UROP
1.[UROP #1] Tailoring Instructions to Student’s Learning Levels Boosts Knowledge Distillation (1)
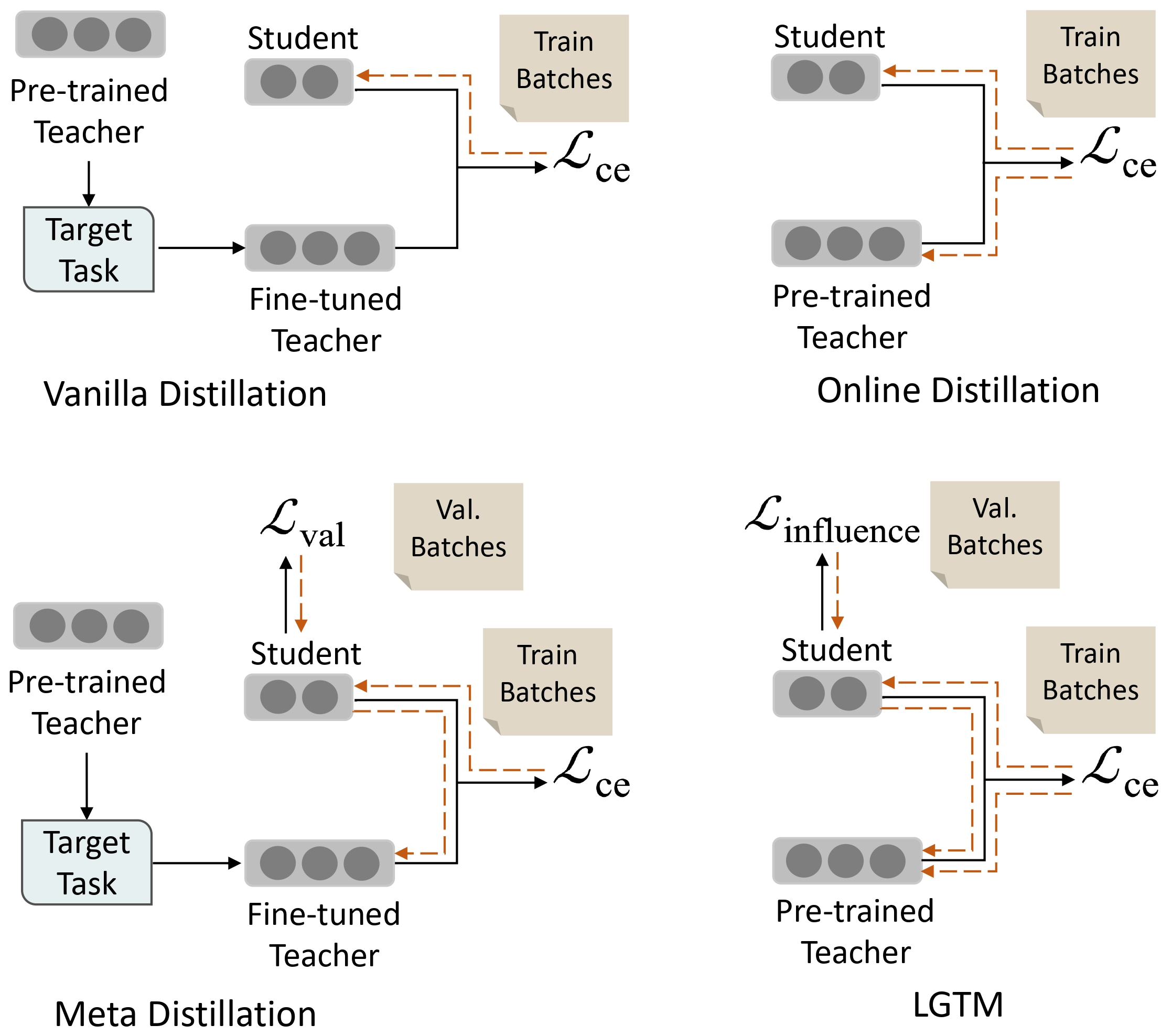
Paper : https://arxiv.org/abs/2305.09651
2.[UROP #2] SCOTT: Self-Consistent Chain-of-Thought Distillation

Paper : SCOTT: Self-Consistent Chain-of-Thought Distillation
3.[UROP #3] PuMer: Pruning and Merging Tokens for Efficient Vision Language Models (1)
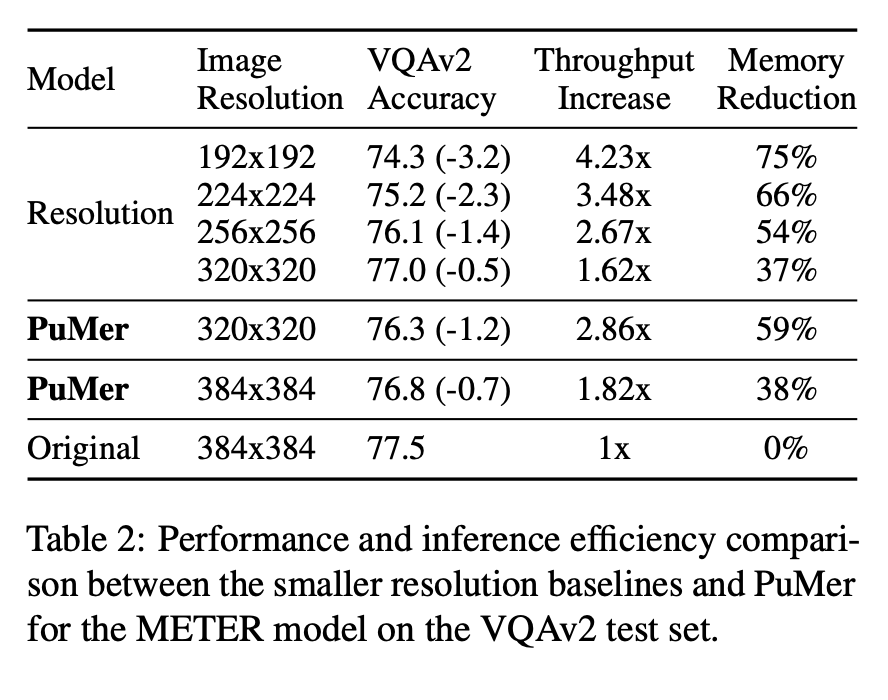
Github : https://github.com/csarron/PuMer
4.[UROP #4] PuMer: Pruning and Merging Tokens for Efficient Vision Language Models (2)
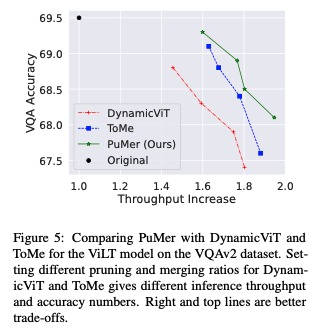
Paper : https://aclanthology.org/2023.acl-long.721/
5.[UROP #5] Specializing Pre-trained Language Models for Better Relational Reasoning via Network Pruning
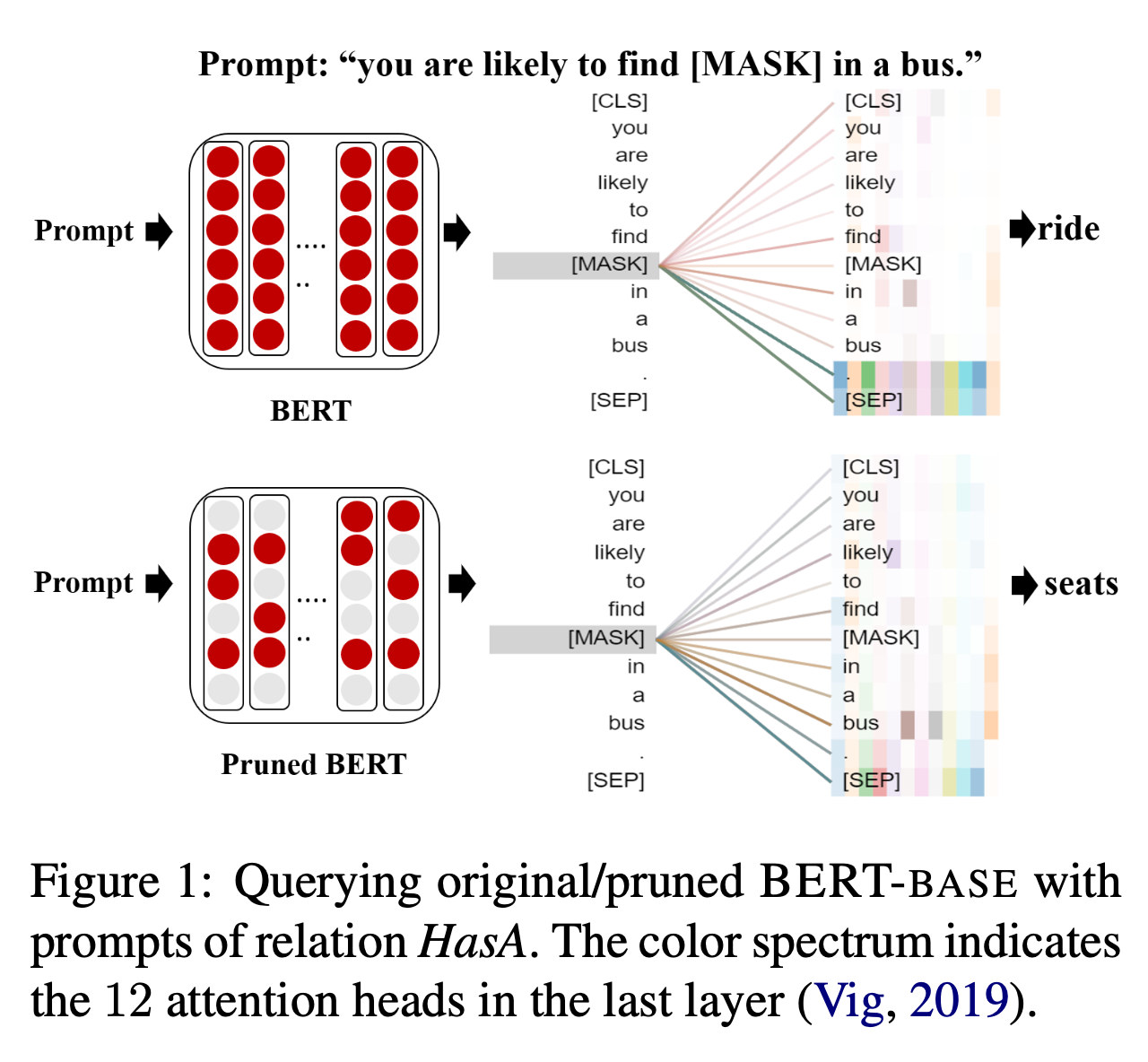
Github : https://github.com/DRSY/LAMP
6.[UROP #6] Understanding and Improving Knowledge Distillation for Quantization Aware Training of Large Transformer Encoders
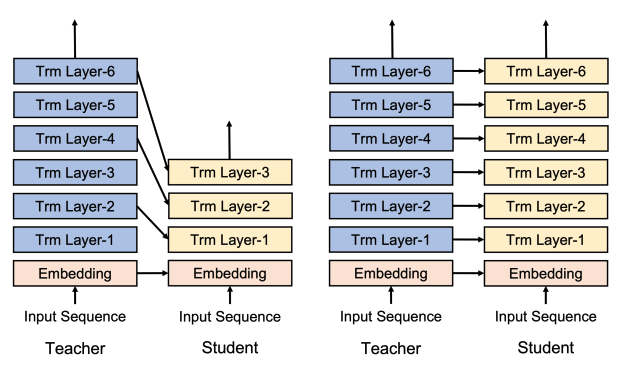
Paper : https://aclanthology.org/2022.emnlp-main.450/
7.[UROP #7] Specializing Smaller Language Models towards Multi-Step ReasoningEncoders

Github : https://github.com/FranxYao/FlanT5-CoT-Specialization
8.[UROP #8] Deep Mutual Learning (1)
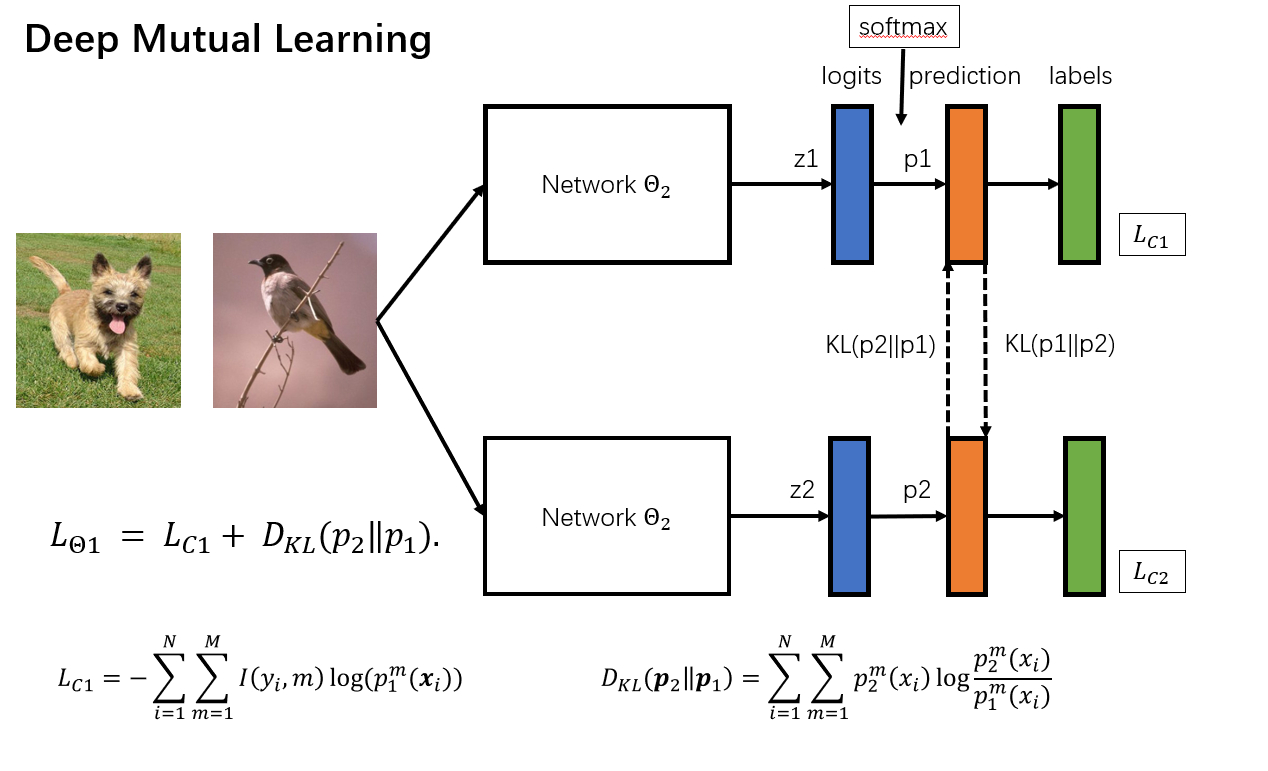
Paper : https://arxiv.org/abs/1706.00384
9.[UROP #9] Deep Mutual Learning (2)
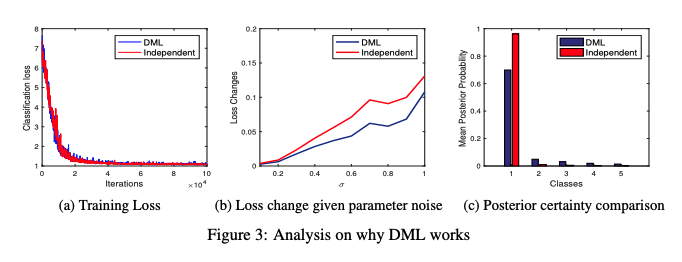
Paper : https://arxiv.org/abs/1706.00384
10.[UROP #10] Dynamic Model Pruning with FeedBack
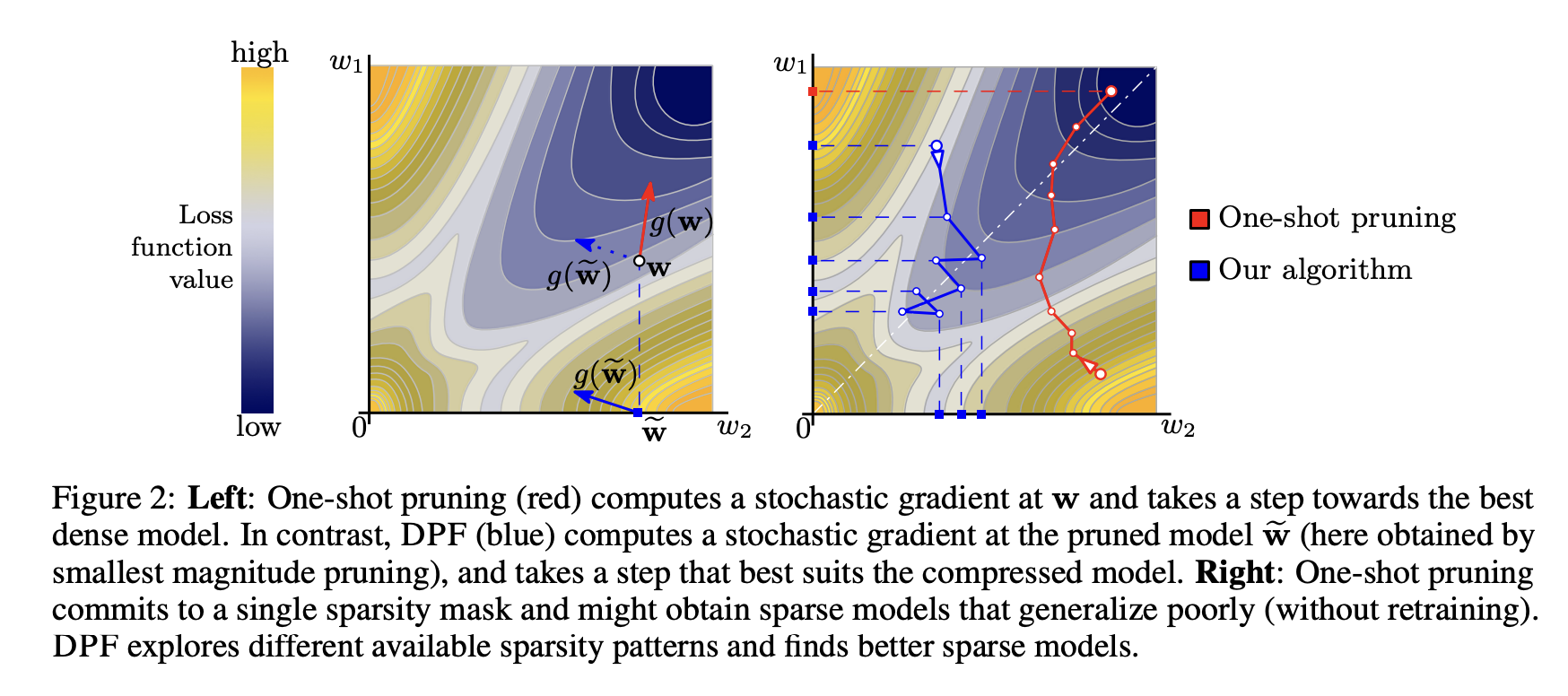
Paper : https://arxiv.org/abs/2006.07253
11.[UROP #11] Tailoring Instructions to Student’s Learning Levels Boosts Knowledge Distillation (2)
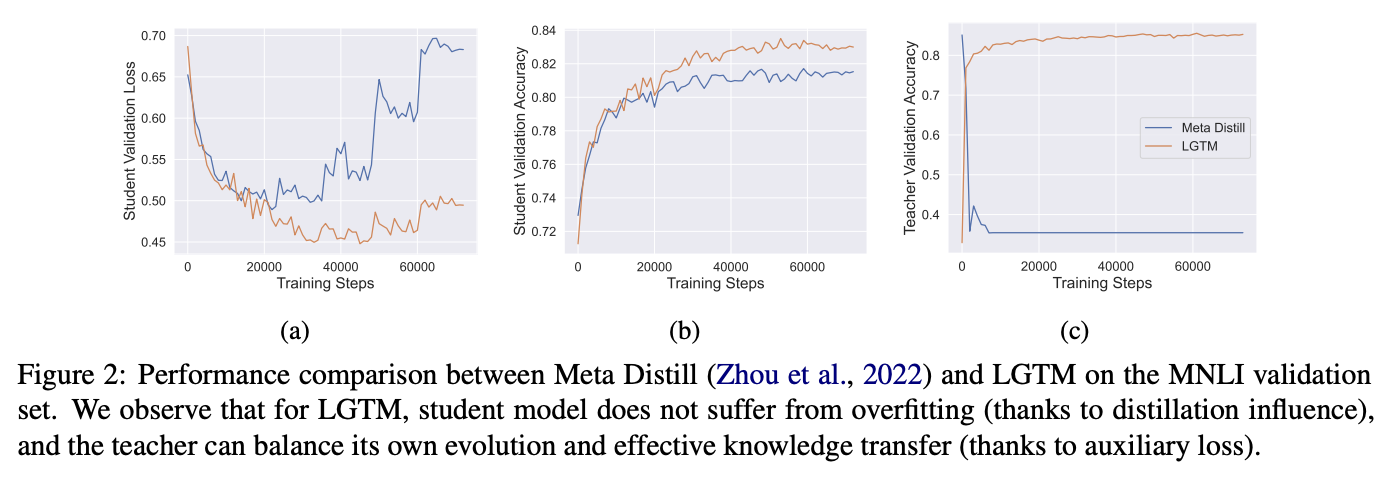
Github : https://github.com/twinkle0331/LGTM
12.[UROP #12] Movement Pruning: Adaptive Sparsity by Fine-Tuning
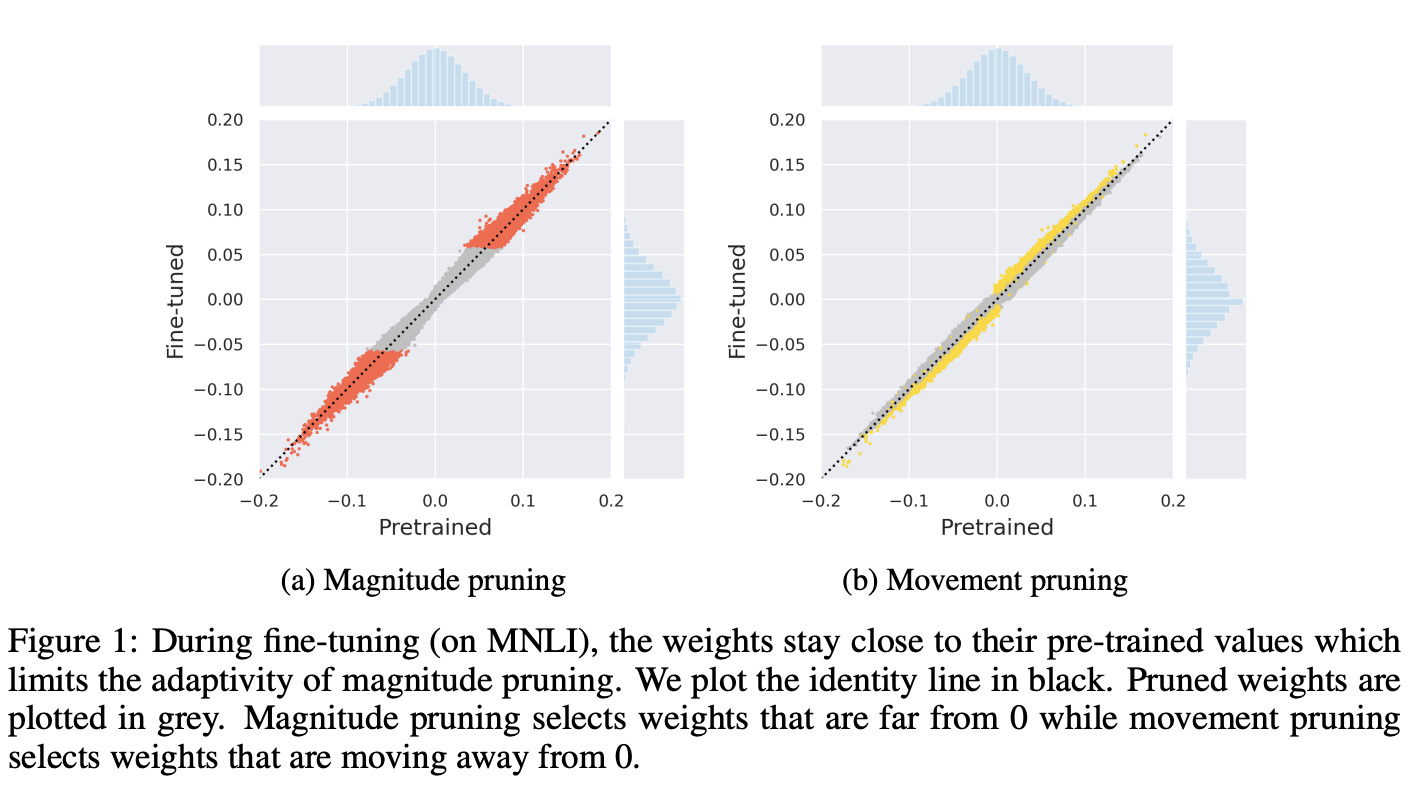
Paper : https://arxiv.org/abs/2005.07683
13.[UROP #13] Block Pruning For Faster Transformers

Paper : https://arxiv.org/abs/2109.04838
14.[UROP #14] Exploring Gender Bias in Pre-Trained Transformer-based Language Models Using Movement Pruning
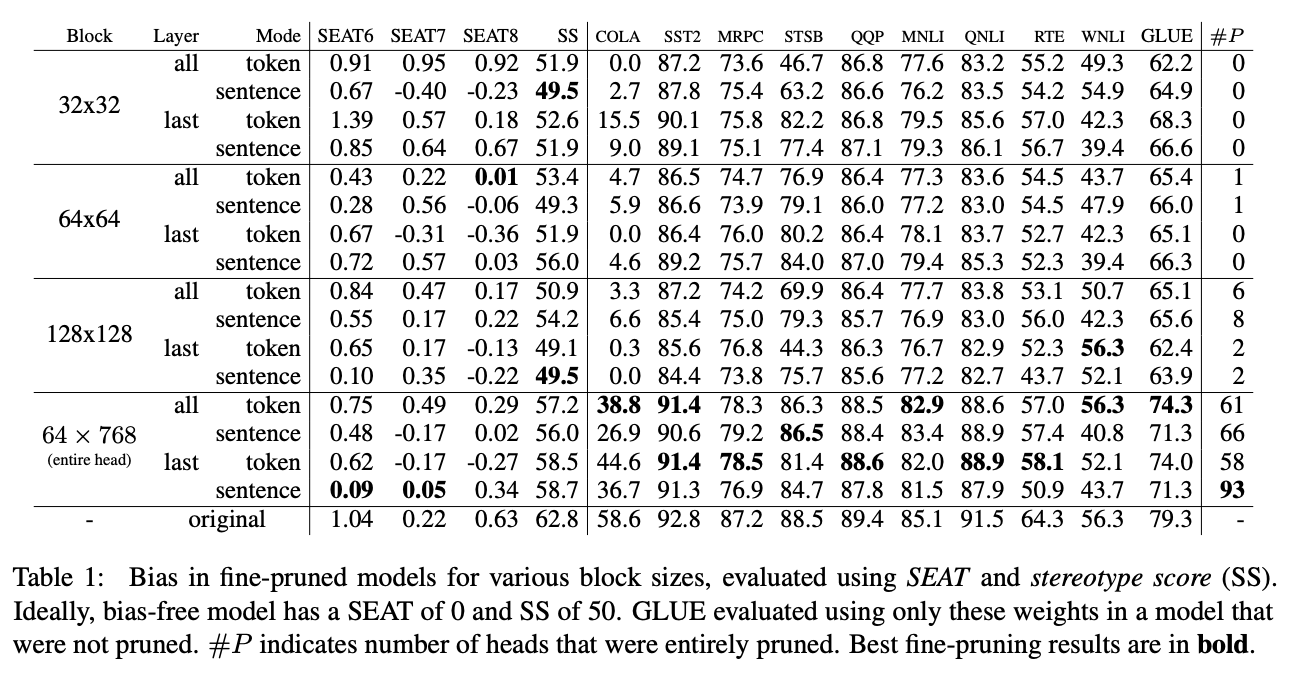
Paper : https://arxiv.org/abs/2207.02463
15.FedBABU: Towards Enhanced Representation for Federated Image Classification

Paper : https://arxiv.org/abs/2106.06042
16.Federated Dynamic Sparse Training: Computing Less, Communicating Less, Yet Learning Better

Paper : https://arxiv.org/abs/2112.09824
17.Sparse Model Soups: A recipe for Improved Pruning via Model Averaging
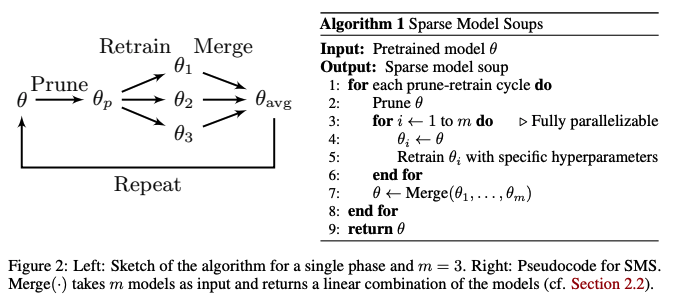
Paper : https://arxiv.org/abs/2306.16788
18.Complement Sparsification: Low-Overhead Model Pruning for Federated Learning
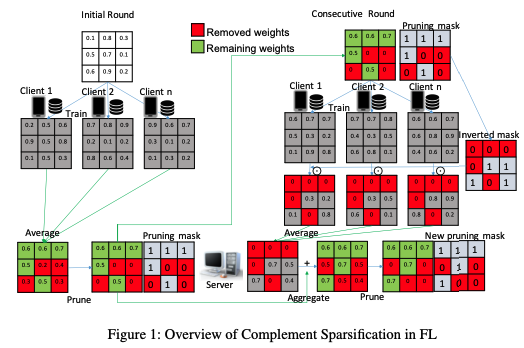
Paper : https://arxiv.org/abs/2303.06237