[Capstone #9] Sound Design Strategies for Latent Audio Space Explorations Using Deep Learning Architectures
Capstone
Paper : https://arxiv.org/abs/2305.15571
Github : https://github.com/ktatar/rawaudiovae?tab=readme-ov-file
Abstract
VAEs는 데이터 포인트가 유사한 데이터 포인트가 서로 가깝게 위치하도록 조직된 latent spaces을 생성하는 데 사용된다. 이전에 VAE는 음색 또는 상징적 음악 단편의 latent spaces을 생성하는 데 사용되었다.
VAE를 음색의 오디오 특징에 적용하려면 네트워크에 의해 생성된 음색을 오디오 신호로 변환하기 위한 보코더가 필요하며, 이는 계산 비용이 많이 든다.
본 연구에서는 오디오 특징 추출을 우회하면서 raw audio 데이터에 VAE를 직접 적용한다. 오디오 신호 생성에 소요되는 낮은 계산 시간으로 인해 raw audio 접근 방식을 실시간 응용 프로그램에 통합할 수 있다. 본 연구에서는 음향 디자인 응용을 위한 오디오와 음색의 잠재 공간을 탐색하기 위한 세 가지 전략을 제안한다.
1. Introduction
딥러닝의 오토인코더 및 ML의 UMAP, t-SNE 또는 k-means 클러스터링과 같은 아키텍처는 데이터 세트 내의 데이터 포인트 간의 거리를 계산하여 유사한 데이터 포인트가 조직된 추상적인 공간을 만든다. 이러한 추상적인 공간은 'latent spaces’라고 한다. 본 연구는 latent audio spaces에 초점을 맞춘다.
본 논문의 접근 방식은 오디오 녹음을 잠재 오디오 공간을 탐색하는 도구로 활용하는 전략을 만드는 것이다. 두 개의 오디오 녹음 사이의 잠재 오디오 공간을 탐색하기 위한 비교적 간단한 수단을 제공한다.
Variational Autoencoders에 의해 생성된 latent audio spaces를 탐색하기 위해 알고리즘적 접근 방식을 활용한다. 세 가지 latent audio spaces 보간 전략을 제안한다. 상대적으로 짧은 오디오 샘플 데이터셋을 사용하여 긴 기간의 작곡 층을 생성하는 것을 목표로 한다.
2. Related work
본 논문은 다양한 딥 러닝 아키텍처를 활용하는 유사한 연구들의 맥락 안에 위치하고 있다. WaveNet 및 VAEs를 사용한 오디오 생성 및 딥러닝 방법과의 미분 가능한 디지털 신호 처리(DDSP)의 통합 등의 작업이 있다.
2.1 Timbre based approaches
이전 연구에서는 신경망을 사용하여 실시간으로 오디오를 합성하기 위해 CNN과 WaveRNN 보코더를 결합하는 구현을 조사했다.
-
입력을 보강하고 latent spaces 탐색에 영향을 미치기 위해 크로마 벡터를 사용한 응용
-
Constant Q-Transform (CQT)을 사용한 음색 전이
-
VAEs를 사용한 latent timbre 합성
CNN 음색 합성을 WaveRNN 기반의 autoregressive vocoder와 결합하여 파이프라인을 음높이와 음량 제어로 조건부로 만들었다. 음색 합성 및 보간을 위해 VAE를 사용하며, 원-핫 인코딩된 크로마 벡터를 사용하여 생성을 안내한다.
조건부 오디오 합성을 위한 GAN을 사용한다. MelGAN 아키텍처를 제시하며, 이는 웨이브폼 생성을 수행하는 non-autoregressive convolutional 아키텍처로, MFCC 스펙트로그램으로부터 원시 오디오 생성을 위해 훈련된 GAN이다.
2.2 Audio generation, WaveNet, and beyond
WaveNet은 원시 오디오 생성에 사용되는 autoregressive DNN이다. PixelCNN 아키텍처를 기반으로 하며, 인과적인 convolutional 레이어의 스택을 활용한다. Convolution 레이어의 확장을 사용하여 모델이 미래 시간 단계에 대한 의존성을 제한하며 오디오 입력의 해상도를 보존한다.
WaveNet의 특별한 특성 중 하나는 기존의 TTS 시스템을 능가하는 정확성으로, 오디오 모델링과 음성 인식에서 유망한 결과를 얻었다.
The challenge of realistic music generation는 자기 회귀형 오토인코더(ADAs)를 사용하여 원시 오디오의 생성을 조사하며, argmax 오토인코더 (AMAE)를 벡터 양자화 변이형 오토인코더 (VQ-VAE)와 비교하여 오디오 웨이브폼의 장거리 상관 관계를 포착했다.
WaveNet 및 이와 관련된 아키텍처의 주요 단점은 상대적으로 높은 계산 복잡성으로, 이는 이러한 아키텍처를 실제 예술적 실천에 통합하는 데 장벽이 된다.
다중 모달 도메인 전이 관점에서 오디오 생성에 접근하는 경우, Raw Music from Free Movements는 댄스 포즈 시퀀스를 오디오 웨이브폼으로 변환하며, seq-to-seq 모델과 adversarial autoencoder를 결합한 딥 러닝 아키텍처를 활용한다.
RAMFEM은 원시 오디오 도메인에서 기존의 음악-움직임 관계를 학습하고 재현한다. 이 파이프라인은 두 개의 오토인코더를 결합하며, 인간의 몸 포즈 공간을 생성하기 위한 RNN 기반의 seq-to-seq 네트워크와 latent audio spaces를 생성하기 위한 VAE가 포함된다.
본 논문에서 제시된 아키텍처는 RAMFEM의 Adversarial VAE를 기반으로 구축되었다. RAMFEM의 오디오 VAE는 Adversarial VAE 파이프라인 내에서 판별자 네트워크를 사용하지만, 본 논문에서 제시된 아키텍처는 더 단순화된 VAE 파이프라인을 위해 판별자 네트워크를 제외한다.
2.3 Differentiable DSP
DDSP는 디지털 신호 처리를 딥 러닝 프레임워크에 통합하여 고품질의 오디오를 생성하기 위해 미분 가능한 합성 블록 및 보코더의 모듈 시스템을 활용했다.
그들은 DDSP 구성 요소를 활용하는 모델의 모듈성을 보여주며, 추가 오디오 기능(음고 및 음량 제어, 방 음향의 모델링 및 이전)에 대한 독립적인 제어; 서로 다른 악기 간의 음색 전이; 그리고 합성 중에 새로운 음고 자료로의 추출을 가능하게 한다.
3. TWO TYPES OF LATENT AUDIO SPACES
3.1 Continuous Latent Audio Spaces
Continuous latent audio spaces는 변이형 오토인코더(VAE)와 같은 다양한 기계 학습 접근 방식을 사용하여 오디오를 잠재 공간으로 인코딩한다. 이러한 유형의 잠재 오디오 공간에서 입력은 수천 개의 샘플을 포함하며, 소수 초의 지속 시간을 가진 오디오 윈도우다.
연속적인 잠재 오디오 공간은 소리 제스처 또는 오디오 샘플을 잠재 공간 안의 연속적인 경로로 인코딩한다. 각 지점은 하나의 오디오 창으로부터 인코딩된다.

이 때, 빨간 원은 1024개의 샘플을 가진 오디오 창을 나타내며, 이러한 원들이 VAE를 사용한 잠재 오디오 공간 접근의 특성으로 나타난다. 따라서 빨간 선은 소리 제스처의 연속적인 잠재 오디오 공간 인코딩이다.
오토인코더(AE)는 원래 데이터 인스턴스를 압축하고 다시 구성하여 낮은 차원 표현으로 변환하는 방법을 학습하는 신경망이다. AE는 두 개의 네트워크로 구성되어 있다. 고차원 입력 데이터를 잠재 부호로 변환하는 인코더와 잠재 부호를 가능한 정확하게 재구성하는 디코더다. 이 작업을 수행하기 위해 오토인코더는 데이터를 효율적으로 잠재 부호로 압축하는 것을 학습한다.
일반적인 오토인코더(AE)에서는 인코더가 데이터 인스턴스를 직접 결정론적 부호로 변환한다.
이 접근 방식은 두 가지 주요 단점이 있다:
-
인코더에 의해 생성된 잠재 공간은 희소하게 분포되어 있고 인코딩을 의미 있는 데이터 인스턴스로 디코딩할 수 없는 영역이 많이 포함되어 있다.
-
데이터 공간의 유사성 측정치가 잠재 공간에 보존되지 않는다. 즉, 비슷한 데이터 인스턴스의 인코딩이 잠재 공간 내에서 서로 가깝게 위치하지 않을 수 있다. 이 두 가지 단점으로 인해 일반적인 AE에서 유효한 데이터 인스턴스로 디코딩될 수 있는 인코딩을 검색하는 것이 어렵다.
변이형 오토인코더(VAE)는 잠재 공간을 덜 희소하게 만들고 원래 데이터 공간과 유사한 유사성 측정치를 부과함으로써 이러한 단점을 완화한다. AE와 달리 VAE의 인코더는 데이터 인스턴스를 확률 분포의 매개변수로 매핑하여 잠재 코드를 샘플링할 수 있다.
인코더는 p(z|x)를 근사하고, 디코더의 기능은 x가 입력 데이터이고 z가 해당 입력 데이터를 나타내는 잠재 벡터임을 고려할 때 사후확률 p(x|z)의 확률을 최대화하는 것이다.
VAE는 z가 확률 분포인 것으로 가정하며, 평균이 µ이고 표준 분산이 σ인 일반적인 분포 함수 N (µ, σ)를 사용하여 z를 샘플링한다. 그러나 샘플링 함수는 미분 가능하지 않다. VAE는 확률 분포에서의 확률적 샘플링을 통해 그래디언트가 역전파될 수 없는 문제를 우회하기 위해 reparameterization trick을 사용한다.
이 트릭은 랜덤 변수의 샘플링을 결정론적 변수와 표준 정규 분포에서 샘플링된 요소 엡실론의 조합으로 표현한다. 구체적으로, 인코더는 µ 및 σ의 두 벡터를 출력하며, 이는 분포 함수로 전달된다. 인코더는 f(x) ∈ F 인 f와 g(x) ∈ G 인 g를 사용하여 q∗(z|x) = N (z; f(x), g(x)2I)를 모델링함으로써 p(z|x)를 모델링한다.
여기서 µM = f(x), f ∈ F, σM = g(x), g ∈ G이고 M은 잠재 공간에서의 차원 수다. 디코더의 입력인 z는 q(z) = N (z; f(x), g(x)2I)에서 샘플링된다. VAE의 손실 함수는 기대값 최대화와 Kullback-Leibler 발산의 정규화 항 두 가지를 포함한다.
VAE는 유효한 데이터 인스턴스를 생성하는 확률을 최대화하면서 사후분포 q∗(z|x)가 사전분포 p∗(z)에 가깝도록 강제하여 훈련된다. 이 두 분포 간의 유사성은 일반적으로 Kullback-Leibler 발산을 사용하여 양자화된다. 식 (1)에서와 같다. RawAudioVAE의 전체 파이프라인은 그림 1에 나와 있다. 섹션 5에서 다루는 특정 VAE 모델은 학습률이 10e−4이고 α가 10e−4인 500번의 epoch 동안 훈련된다.
3.2 Discrete Latent Audio Spaces
이산적인 잠재 오디오 공간은 연속적인 잠재 오디오 공간과 비교할 때, 몇 초의 지속 시간을 가진 소리 제스처를 조직화한다. 훈련 데이터셋의 오디오 샘플들은 종종 일련의 오디오 특징을 사용하여 섬네일로 만들어진다.
음악 정보 검색에서 오디오 섬네일링의 널리 알려진 접근 방식은 프레임의 평균과 표준 편차가 오디오 발췌물이나 샘플 전체에 걸쳐 계산되는 bag-of-frames 접근 방식이다. 이러한 오디오 특징의 통계 결과는 전체 오디오 샘플을 나타내는 하나의 벡터로 결합된다.

이산 잠재 오디오 공간을 생성하는 기계 학습 접근 방식은 오디오 섬네일 벡터와 이러한 벡터 사이의 거리를 사용하여 오디오 샘플을 latent space에 구성한다.
audiostellar와 같은 경우, 잠재 공간의 각 점은 하나의 오디오 샘플을 나타낸다. 다른 기계 학습 접근 방식인 Self-Organizing Maps에서는 각 사각형이 오디오 샘플의 클러스터를 나타낸다.
4. Strategies for exploring latent spaces of audio
음성의 잠재 공간을 탐색하기 위한 세 가지 전략을 제시한다. 이러한 매개변수 공간을 오디오 합성에 어떻게 활용할 것인지에 대한 문제는 아직 조사되지 않았다.
현재는 잠재 공간의 특성 및 음악적 품질 및 음향 미학을 고려한 잠재 오디오 공간의 분석 방법에 대한 지식이 여전히 부족하다. 이러한 잠재 공간을 분석하는 수학적 방법은 아키텍처, 하이퍼 파라미터 최적화를 배우고 모델 훈련에서 문제점을 파악하는 데 유용하지만, 잠재 오디오 공간의 미적 가능성에 대한 지침을 제공하지는 않는다.
잠재 오디오 공간의 음향적 특성과 미학을 드러내는 방법에 대한 지식이 아직 부족하다. 이러한 지식은 예술가와 실무자들이 실제 예술적 응용 프로그램에서 중요한 매개 변수 공간을 활용하는 데 도움이 될 수 있다.
또한, 잠재 음향 공간의 음향 미학을 조사하기 위한 명확한 방법이 부족하며, 음악적 품질에 대한 명시적인 분류 체계도 없다.
VAE가 추가적인 차원으로 조건이 지정된 접근에 집중하는 대신, 본 논문의 접근 방식은 두 가지 선택된 소리 사이의 잠재 소리 공간을 탐색하는 데 초점을 맞추고 있다.
오디오 입력을 사용하여 잠재 오디오 공간을 탐색하는 것은 다양한 음악적 맥락과 문화에서 다양한 미학을 탐구할 수 있는 유연성을 제공한다. 이렇게 함으로써 음악적 차원을 조건으로 설정하는 것을 회피하면서도 잠재 공간 탐색을 안내할 수 있다.
아래 세 가지 전략은 두 오디오 입력 파일을 사용하여 해당 두 파일 사이의 잠재 공간을 탐색한다. 오디오 입력은 동일한 지속 시간을 갖도록 설정된다. 오디오 입력은 잠재 공간 탐색의 미학을 제한한다. 모든 방법에서 입력 파일은 VAE 인코더를 사용하여 잠재 벡터를 생성한다.
오디오 파일은 먼저 창화되고 VAE 입력은 1024개의 샘플로 이루어진 단일 오디오 창이다. 각 오디오 창은 별도로 인코딩된다. 이 비자기 회귀적 접근 방식은 계산 복잡성을 크게 감소시키고 동시에 실시간 구현을 가능하게 한다. 보간은 오디오 입력 파일의 잠재 벡터 쌍 사이에서 잠재 벡터를 생성함으로써 수행된다.
4.1 Stepwise Interpolations

첫 번째 방법은 타임라인 전체에 걸쳐 고정된 보간량을 사용한다. 즉, 알고리즘 1의 12번째와 13번째 줄에 있는 's'는 상수로, 벡터가 아니다.
이 방법에서는 몇 초간의 짧은 오디오 샘플을 사용한다. 선택한 두 오디오 파일 중 더 긴 파일을 우선하여 단축하여 두 파일이 동일한 지속 시간이 되도록 한다. 두 오디오 파일 모두 동일한 수의 오디오 윈도우를 가져야 한다.
VAE는 각 오디오 윈도우를 잠재 공간에서 평균이 µ이고 표준 편차가 σ인 정규 분포 N (µ, σ)로 표현한다. 각 오디오 윈도우는 잠재 벡터를 생성하기 위해 VAE 인코더를 통과된다. 인코더는 각 오디오 윈도우당 두 개의 벡터를 출력하며, µ용 벡터와 σ용 다른 벡터다. 각 벡터는 잠재 공간 차원의 크기다. 여기서는 256 차원이다.
평균과 표준 편차 쌍은 정규 분포 함수로 전달된다(알고리즘 1의 14번째 줄). 정규 분포의 사용은 reparameterization trick이라고 불리며, 훈련 데이터셋에서 두 오디오 파일의 잠재 벡터 사이의 잠재 벡터를 탐색하여 새로운 소리를 합성할 수 있다.
알고리즘 1의 후반부에서는 간단한 그리드 탐색을 사용하여 보간량을 적용한다. 각 보간량에 대해 새로운 잠재 벡터가 12번째와 13번째 줄의 공식을 사용하여 생성된다.
예를 들어, 보간량이 0.2인 경우는 오디오 1의 잠재 벡터의 80%가 오디오 2의 잠재 벡터의 20%에 추가됨을 의미한다. 본질적으로, 두 잠재 벡터 사이에 다차원 평면을 정의한다면 보간량 0.2는 한 소리에 대한 거리가 다른 소리에 대한 거리의 네 배임을 나타낸다.
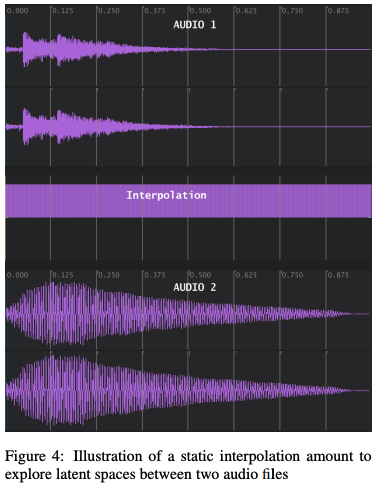
정적 보간량 범위에 집중함으로써 각 단계에서 보간량을 변경하여 하나의 오디오 입력 파일의 재구성에서 시작하여 각 단계에서 보간량을 변경하여 다른 오디오 파일로 점진적으로 변환할 수 있다. 이러한 전략은 사용자가 훈련된 RawAudioVAE 모델의 잠재 공간에서 소리가 어떻게 이동하는지를 듣게 해준다.
4.2 Interpolations in Meso-scale

두 번째 전략은 잠재 오디오 공간을 탐색하는 첫 번째 전략과 두 가지 측면에서 차이가 있다. 첫 번째 차이점은 잠재 공간 탐색 이전에 추가 단계로서 오디오 입력 파일을 생성하는 방식이다. 훈련 데이터셋에서 유사한 오디오 샘플을 연결하여 비교적 긴 두 개의 오디오 발췌문을 생성한다.
오디오 유사성은 훈련 데이터셋의 오디오 샘플 썸네일에 대해 훈련된 Self-Organizing Map에 대한 오디오 클러스터링을 활용함으로써 수행된다.
이러한 클러스터링 과정에 대한 자세한 내용은 Fast and Flexible Neural Audio Synthesis와 MASOM에서 확인할 수 있다. 이런 클러스터링 과정을 통해 오디오 파일을 제약하는 것을 돕고, 임의로 선택한 오디오 샘플들과 비교하여, 연결된 오디오 파일 내의 일관성을 향상시킨다.
오디오 샘플의 연결을 통해 두 개의 입력 오디오 파일을 생성하는 것은 10-30초의 길이를 가진 오디오 파일들과 함께 작업할 수 있게 해준다. 이런 길이의 오디오 파일은 동적으로 변하는 보간 양이 타임라인을 따라 진행되므로 이 두 번째 보간 전략에 유익하다.
이전 연구에서 작곡가 참가자들이 작곡 실천에서 잠재 오디오 공간을 탐색하기 위해 동적 보간 양을 설계하는 과정을 수행한 연구를 진행했다. 이전 연구에서 작곡가들이 두 개의 입력 오디오 파일 사이의 잠재 오디오 공간을 음악적으로 유의미하게 탐색하는 보간 곡선을 설계하는 것을 발견했다.
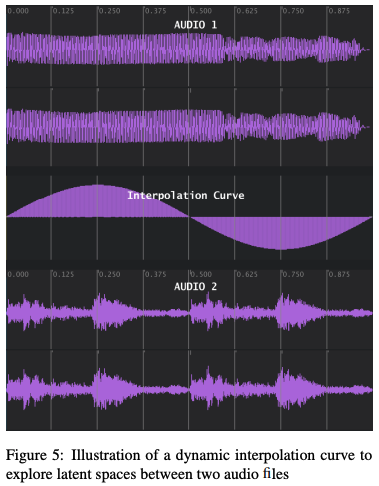
이 두 번째 전략의 동적 보간 개념은 정적 보간 양을 사용한 첫 번째 전략과 다르다. 두 번째 전략의 동적 보간 접근 방식은 각 오디오 윈도우 쌍에 대해 다른 보간 양을 적용한다.
오디오 타임라인을 따라, 보간 양은 주어진 오디오 입력 파일의 전체 오디오 윈도우 수에 해당하는 크기의 곡선을 따른다. 다양한 수학적 함수를 적용하여 보간 곡선을 생성할 수 있다.(sin 함수와 같은 다양한 주기의 함수 등)
4.3 Interpolations with Extensions

두 번째 보간 전략과 유사하게, 세 번째 전략은 오디오 샘플 클러스터를 활용하여 동일한 클러스터 내의 오디오 샘플을 연결하여 음향적 일관성을 갖춘 보다 긴 지속 시간 오디오 파일을 생성한다.
그러나 세 번째 전략은 윈도잉 트릭을 사용하여 연결된 오디오의 지속 시간을 더욱 증가시킨다. 이는 VAE에 공급되는 오디오 입력 파일을 로드할 때 AudioDataset 클래스 대신 TestDataset 클래스를 사용하는 오류에서 비롯된 것이다.
이 두 클래스의 차이점은 훈련 데이터셋의 오디오 파일에 대한 오디오 윈도잉을 처리하는 방식이다. 1024개의 샘플 윈도잉과 256개의 샘플 간격을 사용하여 오디오 파일을 4배로 늘릴 수 있다(알고리즘 3의 16~23줄 참조). 두 번째 전략과 마찬가지로, 이 세 번째 전략은 오디오 타임라인의 다른 섹션에 서로 다른 보간량을 적용하는 동적 보간 접근 방식을 적용한다.
6. Conclusions and future work
이 작업은 잠재 공간을 생성하는 기계 학습 알고리즘 및 이러한 알고리즘을 원시 오디오 데이터에 적용하는 방법에 대한 의문에서 나왔다.
문헌에서 등장하는 두 가지 유형의 잠재 오디오 공간인 연속적 및 이산적인 것을 명확히하고, 이 작업에서 이를 활용했다. 잠재 오디오 공간을 탐색하는 데 적용할 수 있는 세 가지 간단한 알고리즘적 전략을 제안했다.
미래의 연구에서는 음질 및 원시 오디오 접근 방식을 포함한 다양한 잠재 오디오 공간을 비교하여 그들의 수학적 특성과 가능성을 분석하는 것을 목표로 한다. ML에서 잠재 오디오 공간을 분석하기 위한 분석적 방법을 살펴보는 것은 음향 미학과 음악적 품질에 대한 가능성을 알려줄 수 있으며, 이를 음악 실천에 포함시키는 것이 중요하다. 이러한 프레임워크를 음악 창작 및 공연 컨텍스트에서 평가하는 것도 우선 순위다.
마지막으로, 우리가 이 작업에서 사용하는 RawAudioVAE 프레임워크는 가벼우며, 1초 오디오를 10ms 미만으로 생성할 수 있다. 이 저 연산 복잡성은 RawAudioVAE를 미래의 디지털 음악 악기 디자인에 기술과 결합시킬 수 있는 유망한 아키텍처로 만든다.
