[Capstone #10] Encoding Speaker-Specific Latent Speech Feature for Speech Synthesis
Capstone
Paper : https://arxiv.org/abs/2311.11745
Abstract
이 연구에서는 다수의 화자를 모델링하는 새로운 방법을 제안한다. 이 방법은 훈련된 다중 화자 모델처럼 화자의 전반적인 특성을 세부적으로 표현할 수 있으며, Taget speaker의 데이터셋에 대한 추가 훈련 없이도 가능하다.
이와 유사한 목적을 가진 다양한 연구들이 활발히 진행되고 있지만, 근본적인 한계로 인해 훈련된 다중 화자 모델의 성능에 도달하지 못하고 있다. 이전 한계를 극복하기 위해, 특징 학습과 Taget speaker의 음성 특성을 표현하는 효과적인 방법을 제안한다.
이 방법은 특징을 이산화하고 이를 음성 합성 모델에 조건화함으로써 이루어진다. 제안된 방법은 주관적 유사성 평가에서 기존 최고의 다중 화자 모델의 학습된 화자보다 훨씬 높은 유사성 평균 의견 점수(SMOS)를 얻었다. 또한 제안된 방법은 제로샷 방법을 상당한 차이로 능가한다. 게다가, 새로운 인공 화자를 생성하는 데 있어서도 놀라운 성능을 보여준다.
추가로, 인코딩된 잠재 특징이 원래 화자의 음성을 완전히 재구성할 수 있을 만큼 충분히 정보가 풍부하다는 것을 증명한다. 이는 본 논문의 방법이 다양한 작업에서 화자의 특성을 인코딩하고 재구성하는 일반적인 방법론으로 사용될 수 있음을 의미한다.
1. Introduction
최근 실세계에서 다수의 화자를 모델링하는 연구가 활발히 진행되고 있다. 이전 연구들은 학습 가능한 speaker embedding matrix를 사용하여 하나의 모델에서 각 화자의 음성 특성을 학습함으로써 다수의 화자를 모델링했다. 이는 흔히 다중 화자 음성 합성이라고 불린다.
이 방법은 각 화자의 특성을 유사하게 표현하고 화자 간 공통 정보를 공유할 수 있게 하여, 각 화자를 개별적으로 훈련시키는 것보다 상대적으로 적은 훈련 데이터로도 높은 품질의 다중 화자 음성을 합성할 수 있게 한다.
그러나 새로운 화자가 추가될 때마다 모든 화자에 대해 모델을 훈련시켜야 하며, 데이터셋이 상대적으로 작은 화자의 경우 고품질의 음성을 합성하기 어려울 수 있다. 이러한 점을 고려할 때, 이 방법을 확장하여 상당히 많은 수의 화자를 모델링하는 데에는 한계가 있다.
이러한 훈련 과정의 필요성과 한계를 완화하기 위해 fine-tuning 접근법이 사용되었다. 이 방법은 소량의 Target speaker 데이터를 사용하여 충분히 훈련된 모델을 파인튜닝한다. 그러나 이는 훈련 과정의 문제를 부분적으로만 극복할 수 있다.
훈련 접근법의 한계를 해결하기 위해 가장 활발히 연구된 방법은 zero-shot 음성 합성이다. Target speaker의 짧은 오디오로부터 얻은 speaker의 벡터를 조건으로 하여, 해당 speaker의 음성 특성과 유사한 음성을 합성한다. 이는 큰 다중 화자 데이터셋을 사용하여 speaker encoder와 음성 합성 모델을 훈련함으로써 달성된다.
Speaker의 encoder는 Target speaker의 짧은 오디오를 입력으로 받아 speaker vector를 생성하고, 이 벡터를 음성 합성 모델에 조건으로 하여 Target speaker의 음성 특성을 표현한다.
이 방법은 추가 훈련 없이 무한한 수의 speaker의에 대해 Target speaker와 유사한 음성 오디오를 합성할 수 있게 하는 것으로 보인다.
그러나 speaker의 전반적인 음성 특성을 표현하는 데에는 근본적인 한계가 있다. 인간은 주어진 콘텐츠에 따라 다양한 음색과 운율을 표현하므로, 주어진 콘텐츠에 따라 전반적인 음성 특성을 모델링하는 것이 자연스러운 음성을 합성하는 데 중요하다.
음성 오디오에서 표현되는 음색과 운율은 그 내용과 일치하며, 짧은 음성에서는 speaker의 음성 특성의 일부분만 드러난다. 따라서 짧은 참조 오디오로부터 얻은 벡터는 주어진 콘텐츠에 따라 달라지는 speaker의 음성 특성의 작은 부분만을 나타낸다.
예를 들어, "나는 정말 행복해!"와 "나는 정말 슬퍼."라는 두 문장을 생각해 보자. 두 문장을 발음하는 화자의 심리 상태는 크게 다르며, 이는 음성 특성으로 드러난다.
"나는 정말 슬퍼."라는 문장을 "나는 정말 행복해!"라는 녹음된 음성을 참조 오디오로 합성하면, 합성된 음성은 부자연스럽고 실제 speaker가 "나는 정말 슬퍼."라고 말할 때의 음성 특성과는 상당히 다르게 나타날 것이다. 밝은 음색과 운율로 합성되어 전형적인 인간 음성과는 대조될 것이다.
결과적으로, 주어진 참조 오디오에 따라 때로는 자연스럽고 유사한 음성 특성이 표현되지만, 반대로 부자연스럽고 명백히 다른 음성 특성이 자주 나타난다. 같은 이유로, 콘텐츠에 따라 다르게 표현될 수 있는 speaker의 특정 발음과 억양을 모방하는 것도 제한적이며, 이는 실제 음성과 훈련된 다중 화자 모델과는 상당히 다른 결과를 보인다.
이전 연구들은 입력 콘텐츠와 관련된 여러 특징을 사용하였지만, 이러한 방법들은 훈련된 텍스트-음성 변환 모델에서 speaker의 전반적인 음성 특성을 조건으로 하지 않으며 여전히 짧은 참조 오디오를 따르는 데 중점을 두고 있다. 따라서 근본적인 한계는 여전히 남아 있다.
또한, 이 방법은 대개 speaker 검증 작업을 위해 훈련된 speaker encoder를 사용한다. 이 방법의 일반적인 목표는 speaker들을 멀리 떨어뜨려 쉽게 구분할 수 있도록 하는 것이다.
따라서 음색이나 음성 특성이 유사한 speaker들은 실제로는 비슷함에도 불구하고 과도하게 멀리 떨어지도록 학습될 수 있으며, speaker vector를 위한 학습된 공간은 희소하고 불연속적일 수 있다.
이러한 특징들은 학습된 공간에서 음성 합성을 위해 적절한 speaker vector를 얻는 것을 제한할 수 있으며, 합성 모델은 각 벡터를 공간이 아닌 독립적인 조건으로 학습하는 경향이 있다. 이는 Target speaker와 유사한 음성 특성을 표현하는 데 실패하고 정확한 음성을 합성하는 데 실패하는 결과를 초래한다.
최근 들어 프롬프트 메커니즘을 사용하는 제로샷 음성 합성은 좋은 결과를 보여주고 있다. 이러한 연구들은 프롬프트의 음색과 운율을 보존하는 데 탁월한 능력을 입증했다.
기본 작동 원리에 따르면, 이 방법은 음성 특성을 보존하기 위해 주어진 프롬프트에 강하게 의존한다. 연구 결과 또한 합성된 음성들이 주어진 콘텐츠의 문맥보다는 프롬프트를 따라 음성 특성(음색과 운율 등)을 표현한다는 것을 확인했다.
이는 훈련 원리, 목표, 평가 방법을 고려할 때 자연스러운 결과다. 주어진 프롬프트를 가장 정확하게 따르는 방법이 그 측면에서 더 나은 성능을 나타내기 때문이다. 그러나 인간이 콘텐츠에 따라 음색과 운율을 매우 다르게 표현한다는 점을 고려할 때, 이 방법은 인간의 행동과 상당히 다르다.
이 방법은 콘텐츠에 적합한 프롬프트가 주어질 때는 유리하지만, 어떠한 콘텐츠가 주어질지 모르는 상황에서는 불리하다. 이 문제를 해결하기 위해, 화자의 전반적인 음성 특성을 인코딩하고 주어진 콘텐츠에 맞게 이러한 특성을 적절히 표현할 수 있는 방법이 필요하다.
기존 방법들의 문제를 해결하기 위해, 본 논문에서는 음성 합성을 위한 화자별 잠재 음성 특징 인코딩 방법(ELF)을 제안한다. 주요 목표는 훈련 과정 없이도 다중 화자 음성 합성처럼 주어진 콘텐츠에 따라 새로운 화자의 전반적인 음성 특성을 표현할 수 있는 방법을 제시하는 것이다.
먼저, 화자들의 음성에서 다양한 음성 특징을 밀집되고 연속적인 분포로 인코딩한다. 그런 다음, 이러한 음성 특징들을 클러스터링하여 이산화된 대표 지점을 얻는다. 다양한 인간의 음성을 관찰함으로써, 인간의 음성 특성은 이산화될 수 없다는 것을 직관적으로 확인할 수 있다.
따라서, 개별적으로 이산화된 특징을 사용하는 것만으로는 좋은 결과를 기대하기 어렵다. 본 논문에서는 Attention을 통한 가중 합이 본질적으로 벡터의 선형 결합이며, 주어진 벡터들로 형성된 연속 공간에서의 점을 샘플링할 수 있게 한다는 점에서 영감을 받았다.
따라서 Attention을 통해 이산화된 음성 특징을 콘텐츠의 숨겨진 표현에 융합하는 모듈을 설계했다. 이는 음성 합성 모델이 음성 특징 공간을 학습할 수 있게 할 뿐만 아니라, 특징들을 융합하여 주어진 콘텐츠를 자연스럽게 표현할 수 있게 한다.
ELF는 추가 훈련 없이도 Target speaker의 데이터셋으로 훈련된 다중 화자 모델에 비해 더 나은 화자 유사성, 안정성 및 동등한 자연스러움을 보여준다. 또한 zero-shot 시나리오에서 제로샷 모델을 큰 차이로 능가한다. 게다가, ELF는 우수한 speaker blending 성능을 보여준다.
이는 latent space가 화자 유사성에 따라 잘 형성되었음을 의미한다. 이를 통해 새로 생성된 인공 화자로 고품질의 음성을 합성할 수 있다. 더욱이, ELF는 인코딩된 음성 특징만으로 화자의 음성을 완전히 재구성할 수 있음을 보여준다.
이는 제안된 latent representation이 전체 Target speaker의 음성을 직접적인 콘텐츠 입력 없이도 표현할 만큼 충분히 정보가 풍부함을 의미한다. 추가적으로, ELF가 교차 언어적으로 고품질의 음성을 합성할 수 있는 능력을 가지고 있음을 증명한다.
2. Method
2.1 Overview
텍스트-음성 변환 모델이 보지 못한 화자와 주어진 콘텐츠에 따라 전체 음성 특성을 합성할 수 있게 하기 위해서는 훈련 과정에서 화자의 전체 음성 특성을 텍스트-음성 변환 모델에 조건으로 걸어야 한다.
따라서 ELF는 두 단계로 구성된다.
-
각 화자의 개별 음성 특징을 인코딩
-
인코딩된 특징을 조건으로 하여 Target speaker의 음성 특성을 표현하는 음성을 합성
ELF의 전체 구조는 그림 1과 그림 3에 나타나 있다. 다음 섹션에서 세부 사항을 설명한다.
2.2 Speech Feature Encoding
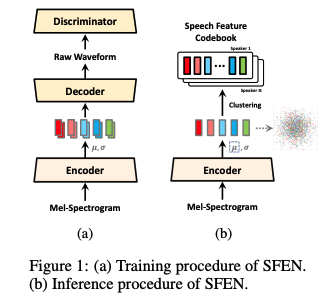
음성 합성 작업은 Target speaker의 음성 특성을 인간이 녹음한 실제 음성과 유사하고 자연스럽게 표현하는 음성을 합성하는 것을 목표로 한다. 따라서 음성 특징을 인코딩할 때 중요한 점은 원래의 음성을 높은 품질로 재구성할 수 있는 표현을 얻는 것이다.
오토인코더가 입력 데이터를 잠재 표현으로 인코딩하고 이를 디코딩하여 원래 데이터를 재구성하는 구조라는 점에서 영감을 얻어, Input mel spectogram으로부터 인코딩 및 디코딩을 통해 원시 파형을 재구성하도록 훈련된 오토인코더로 speech feature encoding network(SFEN)를 설계한다.
디코더로는 원시 파형을 재구성하는 데 우수한 성능을 보인 HiFi-GAN을 채택했다.
- Github : https://github.com/jik876/hifi-gan
- Paper : https://arxiv.org/abs/2010.05646
또한 재구성 성능을 높이기 위해 적대적 학습 메커니즘과 판별자를 도입했다.
더 나아가, 잠재 표현의 조합을 통해 학습된 공간에서 점을 샘플링할 가능성을 높이기 위해 variational 접근법 GAN을 사용하여 unit Gaussian prior에 맞췄다.
따라서 SFEN은 variational 오토인코더다. SFEN은 데이터의 무시할 수 없는 marginal log-likelihood의 변별불가능한 하한인 evidence lower bound(ELBO)를 최대화하도록 훈련된다. 이때 데이터의 marginal log-likelihood log pθ(x)는 다음과 같이 표현된다:
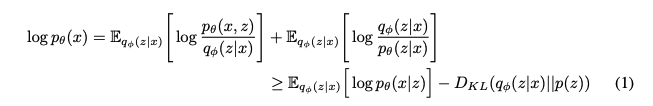
z : prior distribution p(z)에서 생성된 잠재 변수
pθ(x|z) : 데이터 점 x의 우도 함수
qϕ(z|x) : 근사 사후 분포
훈련 손실은 음의 ELBO이며, 이는 reconstruction loss - log pθ(x|z)와 KL 발산 DKL(qϕ(z|x)||p(z))의 합이다.
reconstruction loss를 Input mel spectogram s와 재구성된 파형으로부터의 mel spectogram sˆ 간의 L1 손실로 정의한다. 이는 데이터 분포를 라플라스 분포로 가정하고 상수항을 무시한 최대 우도 추정으로 볼 수 있다.
SFEN 훈련에 적대적 학습을 도입하기 위해 다음을 채택한다.
-
판별자와 손실 함수 (HiFi-GAN)
-
적대적 훈련을 위한 최소 제곱 손실 함수 (Least Squares Generative Adversarial Networks)
-
특징 일치 손실 (Autoencoding beyond pixels using a learned similarity metric)
출처 : https://nrhan.tistory.com/entry/Autoencoding-beyond-pixels-using-a-learned-similarity-metric


SFEN과 판별자의 훈련 총 손실은 다음과 같이 정의된다.
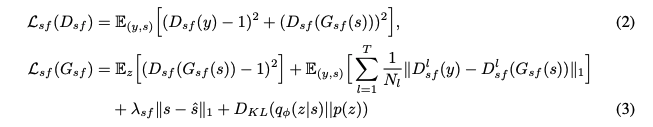
D_sf : 판별자
G_sf : SFEN
y : 실제 파형
T : 판별자의 총 레이어 수
D_l^sf : N_l개의 특징을 가진 판별자의 l번째 레이어의 출력 특징 맵
HiFi-GAN을 따라 lambda_sf = 45로 설정한다.
Speaker별 특정 음성 특징은 학습된 오토인코더 네트워크의 인코더를 사용하여 얻는다.
-
Target speaker의 오디오에서 생성된 mel spectogram을 인코더에 입력하고 출력으로 분포 매개변수인 µ와 σ를 얻는다. 이 출력은 mel spectogram과 동일한 타임 스텝을 갖는다.
-
모든 Target speaker 오디오의 µ 값을 수집하고 k-means++를 사용하여 값들을 클러스터링한다.
-
클러스터의 센트로이드를 speaker의 잠재 음성 특징 코드북으로 사용한다.
- 이러한 특징은 유한 개수의 비연속 벡터다. 그러나 이러한 벡터들은 음성 합성 모델에 조건을 걸 때 결합되어 연속 공간에서 점을 샘플링하는 것과 유사한 효과를 낳는다.
2.3 Text-To-Speech with Speech Feature Condition
음성 특징 인코딩 및 클러스터링 과정을 통해 얻은 코드북은 유한 개수의 벡터로 구성된다. 이러한 벡터들을 개별적으로 샘플링하고 사용하는 것은 합리적이지 않다. 인간의 음성 특성은 이산화될 수 없기 때문이다.
대신, 이러한 특징들을 Softmax attention score와 함께 음성 합성 모델의 중간 특징에 결합하여 추가한다. 이는 연속 공간에서 음성 특징 점을 샘플링하는 것과 유사한 효과를 준다.
본 논문에서는 이 방법을 VITS에 기반한 텍스트-음성 변환(TTS) 작업에 적용한다. 모델 내에서 다양한 포인트가 음성 특징을 조건으로 하는 후보가 될 수 있다.
특정 화자의 발음과 억양이 각 화자의 특성 표현에 크게 영향을 미치지만 입력 텍스트에 나타나지 않는 요소들을 고려하여, 결합된 음성 특징을 텍스트 인코더의 중간 특징에 융합하도록 설계한다.
-
위치 정보 없이 트랜스포머 블록을 사용하여 음성 특징 코드북의 벡터들을 결합한다.
-
이를 intermediate feature에 multi-head attention를 통해 추가함으로써 모델링에 있어서 이러한 요소들을 효과적으로 캡처할 수 있도록 한다.
인코딩된 음성 특징을 prior encoder에 조건으로 걸기 때문에, prior distribution은 VITS와 다르다.
본 논문의 설계에서 conditional prior는 다음과 같이 정의된다.
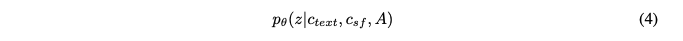
c_text : input phonemes
c_sf : target speaker의 speech feature codebook matrix
A : alignment between the phonemes and latent variables
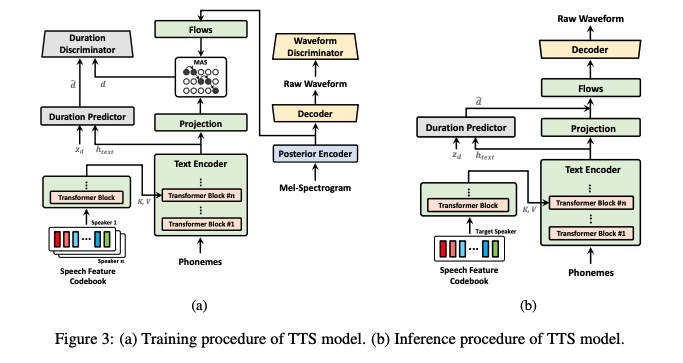
VITS의 duration predictor와 normalizing flows를 변경한다. 그림에 나타난 것처럼, 자연스러운 지속을 모델링하는 상대적으로 간단한 duration predictor를 채택한다.
Prior encoder의 출력인 텍스트의 hidden representation h_text와 Gaussian noise z_d를 생성기의 입력으로 사용한다.
또한, 로그 스케일에서 monotonic alignment search (MAS)을 사용하여 얻은 duration d 또는 duration predictor에서 예측된 d hat을 판별기의 입력으로 사용한다.
두 가지 종류의 손실을 사용한다. adversarial learning을 위한 최소 제곱 손실 함수와 평균 제곱 오차 손실 함수다.
그런 다음, 총 손실 함수는 다음과 같이 정된다.
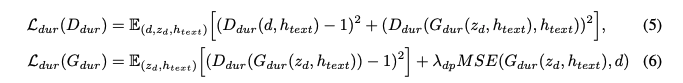
D_dur : 판별자
G_dur : 지속 예측기
또한, 분포를 변환할 때 장기적 종속성을 캡처하는 것이 중요하다. 음성의 각 부분은 인접하지 않은 다른 부분과 관련이 있기 때문이다.
따라서 장기적 종속성을 캡처할 수 있도록 잔여 연결이 있는 작은 트랜스포머 블록을 정규화 플로우에 추가한다.
2.4 Speaker Blending
2.3절에서는 Target speaker의 특성을 표현하기 위해 음성 특징 코드북과 텍스트 인코더의 중간 특징을 결합하여 융합된 특징을 얻는 방법을 설명했다.
비슷한 방식으로, 여러 화자의 특성이 공존하는 음성을 합성하는 것은 prior encoder를 수정하여 여러 화자의 intermediate feature를 특정 비율로 합하는 것을 통해 가능하다.
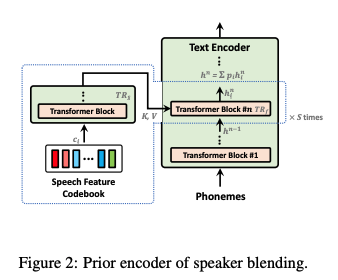
개별 화자에 대한 TTS와 유사하게
-
각 화자의 speech feature와 텍스트 인코더의 intermediate feature을 사용하여 융합된 intermediate feature을 얻는다.
-
주어진 비율에 따라 각 화자에 대한 가중치와 융합된 intermediate feature을 곱하고 이를 모두 합산한다.
그러면 다중 화자의 최종 융합된 특징은 다음과 같이 얻어진다.
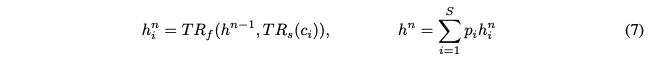
S : blending target speakers의 수
h_n : 텍스트 인코더의 n번째 transformer blocks 출력
h_n^i : i번째 스피커의 융합된 intermediate feature
c_i : codebook
p_i : blending proportion
TR_f : codebook의 벡터를 결합하는 transformer blocks
TR_s : 텍스트 인코더의 intermediate feature 과 TR_f의 출력을 융합하는 transformer block
TR_f의 Multi-head attention에서
- query : h_{n-1}
- key 및 value : TR_s의 출력
2.5 Speech Feature-To-Speech with text condition
Target speaker의 특성을 표현하는 고품질 음성을 합성하는 새로운 방법을 제안한다. Codebook의 벡터들은 target speaker의 음성을 재구성할 수 있는 latent space에서 샘플링되기 때문에, 학습된 잠재 공간이 충분히 정보를 제공하는 경우, 적절하게 결합된 음성 특징만으로 목표 스피커의 음성을 합성하는 것이 가능할 수 있다.
따라서 주어진 텍스트에 해당하는 음성을 합성하기 위해 음성 특징을 결합하는 방법을 설계한다. 2.3절의 TTS 모델의 prior encoder를 수정하여 새로운 방법을 제안한다.
-
각 트랜스포머 블록에서 speech features와 phoneme sequence로부터 intermediate feature을 얻는다.
-
Query 및 key로서 intermediate feature 간의 Multi-head attention을 계산한다.
-
Attention scores에 따라 speech feature의 가중 합을 다음 모듈의 입력으로 사용한다.
따라서 phoneme sequence에서 얻은 intermediate feature은 attention scores를 계산하는 데에만 사용된다. 이 방법은 음성 특징을 결합하는 데 필요한 정보가 있는 다양한 작업에 쉽게 확장할 수 있다.
