Paper : https://arxiv.org/abs/2106.06042
Github : https://github.com/jhoon-oh/FedBABU
Abstract
연합 학습은 데이터 이질성의 저주로 인해 단일 글로벌 모델을 개선하거나, 데이터 이질성을 장점으로 사용하여 여러 개인화된 모델을 개발하는 방향으로 진화해 왔다. 그러나 두 가지 방향을 동시에 고려한 연구는 거의 없다.
본 논문에서는 먼저 클라이언트 수준에서 연합 평균(Federated Averaging)을 분석하여, 더 나은 연합 글로벌 모델 성능이 항상 개인화를 향상시키는 것은 아니라는 것을 확인했다. 이러한 개인화 성능 저하 문제의 원인을 설명하기 위해, 네트워크를 범용성과 관련된 바디(추출기)와 개인화와 관련된 헤드(분류기)로 분해했다. 이후 이 문제는 헤드를 훈련시키는 과정에서 비롯된 것임을 지적했다.
이러한 관찰에 기초하여, 연합 학습 동안 모델의 바디만 업데이트하고(즉, 헤드는 무작위로 초기화되며 절대 업데이트되지 않음), 평가 과정에서 헤드를 개인화하기 위해 미세 조정하는 새로운 연합 학습 알고리즘 FedBABU를 제안한다. 광범위한 실험을 통해 FedBABU의 일관된 성능 향상과 효율적인 개인화를 확인했다.
1. Introduction
개인화된 데이터를 사용하는 분산 학습 프레임워크인 연합 학습(FL)은 매력적인 연구 분야로 자리 잡았다. 이 분야의 초기부터 장치 간 단일 글로벌 모델을 개선하는 것이 주요 목표였다. 여기서 글로벌 모델은 데이터 이질성으로 인해 어려움을 겪는다.
최근 많은 연구자들은 데이터 이질성을 가면의 장점으로 활용하여 여러 개인화된 모델에 초점을 맞추고 있다. 각 연구 방향에서 많은 연구가 진행되었지만, 개인화 목적을 위해 좋은 글로벌 모델을 훈련하는 방법에 대한 연구는 부족하다.
이 연구에서는 개인화 훈련을 위해 각 로컬 클라이언트 모델이
-
모든 클라이언트의 정보를 학습하는 글로벌 모델에서 시작하고,
-
이 글로벌 모델을 활용하여 자체 데이터 분포에 맞추는 방법을 제안한다.
Jiang et al. (2019)은 각 장치에서 글로벌 모델을 미세 조정하여 적응하는 개인화 방법을 분석했다. 그들은 미세 조정의 효과가 고무적이며, 중앙 위치에서 훈련하는 것이 초기 정확도(단일 글로벌 모델)를 높이는 동시에 개인화된 정확도(장치에서 미세 조정된 모델)를 낮춘다는 것을 관찰했다.
본 논문에서는 두 성능이 반대로 변화하는 이유에 초점을 맞춘다. 이는 범용성과 개인화의 요소를 별도로 다루어야 함을 시사하며, 고급 분석을 위해 전체 네트워크를 일반성과 관련된 바디(즉, 추출기)와 전문성과 관련된 헤드(즉, 분류기)로 분리하는 아이디어를 영감으로 받았다.
Kang et al. (2019)과 Yu et al. (2020)은 헤드가 클래스 불균형 환경에서 편향된다는 것을 입증했다. MobileNet과 ResNet과 같은 인기 있는 네트워크에는 모델 끝에 단일 선형 레이어만 있으며, 헤드는 이 선형 레이어로 정의되고 바디는 헤드를 제외한 모든 레이어로 정의된다.
-
Model Body : 표현 학습과 관련
-
Model Head : 선형 결정 경계 학습과 관련
본 논문에서는 매개변수를 분리하여 개인화 성능 저하의 원인을 밝히고, 이러한 문제가 헤드 훈련에서 비롯된 것임을 지적한다.
이와 같은 관찰에 영감을 받아, Federated Averaging 알고리즘을 간단히 변경하여 효율적으로 개인화할 수 있는 단일 글로벌 모델을 학습하는 알고리즘을 제안한다.
FedAvg는 클라이언트 샘플링, 브로드캐스팅, 로컬 업데이트, 그리고 집계의 네 단계로 구성된다.
-
클라이언트 샘플링 단계에서는 클라이언트 수가 너무 많아 모든 클라이언트가 각 라운드에 참여할 수 없기 때문에 클라이언트를 샘플링한다.
-
브로드캐스팅 단계에서는 서버가 글로벌 모델(즉, 첫 번째 브로드캐스트 단계에서는 초기 랜덤 모델, 이후에는 집계된 모델)을 참여 클라이언트에게 보낸다.
-
로컬 업데이트 단계에서는 각 장치의 브로드캐스트 모델이 자체 데이터 세트를 기반으로 훈련된다.
-
집계 단계에서는 로컬 업데이트된 모델이 서버로 전송되어 평균화하여 집계된다.
네 단계 중, 본 논문에서는 로컬 업데이트 단계에서 범용성과 개인화 관점 모두를 고려하여 초점을 맞춘다. 여기서 로컬 업데이트 단계에서 모델의 바디만 업데이트하며, 연합 학습 중에는 헤드가 절대 업데이트되지 않는다.
이를 바탕으로 FedBABU(Federated Averaging with Body Aggregation and Body Update)를 제안한다.

그림 1은 로컬 업데이트 및 집계 단계에서 FedAvg와 FedBABU의 차이를 설명한다. 직관적으로 고정된 헤드는 각 클래스에 대한 기준이나 지침으로 해석될 수 있으며, 본 논문의 접근 방식은 연합 학습 동안 모든 클라이언트에 걸쳐 동일한 고정 기준을 기반으로 한 표현 학습이다. 이 간단한 변경은 단일 글로벌 모델의 표현력을 향상시키고 훈련된 글로벌 모델의 보다 정확하고 빠른 개인화를 가능하게 한다.
본 논문의 기여는 다음과 같이 요약할 수 있다:
-
클라이언트 수준에서 FedAvg 알고리즘을 분석하여 단일 글로벌 모델과 미세 조정된 개인화 모델 간의 연결을 조사하고, 서버에서 공유된 데이터를 사용하여 헤드를 훈련하는 것이 개인화에 부정적인 영향을 미친다는 것을 보여준다.
고정된 랜덤 헤드가 중앙 집중식 설정에서 학습된 헤드와 유사한 성능을 가질 수 있음을 입증한다.
이러한 관찰을 통해 고정된 랜덤 헤드를 모든 클라이언트에 걸쳐 공유하는 것이 연합 설정에서 각 학습된 헤드를 평균화하는 것보다 더 강력할 수 있음을 제안한다.
-
연합 학습 동안 전체 모델의 업데이트 및 집계 부분을 모델의 바디로 축소하는 새로운 알고리즘인 FedBABU를 제안한다.
FedBABU가 특히 더 큰 데이터 이질성 하에서 효율적임을 보여준다.
또한, FedBABU 알고리즘으로 훈련된 단일 글로벌 모델은 빠르게 개인화될 수 있다(심지어 한 번의 미세 조정 에포크만으로도).
FedAvg가 대부분의 기존 개인화 연합 학습 알고리즘을 능가하며, 다양한 연합 학습 설정에서 FedBABU가 FedAvg를 능가함을 관찰한다.
- 바디 업데이트 및 바디 집계 아이디어를 정규화 기반 글로벌 연합 학습 알고리즘(FedProx와 같은)에 적용한다. 정규화가 개인화 능력을 감소시킨다는 문제가 BABU를 통해 완화됨을 보여준다.
2. Related Works
단일 글로벌 모델을 위한 연합 학습:
McMahan et al. (2017)가 제안한 FedAvg는 클라이언트의 원시 데이터를 중앙 서버에 저장하지 않고도 풍부한 데이터의 이점을 모으기 위해 단일 글로벌 모델을 학습하는 것을 목표로 하며, 로컬 업데이트를 통해 통신 비용을 줄인다.
그러나 다양한 클라이언트에서 파생된 비독립적이고 동일하지 않은 분포(non-IID) 데이터에 대해 전역 최적 모델을 개발하기는 어렵다.
이 문제를 해결하기 위해 클라이언트의 데이터 분포를 IID-like로 만들거나 로컬 업데이트 중 글로벌 모델과의 거리에 정규화를 추가하는 연구가 진행되었다.
-
Zhao et al. (2018)은 모든 클라이언트가 공공 데이터의 하위 집합을 공유할 것을 제안했고,
-
Duan et al. (2019)은 클라이언트의 라벨 분포를 균형 있게 하기 위해 데이터를 증강했다.
- 최근에는 두 연구(Li et al., 2018; Acar et al., 2021)가 글로벌 모델과 크게 차이나는 로컬 모델을 벌주기 위해 로컬 최적화 과정에 정규화 항을 추가하여 글로벌 모델이 더 안정적으로 수렴하도록 했다.
그러나 위의 방법을 사용하여 훈련된 단일 글로벌 모델은 각 클라이언트에 최적화되지 않는다는 점을 유의해야 한다.
개인화된 연합 학습:
개인화된 연합 학습은 각 클라이언트에 맞춘 개인화된 로컬 모델을 학습하는 것을 목표로 한다. 로컬 모델은 연합 없이 개발될 수 있지만, 이 방법은 데이터 제한 문제를 겪는다. 따라서 연합의 이점과 개인화된 모델을 유지하기 위해 clustering, multi-task learning, transfer
learning, regularized loss function, meta-learning 등 많은 다른 방법이 FL에 적용되었다.
-
두 연구(Briggs et al., 2020; Mansour et al., 2020)는 유사한 클라이언트를 클러스터링하여 클러스터 내 데이터 분포를 맞추고 클러스터 간 연합 없이 각각의 클러스터에 대한 별도의 모델을 학습했다.
-
클러스터링과 유사하게 Multi-task learning은 관련 클라이언트에 대한 모델을 동시에 학습하는 것을 목표로 한다.
클러스터링은 관련 클라이언트를 단일 클러스터로 묶는 반면, 멀티태스크 학습은 그렇지 않다. 각 모델의 일반화는 관련 클라이언트 간의 표현을 공유함으로써 개선될 수 있다.
-
Smith et al. (2017)과 Dinh et al. (2021)은 Multi-task learning이 개인화된 FL에 적합한 학습 체계임을 보여주었다. Transfer learning도 추천되는 학습 체계이며, 이는 클라이언트 간 지식을 전달하는 것을 목표로 한다.
-
Yang et al. (2020)과 Chen et al. (2020b)는 관련 클라이언트 간 knowledge를 transfer하여 로컬 모델을 향상시켰다.
-
T Dinh et al. (2020)과 Li et al. (2021)은 클라이언트 모델이 단순히 자신의 데이터셋에 과적합하지 않도록 글로벌 또는 평균 개인화 모델을 향해 정규화를 추가했다.
훈련 중 로컬 모델을 개발하는 위의 방법과 달리,
-
Chen et al. (2018)과 Fallah et al. (2020)은 모델 불변 메타 학습(MAML) 접근 방식을 통해 이중 수준 최적화를 사용하여 잘 초기화된 공유 글로벌 모델을 개발하려고 했다. 잘 초기화된 모델은 각 클라이언트에서 업데이트(예: MAML의 내부 업데이트)하여 개인화될 수 있다.
-
Jiang et al. (2019)는 FedAvg 알고리즘이 meta learning 알고리즘으로 해석될 수 있으며, FedAvg를 사용하여 학습된 글로벌 모델에서 미세 조정을 통해 높은 정확도의 개인화된 로컬 모델을 얻을 수 있다고 주장했다.
또한, 개인화된 FL을 위한 다양한 기술과 알고리즘이 제시되었으며, 자세한 내용은 Tan et al. (2021)과 Kulkarni et al. (2020)을 참조하면 도움이 된다.
개인화된 FL을 위한 바디와 헤드 분리:
전체 네트워크를 바디와 헤드로 분리하는 훈련 방식은 long-tail recognition, noisy label learning, meat learning 등 다양한 분야에서 사용되었다. 개인화된 FL을 위해 이러한 분리 접근법을 사용하는 시도가 있었다.
일관된 설명을 위해, 본 논문에서는 로컬 업데이트와 집계 부분의 관점에서 각 알고리즘을 설명한다.
-
FedPer (Arivazhagan et al., 2019)는 FedPav (Zhuang et al., 2020)와 유사하게 로컬 업데이트 중에 전체 네트워크를 공동으로 학습하고 하위 레이어만 집계한다. 하위 레이어가 바디와 일치할 때, 바디는 모든 클라이언트에 공유되고 헤드는 각 클라이언트에 개인화된다.
-
LG-FedAvg (Liang et al., 2020)는 로컬 업데이트 중에 전체 네트워크를 공동으로 학습하고, FedAvg를 통해 사전 훈련된 글로벌 네트워크 기반으로 상위 레이어만 집계한다. 상위 레이어가 헤드와 일치할 때, 바디는 각 클라이언트에 개인화되고 헤드는 모든 클라이언트에 공유된다.
-
FedRep (Collins et al., 2021)는 로컬 업데이트 중에 전체 네트워크를 순차적으로 학습하고 바디만 집계한다. 로컬 업데이트 단계에서 각 클라이언트는 먼저 집계된 표현으로 헤드만 학습하고, 그 다음 자신의 헤드로 바디를 단일 에포크 내에서 학습한다.
위의 분리 방법과 달리, 본 논문에서는 로컬 업데이트 중에 무작위로 초기화된 헤드로 바디만 학습하고 바디만 집계하는 FedBABU 알고리즘을 제안한다. 전체 연합 학습 동안 헤드를 고정하면 모든 클라이언트에 걸쳐 동일한 표현 학습 지침을 제공하는 것으로 생각된다. 그런 다음, 헤드를 미세 조정하여 개인화된 로컬 모델을 얻을 수 있다.
3. Preliminaries
FL 학습 절차
- 클라이언트 샘플링
- 전체 클라이언트 집합 {1, ···, N}에서 클라이언트 비율 f에 따라 클라이언트들이 샘플링됨.
- k번째 라운드에서 참여 클라이언트 Ck = {Ck i }⌊Nf⌋ i=1.
- 브로드캐스팅
- 서버는 초기에는 무작위로 초기화된 글로벌 모델 θ0 G를, 이후에는 집계된 모델 θk-1 G를 참여 클라이언트들에게 전송.
- 참여 클라이언트들의 로컬 파라미터는 글로벌 파라미터로 초기화됨: θk i (0) ← θk-1 G.
- 로컬 업데이트
- 각 디바이스에서 로컬 데이터 셋을 사용하여 모델을 업데이트.
- 로컬 에포크 τ 후 로컬 업데이트된 모델은 {θk i (τ Ik i )}⌊Nf⌋ i=1이 됨.
- 집계
- 로컬 업데이트된 모델을 서버로 전송하고, 이를 평균하여 글로벌 파라미터 θk G를 집계.
- 글로벌 파라미터 θk G = P⌊Nf⌋ i=1 nCk i n θk i (τ Ik i ), 여기서 n = P⌊Nf⌋ i=1 nCk i.
실험 설정
-
주요 모델 및 데이터셋: MobileNet과 CIFAR100 사용.
-
클라이언트 수: 100명.
-
데이터 분포: 각 클라이언트는 500개의 훈련 데이터와 100개의 테스트 데이터를 가짐.
-
데이터 이질성 제어:
- 클라이언트 비율 (f): 매 라운드에 참여하는 클라이언트의 비율.
- 로컬 에포크 (τ): 두 연속 통신 라운드 간격.
- 사용자당 샤드 수 (s): 각 사용자가 가질 수 있는 최대 클래스 수.
평가
-
초기 정확도 및 개인화된 정확도:
- 초기 정확도: 학습된 글로벌 모델이 각 클라이언트의 테스트 데이터 셋에서 평가된 성능.
- 개인화된 정확도: 학습된 글로벌 모델을 각 클라이언트의 훈련 데이터 셋을 사용하여 미세 조정한 후 평가된 성능.
-
다른 개인화된 FL 알고리즘과의 비교:
- FedPer, LG-FedAvg, FedRep 등의 개인화된 FL 알고리즘과 비교하여 평가.
각 표의 값 (X±Y)은 모든 클라이언트에 걸친 정확도의 평균±표준 편차를 나타낸다.
4. Personalization of a Single Global Model
우선 Wang et al. (2019) 및 Jiang et al. (2019)를 따르며, FedAvg 알고리즘을 사용하여 단일 글로벌 모델을 개인화하는 것을 조사하여 단일 글로벌 모델과 여러 개인화 모델을 연결한다. 테스트 데이터 세트가 서버에 모이지 않고 클라이언트에 분산되어 있다고 가정하여 초기 정확도와 개인화된 정확도를 평가한다.
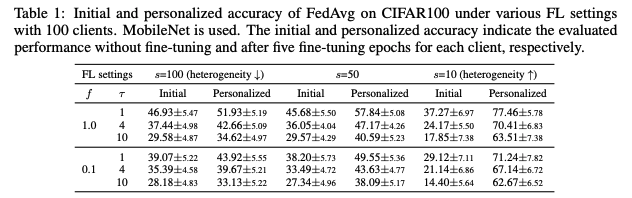
표 1은 100명의 클라이언트를 대상으로 한 다양한 FL 설정(f, τ, s)에 따른 CIFAR100에서의 FedAvg의 정확도를 설명한다. 초기 및 개인화된 정확도는 각각 미세 조정 없이 평가된 성능과 각 클라이언트에 대해 5개의 미세 조정 에포크로 평가된 성능을 나타낸다.
-
이전 연구에서 보여준 바와 같이, 더 현실적인 설정(즉, 더 작은 f, 더 큰 τ, 더 작은 s)일수록 초기 정확도가 낮아진다.
-
또한, Jiang et al. (2019)에서 관찰된 바와 같이, 개인화된 모델이 글로벌 모델보다 더 높은 정확도로 수렴하는 경향도 동일하다.
-
더욱 흥미로운 점은 데이터가 더 이질적일수록 초기 정확도와 개인화된 정확도 사이의 격차가 크게 증가한다는 것이다.
작은 s는 각 클라이언트가 보유한 라벨 분포가 제한되고 클래스당 샘플 수가 증가하여 로컬 작업을 더 쉽게 만드는 것으로 생각된다.
또한, 초기 정확도는 증가하지만 개인화된 정확도는 감소하는 흥미로운 실험을 수행하며, FL 학습 절차를 유지한다.
Jiang et al. (2019)에서는 중앙 집중식으로 학습된 모델이 개인화하기 더 어렵다는 것을 보여주었다.
유사하게, 본 논문에서는 연합 학습된 모델이 더 개인화하기 어렵도록 설계된 실험을 진행한다.
-
서버가 클라이언트의 비공개 데이터를 작은 비율 p만큼 가지고 있다고 가정하며, 이러한 비공개 데이터를 서버에서 데이터 이질성으로 인한 성능 저하를 완화하는 데 사용할 수 있다.
-
이 공유된 비공개 데이터를 사용하여 글로벌 모델을 매 집계 후 단 한 에포크 동안 업데이트한다.

표 2는 이 실험의 결과를 설명한다. 서버에서 네트워크 전체를 업데이트한다(Table 2의 F). 예상대로 p가 증가할수록 초기 정확도가 증가한다. 그러나 데이터 이질성이 큰 경우(s=10) 개인화된 정확도는 감소한다.
이 결과는 단일 글로벌 모델을 향상시키는 것이 초기 성능보다 더 중요하게 여겨질 수 있는 개인화에 해로울 수 있음을 시사한다. 따라서 본 논문에서는 훌륭한 글로벌 모델의 개발이 적절히 미세 조정되거나 개인화될 수 있는 능력을 고려해야 한다고 동의한다.
개인화 성능 저하의 원인을 조사하기 위해, 글로벌 모델이 서버에서 학습될 때 개인화에 불필요하고 방해가 되는 정보(즉, 특정 클라이언트가 가지고 있지 않은 유사한 클래스의 정보)가 헤드에 주입된다고 가정한다.
이를 포착하기 위해 서버에서 학습률을 헤드에 해당하는 부분만 0으로 설정하여 바디만 업데이트한다(Table 2의 B). 업데이트 부분을 좁힘으로써 초기 정확도에 영향을 미치지 않으면서 개인화 저하 문제를 크게 해결할 수 있다.
이 관찰을 통해 공유 데이터를 사용하여 헤드를 학습하는 것이 개인화에 부정적인 영향을 미친다고 주장한다.
5. FedBABU: Federated Averaging with Body Aggregation and Body Update
효율적으로 개인화할 수 있는 더 나은 단일 글로벌 모델을 학습하는 새로운 알고리즘을 제안한다. 앞선 연구들에서 영감을 받아 전체 네트워크를 본체와 헤드로 분리한다.
본체는 일반화를 위해 훈련되고 헤드는 전문화를 위해 훈련된다. 이 아이디어를 연합 학습에 적용하여, 연합 학습 단계에서는 헤드를 전혀 훈련하지 않고 (즉, 단일 글로벌 모델을 개발), 평가 과정에서는 헤드를 미세 조정하여 개인화한다.
5.1 Frozen Head in the Centralized Setting
알고리즘을 제안하기 전에, 초기화된 고정 헤드를 가진 모델이 본체와 헤드를 함께 학습하는 모델과 비슷한 성능을 보임을 실험적으로 보여준다.
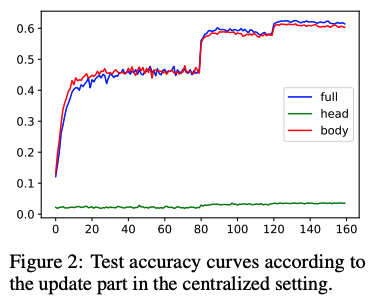
그림 2는 CIFAR100에서 MobileNet의 다양한 훈련 시나리오에 따른 테스트 정확도 곡선을 나타낸다. 총 에포크는 160이고, 학습률은 0.1에서 시작하여 80과 120 에포크에서 0.1씩 감소한다.
파란색 선은 모든 레이어를 훈련할 때의 정확도를, 빨간색 선은 모델의 본체만 훈련할 때의 정확도를, 녹색 선은 모델의 헤드만 훈련할 때의 정확도를 나타낸다.
완전히 훈련된 모델과 고정된 헤드는 거의 동일한 성능을 보이지만, 고정된 본체는 성능이 낮다. 따라서 무작위로 초기화된 고정 헤드는 수용 가능하지만, 무작위로 초기화된 고정 본체는 수용 불가하다고 주장한다.
이는 헤드의 직교성에서 비롯된 특성으로, 이는 부록 B에서 설명한다. 이러한 결과는 연합 학습 설정에서 로컬 훈련 중 본체만 업데이트할 수 있는 이유이다.
5.2 FedBABU Algorithm

섹션 5.1의 통찰과 결과를 바탕으로 새로운 FL 알고리즘인 FedBABU (본체 집계 및 본체 업데이트를 통한 연합 평균화)를 제안한다. 본체만 훈련되고, 연합 학습 중에는 헤드는 전혀 훈련되지 않는다. 따라서 헤드를 집계할 필요가 없다.
공식적으로, 모델 파라미터 θ는 본체(추출기) 파라미터 θ_ext와 헤드(분류기) 파라미터 θ_cls로 분리된다.
클라이언트의 θ_cls는 단일 글로벌 모델이 수렴할 때까지 무작위로 초기화된 글로벌 파라미터 θ_0 G의 헤드 파라미터로 고정된다. 이는 헤드에 해당하는 학습률을 0으로 설정하여 구현된다.
직관적으로, 모든 클라이언트에서 동일한 고정 헤드는 훈련 시간의 경과에도 불구하고 모든 클라이언트에서 동일한 기준으로 표현 학습을 제공한다고 믿어진다.
5.2.1 Representation Power of Global Models Trained by FedAVG and FedBABU
높은 초기 정확도는 개인화할 데이터가 없는 클라이언트가 있을 수 있기 때문에 종종 필요하다. 또한 초기 모델의 표현력은 다운스트림 또는 개인 작업의 성능과 관련이 있다.
표현력을 측정하기 위해 "헤드 없음" 정확도는 훈련된 헤드를 가장 가까운 템플릿으로 대체하여 계산된다. 이 방법은 이전 연구들을 따른다.
훈련된 글로벌 모델과 각 클라이언트의 훈련 데이터 세트를 사용하여 각 클래스의 표현이 템플릿으로 평균화된다. 그런 다음 테스트 샘플과 템플릿 간의 코사인 유사도를 측정하고 테스트 샘플을 가장 가까운 템플릿의 클래스로 분류한다. 템플릿은 원시 데이터를 이동할 수 없기 때문에 각 클라이언트에 대해 생성된다.
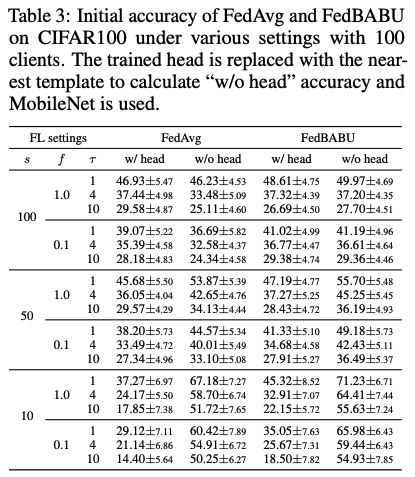
표 3은 헤드의 존재 여부에 따른 FedAvg와 FedBABU의 초기 정확도를 설명한다. FedBABU는 모든 클라이언트가 동일한 기준을 공유하고 그 기준에 따라 표현을 학습하기 때문에 향상된 표현력을 기대할 수 있다.
헤드가 없는 상태에서 평가된 경우, FedBABU는 모든 경우에 FedAvg보다 향상된 성능을 보이며, 특히 데이터 이질성이 큰 경우에 그렇다.
구체적으로, s = 100인 경우(즉, 각 클라이언트가 CIFAR100의 대부분의 클래스를 갖는 경우), FedAvg에서의 성능 차이는 헤드의 존재 여부에 따라 달라지지만, FedBABU에서는 그렇지 않다.
이는 FedBABU를 통해 생성된 특징이 헤드를 통해 보완할 필요가 없을 정도로 잘 표현된다는 것을 의미한다. s가 작은 경우, 헤드가 없을 때 성능이 향상된다.
템플릿은 각 클라이언트의 훈련 데이터 세트를 기반으로 구성되기 때문에 클라이언트가 가지고 있지 않은 클래스로 테스트 샘플을 분류할 수 없다.
즉, 각 클라이언트의 출력 분포에 대한 제한이 엄청난 성능 향상을 가져오며, 글로벌 모델을 훈련하지 않아도 그렇다. 따라서 강력한 표현력을 가진 글로벌 모델을 미세 조정하면 개인화가 향상될 것으로 기대된다.
5.2.2 Personalization of FedAVG and FedBABU
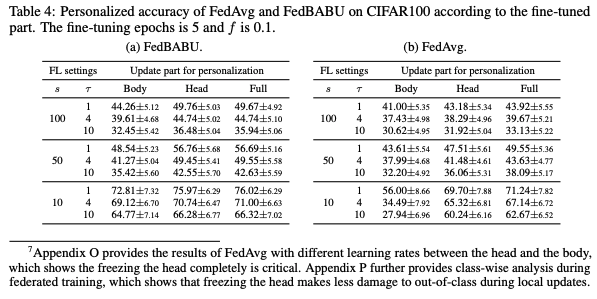
FedBABU의 개인화에 대한 주된 요인을 조사하기 위해, 미세 조정된 부분에 따른 성능을 비교한다.
표 4a는 이 실험의 결과를 설명한다. 각 클라이언트의 훈련 데이터 세트를 기반으로 글로벌 모델을 5개의 에포크 동안 미세 조정한다.
헤드를 포함한 미세 조정(즉, 표 4a의 Head 또는 Full)이 본체 부분적인 미세 조정(즉, 표 4a의 Body)보다 개인화에 더 나은 것으로 나타난다.
FedBABU의 경우, 성능 저하 없이 헤드만 미세 조정하여 계산 비용을 줄일 수 있다.
그러나 FedAvg의 경우, 성능 차이가 나타난다. 표 4b는 미세 조정된 부분에 따른 FedAvg의 개인화 정확도를 설명한다.
전체 네트워크를 미세 조정하는 것이(표 4b의 Full) 부분적으로 미세 조정하는 것(표 4b의 Body 또는 Head)보다 개인화에 더 나은 것으로 나타난다.
따라서 FedAvg의 경우, 더 나은 성능을 위해 전체 네트워크를 미세 조정하여 글로벌 모델을 개인화하는 것이 권장된다.
평가의 일관성을 위해, FedAvg와 FedBABU 모두 이 논문에서 전체 모델을 미세 조정하였다.
5.2.3 Personalization Performance Comparison
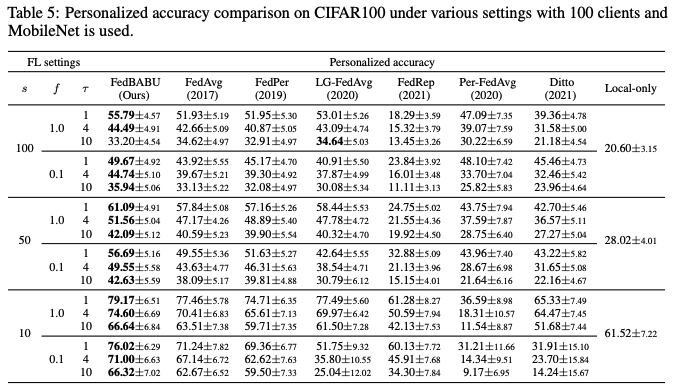
FedBABU를 기존 방법과 비교하여 개인화 관점에서 평가한다. 평가 절차와 각 알고리즘의 구현에 대한 자세한 내용은 부록 A에 있다. 표 5는 다양한 알고리즘의 개인화 정확도를 설명한다.
주목할 점은 FedAvg가 매우 강력한 기준선으로, 대부분의 경우 CIFAR100에서 최근의 개인화 FL 알고리즘을 압도한다는 것이다.
이러한 결과는 잘 훈련된 표현을 기반으로 한 미세 조정이 이질적 작업에 대해 advanced few-shot classification 알고리즘을 압도하는 meta-learning 분야의 최근 트렌드와 유사하다.
FedBABU(본 연구)는 FedAvg를 더욱 능가하며, 헤드를 고정함으로써 표현력을 강화하여 성능을 향상시킨다고 여겨진다.
구체적으로, τ=1일 때, FedBABU와 FedRep 간의 성능 차이는 클라이언트 간 헤드를 고정하는 것의 중요성을 보여준다. τ=1일 때, 만약 FedRep에서 헤드에 대한 훈련 과정이 없다면, FedRep은 FedBABU로 축소된다.
또한, FedRep의 성능 저하는 본체 훈련의 낮은 에포크 수 때문이라고 생각된다. 개인화 FL 알고리즘의 효율성은 모든 클라이언트가 참여할 때 증가하므로, FedPer(Arivazhagan et al., 2019)는 매 통신 라운드 동안 모든 클라이언트의 활성화를 가정한다.
Per-FedAvg 알고리즘은 클래스가 많고 미세 조정 반복이 적을 때 테스트 세트를 지원 세트와 쿼리 세트로 나누는 문제를 겪을 수 있다.
요약하면, FedAvg는 최근의 개인화 FL 알고리즘인 Per-FedAvg 및 Ditto보다 비교 가능하거나 더 나은 성능을 보이며, FedBABU(본 연구)는 FedAvg 및 다른 분리 알고리즘보다 높은 성능을 달성한다.
Personalization Speed of FedAVG and FedBABU
평가 과정에서 미세 조정 에포크 τf를 조절하여 FedAvg와 FedBABU의 개인화 속도를 조사한다.
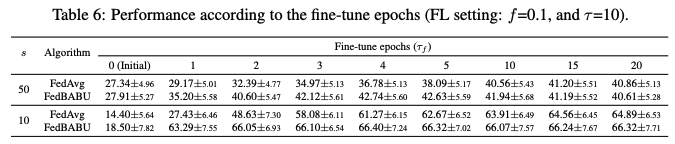
표 6은 FedAvg와 FedBABU의 초기(τf가 0일 때) 및 개인화(그 외의 경우) 정확도를 설명한다. 여기서 한 에포크는 10번의 업데이트와 같으며, 각 클라이언트는 500개의 훈련 샘플을 가지고 있고 배치 크기는 50이다.
FedAvg는 미세 조정을 위해 충분한 에포크가 필요함이 Jiang et al. (2019)에서 보고된 바 있다. 주목할 점은 FedBABU가 적은 수의 에포크로 더 나은 정확도를 달성한다는 것으로, 이는 미세 조정이 비용이 많이 들거나 제한된 경우에 FedBABU가 정확하고 빠르게 개인화할 수 있음을 의미한다. 이 특성은 부록 K의 코사인 유사성을 기반으로 추가 설명된다.
5.2.5 Body Aggregation and Body Update on the Fedprox
FedProx (Li et al., 2018)는 로컬 모델이 글로벌 모델에서 벗어나는 것을 방지하기 위해 글로벌 모델과 로컬 모델 간의 거리를 정규화한다.
정규화의 정도는 µ로 조절된다. µ가 0.0일 때, FedProx는 FedAvg로 축소된다.
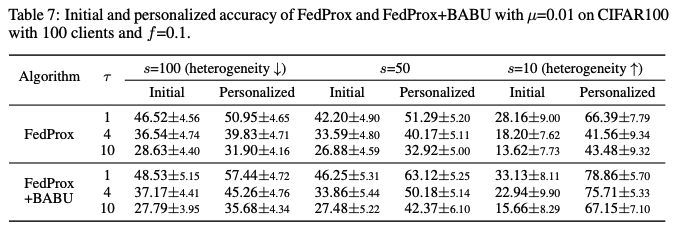
표 7은 f=0.1일 때 µ=0.01로 설정된 FedProx와 FedProx+BABU의 초기 및 개인화 정확도를 설명하며, 부록 M에서는 f=1.0일 때의 결과를 보고한다.
FedProx로 훈련된 글로벌 모델은 개인화 능력을 FedAvg에 비해 감소시킨다(표 1의 f=0.1일 때를 참조), 특히 현실적인 FL 설정에서 그렇다. 본 논문은 FedProx 알고리즘에 바디 어그리게이션과 바디 업데이트 아이디어를 적용하여 FedProx+BABU를 만들었으며, 이는 FedAvg의 개인화 성능보다 뛰어나다.
더욱이, FedProx+BABU는 FedBABU에 비해 개인화 성능을 향상시킨다(표 5의 f=0.1일 때를 참조). 이는 바디의 정규화가 여전히 의미가 있다는 것을 의미한다.
본 논문의 알고리즘과 다양한 실험은 연합 학습의 미래 방향을 제시한다: 연합하고 향상시켜야 할 부분은 무엇인가? 바로 표현력이다!
6. Conclusion
본 연구에서는 개인화를 목적으로 하는 좋은 연합 글로벌 모델을 훈련하는 방법에 중점을 두었다. 즉, 이 문제는 다운스트림 개인 작업을 위해 연합 학습 방식으로 더 나은 백본을 사전 훈련하는 방법으로 귀결된다.
먼저 글로벌 모델을 개선하기 위한 기존 방법들(예: 데이터 공유 또는 정규화)이 개인화 능력을 감소시킬 수 있음을 보여주었다. 이러한 개인화 성능 저하 문제를 완화하기 위해, 우리는 전체 네트워크를 일반성과 관련된 바디와 개인화와 관련된 헤드로 분리했다. 그런 다음, 헤드를 훈련시키는 것이 이 문제를 일으킨다는 것을 입증했다.
더 나아가, 클라이언트마다 이질적인 데이터에 빠르게 적응할 수 있는 공유 글로벌 모델을 학습하는 FedBABU 알고리즘을 제안했다. FedBABU는 로컬 업데이트 단계에서 바디만 업데이트하고, 어그리게이션 단계에서도 바디만 어그리게이션하여 강력한 표현력을 가진 단일 글로벌 모델을 개발한다. 이 글로벌 모델은 각 클라이언트의 데이터 세트를 사용하여 클라이언트의 모델을 미세 조정함으로써 효율적으로 개인화할 수 있다.
광범위한 실험 결과는 FedBABU가 다양한 개인화 FL 알고리즘을 압도한다는 것을 보여주었다. 우리의 개선은 FL에서 표현력을 연합하고 향상시키는 것이 중요하다는 점을 강조한다.
