을 포함하며, ASVspoof 2015 챌린지를 지원하기 위해 개발됨 |
| PhoneSpoof | 전화 채널에서 수집된 발화를 포함하며, 화자 검증 시스템을 위한 데이터셋 |
| 부분적 스푸핑 데이터베이스 | 음성 활동 탐지 기술을 사용하여 스푸핑된 발화를 무작위로 연결하여 생성됨 |
| FoR | 오픈 소스 TTS 도구로 생성된 합성 발화를 포함하는 공개 데이터셋 |
| WaveFake | 최신 TTS 모델로 합성된 두 명의 화자의 가짜 발화를 포함하는 가짜 오디오 데이터셋 |
| FMFCC-A | 노이즈 추가 및 오디오 압축을 포함한 13가지 종류의 가짜 오디오를 포함하는 중국어 합성 음성 탐지 데이터셋 |
| EmoFake | 화자의 원래 감정이 다른 감정으로 조작된 감정 가짜 오디오 탐지 데이터셋 |
| SceneFake | 원래 발화의 음향 장면이 다른 장면으로 대체된 장면 조작 오디오 데이터셋 |
| In-the-Wild | 사회 네트워크 및 비디오 공유 플랫폼에서 수집된 실제 세계 데이터셋으로, 유명 인사 및 정치인의 발화를 포함 |
이와 같이, 다양한 오디오 딥페이크 탐지 대회와 데이터셋은 이 분야의 연구 및 개발에 중요한 자원을 제공하고 있다.
일부 스푸핑 데이터셋은 특정 TTS 방법 또는 VC 접근 방식만 포함하도록 설계되었다. 그러나 다양한 스푸핑 방법 간의 비교는 어렵다. 이러한 문제를 해결하기 위해, 재생, TTS 및 VC 기술을 포함하는 여러 접근 방식을 포함한 스푸핑 데이터셋을 설계했다. 그러나 일반화된 대응 연구에서 요구되는 다양성에 비해 여전히 스푸핑 기술의 다양성은 충분하지 않다.
반복 가능하고 비교 가능한 스푸핑 탐지 연구를 수행하기 위해, 2015년에 다양한 TTS 및 VC 방법을 포함하는 표준 공개 스푸핑 데이터셋 SAS를 개발했다. SAS 데이터셋은 스푸핑된 음성을 탐지하기 위한 첫 번째 ASVspoof 챌린지 (ASVspoof 2015)를 지원하기 위해 사용되었다.
재생은 ASVspoof 2017 챌린지에 포함된 저비용 및 도전적인 공격으로 간주된다. ASVspoof 2019 및 2021 데이터셋에는 모두 재생, TTS 및 VC 공격이 포함된다. 이전 ASVspoof 챌린지 데이터셋은 마이크로폰 채널에서의 음성 공격 탐지에 중점을 두고 있다. 전화 채널에서 수집된 발화를 포함하는 PhoneSpoof 데이터셋을 설계되었다. 부분적으로 스푸핑된 데이터베이스는 음성 활동 탐지 기술을 사용하여 스푸핑된 발화를 무작위로 연결하여 설계되었다.
몇몇 오디오 딥페이크 탐지 데이터셋은 딥페이크 오디오로부터 사람들을 보호하기 위해 개발되었다. 데이터셋에 포함된 딥페이크 유형은 주로 TTS, VC, 감정 가짜, 장면 가짜 및 부분 가짜다. 2020년, 공개적으로 사용할 수 있는 데이터셋 FoR를 개발되었으며, 이는 오픈 소스 TTS 도구로 생성된 합성 발화를 포함한다. 비공개 가짜 데이터셋은 오픈 소스 VC 및 TTS 시스템을 사용하여 구성되었다.
2021년, 최신 TTS 모델에 의해 합성된 두 명의 화자의 가짜 발화를 포함하는 WaveFake라는 가짜 오디오 데이터셋을 개발되었다. ASVspoof 2021에는 데이터 압축 효과를 고려한 오디오 딥페이크 공격이 포함되었다. 그러나 이러한 데이터셋은 일부 실제 생활의 도전적인 상황을 포괄하지 못했다. ADD 2022 챌린지의 데이터셋은 이러한 간극을 메우기 위해 설계되었다.
LF 데이터셋의 가짜 발화는 다양한 노이즈 간섭을 포함하는 최신 TTS 및 VC 모델을 사용하여 생성되었다. PF 데이터셋의 가짜 발화는 HAD 데이터셋에서 선택되었으며, 이는 몇몇 핵심 단어의 실제 또는 합성된 오디오 세그먼트로 원래의 진짜 발화를 조작하여 생성되었다. FG 트랙(FG-D)의 탐지 작업 데이터셋은 ADD 2022 생성 작업의 제출된 발화에서 무작위로 선택되었다. 중국어 합성 음성 탐지 데이터셋 FMFCC-A는 노이즈 추가 및 오디오 압축을 포함한 13가지 종류의 가짜 오디오를 포함한다.
앞서 언급한 데이터셋은 오디오 딥페이크 탐지의 발전을 가속화하는 데 중요한 역할을 했다. 그러나 가짜 발화는 주로 원래 오디오의 화자 정체성, 음성 내용 또는 채널 노이즈를 변경하는 것을 포함한다. 가장 최근에는 화자의 원래 감정이 다른 감정으로 조작된 감정 가짜 오디오 탐지 데이터셋 EmoFake를 설계했으며, 다른 정보는 그대로 유지된다.
원래 발화의 음향 장면이 음성 향상 기술을 사용하여 다른 장면으로 대체된 장면 조작 오디오 데이터셋 SceneFake를 구축되었다. 2022년에는 사회 네트워크 및 인기 있는 비디오 공유 플랫폼과 같은 공개적으로 사용 가능한 소스에서 수집된 실제 세계 데이터셋 In-the-Wild가 수집되었다. 이 데이터셋의 발화는 영어를 사용하는 유명 인사 및 정치인으로부터 수집되었다.
2.4 평가 지표
이전에는 ASVspoof 및 ADD 챌린지에서 오디오 딥페이크 탐지 작업의 평가 지표로 등오율(EER)을 사용했다. '임계값 없는' EER은 다음과 같이 정의된다. Pfa(θ)와 Pmiss(θ)는 각각 임계값 θ에서의 오탐률 및 미탐률을 나타낸다.

따라서 Pfa(θ)와 Pmiss(θ)는 각각 θ의 함수로 단조 감소 및 단조 증가 함수다. EER은 두 탐지 오류율이 동일한 임계값 θEER에서의 오류율에 해당하며, EER = Pfa(θEER) = Pmiss(θEER)다.
ADD 챌린지의 오디오 가짜 게임 트랙의 탐지 작업에는 두 번의 평가가 있으며, 각 라운드 평가는 각각의 EER에 따라 순위가 매겨진다. 최종 순위는 가중치 EER(WEER)을 기준으로 한다.
가중치 EER(WEER)은 다음과 같이 정의된다:
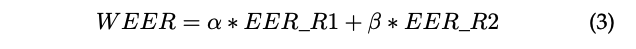
여기서 α와 β는 각각의 EER에 대한 가중치이며, EER{R1}과 EER{R2}는 오디오 가짜 게임 트랙의 탐지 작업에서 첫 번째와 두 번째 라운드 평가의 EER다.
오디오 딥페이크 탐지의 평가 지표
| 평가 지표 | 정의 |
|---|---|
| EER | Pfa(θ)와 Pmiss(θ)가 동일한 임계값 θEER에서의 오류율 |
| WEER | 각 라운드 평가의 가중치 EER |
이와 같이, 다양한 오디오 딥페이크 탐지 데이터셋과 평가 지표는 이 분야의 연구 및 개발에 중요한 자원을 제공하고 있다. 특히, 다양한 스푸핑 기술과 평가 방법을 통해 탐지 기술의 일반화 및 정확도를 높이는 데 기여하고 있다.
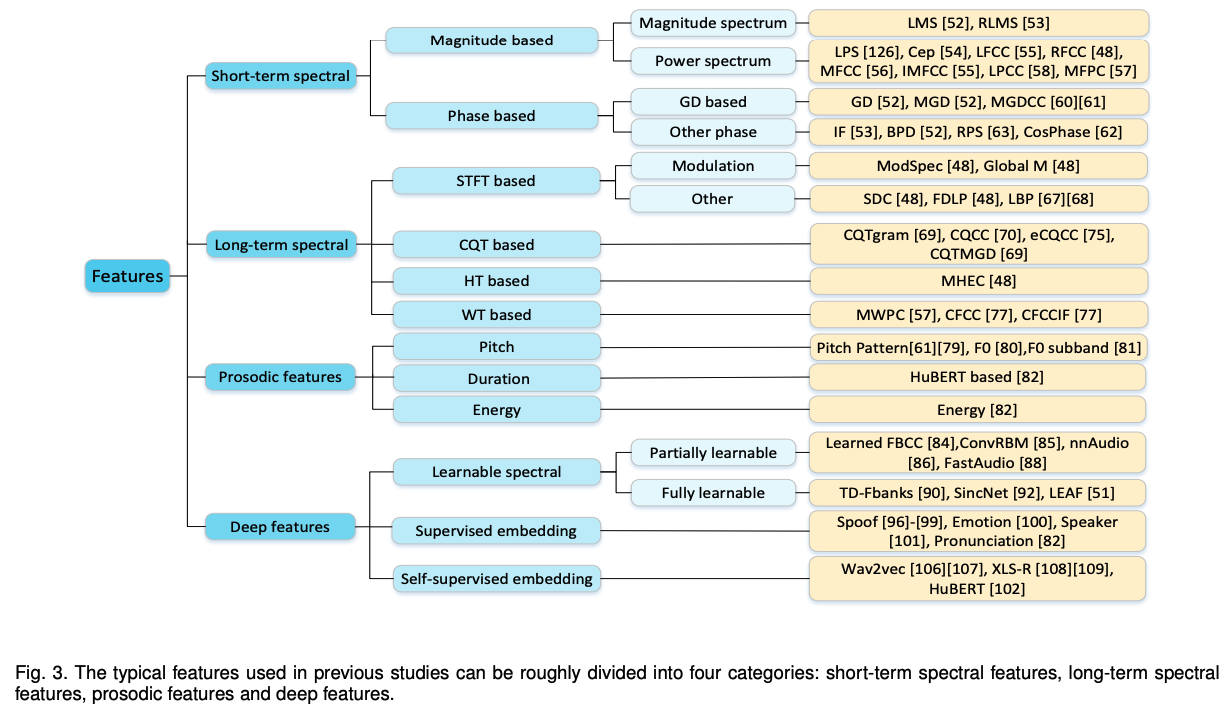
3. 판별적 특징
특징 추출은 파이프라인 탐지기의 핵심 모듈이다. 특징 추출의 목표는 음성 신호에서 오디오 가짜 인공물을 포착하여 판별적 특징을 학습하는 것이다. 많은 연구는 가짜 공격을 탐지하기 위한 유용한 특징의 중요성을 보여주었다.
이전 연구에서 사용된 특징은 크게 네 가지 범주로 나눌 수 있다:
- 단기 스펙트럼 특징
- 장기 스펙트럼 특징
- 운율 특징
- 심층 특징
단기 및 장기 스펙트럼 특징은 주로 디지털 신호 처리 알고리즘에 의존하여 추출된다.
단기 스펙트럼 특징은 일반적으로 20-30ms의 짧은 프레임에서 추출되며, 음색의 음향적 상관성을 포함한 단기 스펙트럼 엔벨로프를 설명한다. 그러나 단기 스펙트럼 특징은 음성 특징 궤적의 시간적 특성을 포착하는 데 불충분하다고 입증되었다.
이에 대응하여, 일부 연구자들은 음성 신호에서 장거리 정보를 포착하기 위해 장기 스펙트럼 특징을 제안한다.
또한 운율 특징은 가짜 음성을 탐지하는 데 사용된다. 짧은 기간의 단기 스펙트럼 특징과 달리, 운율 특징은 음소, 음절, 단어, 발화 등과 같은 더 긴 세그먼트에 걸쳐 있다.
앞서 언급한 대부분의 스펙트럼 및 운율 특징은 수작업으로 만든 특징으로, 수작업 표현의 한계로 인해 편향이 발생할 수 있다. 따라서 심층 신경망 기반 모델을 통해 추출된 심층 특징이 이러한 간극을 메우기 위해 제안된다.
3.1 단기 스펙트럼 특징
단기 스펙트럼 특징은 주로 음성 신호에 단시간 푸리에 변환(STFT)을 적용하여 계산된다. 주어진 음성 신호 ( x(t) )는 짧은 기간(예: 25ms) 동안 준정상 상태로 가정된다.
음성 신호 ( x(t) )의 STFT는 다음과 같이 공식화된다:
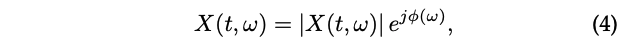
여기서 X(t, omega)는 t 프레임과 omega 주파수 빈에서의 크기 스펙트럼이고, phi(omega)는 위상 스펙트럼입니다. 전력 스펙트럼은 X(t, omega)^2 로 정의된다.
단기 스펙트럼 특징은 주로 단기 크기 기반 특징과 단기 위상 기반 특징으로 구성된다. 일반적으로, 일부 크기 기반 특징은 직접적으로 크기 스펙트럼에서 파생되지만 대부분은 전력 스펙트럼에서 파생된다. 위상 기반 특징은 위상 스펙트럼에서 파생된다.
3.1.1 단기 크기 기반 특징
전력 스펙트럼에서 파생된 전력 스펙트럼 특징은 가짜 음성 탐지에서 가장 많이 연구된 특징일 수 있다. 여기에는 로그 전력 스펙트럼(LPS), 켑스트럼(Cep), 필터 뱅크 기반 켑스트랄 계수(FBCC), 전극 모델링 기반 켑스트랄 계수(APCC) 및 서브밴드 스펙트럼(SS) 특징이 포함된다.
-
LPS는 일반적으로 로그 스펙트럼이라고 하며, 로그를 사용하여 원시 전력 스펙트럼에서 직접 계산된다. 켑스트럼(Cep)은 전력 스펙트럼에서 이산 코사인 변환(DCT)을 적용하여 파생된다. 그러나 LPS와 Cep 특징의 차원은 너무 높다.
-
FBCC 특징은 이 문제를 해결하기 위해 제안되었으며, 직사각형 필터 켑스트랄 계수(RFCC), 선형 주파수 켑스트랄 계수(LFCC), 멜 주파수 켑스트랄 계수(MFCC), 역멜 주파수 켑스트랄 계수(IMFCC)를 포함한다.
-
RFCC는 선형 스케일 직사각형 필터를 사용하여 계산된다.
-
LFCC는 선형 삼각형 필터를 사용하여 추출된다.
-
MFCC는 멜 스케일 삼각형 필터에서 파생되며, 낮은 주파수에 더 밀집되어 인간의 청각 인식을 모방한다.
-
IMFCC는 역멜 스케일에 선형적으로 배치된 삼각형 필터를 사용하여 고주파 영역에 더 큰 비중을 둔다.
-
MFPC 특징 (멜 주파수 주성분 계수)는 MFCC 계수와 유사하게 얻어지지만, DCT 대신 주성분 분석(PCA)을 사용하여 음향 특징의 관계를 제거한다. 멜 스펙트럼(Mel spec)도 DCT 없이 MFCC 계수와 유사하게 파생된다.
-
LFCC 특징은 잘 알려져 있으며, 가우시안 혼합 모델(GMM)과 가벼운 컨볼루션 신경망(LCNN)과 함께 ASVspoof 및 ADD 챌린지의 베이스라인 모델로 사용된다.
-
APCC 특징은 신호의 모든 전극 모델링 표현에서 파생된 선형 예측 켑스트랄 계수(LPCC)로 변환된다.
-
SS 특징은 서브밴드 스펙트럼 플럭스 계수(SSFC), 스펙트럼 중심 크기 계수(SCMC), 서브밴드 중심 주파수 계수(SCFC) 및 이산 푸리에 멜 서브밴드 변환(DF-MST)을 포함한다. 서브밴드 특징은 대부분 스펙트럼 플럭스 및 중심 크기와 같은 정보를 추출하며, 각 서브밴드 내의 세부 사항은 보지 않는다.
3.1.2 단기 위상 기반 특징
위상 정보는 인간의 음성 인식에 중요하지만, 대부분의 텍스트-음성 변환(TTS) 및 음성 변환(VC) 시스템은 단순화된 최소 위상 모델을 사용하여 위상 스펙트럼에 인공적인 왜곡을 도입할 수 있다. 따라서 위상 기반 특징은 인간 음성과 생성된 음성을 구별하는 데 사용할 수 있다.
위상 스펙트럼 자체는 위상 왜곡으로 인해 가짜 오디오 탐지에 안정적인 패턴을 제공하지 않는다. 대신, 유용한 단기 위상 기반 특징을 생성하기 위해 후처리 방법이 사용된다. 여기에는 그룹 지연(GD) 기반 특징과 기타 위상 특징이 포함된다.
그룹 지연(GD) 기반 특징
GD 기반 특징은 GD, 수정된 GD(MGD), MGD 켑스트럼 계수(MGDCC), 전극 그룹 지연(APGD)를 포함한다.
-
GD는 주파수 축을 따라 위상 스펙트럼의 미분으로, 필터 위상 응답의 표현으로 언급된다.
-
MGD는 켑스트럼 평활화 후 프레임별로 스펙트럼에서 계산되며, GD의 변형으로 GD보다 더 명확한 위상 패턴을 추출할 수 있다. Xiao 등 은 안티 스푸핑을 위해 MGD의 동적 범위를 제어하는 두 가지 요소를 사용한다.
-
MGDCC는 위상 및 크기 정보를 모두 사용하여 MGD 위상 스펙트럼에서 계산된다. Wu 등 은 MGDCC 특징을 사용하여 합성 음성과 인간 음성을 구별하며, 이는 MFCC 특징보다 우수하다.
-
APGD는 모든 극 모델링을 사용하는 위상 기반 특징으로, 스푸핑된 음성 탐지에서 그 역할이 조사되었으며, 최적화해야 하는 매개변수가 MGD보다 적다.
기타 위상 특징
기타 위상 특징 은 순간 주파수(IF), 기저 대역 위상 차이(BPD), 상대 위상 이동(RPS), 피치 동기 위상(PSP), 코사인-위상(CosPhase) 기반 특징을 포함한다.
-
IF 특징은 시간 축을 따라 위상 스펙트럼의 미분이다. 생 위상 스펙트럼과 달리, 시간 정보가 담긴 IF 스펙트럼은 명확한 패턴을 포착한다. IF와 GD는 매우 다른 패턴을 포함하여 스푸핑된 음성 탐지에 보완적인 정보를 제공할 수 있다.
-
BPD는 기저 대역 STFT에서 추출된 위상 특징으로, IF에 비해 더 안정적인 시간 미분 위상 정보를 제공한다.
-
RPS는 기본 주파수에 대한 조화 성분의 "위상 이동"을 반영한다.
-
위상 스펙트럼의 패턴을 드러내는 또 다른 방법은 피치 동기 STFT를 사용하는 것으로, 이 패턴은 PSP 특징이라 불린다.
-
CosPhase 특징은 DCT를 적용한 풀린 위상 스펙트럼에 코사인 함수를 적용하여 위상 스펙트럼에서 추출된다. CosPhase 특징의 차원을 줄이기 위해 PCA를 이용한 CosPhase 주성분 계수(CosPhasePC)가 계산된다.
3.2 장기 스펙트럼 특징
단기 스펙트럼 특징은 프레임별로 계산되기 때문에 음성 신호의 시간적 특성을 잘 포착하지 못한다. 이를 보완하기 위해 장기 스펙트럼 특징이 제안되었으며, 장기 정보를 포착하는 데 중요한 역할을 한다.
장기 스펙트럼 특징은 주파수-시간 분석 접근법에 따라 크게 네 가지로 나눌 수 있다:
- STFT 기반 특징
- CQT 기반 특징
- HT 기반 특징
- WT 기반 특징
3.2.1 STFT 기반 특징
STFT(Short-Time Fourier Transform) 기반 특징은 다음과 같이 네 가지로 나눌 수 있다:
-
변조 특징(Modulation features): 변조 스펙트럼(ModSpec)과 전역 변조(Global M)를 포함한다. ModSpec은 음성 신호의 장기 시간 특성을 포함한다. Global M 특징은 스펙트럼(MFCC 등)과 시간 변조 정보를 결합하여 가짜 음성 탐지 성능을 향상시킨다.
-
Shifted Delta Coefficients (SDC): 여러 음성 프레임의 델타 계수를 증강하여 장기 음성 정보를 포착한다.
-
주파수 도메인 선형 예측(FDLP): 다양한 서브밴드에서 선형 예측 분석을 수행하여 얻어진 DCT를 사용한다.
-
로컬 바이너리 패턴(LBP) 특징 : 컴퓨터 비전 작업에서 LBP 분석을 통해 스펙트럼 특징에서 장기 정보를 얻는다. LFCC 특징을 텍스트로그램으로 변환하여 히스토그램을 사용해 스푸프 탐지를 수행하는 방법이 있었다.
3.2.2 CQT 기반 특징
CQT(Constant-Q Transform)는 긴 창 변환으로, STFT와는 달리 낮은 주파수에서 높은 주파수 해상도를 제공하고, 높은 주파수에서 높은 시간 해상도를 제공한다. CQT 기반 특징은 여러 방식으로 파생되며, 주요한 예로는 CQT 스펙트럼, CQCC, eCQCC, ICQCC, CQTMGD 등이 있다.
-
CQT 스펙트럼(CQT spectrum) : CQT를 통해 얻어진 원시 파워 스펙트럼에 로그를 적용하여 계산되며, CQTgram이라고도 한다. CQT 스펙트럼을 사용한 방법이 ASVspoof 2017에서 최고의 결과를 얻었다.
-
CQCC(CQ Cepstral Coefficient) : CQT로부터 파생된 로그 파워 스펙트럼의 DCT를 통해 얻어진다. 2016년에 CQCC 특징을 사용한 방법이 TTS 기반 공격을 효과적으로 탐지했다.
-
eCQCC : 옥타브 파워 스펙트럼과 선형 파워 스펙트럼에서 계산된 CQCC 특징의 조합으로 파생된다.
-
ICQCC : 장기 CQT의 역 선형 파워 스펙트럼에서 파생된다.
-
CQTMGD : CQT와 MGD를 결합하여 위상 기반 특징을 강화한 것으로, ASVspoof 2019에서 물리적 접근 서브 챌린지에서 1위를 차지했다.
3.2.3 HT 기반 특징
HT(Hilbert Transform) 기반 특징은 힐버트 변환을 통해 얻어진 분석 신호에서 계산된다. 예로는 평균 힐버트 엔벨로프 계수(MHEC)가 있다. 힐버트 엔벨로프는 신호의 각 감마톤 필터 출력에서 계산되고 저역 통과 필터를 사용하여 평활화된다.
3.2.4 WT 기반 특징
WT(Wavelet Transform) 기반 특징은 주로 음성 신호에 WT를 수행하여 파생된다. 예로는 멜 웨이브릿 패킷 계수(MWPC), 와우라 필터 켑스트랄 계수(CFCC) 및 CFCCIF가 있다.
-
MWPC : 음성 신호에 웨이브릿 패킷 변환을 수행하여 계산된다. 로그 멜 스케일 정보를 PCA를 사용하여 12개의 계수로 파생하여 MWPC 특징을 도출한 방법이 제안되었다.
-
CFCC : 와우라 변환과 유사한 청각 변환을 기반으로 도출된다.
-
CFCCIF : 각 서브밴드 필터 출력에서 CFCC와 IF(즉시 주파수) 특징을 결합한 것이다. CFCCIF는 프레임 간 변화를 포착하여 실제 음성과 스푸프 음성을 구별하는 데 유용하며, ASVspoof 2015에서 최고의 결과를 얻었다.
3.3 프로소딕 특징
프로소디는 발화 신호의 세그멘트가 아닌 정보를 나타내며, 음절 강세, 억양 패턴, 발화 속도 및 리듬 등을 포함한다. 전형적으로 20-30ms와 같은 짧은 기간의 단기 스펙트럼 특징과 달리, 프로소디는 폰, 음절, 단어 및 발화와 같은 더 긴 세그먼트에 걸쳐 있다.
중요한 프로소딕 매개변수에는 주파수 기본(자연주파수, F0), 지속시간(예: 폰 지속시간, 일시정지 통계), 에너지 분포, 발화 속도 등이 있다. 가짜 오디오 탐지에 대한 이전 연구들은 주로 세 가지 주요 프로소딕 특징을 고려한다:
- F0
- 지속시간 및 에너지
이러한 특징은 스펙트럼 특징과 비교했을 때 채널 효과에 덜 민감하다. 스펙트럼 특징을 보완하여 가짜 오디오 탐지의 성능을 향상시킬 수 있다.
F0는 피치라고도 알려져 있다. 합성 음성의 피치 패턴은 자연 음성과 다르다. TTS 또는 VC 모델이 적절하게 합성하기 위해 필요한 인간의 생리학적 특성을 정확하게 모델링하는 것은 어렵다. 그래서 합성 음성은 인간의 음성과 다른 평균 피치 안정성을 갖는다.
또한, 인간 음성의 발음은 합성 음성보다 더 부드럽고 더 느긋하다. 이 차이는 후자의 피치 패턴의 jitters에 의해 포착된다. 따라서 이미지 분석에서 유도된 평균 피치 안정성과 같은 피치 패턴 통계를 사용하여 합성 음성을 탐지하는 방법이 제안되었다.
- TTS는 일반적으로 텍스트에서 F0를 예측하여 비자연적인 궤적을 만든다. 그러나 VC는 일반적으로 원본 화자의 자연스러운 F0 궤적을 복사하기 때문에, 피치 패턴은 특히 유닛 선택 합성 공격에 대한 합성 음성을 감지하는 데 유용하다.
Magnitude와 위상 기반 특징에 보충적인 정보로서 프레임 수준에서의 피치 변동을 추출하여 합성 음성 탐지의 성능을 개선한다. 그러나 F0의 분포는 불규칙하기 때문에 직접 사용하기 어렵다.
이 문제를 해결하기 위해 2022년에 F0 서브밴드의 식별적 특징을 포착하기 위한 방법이 제안되었다. 그러나 피치 추출 알고리즘은 일반적으로 소음 환경에서 믿을 수 없으며, 프로소딕 특징의 추출에는 상대적으로 많은 양의 훈련 데이터가 필요하다.
최근에 F0, 음소 지속시간 및 에너지를 통합하여 가짜 오디오 탐지하는 방법이 시도되었다. 음소 지속시간 특징은 HuBERT를 사용하여 사전 훈련된 모델을 통해 추출된다.
3.4 딥 특징
이전에 언급된 스펙트럼 특징과 프로소딕 특징 대부분은 수작업으로 만들어진 특징이며, 강력하고 유용한 표현 능력을 갖고 있다. 그러나 이러한 특징들의 설계는 수작업 표현의 한계로 인해 편향이 있다. 이러한 이유로, 딥 특징이 도입되었다. 딥 특징은 딥 뉴럴 네트워크를 사용하여 학습되며, 주로 다음과 같이 분류된다:
3.4.1 학습 가능한 스펙트럼 특징
학습 가능한 스펙트럼 특징은 학습 가능한 뉴럴 레이어를 사용하여 표준 필터링 프로세스를 추정하는 것을 포함한다. 이러한 특징들은 수행하는 절차에 따라 부분적으로 학습 가능한 스펙트럼 특징과 완전히 학습 가능한 스펙트럼 특징으로 분류된다.
부분적으로 학습 가능한 스펙트럼 특징은 음성 신호에 STFT를 적용하여 얻은 스펙트로그램과 함께 신경망 기반 필터 뱅크 행렬을 훈련함으로써 추출된다.
-
이 방법은 Hong et al. (2017)에 의해 개발된 DNN 필터 뱅크 켑스트럴 계수 (FBCC)인 '학습된 FBCC'로 예를 들 수 있다. 이를 통해 자연스러운 음성과 합성된 음성 사이의 차이를 더 잘 포착할 수 있다.
-
또한, Sailor et al.은 제한된 볼츠만 머신을 사용하여 필터 뱅크 표현을 학습하는 ConvRBM 기능을 제안한다.
-
Cheuk et al.은 nnAudio라는 오디오 처리 툴킷을 제안하고 이를 사용하여 시간 영역에서 주파수 영역으로 오디오 신호를 변환한다.
-
그러나 Fu et al.은 nnAudio를 구현하는 데 제한이 없는 학습 가능한 필터 뱅크 세트로 인해 nnAudio 기반의 스푸핑 방지 방법이 한계적인 개선만 얻는다고 보고한다.
-
Zhang et al.은 다른 제약을 가진 필터 뱅크의 주파수 중심, 대역폭, 이득 및 형태를 학습하기 위해 신경망을 사용한다.
-
Fu et al.은 고정 필터 뱅크를 대체하는 대신 안티-스푸핑 작업에 대한 필터 뱅크 형상 제약을 수행하기 위해 STFT의 스펙트로그램을 입력으로 사용하는 'FastAudio'라는 프론트엔드를 제안한다.
완전히 학습 가능한 스펙트럼 특징은 표준 필터링 프로세스를 근사화하기 위해 원시 파형(raw waveforms)에서 직접 학습된다. 이러한 특징은 스펙트로그램과 필터뱅크 행렬을 훈련하여 추출되는 부분적으로 학습 가능한 스펙트럼 특징과는 다르다.
-
Zeghidour et al.은 멜-필터뱅크의 산란 변환 근사화를 통해 시간 영역 필터뱅크(TD-FBanks)를 제안한다.
-
TD-FBanks는 초기화 단계에서 멜-필터뱅크를 근사화하는데 어떠한 제약도 가하지 않고 학습된다.
-
SincNet은 사인 카디널 필터(convolution with sine cardinal filters), 비선형성, 최대 풀링 레이어를 학습하는 것과 Gabor 필터를 사용하는 변형을 학습하는 것을 제안한다.
-
Tak et al.는 SincNet을 엔드-투-엔드 안티-스푸핑 모델인 RawNet2의 첫 번째 레이어로 사용한다.
-
Zeghidour et al.은 Gabor 필터를 사용하는 새로운 학습 가능한 필터링 레이어인 LEAF를 설계한다. 이는 멜-필터뱅크의 대체품으로 사용될 수 있다. Sinc 필터가 창 함수를 사용해야 하는 반면 [92], Gabor 필터는 시간과 주파수 영역에서 최적으로 로컬라이즈된다.
-
Tomilov et al.은 ASVspoof 2021의 리플레이 공격을 감지하기 위해 LEAF 특징을 사용하여 유망한 결과를 얻었다.
3.4.2 Supervised embedding features
지도된 임베딩 특징은 지도된 훈련을 통해 딥 뉴럴 네트워크로부터 깊은 임베딩을 추출하는 것을 포함한다. 오디오 딥페이크 감지를 위한 지도된 임베딩 특징은 대략 네 가지 유형이 있다:
스푸프 임베딩은 정상적인(bonafide) 및 가짜(spoofed) 데이터로 훈련된 뉴럴 네트워크 기반 모델에서 추출된다.
-
Chen et al.은 ASVspoof 2015 챌린지에서 스푸프 음성 감지를 위해 강력하고 추상적인 특징 표현을 계산하기 위해 DNN 기반 모델을 사용한다.
-
Qian et al.은 반복 신경망(RNN) 모델에서 시퀀스 수준 병목 특징으로 s-벡터라고 불리는 것을 추출하여 안티-스푸핑을 수행한다.
-
Das et al.은 2019년 LPS 특징을 사용하여 DNN 모델을 사용하여 깊은 특징 추출기를 훈련시킨다.
스푸프 임베딩은 출력 레이어를 제거하여 특징 추출기에서 계산된다. 가짜 오디오 감지를 위해 시퀀스 문맥 정보를 학습하기 위해
-
Alejandro et al.은 문장 수준의 깊은 임베딩을 학습하기 위해 경량 컨볼루션 게이트 RNN을 제안한다.
-
가장 최근에 Doan et al.은 RNN, 컨볼루션 시퀀스-투-시퀀스 및 트랜스포머 기반 인코더를 사용하여 오디오 클립에서 숨쉬는 소리와 말하는 소리, 그리고 공백을 학습한다.
3.4.3 Self-supervised embedding features
지도된 임베딩 특징은 알려지지 않은 조건에 대해 잘 일반화되지만, 이러한 특징은 레이블이 지정된 풍부한 훈련 데이터를 사용하여 학습된다. 그러나 주석이 달린 음성 데이터나 가짜 발화를 얻는 것은 비용이 많이 들고 기술적으로 요구된다.
이로 인해 연구자들은 자기 지도 음성 모델을 사용하여 훈련된 깊은 임베딩 특징을 추출하는 것에 동기부여를 받는다.
효과적인 자기 지도 모델을 훈련하는 것은 비용이 많이 들지만, Wav2vec, XLS-R, HuBERT와 같은 사전 훈련된 자기 지도 음성 모델이 여럿 공개되어 있다.
Wav2vec 기반 특징은 사전 훈련된 Wav2vec 또는 Wav2vec2.0 모델에서 추출된다.
-
Xie et al.는 2021년에 실제 음성과 가짜 음성을 구별하기 위해 Siamese 신경망 기반의 표현 학습 모델을 제안했다. 이 모델은 사전 훈련된 Wav2vec 모델에서 추출된 wav2vec 특징을 사용하여 훈련된다.
-
Tak et al.은 2022년에 가짜 오디오 감지를 위해 Wav2vec2.0 프론트 엔드를 사용하는 자기 지도 학습을 제안한다. 사전 훈련된 Wav2vec2.0은 가짜 오디오 없이 실제 음성 데이터만을 사용하여 훈련되었지만, 그들은 ASVspoof 2021 LA와 Deepfake 데이터셋에 대해 문헌에서 보고된 최신 결과를 얻었다.
XLS-R 기반 특징은 Wav2vec2.0의 변형인 사전 훈련된 XLS-R 모델에서 추출된다.
-
Martin-Donas는 2022년 ADD 챌린지의 LF 트랙에서 사전 훈련된 XLS-R에서 추출된 깊은 특징을 활용했다.
-
Lv et al.는 가짜 오디오 감지를 위해 자기 지도 모델 XLS-R을 특징 추출기로 사용한다. 이러한 특징은 알려지지 않은 부분적으로 가짜인 음성에 대해 잘 일반화되며, ADD 2022 대회의 PF 작업에서 최고의 결과를 얻었다.
HuBERT 기반 특징은 사전 훈련된 HuBERT 모델에서 추출된다.
- Wang 등은 오디오 딥페이크 감지를 위해 사전 훈련된 HuBERT 모델을 사용하여 지속 시간 인코딩 벡터를 추출한다. 이 인코딩 벡터는 음성 음운과 유사한 인코딩이다. 사전 훈련된 HuBERT에서 추출된 임베딩을 직접 감지 모델의 입력 특징으로 사용한다.
다른 사전 훈련된 자기 지도 모델에서 추출된 임베딩 특징을 사용하여 스푸핑 음성 감지의 성능을 조사했다. 예를 들어, Wav2vec2.0, XLS-R 및 HuBERT와 같은 모델에서 추출된 임베딩 특징을 사용하여 유용한 결과를 제시했다.
사전 훈련된 모델이 대상 데이터로 미세 조정되지 않은 경우, 분류기는 안티 스푸핑 모델에 대해 심층적이어야 한다. 그러나 사전 훈련된 모델이 안티 스푸핑 데이터로 미세 조정된 경우, 간단한 신경망으로도 충분하다.
자기 지도 학습을 사용하여 깊은 임베딩 특징을 학습하는 것은 가짜 오디오 감지의 일반화를 향상시킬 가능성이 있는 잠재적인 방향으로 제안된다.
4. 분류 알고리즘
백엔드 분류기는 오디오 딥페이크 감지에 있어 매우 중요하며, 프런트엔드 입력 특징의 고수준 특성 표현을 학습하고 우수한 구별 능력을 모델링하는 것을 목표로 한다. 분류 알고리즘은 주로 전통적 분류와 심층 학습 분류로 나뉜다.
4.1 전통적 분류
가짜 음성을 탐지하는 데 많은 고전적인 패턴 분류 접근 방식이 사용되었다. 로지스틱 회귀 (LR), 확률적 선형 판별 분석 (PLDA), 랜덤 포레스트 (RF), 그래디언트 부스팅 결정 트리 (GBDT), 익스트림 러닝 머신 (ELM) , k-최근접 이웃 (KNN) 등이 포함된다. 가장 널리 사용되는 분류기는 서포트 벡터 머신 (SVM) 및 GMM이다.
4.1.1 SVM 기반 분류기
이전 초기 작업에서 스푸핑 오디오 감지에 광범위하게 사용되는 전통적 분류기 중 하나는 우수한 분류 능력으로 인해 SVM이다.
-
Alegre 등은 SVM 분류기가 인공적 신호 스푸핑 공격에 대해 내재적으로 견고하다고 제안한다. 그러나 실제 시나리오에서 스푸핑 공격의 정확한 성격을 알기가 매우 어렵다.
-
따라서 Alegre 등과 Villalba 등은 오직 진짜 발음을 사용하여 훈련된 단일 클래스 SVM 분류기를 제안하여 실제와 가짜 음성을 분류하고, 이는 알려지지 않은 스푸핑 공격에 잘 일반화된다.
-
Hanilc¸i 등은 SVM의 입력 특징으로 ivector를 사용하여 실제 발음과 가짜 발음을 구별한다.
4.1.2 GMM 기반 분류기
GMM으로 잘 알려진 또 다른 전통적 분류기는 효과적인 생성 모델로, ASVspoof 201, 2019, 2021 및 ADD 2022 와 같은 일련의 대회에서 기준 모델로 사용되었다.
-
Amin 등은 MFCC 특징을 사용하여 음성 변장을 감지하기 위해 GMM 분류기를 훈련시켰다.
-
De Leon 등은 인간과 합성 음성을 구별하기 위해 GMM 분류를 사용한다.
-
Wu 등은 실제와 변환된 음성 사이를 결정하기 위해 실제 및 변환된 음성에 대한 GMM 모델을 기반으로 한 로그 스케일 우도 비율을 사용하는 방법을 제안한다.
-
Sizov 등은 GMM 평균 슈퍼벡터로 훈련된 i-벡터를 사용하여 VC 공격 감지와 스피커 확인을 동시에 수행하여 유망한 성능을 얻었다.
ASVspoof 2015 및 2017의 많은 참가자들이 진짜와 가짜 음성을 분류하기 위해 GMM을 채택하여 유망한 성능을 얻었다.
-
Sahidullah 등은 다양한 특징의 벤치마킹을 위해 ASVspoof 2015 데이터셋에서 합리적인 정확도를 얻기 때문에 GMM 분류기를 선택한다.
-
또한, Todisco 등 [115]은 정품과 가짜 음성에 해당하는 두 클래스에 GMM을 사용하여 표준 2-클래스 분류기를 사용한다.
4.2 딥러닝 분류
가장 최근의 가짜 오디오 탐지 시스템의 백엔드 분류는 주로 강력한 모델링 능력으로 인해 SVM 및 GMM 기반 분류기를 크게 능가하는 딥러닝 방법을 기반으로 한다. 백엔드 분류의 모델 아키텍처는 일반적으로 합성곱 신경망 (CNN), 딥 잔여 신경망 (ResNet), 수정된 ResNet (Res2Net), 스퀴즈-앤-익스사이트 네트워크 (SENet), 그래프 신경망 (GNN), 차별 가능한 아키텍처 탐색 (DARTS) 및 Transformer를 기반으로 한다.
4.2.1 CNN 기반 분류기
CNN은 공간적으로 지역적인 상관 관계를 잘 포착하는 데 능하므로, CNN 기반 분류기는 유망한 성능을 달성했다. 이러한 분류기 중 하나인 경량 CNN (LCNN)은 최대 특징 맵 (MFM) 활성화와 함께 합성곱 및 최대 풀링 레이어로 구성된다.
LCNN은 ASVspoof 및 ADD 대회의 기준 모델로 사용된다. ASVspoof 2017의 최고 시스템 및 ASVspoof 2019 LA 작업의 최고 단일 시스템도 모두 LCNN을 가짜 오디오 탐지에 사용한다.
MFM 활성화는 잡음 효과 (주변 잡음, 신호 왜곡 등)를 필터링하고 핵심 정보를 유지하는데 도움이 되며, 계산 비용과 저장 공간을 줄인다.
-
Zeinali 등은 가짜 발화를 감지하기 위해 여러 합성곱 및 풀링 레이어 후 통계 풀링 및 여러 밀도 레이어로 구성된 VGG와 유사한 네트워크를 사용한다.
-
Wu 등은 정품 음성만을 사용하여 훈련된 특징 정형화 트랜스포머와 CNN을 사용하여 모델을 학습한다.
4.2.2 ResNet 기반 분류기
딥 CNN은 가짜 오디오 감지에 유망한 결과를 얻었지만, 더 깊은 신경망은 더 어려운 훈련을 필요로 하며 성능 저하를 초래할 수 있다. 이 문제를 해결하기 위해 잔여 매핑을 사용하는 ResNet이 분류기로 도입된다.
-
Tomilov 등과 Chen 등은 모두 ASVspoof 2021의 딥페이크 과제에서 유망한 결과를 얻기 위해 ResNet을 사용한다.
-
Yan 등은 다중 헤드 어텐션 풀링 레이어가 있는 표준 34층 ResNet을 사용하여 딥페이크 오디오를 감지하며, ADD 2022의 FG-D 과제에서 1위를 차지한다.
-
Lai 등은 ResNet 기반의 Attentive Filtering Network (AFN)라는 분류기를 제안하여 성능을 더 향상시킵니다. AFN은 저항성 유닛을 수정하여 완전 연결 레이어 대신 컨볼루션 레이어를 사용하고 확장을 추가하는 방식의 잔여 네트워크를 기반으로 한다.
-
Parasu 등은 오버피팅을 방지하기 위해 네트워크 매개변수를 줄이면서 경량 ResNet 기반 가짜 오디오 감지 시스템을 소개한다.
-
Kwak 등은 MFM 활성화와 ResNet을 결합한 ResMax라는 컴팩트 네트워크를 소개하여 위조 오디오 감지 시스템의 성능을 향상시킨다.
4.2.3 Res2Net 기반 분류기
ResNet 기반 모델은 위조 신호를 잘 포착하는 능력이 강하지만, 보이지 않는 위조 공격에 대한 일반화 능력은 여전히 제한적이다.
-
따라서 Li 등은 Res2Net을 위조 오디오 탐지 시스템에 통합하는 것을 제안했다. 여기서 ResNet 블록 내의 피쳐 맵은 잔여 연결에 의해 연결된 여러 채널 그룹으로 분할된다. Res2Net의 연결은 수용 영역을 확장하고 보이지 않는 가짜 발화에 대한 일반화를 향상시킨다.
-
Kim 등은 위조 오디오를 감지하기 위해 위상 및 크기 피쳐로 공급된 Res2Net 및 Phase 네트워크를 활용한다.
4.2.4 SENet 기반 분류기
CNN의 합성곱 연산자는 각 레이어에서 로컬 수용 영역 내에서 공간 및 채널별 정보를 모두 융합하기 위해 설계되었으며 채널 간의 관계를 고려하지 않는다.
-
Hu 등 및 Zhang 등은 채널 간 상호 의존성을 적응적으로 모델링하기 위해 Squeeze-and-Excitation 네트워크 (SENet)를 제안한다.
-
Lai 등은 가짜 오디오 탐지 모델 중 하나를 훈련하는 데 SENet을 사용한다. 더 나아가, 그들은 SENet과 ResNet을 결합한 시스템인 Squeeze-Excitation 및 Residual neTworks (ASSERT)를 제안한다. ASSERT는 ASVspooof 2019의 두 하위 챌린지에서 성능이 우수한 시스템 중 하나로 순위가 매겨진다.
-
Wu 등은 SELF-Attention 레이어와 함께 SENet을 사용하여 부분적으로 위조된 오디오를 감지하여 ADD 2022 챌린지에서 최고의 성능을 달성한다.
-
Xue 등은 효율적인 채널 어텐션을 통한 SENet을 사용하여 위조 음성을 감지한다.
4.2.5 GNN 기반 분류기
그래프 신경망(GNN), 예를 들어 그래프 주의 네트워크(GAT)나 그래프 합성곱 네트워크(GCN)는 데이터 간의 기본적인 관계를 학습하는 데 사용된다. 위조 공격을 감지하기 위해 사용되는 가짜 아티팩트는 특정 시간 구간이나 스펙트럼 서브밴드에 위치하는 경우가 많다. 하지만 앞서 언급된 연구들은 이웃한 서브밴드나 구간 간의 관계 학습에 초점을 맞추지 않았다.
-
Tak 등은 이러한 관계를 모델링하여 위조 오디오 탐지 시스템의 성능을 향상시키기 위해 GAT를 사용한다.
-
최근 Chen 등은 GCN을 사용하여 사전 지식을 통합해 스펙트로-템포럴 종속성 정보를 학습하여 ASVspoof 2019 LA 데이터셋에서 유망한 성능을 달성했다.
4.2.6 DARTS 기반 분류기
차별화된 아키텍처 검색(DARTS)라는 특정 변형된 신경망 아키텍처 검색 방법은 아키텍처 블록 내의 연산(합성곱, 풀링, 잔여 연결 연산 등)을 자동으로 최적화한다.
-
Ge 등은 부분 채널 연결(PC-DARTS)이라는 DARTS의 변형을 오디오 딥페이크 탐지에 도입했다. PC-DARTS 기반 모델은 인간의 개입이 거의 없고 Res2Net 모델보다 85% 적은 파라미터를 포함하면서도 이전 연구에서 최고 성능을 기록한 시스템과 비교하여 경쟁력 있는 결과를 얻었다.
-
Wang 등은 DARTS와 MFM 활성화를 결합한 경량 DARTS를 제안하여 피처 선택의 역할을 수행한다.
4.2.7 Transformer 기반 분류기
완전히 위조된 발화와 달리 부분적으로 위조된 발화는 연결된 오디오 클립 사이에 불연속적인 아티팩트가 포함되어 있다. Transformer는 로컬 및 글로벌 아티팩트와 관계를 모델링하는 데 뛰어나다.
- Cai 등은 Transformer와 ResNet-1D를 백엔드 분류기로 사용하여 부분적으로 위조된 오디오를 감지하고 가짜 영역을 찾는다.
5. 엔드 투 엔드 모델
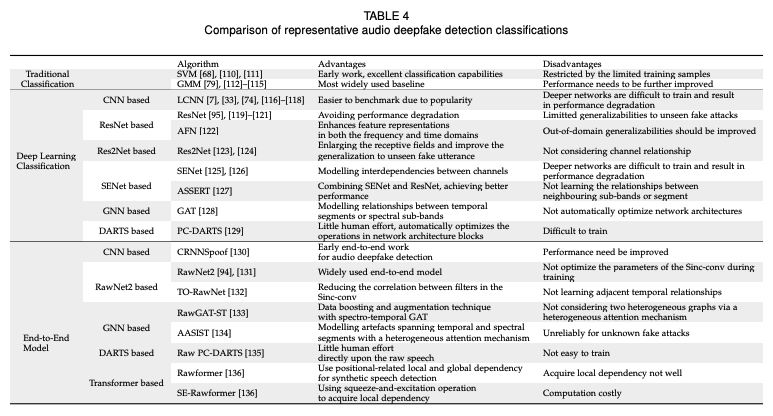
앞서 언급된 오디오 딥페이크 탐지 방법은 손으로 만든 피처 또는 학습 가능한 피처를 제공받는 머신 러닝 기반 분류기의 설계에 중점을 두었다. 과거 문헌에서는 잘 설계된 분류기를 사용하면 더 나은 성능을 발휘할 수 있음을 보여주었지만, 특정 분류기의 성능은 다른 피처와 결합할 때 크게 달라질 수 있다.
최근 몇 년 동안, 피처 추출과 분류를 통합한 엔드 투 엔드 방식의 딥 뉴럴 네트워크 기반 접근법이 경쟁력 있는 성능을 달성했으며, 이 방식에서는 피처 추출기와 분류기가 원시 음성 파형에서 직접 공동으로 최적화된다. 엔드 투 엔드 모델은 지식 기반 피처 사용에서 발생하는 한계를 피하고 애플리케이션에 최적화되어 일반적인 분해보다는 더 나은 성능을 발휘한다.
오디오 딥페이크 탐지의 엔드 투 엔드 아키텍처는 대략 네 가지 유형으로 분류될 수 있다: CNN, RawNet2, ResNet, GNN, DARTS 및 Transformer.
5.1 CNN 기반 모델
몇몇 연구자들은 CNN 기반 모델을 활용하여 엔드투엔드 가짜 오디오 탐지를 시도한다.
-
Muckenhirn 등은 스푸핑 공격을 탐지하기 위해 간단한 CNN 기반 엔드투엔드 접근 방식을 사용했다. 제안된 모델은 단일 합성곱 레이어와 다층 퍼셉트론(MLP) 레이어로 구성되어 있으며, VC와 TTS 공격에 대해 우수한 성능을 보였다.
-
Dinkel 등은 원시 파형 합성곱 장기단기 기억 신경망(CLDNN) 기반의 안티스푸핑 방법을 제안했다. CLDNN 모델은 시간 및 주파수 합성곱 레이어를 사용하여 시간 및 스펙트럼 변동을 줄이고 장기 시간 정보를 모델링하기 위해 장기 메모리 레이어를 사용한다.
-
2020년, Chintha 등은 스푸핑 탐지를 위한 합성곱-순환 신경망인 CRNNSpoof를 제안했으며, 이 모델은 5개의 1-D 합성곱 레이어, 양방향 LSTM 레이어 및 두 개의 완전 연결 레이어로 구성된다.
그러나 앞서 언급된 모델들은 교차 데이터셋 평가에서 좋은 성능을 보이지 않는다.
- 이를 해결하기 위해 Hua 등은 Inception 병렬 합성곱 구조를 포함한 시간 도메인 합성 음성 구간 네트워크인 TSSDNet을 제안했다. 제안된 모델은 보지 못한 데이터셋에 대해 유망한 일반화 능력을 가지고 있다.
5.2 RawNet2 기반 모델
텍스트 독립적인 화자 검증에서 RawNet2의 강력함에 영감을 받아
-
Tak 등은 RawNet2를 안티스푸핑에 활용니다. RawNet2는 잔차 블록이 있는 합성곱 신경망으로, 첫 번째 레이어는 SincNet과 본질적으로 동일한 sinc 모양의 필터 뱅크를 가지고 있다. RawNet2는 시간 도메인 합성곱을 통해 원시 오디오에서 직접 작동하며 지식 기반 방법을 사용하여 탐지할 수 없는 신호를 학습할 수 있는 잠재력을 가지고 있다.
-
Wang 등은 가짜 오디오 탐지를 위해 가중치가 부여된 가산 각도 마진 손실을 사용하여 RawNet2를 사용한다. 그러나 RawNet2는 훈련 중 Sinc-Conv 레이어의 파라미터를 최적화하지 않아 성능이 제한된다.
-
이를 해결하기 위해 Wang 등은 필터 간의 상관성을 줄이는 정규화를 적용하여 RawNet2에 정규화 합성곱을 통합하여 구별력을 향상시킨 TO-RawNet을 제안한다. TO-RawNet 기반의 가짜 오디오 탐지 모델은 RawNet2 기반 모델보다 눈에 띄게 우수한 성능을 보인다.
5.3 ResNet 기반 모델
잔차 매핑이 있는 심층 신경망인 ResNet은 훈련이 쉬워지고 유망한 성능을 달성한다.
-
Hua 등은 잔차 스킵 연결이 있는 TSSDNet을 제안하여 더 나은 성능을 얻었다.
-
Ma 등은 Conv1D Resblocks와 백본 ResNet34로 구성된 RW-ResNet이라는 음성 안티스푸핑 모델을 제안한다.
5.4 GNN 기반 모델
그래프 표현 간의 복잡한 관계를 모델링하는 GAT의 성공에서 영감을 받아
-
Tak 등은 RawGAT-ST라는 스펙트로-템포럴 GAT를 제안하여 관계를 학습하고 ASVspoof 2019 LA 평가 세트에서 RawNet2와 Res-TSSDNet을 능가한다.
그러나 RawGAT-ST는 두 개의 그래프를 병렬로 결합하여 두 그래프에 요소별 곱셈을 적용하여 정보를 결합한다. 사실, heterogeneous attention 메커니즘을 통해 두 이종 그래프를 결합하는 것이 유익하다.
-
따라서 Jung 등 [134]은 AASIST라는 heterogeneous attention 메커니즘을 사용하여 시간 및 스펙트럼 구간에 걸친 아티팩트를 모델링하는 heterogeneous stacking graph attention layer를 제안한다.
AASIST는 현재 최첨단 엔드투엔드 모델을 능가한다. 또한 AASIST의 경량 변형인 AASIST-L은 경쟁력 있는 성능을 얻는다.
이러한 방법들은 알려진 인코딩 및 전송 조건에서는 안정적으로 작동하지만 알려지지 않은 전화 시나리오에서는 신뢰할 수 없다.
- 이를 해결하기 위해 Tak 등은 RawGAT-ST와 RawNet2 시스템을 기반으로 한 모델인 RawBoost를 제안한다.
이는 원시 오디오에 직접 적용할 수 있는 선형 및 비선형 컨볼루션 잡음과 임펄스 및 정적 가산 잡음을 결합한 데이터 부스팅 및 증강 기법이다. 또한, AASIST는 훈련 중 sinc-conv의 파라미터를 최적화하지 않기 때문에 성능이 제한된다.
- 따라서 Wang 등은 AASIST의 Sinc-conv 레이어에 정규화를 적용하여 Orth-AASIST를 사용하여 AASIST 기반 모델을 능가한다.
5.5 DARTS 기반 모델
앞서 언급한 엔드투엔드 방법은 고무적이고 유망하다. 그러나 이들은 피처와 네트워크 파라미터를 자동으로 학습할 수 있을 뿐 네트워크 아키텍처는 학습할 수 없다.
- 따라서 Ge 등은 원시 오디오 파형(Raw PC-DARTS)에서 부분적으로 연결된 차별적 아키텍처 검색을 기반으로 구현된 자동 접근 방식을 시도한다.
5.6 Transformer 기반 모델
원시 오디오에서 로컬 및 글로벌 아티팩트와 관계를 모델링하기 위해
-
Liu 등은 가짜 발화를 감지하기 위해 합성곱 레이어와 트랜스포머로 구성된 Rawformer라는 모델을 제안한다. Rawformer는 교차 데이터셋 평가에서 AASIST보다 더 잘 일반화된다.
-
Liu 등은 또한 로컬 종속성을 획득하기 위해 squeeze-and-excitation 연산을 사용하는 SE-Rawformer라는 스퀴즈-앤-익사이트 Rawformer를 제안하여 Rawformer를 능가한다.
6. 일반화 방법
대부분의 기존 오디오 딥페이크 탐지 방법은 도메인 내 테스트에서 인상적인 성능을 보였지만, 실제 시나리오에서 도메인 외 데이터셋을 처리할 때 성능이 급격히 떨어진다. 즉, 오디오 딥페이크 탐지 시스템의 일반화 능력은 여전히 부족하다. 여러 시도들이 다양한 관점에서 이 문제를 해결하려고 했으며, 여기에는 손실 함수와 지속 학습이 포함된다.
6.1 손실 함수
알 수 없는 공격에 대한 오디오 딥페이크 탐지 시스템의 일반화 능력을 향상시키는 것은 점점 더 어려워지고 있다.
-
이 문제를 해결하기 위해 Chen 등은 큰 마진 코사인 손실(LMCL) 함수와 온라인 주파수 마스킹 증강을 사용하여 신경망이 더 강력한 특징 임베딩을 학습하도록 한다. LMCL과 데이터 증강을 적용하여 탐지 모델의 일반화 능력을 향상시킨다.
-
Zhang 등은 알 수 없는 가짜 공격을 처리하기 위해 단일 클래스 학습을 사용하며, 주요 아이디어는 진짜 오디오 표현의 컴팩트한 표현을 구축하고 임베딩 공간에서 가짜 발화를 분리하는 각도 마진을 사용하는 것이다.
이 방법은 데이터 증강 방법 없이 ASVspoof 2019 챌린지의 LA 작업 평가 세트에서 모든 기존 단일 시스템을 능가한다.
이러한 방법들은 실질적인 사용에서 알 수 없는 공격을 탐지하는 어려움을 어느 정도 해결한다. 그러나 임베딩 공간에서 본아피드 발화의 컴팩트성은 화자의 다양성을 고려하지 않는다.
-
Ding 등은 이 문제를 해결하기 위해 스피커 어트랙터 멀티센터 단일 클래스 학습(SAMO) 을 제안한다.
SAMO의 핵심 아이디어는 실제 발화가 여러 스피커 어트랙터 주위에 클러스터링되고, 이 방법은 고차원 임베딩 공간에서 모든 어트랙터로부터 가짜 목소리를 밀어내는 것이다.
6.2 지속 학습
지속 학습은 새로운 정보에 대한 모델의 지속적인 훈련과 적응에 중점을 두며, 파인 튜닝에서 발생하는 재앙적 망각을 극복하는 것을 목표로 한다.
-
보지 못한 딥페이크 오디오에 대한 성능을 향상시키기 위해 Ma 등은 Detecting Fake Without Forgetting(DFWF)이라는 정규화 기반 지속 학습 방법을 제안한다.
이 방법은 이전 데이터를 접근할 필요 없이 모델이 새로운 가짜 공격을 점진적으로 학습할 수 있게 한다. 또한 정규화를 도입하여 새로운 데이터셋에서 탐지 성능을 향상시키고 재앙적 망각을 극복한다.
그러나 DFWF의 근사는 지속 학습에서 오류 누적을 초래하여 학습 성능을 저하시킬 수 있다.
-
가장 최근에 Zhang 등은 이 문제를 해결하기 위해 가짜 오디오 탐지를 위한 지속 학습 알고리즘인 정규화 적응 가중치 수정(RAWM) 을 제안한다.
RAWM은 DFWF의 정규화 제약을 완화하고 재앙적 망각을 극복하기 위해 적응적 방향 수정을 도입하여 오디오 딥페이크 탐지 작업에서 대부분의 전형적인 지속 학습 방법을 능가한다.
7. 성능 비교
7.1 주요 대회에서의 최고 성능 방법
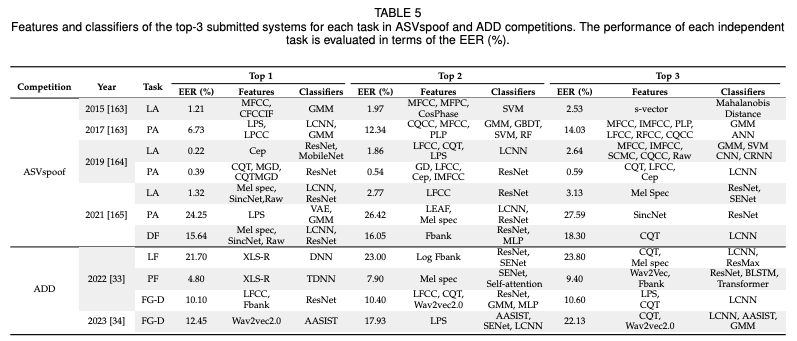
ASVspoof와 ADD 대회에서의 최고 성능 시스템은 표 5에 요약되어 있으며, EER(평균 오류율)을 기준으로 성능이 평가되었다. 이러한 시스템들은 모두 데이터 증강을 훈련에 사용하지만, 공통된 형태의 데이터 증강 방법은 확인되지 않았다.
대부분은 앙상블 시스템이며, 대부분이 단기 스펙트럼 특징이나 원시 파형을 기반으로 동작한다. 대부분은 ResNet 분류기나 그 변형을 사용하며, 다른 형태의 합성곱 신경망도 인기를 끌고 있다. 이 방법에서 사용된 융합 전략에는 균일하게 또는 경험적으로 설정된 가중치를 사용하는 가중 평균이 포함된다.
이 시스템들은 일반적으로 스펙트럼 특징에 의존하며, 특히 ASVspoof 챌린지의 초기 반복에서는 더욱 그렇다. 최근에는 Wav2vec2.0 또는 XLS-R과 같은 사전 훈련된 모델에서 파생된 특징도 많이 사용되며, ADD 대회의 최고 성능 시스템에서 사용된 바와 같이 상당한 성공을 거두고 있다.
분류기 측면에서는 전통적인 분류기(SVM, GMM 등)와 딥러닝 네트워크가 최고 성능 시스템에서 모두 사용되었다. ASVspoof 대회의 최고 성능 시스템은 GMM, SVM 및 ResNet 분류기를 사용한 반면, ADD 대회의 최고 성능 시스템은 ResNet, LCNN 및 AASIST 분류기를 사용했다.
표면적으로는 EER 증가로 인해 성능이 감소하는 것처럼 보일 수 있지만, 이는 성능 감소보다는 과제의 난이도가 증가했기 때문일 가능성이 크다. 대회에서 최고 성능 시스템은 일관되게 기준 시스템보다 큰 차이로 뛰어난 성능을 보여주었다.
7.2 특징 평가
가짜 오디오 탐지에서 다양한 핸드크래프트 특징의 판별 성능을 평가했다. 특징에는 단기 스펙트럼 특징(MFCC, LPS, LFCC, IMFCC), 장기 스펙트럼 특징(CQCC), 운율 특징(F0, 에너지, 지속 시간) 및 자기 지도 임베딩 특징(XLS-R)이 포함된다. 또한 운율 특징과 LFCC 또는 XLS-R의 연결로 생성된 특징도 포함된다. 이 실험 그룹에서 우리는 가짜 오디오 탐지 작업에서의 인기도와 효과 때문에 GMM, LCNN 및 ASSERT 분류기를 선택한다.
단기 스펙트럼 특징의 추출을 위해 기준 시스템의 설정을 참조했다. 그런 다음 1차 및 2차 차이를 계산했다. LFCC와 CQCC의 경우, 기준 시스템의 기본 설정을 따른다. LPS 특징은 오디오 처리 툴킷을 사용하여 STFT에서 블랙먼 창을 통해 추출된다.
운율 특징의 경우, 피치 추적 방법(YAPPT) [174]을 사용하여 F0 특징(A)을 추출한다. 윈도우 길이는 25ms로 설정하고 윈도우 이동은 에너지 특징(B)을 추출하기 위해 10ms로 설정한다. 지속 시간 특징(C)의 경우, HuBERT 기반 지속 시간 방법의 설정을 따른다.
Wav2vec2.0의 변형인 "Wav2vec2.0 XLS-R"을 사용하여 XLS-R 특징을 추출한다. 이 모델은 53개 언어와 56,000시간의 오디오 데이터셋에서 사전 훈련되었으며, 더 많은 선형 변환과 더 큰 컨텍스트 네트워크를 포함한다. 10ms의 오디오 세그먼트는 사전 훈련된 모델에 대해 1024차원 벡터로 변환된다.
분류기에는 GMM, LCNN 및 ASSERT 모델이 포함된다. GMM 모델은 무작위로 초기화된 512개의 구성 요소를 가진 GMM을 사용하여 기대-최대화 알고리즘으로 훈련한다. LCNN 백엔드 분류기는 Asvspoof 2019를 기반으로 하지만 LSTM 레이어와 평균 풀링을 포함한다. ASSERT 분류기는 해당 논문을 기반으로 한다.
위에 언급된 시스템 세트를 사용하여 두 가지 실험 세트를 수행한다. 첫 번째 세트에서는 ASVspoof 2021 DF 과제 훈련 세트에서 분류기를 훈련시키고, ASVspoof 2021 DF 과제 테스트 세트와 In-the-Wild 테스트 세트에서 평가한다. 두 번째 세트에서는 ADD 2023 FG-D 과제 훈련 세트에서 분류기를 훈련시키고, ADD 2023 FG-D 과제 테스트 세트와 In-the-Wild 테스트 세트에서 평가합니다. 결과는 표 6 및 7에 나와 있다.
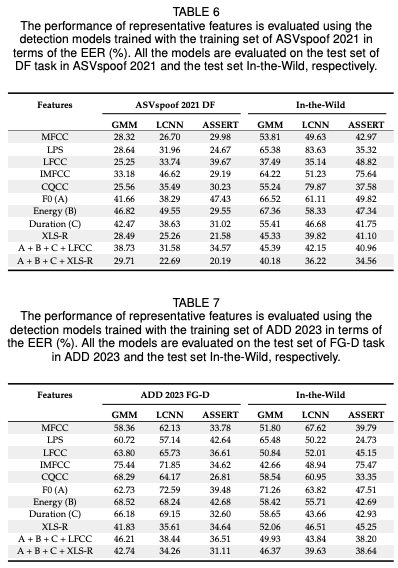
결과에서 알 수 있듯이, 탐지 시스템은 인-도메인 테스트에 비해 아웃-도메인 평가에서 성능이 더 나쁘며, EER이 2%에서 52%까지 증가한다. 특히 주목할 점은, 핸드크래프트 특징이 인-도메인 평가에서 비교 가능한 성능을 달성하지만, 아웃-도메인 상황에서는 성능 변동이 더 크다는 것이다.
반면, 사전 훈련된 모델에서 추출된 특징 및 연결된 특징은 더 일관된 성능을 보여준다. 이는 사전 훈련된 모델에서 추출된 특징이 아웃-도메인 평가에 더 강인하다는 것을 시사하며, 특징 연결이 탐지 시스템의 강인성을 향상시키는 유효한 전략일 수 있음을 보여준다. 특히, XLS-R 특징과 연결된 특징(A + B + C + XLS-R) 및 LFCC는 인-도메인과 아웃-도메인 평가 모두에서 일관적이고 경쟁력 있는 성능을 달성한다.
7.3 분류기 평가
이전의 판별 특징 평가에 이어, 우리는 다양한 백엔드 분류기와 엔드-투-엔드 모델의 성능도 평가한다. 우리는 가짜 오디오 탐지 작업에서 인기도와 효과 때문에 GMM, LCNN, ResNet, ASSERT, Res2Net, AFN 및 GAT 분류기를 선택한다. XLS-R 특징과 LFCC의 효과를 고려하여, 우리는 이 두 특징에 대해 분류기를 평가한다.
GMM, LCNN 및 ASSERT 분류기는 이전 섹션에서 설명한 대로 구성된다. ResNet 분류기는 ResNet-34 모델입니다. Res2Net, AFN, GRU 및 GAT 분류기는 오픈 소스 구현을 기반으로 한다. 훈련 시, 우리는 학습률 5 × 10^-5의 Adam 옵티마이저를 사용하며, 모델은 배치 크기 32로 200에폭 동안 훈련됩니다. 결과는 표 8 및 9에 나와 있다.
표 8에서 보듯이, AFN 및 GAT 분류기는 인-분포 조건에서 매우 좋은 성능을 보여주며, EER이 14%에서 15%로 가장 낮다. 분류기들은 아웃-분포 조건에서도 성능 변동을 크게 보이지 않는다. 이는 사전 훈련된 모델 특징을 가진 딥 컨볼루션 모델이 테스트 데이터가 인-분포일 때 효과적임을 보여준다. 그러나, 훈련 데이터와 테스트 데이터의 분포에 차이가 있을 때 분류기의 성능은 크게 저하된다. 이는 GAT 분류기의 성능에서 특히 두드러지며, In-the-Wild 테스트 세트에서 평가 시 EER이 10% 증가한다. 이는 분류기가 아웃-분포 평가에 강인하지 않음을 시사한다.
이는 표 9의 결과에서도 확인할 수 있으며, 분류기는 ADD 2023 FG-D 과제 테스트 세트와 In-the-Wild 테스트 세트에서 평가된다. 분류기는 In-the-Wild 테스트 세트에서 평가 시 EER이 크게 증가하며, 이는 훈련 데이터셋과 다른 언어다. 이는 분류기가 아웃-분포 평가에 강인하지 않음을 시사하며, 테스트 데이터가 아웃-분포일 때 분류기의 성능이 크게 저하됨을 나타낸다.
7.4 엔드-투-엔드 모델 평가
가짜 오디오 탐지 작업에서 인기도와 효과 때문에 RawNet2 및 AASIST와 같은 다양한 엔드-투-엔드 모델의 성능을 평가한다. RawNet2, AASIST 엔드-투-엔드 모델은 오픈 소스 코드를 기반으로 한다. 훈련 시, 학습률 5 times 10^{-5}의 Adam 옵티마이저를 사용하며, 모델은 배치 크기 32로 200에폭 동안 훈련된다.
표 10은 ASVspoof 2021 DF 과제 훈련 세트와 ADD 2023 FG-D 과제 훈련 세트에서 훈련된 엔드-투-엔드 모델의 성능을 보여준다. 이 모델들은 ASVspoof 2021 DF 과제 테스트 세트, ADD 2023 FG-D 과제 테스트 세트, 그리고 In-the-Wild 테스트 세트에서 평가되었다. ASVspoof 데이터셋에서 훈련된 모델의 결과는 엔드-투-엔드 모델이 인-분포 조건에서 잘 작동하며, EER이 19%에서 25%로 가장 낮은 것을 보여준다. 그러나, 엔드-투-엔드 모델의 성능은 In-the-Wild 테스트 세트에서 평가될 때 저하되며, EER이 10%에서 15% 증가한다.
반면, ADD 2023 데이터셋에서 훈련된 모델은 In-the-Wild에서 더 나은 성능을 보인다. 이는 ADD 2023 훈련 및 테스트 세트 간의 오디오 품질 및 변형의 차이로 인해 분포 차이가 더 크게 발생할 수 있기 때문이다. 전반적으로, 이러한 결과는 이 문제를 해결하는 것이 향후 연구의 유망한 방향임을 시사한다.
8. 미래 연구 방향
지난 10년 동안 오디오 딥페이크 탐지에 대한 상당한 진전이 이루어졌지만, 여전히 해결해야 할 몇 가지 한계가 있다. 다음은 잠재적인 연구 방향을 요약한 것이다.
8.1 현실 환경에서의 오디오 데이터셋 수집
대부분의 오디오 딥페이크 탐지 데이터셋은 현실 환경에서 수집되지 않아, 실제 조건에서 녹음되거나 생성된 발화와 일치하지 않는다. 실제 발화 조건은 시뮬레이션된 조건보다 더 나쁘고 다양할 수 있다. 오디오 딥페이크 탐지 방법을 실용적인 응용에서 평가하기 위해서는 다양한 채널이나 조건에서 현실 환경 조건을 통해 발화를 수집해야 한다. 예를 들어, 소셜 미디어 플랫폼, 인터넷 또는 전화 채널 등을 통해 수집할 수 있다.
8.2 대규모 다국어 데이터셋 설계
이전의 데이터셋은 주로 단일 언어 기반이며, 대부분이 영어 딥페이크 오디오 데이터셋이고 다른 언어 데이터셋(예: 중국어 또는 일본어)은 적다. 이는 탐지 방법이 언어에 의존할 수 있다. 그러나 현실적인 응용에서는 언어에 독립적인 탐지 시스템이 필요하다. 다른 언어에 대해 탐지 시스템을 더 견고하게 만들기 위해서는 교차 언어 시나리오와 다른 언어 간 코드 전환에 대한 탐지 모델의 성능을 평가해야 한다. 따라서, 현실 환경에서 오디오 딥페이크 탐지에 대한 대규모 다국어 데이터셋을 설계하고 개발하는 것이 중요하다.
8.3 탐지 모델의 일반화 능력 및 견고성 향상
이전 연구들은 오디오 딥페이크 탐지에 많은 시도를 하여 유망한 성과를 거두었지만, 탐지 모델의 일반화와 견고성은 여전히 부족하다. ASVspoof와 ADD 대회에서 최고 성능 모델의 성능이 매우 높지만, 새로운 가짜 공격이나 보지 못한 음향 조건, 또는 보지 못한 언어를 포함하는 불일치 데이터셋에서 평가할 때 성능이 크게 저하된다. 일부 연구자들은 이 문제를 해결하기 위해 효과적인 손실 함수나 지속 학습 방법을 사용했지만, 여전히 개선의 여지가 많다.
8.4 급속히 발전하는 딥페이크 기술 대처
딥페이크 기술은 빠르게 발전하고 있으며, 생성된 오디오가 점점 더 현실적이 되어 감지하기 어렵다. 이는 현재의 탐지 방법에 새로운 도전을 제공한다. 이 문제를 완화하기 위해, ADD 2022 및 2023 대회에서는 참가자들이 딥페이크 오디오 생성 및 탐지 작업을 경쟁 게임으로 간주한다. 생성 작업 참가자들은 탐지 모델을 속이기 위해 딥페이크 샘플을 생성하고, 탐지 작업 참가자들은 가능한 한 많은 가짜 발화를 탐지하려고 한다. 게임을 통한 탐지 모델의 반 공격 능력을 부분적으로 향상시키기는 했지만, 게임 방법은 단순하고 지능이 부족하다. 따라서, 새로운 보지 못한 딥페이크 오디오 기술에 대응할 수 있는 더 효과적인 탐지 접근 방식을 제안해야 한다.
8.5 탐지 결과의 해석 가능성 향상
현재 대부분의 연구는 진짜 오디오와 가짜 오디오를 구별하는 데 중점을 두고 있다. 그러나 이진 분류의 한계를 넘어서 부분적으로 가짜인 음성에서 조작된 구간을 찾고, 가짜 오디오를 생성한 출처를 식별하는 데에도 관심이 있다. 또한, 실생활 응용에서 탐지 결과의 해석 가능성은 중요하다.
예를 들어, 오디오 포렌식과 출처 추적에서는 발화가 왜 가짜인지, 가짜 오디오를 생성한 도구나 딥페이크 기법을 아는 것이 중요하다. 또한, 어떤 조작 기술이 사용되었는지, 심지어 조작의 의도까지 아는 것이 특히 중요하다. ADD 2023 챌린지에는 조작된 구간 위치 및 딥페이크 알고리즘 인식 하위 챌린지가 포함되어 있지만, 연구는 아직 초기 단계에 있다.
8.6 더 합리적인 평가 지표 탐색
이전 연구에서는 EER이 평가 지표로 널리 사용되었다. 그러나 오디오 딥페이크 탐지 모델에 EER이 적합한지 평가할 필요가 있다. 인간의 탐지 능력과 딥페이크 오디오를 탐지하는 인간과 기계 간의 차이를 고려해야 한다.
9. 결론
딥페이크 기술은 악의적으로 사용될 경우 사회적 안전과 정치 경제에 심각한 위협이 된다. 따라서 딥페이크 오디오를 탐지하는 것은 필수적이다. 실생활에서 오디오 딥페이크 탐지를 유용하게 만들기 위해서는, 견고하고 일반화된 알고리즘을 제안하고 유효하고 신뢰할 수 있는 샘플을 제공하여 딥페이크 오디오 탐지를 실제 상황에 적용할 수 있어야 한다.
이에 따라, 이 설문 조사에서는 오디오 딥페이크 탐지에 대한 현재의 연구를 검토하고, 기존 최첨단 방법들의 성능을 비교하며, 잠재력과 향후 연구를 위한 중요한 문제를 강조한다. 최근 오디오 딥페이크 탐지는 활발한 연구 영역이 되었으므로, 이 설문 조사가 연구자들에게 출발점으로서 최첨단 기술 개발을 검토하고 향후 연구 방향을 식별하는 데 도움이 되기를 바란다.
