Paper : https://arxiv.org/abs/2303.06237
Github : https://github.com/XJ8/complement-sparsification-FL
Abstract
연합 학습(FL)은 개인 정보를 보호하는 분산 심층 학습 패러다임으로, 자원이 제한된 모바일 및 IoT 장치에 있어 상당한 통신 및 계산 노력을 필요로 한다는 문제점이 있다. 모델 가지치기/희소화는 이러한 문제를 해결할 수 있는 희소 모델을 개발하지만, 기존의 희소화 솔루션은 서버와 클라이언트 간의 양방향 통신 오버헤드가 낮고, 클라이언트의 계산 오버헤드가 적으며, 모델 정확도가 좋은 요구사항을 동시에 만족시킬 수 없다.
본 논문에서는 보완 희소화(CS)를 제안하는데, 이는 서버와 클라이언트에서 보완적이고 협력적인 가지치기를 통해 이러한 요구사항을 모두 충족하는 가지치기 메커니즘이다.
각 라운드에서 CS는 모든 클라이언트의 일반적인 데이터 분포를 캡처하는 가중치를 포함하는 글로벌 희소 모델을 생성하고, 클라이언트는 글로벌 모델에서 가지치기된 가중치로 로컬 희소 모델을 생성하여 로컬 트렌드를 캡처한다.
모델 성능을 개선하기 위해 이러한 두 종류의 보완 희소 모델을 각 라운드에서 밀집 모델로 집계한 후 반복적인 과정을 통해 가지치기한다.
CS는 서버와 클라이언트 모두에서 기본 FL보다 약간의 계산 오버헤드만 필요로 한다. 본 논문에서는 CS가 기본 FL의 근사치임을 입증하며, 따라서 모델이 잘 작동함을 보여준다. 두 가지 인기 있는 FL 벤치마크 데이터셋을 사용하여 CS를 실험적으로 평가한다. CS는 양방향 통신을 크게 줄이면서도 기본 FL과 비교할 만한 성능을 달성한다. 또한, CS는 FL을 위한 기본 가지치기 메커니즘보다 우수하다.
1. Introduction
연합 학습(FL)은 사용자의 개인 정보를 보호하는 협력적인 심층 학습 패러다임이다. 클라이언트는 개인 정보에 민감한 원시 데이터를 공유하지 않고, 로컬에서 훈련된 그라디언트만을 집계 서버에 전송한다. 전통적으로 FL은 밀집되고 과매개변수화된 심층 학습(DL) 모델을 사용한다.
실증적 증거는 이러한 모델이 확률적 경사 하강법(SGD)으로 훈련하기 더 쉽다는 것을 시사한다. 그러나 과매개변수화는 상당한 메모리, 계산 및 통신 오버헤드를 초래한다. 이는 추론뿐만 아니라 훈련도 수행해야 하는 자원이 제한된 모바일 및 IoT 장치에게 문제가 된다. 따라서, FL의 계산 및 통신 오버헤드를 줄이면서도 좋은 모델 성능을 유지하는 것이 모바일 및 IoT 장치에서 FL의 광범위한 배포를 보장하는 데 필수적이다.
이 문제에 대한 한 가지 잠재적 해결책은 모델 가지치기/희소화이다. 이는 모델 성능을 희생하지 않으면서 희소 신경망을 생성하는 것을 목표로 한다. 희소 모델은 밀집 모델에 비해 메모리 및 계산 비용이 크게 감소하며, 동일한 크기의 작은 밀집 모델보다 더 나은 성능을 발휘한다.
희소 모델은 네트워크의 일반화 능력을 향상시키고, 적대적 공격에 더 강하다(왜?) 가지치기/희소화는 FL에서도 사용할 수 있으며, 서버와 클라이언트가 협력하여 희소 신경망을 최적화하여 훈련의 계산 및 통신 오버헤드를 줄일 수 있다.
희소 모델의 이점에도 불구하고, FL을 위한 통신-계산 효율적인 모델 가지치기를 설계하는 것은 어려운 일이다.
일반적인 가지치기 메커니즘에는 세 가지 단계가 있다:
- 훈련(밀집 모델)
- 가중치 제거
- 미세 조정
일부 가중치가 제거된 모델은 추가적인 미세 조정을 통해 성능 손실을 회복해야 하므로, 미세 조정과 가중치 제거는 메커니즘의 계산 오버헤드를 나타낸다.
FL에서는 이 오버헤드를 서버에만 부과할 수 없으므로, 서버는 미세 조정을 위한 원시 훈련 데이터에 접근할 수 없다. 따라서 가지치기는 서버와 클라이언트가 협력하여 수행해야 하며, 클라이언트에 상당한 계산 오버헤드가 부과된다.
FL은 매 라운드마다 클라이언트와 서버 간에 모델 업데이트를 교환하므로, 더 작은 가지치기 모델은 더 낮은 통신 오버헤드를 초래할 것이다. 그러나 낮은 통신 오버헤드는 가지치기를 위한 계산 오버헤드와 맞바꾸는 것이다.
연합 학습(FL)을 위한 통신-계산 효율적인 모델 가지치기 메커니즘을 설계하려면 네 가지 요구사항을 충족해야 한다:
- (R1) 클라이언트에서 서버로 전송되는 로컬 업데이트 크기를 줄이는 것
- (R2) 서버에서 클라이언트로 전송되는 글로벌 모델 크기를 줄이는 것
- (R3) 클라이언트에서 가지치기 계산 오버헤드를 줄이는 것
- (R4) 기본 FL에서 밀집 모델과 비교할 만한 모델 성능을 달성하는 것
이러한 요구사항은 모두 서버가 개인 정보 보호 문제로 원시 데이터에 접근할 수 없다는 가정하에 충족되어야 한다. 기존의 FL 가지치기 연구들은 이러한 요구사항을 동시에 충족할 수 없다.
이들은 클라이언트에 상당한 계산 오버헤드를 부과하거나 클라이언트에서 서버로의 통신 오버헤드만 줄일 뿐, 반대 방향은 고려하지 않는다. 주요 미해결 문제는 이러한 요구사항들이 명백히 상충된다는 점이다.
이 논문에서는 모든 요구사항을 충족하는 연합 학습을 위한 가지치기 메커니즘인 보완 희소화(CS)를 제안한다. 주요 아이디어는 서버와 클라이언트가 추가적인 미세 조정 없이 보완적으로 희소 모델을 생성하고 교환하는 것이다.
첫 라운드는 기본 FL에서 시작하며, 클라이언트가 서버에서 집계할 밀집 모델을 훈련한다. 서버는 집계된 모델의 낮은 크기의 가중치를 제거하여 글로벌 희소 모델을 생성하고 이를 클라이언트에 전송한다.
이후 라운드에서 각 클라이언트는 서버로부터 받은 희소 모델을 훈련하고, 로컬에서 계산된 희소 모델만을 서버로 다시 전송한다. 클라이언트 희소 모델은 글로벌 희소 모델에서 원래 0이었던 가중치만 포함하여 글로벌 모델을 보완한다.
그런 다음 서버는 클라이언트 희소 모델을 이전 라운드의 글로벌 희소 모델과 집계하여 새로운 밀집 모델을 생성한다. 초기 라운드와 마찬가지로, 서버는 작은 크기의 가중치를 제거하고 새로운 글로벌 희소 모델을 클라이언트에 전송한다.
새로운 모델은 클라이언트 모델 가중치가 주어진 집계 비율로 증폭되어 다른 가중치를 넘어설 수 있도록 하여, 다른 0이 아닌 가중치 부분집합을 갖는다. 이러한 방식으로, 모델의 모든 가중치는 시간이 지남에 따라 학습하도록 업데이트된다.
CS에서는 서버와 클라이언트 모두 희소 모델을 전송하여 양방향 통신 오버헤드를 절약한다(R1 및 R2). 의도적인 미세 조정 없이 시스템에 부과되는 계산 오버헤드는 최소화된다(R3). CS에서 서버의 가지치기는 전체 데이터 분포를 포착하는 글로벌 모델을 유지하며, 새로 학습된 클라이언트 데이터 분포는 보완 가중치(즉, 글로벌 희소 모델의 0 가중치)에 위치한다.
실질적으로 클라이언트의 훈련은 추가적인 미세 조정 없이 가지치기 동안의 모델 성능 손실을 회복한다. 반복적으로 글로벌 모델의 성능이 향상된다. 궁극적으로 클라이언트는 수렴된 글로벌 희소 모델을 추론에 사용할 수 있다. 이 과정은 기본 FL에서 밀집 모델과 비교할 만한 모델 성능을 달성할 수 있다(R4).
본 논문에서는 CS가 기본 FL의 근사치임을 입증하고, 트위터 감성 분석과 이미지 분류(FEMNIST)를 위한 두 가지 인기 있는 벤치마크 데이터셋으로 CS를 평가한다. 통신 오버헤드를 정량화하기 위해 모델 희소성을 측정한다. 구체적으로 CS는 서버 모델 희소성이 50%에서 80% 사이에서 좋은 모델 정확도를 달성한다. 이 희소성은 서버에서 클라이언트로의 통신 오버헤드 감소를 나타낸다.
클라이언트는 81.2%에서 93.2% 사이의 희소성을 가진 모델 업데이트를 생성한다. 클라이언트 희소성은 클라이언트에서 서버로의 통신 오버헤드 감소를 나타낸다. CS는 기본 FL에 비해 부동 소수점 연산(FLOP)에서 29.1%에서 49.3%의 계산 오버헤드를 줄인다. 또한 실험과 정성적 분석을 통해 CS가 FL에서 모델 정확도와 오버헤드 측면에서 기존의 기본 모델 가지치기 메커니즘보다 우수함을 입증한다.
2. Related Work
모델 가지치기는 구조적 가지치기와 비구조적 가지치기로 분류될 수 있다. 중앙 집중 학습을 위한 모델 가지치기에 관한 많은 문헌이 있다. 이러한 방법들은 계산 비용이 많이 들고, 전역 데이터 분포를 대표하는 데이터셋이 필요하다. 따라서, 원시 데이터를 서버와 공유하지 않는 FL에서는 실용적이지 않으며, 자원이 제한된 모바일 및 IoT 장치에서는 사용하기 어렵다.
반면, CS 모델 가지치기는 자원 제한 장치에서의 FL을 위해 설계되었다. 중앙 집중 데이터셋을 필요로 하지 않으며, 계산 효율성을 위해 명시적인 미세 조정을 제거한다. CS는 FL에서 비구조적 가지치기를 적용하는데, 이는 FL 훈련 라운드 동안 다양한 중요한 가중치를 업데이트할 수 있는 자유를 제공하며, 따라서 더 나은 성능을 달성한다.
최근 문헌에는 FL을 위한 모델 가지치기에 관한 여러 연구가 포함되어 있다.
-
Han, Wang, and Leung (2020)는 그래디언트 희소성을 통해 통신과 계산의 근사 최적화 트레이드오프를 결정하는 온라인 학습 접근 방식을 제안했다.
-
Liu et al. (2021)은 모델 가지치기를 적용하여 수렴 속도를 최대화한다.
-
PruneFL (Jiang et al. 2022)은 모델 크기를 조정하여 "가장 빠르게" 학습하는 최적의 모델 파라미터 집합을 찾는다.
-
FL-PQSU (Xu et al. 2021)는 구조적 가지치기, 가중치 양자화 및 선택적 업데이트의 3단계 파이프라인으로 구성된다.
-
Yu et al. (2021)은 추론 가속화를 위해 데이터셋 인식 동적 가지치기를 적용하는 적응형 가지치기 방식을 제안한다.
-
SubFedAvg (Vahidian, Morafah, and Lin 2021)에서는 클라이언트가 가지치기를 통해 작은 서브네트워크를 사용한다.
이들 연구는 대부분 기본 FL과 비교할 만한 모델 정확도를 달성하고, 클라이언트가 서버에 로컬 업데이트를 전송할 때 통신을 절약하지만, 추가 최적화나 가지치기에서 발생하는 성능 손실 회복을 위해 클라이언트에 상당한 계산 오버헤드를 부과한다.
CS에서는 클라이언트에서의 가지치기 계산 오버헤드가 매우 낮은데, 이는 클라이언트의 유일한 작업이 이전 글로벌 희소 모델에서 0이 아니었던 가중치를 제거하는 것이기 때문이다. 이 낮은 오버헤드 덕분에 CS는 자원이 제한된 장치에서 실용적이다.
지금까지 언급된 연구들은 모델 가중치를 가지치기하지만, 다른 연구들은 클라이언트에서 모델의 뉴런을 제거하는 방법을 선택한다.
-
장치 이질성에 대처하기 위해 Ordered Dropout (OD)은 클라이언트가 원본 네트워크의 서브네트워크를 순서대로 훈련하도록 한다. 그러나, OD는 서버에서 클라이언트로의 통신을 절약할 수 없다.
-
FedDrop에서는 서버에서 드롭아웃을 사용하여 이질적인 드롭아웃 비율로 글로벌 모델에서 서브넷을 무작위로 생성하고, 클라이언트는 서브넷만 훈련하여 서버로 전송한다. 이 연구는 양방향 통신을 절약하지만, 기본 FL과 비교하여 모델 정확도가 떨어진다. CS는 양방향 통신 오버헤드를 줄일 뿐만 아니라, 기본 FL과 비교할 만한 성능을 달성한다.
가지치기 외에도 FL에서 오버헤드를 줄이는 다른 방법들이 있다.
-
Karimireddy et al. (2020)와 Wang et al. (2019)의 연구는 통신 빈도를 최적화한다.
-
LotteryFL (Li et al. 2020)은 클라이언트가 학습한 개인화된 로터리 네트워크를 통신한다.
-
Ozkara et al. (2021)은 손실 함수를 조작하여 FL에서 개인화된 압축을 위해 양자화 및 증류를 사용한다.
-
Lin et al. (2018)에서는 클라이언트가 큰 그래디언트만 집계하여 전송하고 작은 그래디언트는 충분히 커질 때까지 로컬에 누적한다.
이러한 방법들은 희소 모델 사용의 모든 이점을 누릴 수 없는데, 예를 들어 더 나은 일반화 성능과 미지의 데이터에 대한 모델 성능 유지, 그리고 적대적 공격에 대한 높은 강인성 등이다. 이 방법들은 서로 다른 클래스의 모델 압축에 속하므로, 이들을 CS와 비교하지 않는다.
3. Complement Sparsification in FL
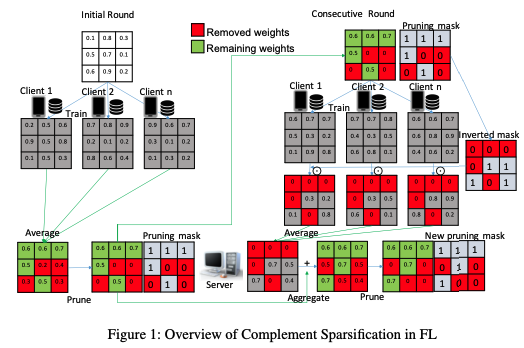
보완 희소화(CS)의 목표는 서버와 클라이언트 간의 양방향 통신 오버헤드를 줄이고, 시스템에 최소한의 계산 오버헤드를 부과하며, 좋은 모델 성능을 달성하는 것이다.
초기 라운드
-
클라이언트 : 랜덤 가중치로부터 학습하고, 그들의 밀집 모델을 서버로 보낸다.
-
서버 : 집계 후 모델 가중치의 일부를 작은 값으로 가지치기하고, 글로벌 희소 모델을 클라이언트에게 보낸다.
가지치기 마스크도 함께 전송되어 가지치기된 가중치를 표시한다. 마스크에서 0은 가중치가 제거되었음을, 1은 가중치가 남아있음을 의미한다.
다음 라운드
-
클라이언트 : 학습 후 글로벌 희소 모델의 역마스크를 적용하고 그들의 희소 모델을 다시 서버로 보낸다.
-
서버 : 이전 라운드의 글로벌 희소 모델과 클라이언트 모델을 집계하여 완전한 밀집 모델을 생성한다.
새로운 밀집 모델에서는 작은 값의 가중치가 가지치기되고, 이전 라운드와 다른 새로운 가지치기 마스크를 가진 새로운 글로벌 희소 모델이 생성된다.
클라이언트 모델의 가중치는 주어진 집계 비율로 증폭되어 다른 가중치를 넘어서게 된다.
모델의 정확도는 시간이 지남에 따라 향상된다. CS는 미세 조정을 필요로 하지 않으므로, 계산 오버헤드는 단지 일부 가중치를 제거하는 정도다. 또한 서버와 클라이언트 모두 희소 모델을 전송하므로 양방향 통신 오버헤드가 크게 줄어든다.
3.1 Preliminaries
CS를 공식화하기 위해, 먼저 FL의 공식화를 시작한다. FL은 글로벌 경험적 손실 F(w)를 최소화하는 모델 가중치 w를 찾는 분산 딥러닝 시스템이다:
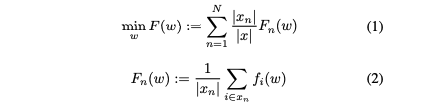
𝐹_𝑛(𝑤) : 각 클라이언트 𝑛의 로컬 경험적 손실
𝑥_𝑛 : 클라이언트 𝑛의 로컬 데이터셋
∣𝑥_𝑛∣ : 클라이언트 𝑛의 데이터셋 크기
∣𝑥∣=∑∣𝑥_𝑛∣ : 모든 클라이언트의 데이터셋 크기
f_𝑖(𝑤) : 주어진 클라이언트의 주어진 데이터 샘플 𝑖에 대한 손실 함수
각 클라이언트 𝑛은 매 라운드마다 로컬 데이터에서 학습한다:
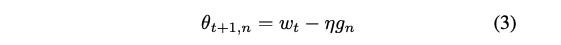
𝜃 : 현재 로컬 모델
𝑤𝑡 : 이전 라운드의 글로벌 모델
𝜂 : 학습률
𝑔𝑛=∇𝐹𝑛(𝑤𝑡) : 로컬 데이터에서의 𝑤𝑡의 평균 그래디언트
이 단계는 다른 데이터 배치와 함께 여러 번 반복될 수 있으며, 전체 데이터셋에 걸쳐 반복된다.
모든 클라이언트가 매 라운드마다 집계에 참여한다고 가정한다. 서버는 다음의 식 (4) 또는 (5)와 같이 클라이언트의 학습 결과를 집계한다.
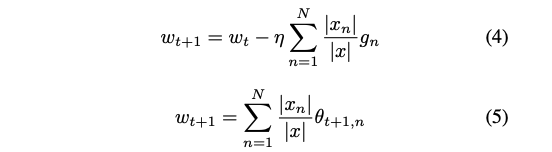
식 (4)와 (5)는 (3) 때문에 동일하다. 식 (4)에서 서버는 클라이언트 학습률 𝜂와 다른 학습률 𝜂를 사용할 수 있다.
3.2 CS Workflow
초기 라운드
CS는 기본 FL에서 시작한다. 집계된 가중치 w_t+1는 Pruning 함수 (w'_t+1, mask) = Prune(w_t+1)을 갖는 서버에 의해 프루닝된다. Pruning 함수는 어떠한 의도한 fine-tuning 없이 낮은 크기의 가중치를 제거한다. 이는 낮은 오버헤드를 위한 것이다.
Pruning된 모델 w'_t+1과 pruning mask는 다음 라운드를 위해 클라이언트에게 전송된다. Pruning 마스크는 이진 텐서로 w'_t+1이 0으로 설정된 위치를 나타내는 이진 텐서다.
연속 라운드
새로운 라운드에서 각 클라이언트 𝑛은 서버로부터 가지치기된 모델 w't를 전달받고, 로컬 데이터 x_n에서 학습하여 새로운 로컬 모델 𝜃_t+1,n을 생성한다:
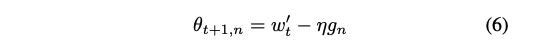
그런 다음, 클라이언트는 역 비트 마스크 ¬mask를 계산하고 𝜃_t+1,n과 ¬mask에 element-wise product를 적용한다:
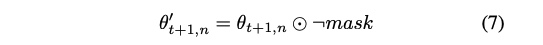
통신 오버헤드를 절약하고 서버에서 클라이언트로 마스크를 전송하지 않으려면 사소한 계산 오버헤드를 희생하면서 클라이언트가 직접 w't에서 ¬mask를 도출할 수 있다.
서버는 클라이언트로부터 보완 희소화된 가중치 𝜃'_t+1,n 을 수신하고, 이전 라운드의 w'_t 및 집계 비율 𝜂'과 함께 이를 집계한다:
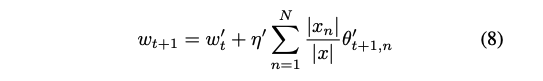
그런 다음 서버는 이전 라운드의 프로토콜을 반복하며, CS 작업 흐름은 반복적으로 계속된다.
3.3 Algorithmic Description
다음은 CS의 의사코드를 보여준다.

CS는 다중 라운드, 반복 FL 주기로 실행된다 (4-14행). 여기에는 클라이언트가 데이터 배치를 사용하여 수행하는 로컬 모델 업데이트 (16-20행), 로컬 모델의 보완 희소화 (21행), 서버 집계 (9-12행), 글로벌 모델 가지치기 (13행)가 포함된다.
글로벌 모델을 가지치기하기 위해, 작은 값의 가중치를 제거하고 (26-29행) 0인 가중치를 마스킹하는 이진 텐서를 생성한다 (30-33행).
3.4 Technical Insights
FL에서 클라이언트는 로컬 데이터를 적합화한 모델을 생성하고, 서버의 집계는 클라이언트 모델의 노이즈를 평균화하여 글로벌 데이터를 적합화한 글로벌 모델을 생성한다. 다시 말해, 클라이언트와 서버는 상호 보완적인 관계에 있다.
각 라운드마다 클라이언트는 글로벌 모델을 방해하여 로컬 데이터 분포를 더 잘 따르게 하고, 서버는 클라이언트 모델을 조정하여 글로벌 데이터 분포를 포착한다. CS는 이러한 통찰을 활용하여 각각 서버와 클라이언트에서 보완 희소 모델을 생성한다. 이렇게 하면 계산 및 통신 오버헤드를 줄이면서도 좋은 모델 성능을 달성할 수 있다.
CS에서는 서버가 집계된 밀집 모델에서 희소 모델을 추출한다. 이 희소 모델은 글로벌 데이터 분포를 유지한다.
서버가 희소 모델을 미세 조정하지 않더라도, 클라이언트는 암묵적으로 미세 조정을 수행한다. 클라이언트는 로컬 데이터 분포를 학습하고, 로컬과 글로벌 분포 간의 변화를 반영한 클라이언트 희소 모델을 생성한다.
업데이트는 글로벌 희소 모델 가중치의 보완 집합(즉, 이전에 0이었던 가중치)에 더 쉽게 반영된다. 따라서 클라이언트는 식 (7)과 같이 모델을 보완 희소화하고, 중요한 모델 업데이트만 서버에 전송하여 낮은 통신 오버헤드를 유지한다. 이 과정은 클라이언트의 로컬 데이터로 인해 글로벌 희소 모델의 0이 아닌 가중치가 과적합되는 것을 피할 수 있다.
계산 오버헤드는 대부분 서버에 부과되며, 클라이언트는 역 가지치기 마스크를 적용하는 것뿐이다. 정확한 모델을 위해 모든 가중치가 시간이 지남에 따라 업데이트되도록 하려면, 각 라운드마다 CS는 완전한 밀집 모델을 생성하고 이전 라운드와 다른 가지치기 마스크를 생성해야 한다.
이는 식 (8)과 같이 t+1 라운드의 클라이언트 모델의 보완 가중치를 t 라운드의 글로벌 모델 가중치와 집계하여 달성된다. 구체적으로, 새로운 집계된 모델 가중치는 글로벌 희소 모델 가중치와 클라이언트 가중치의 가중 합을 더하여 계산된다.
서버는 상수 집계 비율 𝜂' > 1 을 사용하여 이전 라운드에서 가지치기된 가중치가 다른 가중치를 초과하도록 보장한다. 이는 현재 라운드에서 가지치기될 가능성을 줄인다. 일부 클라이언트 업데이트가 항상 작아 서버에 의해 제거되는 경우, 훈련은 더 높은 𝜂'를 사용할 수 있지만, 그래디언트 폭발을 방지하기 위해 1/𝜂 보다 높지 않아야 한다 (섹션 3.5 참조).
3.5 Algorithm Analysis
CS가 실제로 성능 면에서 vanilla FL의 근사치임을 보여주기 위해, CS(8)에서 vanilla FL(4)의 집계 함수를 다음과 같이 유도한다.
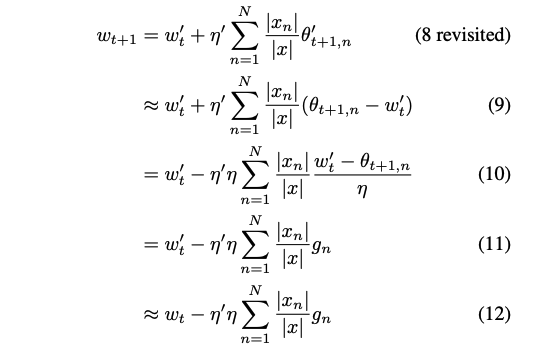
식 (9)는 θ'_t+1,n ≈ θ_t+1,n − w'_t에서 나온다. 이는 로컬에서 학습된 클라이언트 모델 θ_t+1,n이 이전 글로벌 희소 모델 w_t′ 와 주로 w_t′ 의 0 가중치에서 차이가 나기 때문이다.
θ_t+1,n − w'_t는 w'_t의 0이 아닌 가중치를 0으로 설정하여 (7)의 θ_t+1,n * ¬mask와 유사하다. 식 (10)은 합에서 −η를 빼내어 유도된다. 식 (11)은 (10)에서 (6)을 사용하여 유도된다. 최종 결과인 식 (12)은 가지치기된 가중치 w'_t가 가지치기 전의 가중치 w_t를 근사하기 때문에 작은 크기의 가중치만 차이가 난다.
식 (12)와 (4)를 비교해보면, 서버는 η'η를 학습률로 적용한다. 집계 비율 η'는 클라이언트 학습률에 대한 서버 학습률 비율로, 서버 학습률을 클라이언트 학습률에 맞추기 위해 사용된다. 실제로 학습률은 일반적으로 0과 1 사이에서 선택되므로, η'는 1과 1/η 사이에서 선택되어 w'_t을 초과하도록 하면서도 w_t+1 의 폭발을 방지해야 한다.
글로벌 희소 모델 vs. 집계된 밀집 모델
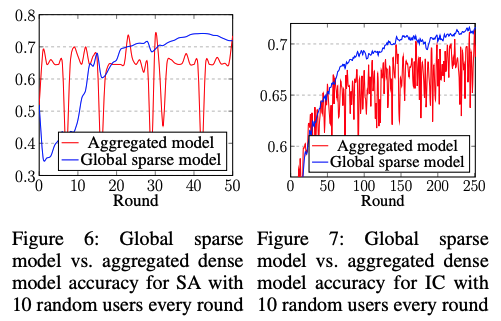
그림 6과 7은 SA 및 IC 모델에서 CS의 글로벌 희소 모델과 집계된 밀집 모델(각 라운드에서 희소화 이전 모델) 간의 비교를 보여준다.
전체적으로 글로벌 희소 모델은 부드러운 학습 곡선을 나타내며 집계된 모델보다 성능이 뛰어나다. 이는 CS에서 통신 오버헤드를 줄이고 낮은 크기의 가중치를 제거하여 모델 성능을 유지하는 저오버헤드 모델 가지치기의 효과를 입증한다.
CS에서는 집계된 모델이 글로벌 분포를 캡처할 뿐만 아니라 클라이언트 데이터에서 유도된 잡음 분포 변이에 의해 오염된다. 각 라운드에서 새로 집계된 모델에서 낮은 크기의 가중치를 제거하는 것만으로도 잡음 분포 변이를 효과적으로 제거할 수 있으며, 글로벌 희소 모델은 글로벌 데이터 분포를 안정적으로 학습할 수 있다.
서버 모델 희소성과 모델 정확도
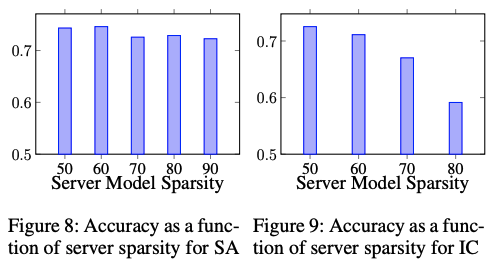
그림 8과 9는 SA와 IC 모델에서 서버 모델 희소성에 따라 모델 정확도가 어떻게 변하는지를 보여준다. 서버 모델 희소성은 모델마다 다르게 설정할 수 있는 파라미터로, 시스템 운영자는 모델 정확도와 통신/계산 오버헤드 감소 간의 원하는 균형을 달성할 수 있다.
일반적으로 서버 모델 희소성이 낮을수록 모델 성능이 더 좋다. SA의 경우, 희소성이 90%이어도 성능이 좋으며(50% 희소성과 비교하여 정확도 저하가 2%에 불과), IC의 경우 희소성을 최대 70%로 유지해야 수용 가능한 성능을 달성할 수 있다.
Conclusion
자원 제약이 있는 장치에서 FL의 채택을 돕기 위한 실용적인 모델 가지치기 기법인 Complement Sparsification (CS)을 제안한다. CS에서 서버와 클라이언트는 오버헤드를 줄이면서 좋은 정확도의 모델을 구축하기 위해 밀집 모델의 희소하고 상보적인 부분 집합을 생성하고 교환한다. CS는 클라이언트와 서버 간의 협력을 통해 가지치기된 모델을 암묵적으로 미세 조정한다.
희소 모델은 적은 계산 노력으로 생성된다. CS는 Vanilla FL의 근사치임을 증명했다. 실험적으로 CS는 텍스트 및 이미지 응용 프로그램에 대한 두 가지 인기 있는 벤치마크 데이터셋으로 평가된다. CS는 최대 93.2%의 통신 절감과 49.3%의 계산 절감을 달성하면서 Vanilla FL과 유사한 성능을 보였다. CS는 모델 정확도와 오버헤드 측면에서 베이스라인 모델보다 뛰어난 성능을 발휘한다.
