Paper : https://arxiv.org/abs/2112.09824
Github : https://github.com/bibikar/feddst?utm_source=catalyzex.com
Abstract
연합 학습(FL)은 클라우드에서 자원 제약이 있는 엣지 디바이스로 머신 러닝 작업을 분산시킨다. 하지만 현재의 딥 네트워크는 엣지 디바이스에서 추론 및 학습하기에 너무 많은 연산을 필요로 할 뿐만 아니라, 대역폭이 제한된 네트워크를 통해 업데이트를 전송하기에도 너무 크다.
본 논문에서는 연합 동적 희소 학습(FedDST)이라는 새로운 FL 프레임워크를 개발, 구현, 실험적으로 검증하였다. 이를 통해 복잡한 신경망을 엣지 디바이스에서 효율적으로 학습하고 네트워크 통신을 대폭 개선할 수 있다.
FedDST의 핵심은 대상 전체 네트워크에서 희소 하위 네트워크를 추출하고 학습하는 동적 과정에 있다. 이 방식을 통해 "일석이조"의 효과를 얻는다.
각 클라이언트는 전체 모델 대신 자신의 희소 네트워크를 효율적으로 학습하며, 희소 네트워크만이 디바이스와 클라우드 사이에서 전송된다. 또한, 실험 결과에 따르면 FL 학습 중 ❗동적 희소성은 고정된 공유 희소 마스크보다 로컬 이질성을 더 유연하게 수용한다.
동적 희소성은 학습 동작에 "실시간 자기 앙상블 효과"를 자연스럽게 도입하여 FL 성능을 밀집 학습보다 더욱 향상시킨다.
현실적이고 도전적인 Non-IID FL 설정에서 FedDST는 실험에서 경쟁 알고리즘을 지속적으로 능가한다.
-
예를 들어, 비독립적이고 동일한 분포가 아닌 CIFAR-10에서 동일한 업로드 데이터 제한을 준수할 때 FedDST는 FedAvgM에 비해 10%의 놀라운 정확도 우위를 확보한다.
-
업로드 데이터 제한이 2배인 경우에도 정확도 차이는 3%로 유지되며, FedDST의 효율성을 더욱 입증한다.
Introduction
개인 데이터의 프라이버시 보호와 엣지에서의 머신 러닝(ML) 구현에 대한 욕구에 힘입어, 연합 학습(FL)이 최근 다수의 클라이언트 디바이스에서 분산된 ML을 가능하게 하는 사실상 표준 패러다임으로 떠올랐다.
FL 시스템에서는 중앙 클라우드 서버가 클라이언트 네트워크 내 정보 전송을 중재하며, 클라이언트는 로컬 데이터를 비공개로 유지해야 한다. 전통적인 방법에서는 FL이 여러 개의 동기 라운드를 실행한다.
각 라운드에서는 FL이 선택된 디바이스의 로컬 데이터만 사용하여 여러 로컬 학습 에포크를 실행한다. 이 로컬 학습 후, 클라이언트의 모델 업데이트가 중앙 서버로 전송되고, 서버는 이를 모두 집계하여 글로벌 모델을 업데이트한다.
FL 시스템에서는 무거운 연산 작업이 클라우드에서 자원 제약이 있는 엣지 디바이스로 배포된다. 엣지에서의 사용을 가능하게 하려면 FL 시스템은 디바이스 수준의 로컬 학습 효율성과 네트워크 내 통신 효율성을 최적화해야 한다.
불행히도 현재의 ML 모델은 엣지 디바이스에서 추론하기에 너무 복잡할 뿐만 아니라, 학습하기에도 너무 복잡하다. 모델의 간결함 외에도 클라우드와 디바이스 간 통신 효율성도 중요하다.
모바일 폰과 같은 클라이언트 디바이스는 비대칭 인터넷 연결로 인해 업로드 대역폭 제한이 심각한 경우가 많아 연합 학습 알고리즘의 업로드 비용을 줄이는 것이 매우 중요하다.
기존의 많은 통신 효율 FL 연구는 FL 업데이트에서 구조적 및 스케치된 희소성, 최적의 클라이언트 샘플링, 및 기타 전통적인 방법에 초점을 맞추고 있다.
경량 모델을 엣지 디바이스에서 추론할 수 있도록 하기 위한 목표로, 희소 신경망(NNs)을 최적화하려는 상당한 노력이 있었다. 이러한 방법들은 추론 지연 시간을 크게 줄이지만, 학습에 필요한 연산 및 메모리 자원에 큰 영향을 미친다.
로터리 티켓 가설은 Dense NNs가 완전한 정확도로 고립하여 학습할 수 있는 희소 일치 하위 네트워크를 포함하고 있음을 보여주었다. 더 많은 연구들은 희소성이 초기화 시점에서 나타날 수 있거나, 학습 중 동적 형태로 활용될 수 있음을 보여주었다.
본 논문의 주된 목표는 연합 동적 희소 학습(FedDST)이라는 새로운 FL 프레임워크를 개발, 구현 및 실험적으로 검증하는 것이다. 이를 통해 복잡한 NNs를 배포하고 학습하여 디바이스 연산과 네트워크 통신 효율성을 크게 개선할 수 있다.
FedDST의 핵심은 동적 희소 학습에 대한 신중하게 설계된 연합 접근법에 있다. FedDST는 클라이언트의 고도로 희소한 일치 하위 네트워크만을 전송하고, 각 클라이언트가 효율적인 희소 분산 학습을 수행할 수 있게 하여 "일석이조"의 효과를 제공한다.
더욱 중요한 점은 FL 학습 중 동적 희소성이 최첨단 알고리즘보다 로컬 이질성을 더 견고하게 수용함을 발견한 것이다. 동적 희소성 자체가 실시간 자기 앙상블 효과를 유도하여 밀집 학습보다 FL 성능을 향상시킨다.
본 논문의 공헌 :
-
동적 희소 학습을 연합 학습에 도입하여 희소 NNs와 FL 패러다임을 원활하게 통합하는 것은 이번이 처음이다. 우리의 프레임워크인 FedDST는 희소성을 통합 도구로 활용하여 통신 및 로컬 학습 비용을 절감한다.
-
❗유연한 집계 방법을 사용하여, 추가 전송 오버헤드 없이 FedAvg 위에 FedDST를 배포하였다. 일반 설계 원칙으로서, 우리의 방법은 FedProx와 같은 다른 FL 프레임워크에도 쉽게 확장 가능하다.
또한, 동적 희소성 개념은 ❗로컬 이질성을 수용하고 실시간 자기 앙상블 효과를 생성하여 밀집 베이스라인보다 FL 성능을 향상시키는 것으로 나타났다.
-
광범위한 실험을 통해 FedDST가 비독립적이고 동일한 분포가 아닌 데이터 분포의 어려운 문제에서도 통신 효율성을 극적으로 개선함을 보여준다.
이러한 비독립적이고 동일한 분포가 아닌 설정에서도, FedDST는 CIFAR-10에서 FedAvgM보다 3%의 정확도 향상을 제공하며, 업로드 대역폭은 절반만 필요하다.
또한, 매개변수의 합리적 변동에 대한 FedDST의 견고성을 보여주는 광범위한 소멸 연구도 제공한다. 이러한 결과는 희소 학습이 FL의 미래 "기본 옵션"이 될 수 있음을 시사한다.
Related work
Federated Learning
연합 학습에서, 클라이언트 세트 j ∈ [N]는 중앙 조정 서버의 참여로 하나 이상의 모델을 학습하기 위해 협력한다.
각 클라이언트는 로컬 학습을 위한 소규모 데이터 세트 Dj를 가지고 있지만, 사용자 프라이버시를 보호하기 위해 클라이언트는 로컬 학습 데이터를 공유하지 않는다.
본 연구에서는 글로벌 모델 θ를 학습하고, 글로벌 손실을 최소화하는 것을 목표로 한다.
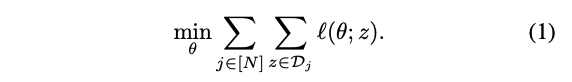
FedAvg 알고리즘 계열에서는 통신 라운드로 학습이 진행된다.
-
각 라운드의 시작 시, 서버는 클라이언트 세트 Ci를 선택하고 현재 서버 모델 매개변수 θi를 클라이언트에게 보낸다.
-
각 클라이언트 j ∈ Ci는 로컬 학습 세트를 사용하여 받은 모델로 E 에포크의 학습을 수행하여 매개변수 θij를 생성하고 이를 서버에 업로드한다.
FedAvg에서는
-
클라이언트 : SGD로 로컬 학습
-
서버 : 샘플링된 클라이언트의 weighted average를 통해 글로벌 모델을 업데이트
Reddi et al.(2021)은 클라이언트가 생성한 업데이트를 pseudo-gradients로 해석하고 사용할 수 있음을 주장하며, 이를 통해 FedAvg를 FedOpt 프레임워크로 일반화하여 다양한 클라이언트 및 서버 옵티마이저를 "플러그인"할 수 있도록 한다.
실제 FL 설정에서는 비독립적이고 동일한 분포가 아닌 데이터 분포, 클라이언트 이질성, 엣지에서 제한된 연산, 메모리, 대역폭 등 여러 가지 도전 과제가 있다.
클라이언트의 연산 능력 이질성은 특정 클라이언트가 모델 업데이트를 형성하는 데 "너무 오래" 걸리는 이른바 지연 문제를 야기하여, 서버가 이를 기다리지 못하고 진행해야 한다.
-
Hsu et al.(2019)은 FedAvgM에서 클라이언트 옵티마이저에 모멘텀 항을 추가하면 non-IID 설정에서 성능이 지속적으로 향상됨을 보여준다.
-
Li et al.(2018)은 FedAvg에 근접 패널티를 추가하여 지연자가 부분 업데이트를 제출할 수 있도록 하는 FedProx를 제안한다.
통신 효율적인 FL을 위해, Konecny et al.(2017)은 모델 업데이트가 통신 중 압축되지만 로컬 학습 중에는 압축되지 않는 ❗스케치된 업데이트와, 로컬 학습이 압축된 표현에서 직접 수행되는 ❗구조화된 업데이트를 구별한다.
연합 학습 전체 과정에서 가지치기 또는 가중치 재조정에 대해 논의하는 이전 연구는 상대적으로 적다.
Network Pruning
모델 가지치기는 연결을 제거하여 더 큰 신경망(NN)에서 희소 하위 네트워크를 선택하는 것을 목표로 한다. 전통적으로 가지치기 방법은 매우 과매개변수화된 학습된 모델에서 시작하여, 연결을 제거한 후 가지치기된 모델을 미세 조정한다.
가지치기의 일반적인 목표는 연산, 메모리, 통신 또는 기타 자원을 절약하는 것이다. 여러 가지 선택 기준이 가능하며, 여기에는 가중치 크기, 최적의 뇌 손상, 제로 활성화, 테일러 확장 등이 포함된다.
최근 연구들은 초기화 시 "단일 샷" 가지치기를 수행하는 다양한 알고리즘을 제안하였다.
-
Lee et al.(2019)은 초기화 시 미니배치를 샘플링하고 연결의 민감도에 따라 정렬하여 연결을 선택한다.
-
Wang et al.(2020)도 초기화 시 미니배치를 샘플링하지만 가지치기 후 그래디언트 흐름을 유지하려고 시도한다.
Dynamic Sparse Training
동적 희소 학습(DST)은 학습 과정에서 정기적으로 선택된 하위 네트워크를 이동시키며, 일정한 수의 매개변수를 유지한다.
-
주목할 만한 연구(Mocanu et al. 2018)는 SET 알고리즘을 제안하여 가장 작은 크기의 가중치를 반복적으로 가지치기하고 ❗무작위로 연결을 성장시킨다.
또한 특정 밀도 분포를 층별로 유지하며, Erdos-Renyi 무작위 그래프 토폴로지를 따르며 층의 입력 및 출력 연결 수로 밀도를 조절한다.
-
RigL에서는 희소 마스크를 무작위로 초기화하고, layer-wise magnitude pruning과 gradient-magnitude weight growth을 수행한다.
Mocanu et al.(2018)와 마찬가지로, 이들은 특정 층별 희소성 분포를 따르며, ERK 희소성 분포를 도입하여 밀도를 연결 수 및 커널 크기로 조절한다.
-
Liu et al.(2021c)는 DST가 매개변수 탐색에서 얻는 이점을 보여준다. 구체적으로, ❗다양한 희소 네트워크를 탐색함으로써 DST는 "시간적 자기 앙상블"을 효과적으로 수행하여 밀집 네트워크보다도 성능 이점을 제공한다(Liu et al. 2021a,b).
Pruning in Federated Learning
연합 학습(FL) 과정에서 가지치기를 다루는 연구는 두 가지뿐이다.
PruneFL은 특정 클라이언트에서 선택된 초기 마스크에 의존하며, 마스크 재조정을 매 ΔR 라운드마다 수행하는 FedAvg와 유사한 알고리즘을 수행한다.
학습은 희소 행렬 연산을 통해 수행된다. 마스크 재조정 라운드에서는 클라이언트가 전체 밀집 그래디언트를 업로드해야 하며, 서버는 이를 사용하여 집합 그래디언트 g를 형성한다.
마스크를 선택할 때 가지치기 가능한 가중치에 해당하는 인덱스 j는 g²_j / t_j로 정렬된다. 여기서 t_j는 네트워크에서 연결 j를 유지하는 시간 비용의 추정치이다.
이 추정치는 다양한 희소성을 가진 FL의 한 라운드의 시간 비용을 측정하여 실험적으로 결정된다.
LotteryFL은 LGFedAvg에서 영감을 받아 ❗클라이언트가 글로벌 네트워크의 로컬 하위 집합을 선택하여 로컬 표현을 유지할 수 있도록 한다.
이는 ❗각 클라이언트 c가 별도의 마스크 mc를 유지하는 FedAvg의 확장으로 설명될 수 있다. 각 라운드 r에서 선택된 클라이언트는 로컬 검증 세트를 사용하여 자신의 하위 네트워크 θ^r * m_c^r를 평가한다.
검증 정확도가 사전 정의된 임계값을 초과하고 클라이언트의 현재 희소성 ||m_c^r||_0가 목표 희소성보다 작은 경우, magnitude pruning을 수행하여 새로운 마스크 m_c^(r+1)를 생성하고 해당 가중치는 초기 값으로 재설정된다.
Comparing FedDST to prior pruning works in FL.
FedDST는 기존의 FL 가지치기 작업과 몇 가지 중요한 차이점을 가지고 있다.
LotteryFL와의 비교
-
글로벌 모델 vs. 로컬 모델 :
-
LotteryFL : 로컬 데이터셋에서만 잘 작동하는 희소 모델 시스템을 생성
-
FedDST : 시간이 지남에 따라 동적으로 변화하며 모든 곳에서 잘 작동하는 하나의 글로벌 희소 모델을 생성
-
-
연결 마스크 조정 :
-
FedDST : " 클라이언트와 서버 모두에서 마스크 조정을 수행
- 상대적으로 적은 오버헤드(층별 크기 가지치기 및 그래디언트 크기 성장을 사용)
-
LotteryFL : 전체 모델이나 그래디언트를 전송하고, 학습 초기 단계에서도 밀집 모델을 학습
- FedDST보다 훨씬 무겁다.
-
PruneFL와의 비교
-
비현실적인 설정 :
-
PruneFL : 초기 라운드 이후 클라이언트 마스크를 재조정하지 않으며, 특정 라운드에서 서버에 밀집 그래디언트를 전송하고, 서버가 다음 라운드의 마스크를 결정
- 데이터 이질성으로 인해 클라이언트 간 그래디언트 크기를 직접 비교할 수 없기 때문에, 그래디언트 집계가 본질적으로 불안정해진다.
-
-
비교적 높은 오버헤드 :
-
PruneFL : 대부분의 라운드에서 희소 업데이트를 전송하지만, 마스크 조정을 위해 몇 라운드마다 밀집 그래디언트를 전송
-
FedDST : 학습 전체 동안 고정된 희소성 예산 덕분에 네트워크 대역폭을 거의 소모하지 않는다.
-
Methodology
FedDST는 NN의 동적 희소 학습을 완전한 연합 접근 방식으로 제공한다. 이 방법에서는 모든 클라이언트에 대해 좋은 정확도를 제공하는 단일 모델을 학습하는 동시에 최소한의 연산, 메모리, 통신 자원을 소비하는 것을 목표로 한다. 특히 non-iid 설정에서도 잘 작동하도록 설계되었다.
FedDST: Overview of the General Framework
-
서버는 Evci et al. (2020)에서 설명된 층별 희소성 분포에 따라 서버 네트워크 θ^1과 희소 마스크 m^1을 초기화한다.
-
각 라운드 r에서, 서버는 클라이언트 C_r를 샘플링한다.
-
서버 네트워크와 마스크는 클라이언트 c ∈ C_r로 전송된다.
-
각 클라이언트는 로컬 학습을 E 에포크 수행한다.
-
로컬 학습의 마지막 에포크 후, 클라이언트는 모델 질량의 α_r을 다른 연결로 재할당하는 마스크 조정을 수행한다.
조정은 특정 라운드에서만 수행되며, 조정 빈도는 ΔR로 지정된다.
-
선택된 클라이언트는 새로운 희소 네트워크와 마스크(필요한 경우)를 서버에 업로드하며,
서버는 수신된 정보를 집계하여 새로운 글로벌 매개변수와 마스크 (θ^r+1, m^r+1)를 생성한다.
클라이언트 측 마스크 조정 절차는 RigL에서 영감을 받았으며, 모델 질량의 α_r 을 재할당하여 더 효과적인 하위 네트워크를 찾는 것이 목표이다.
-
먼저 네트워크를 더 높은 희소성 S+(1−S)α_r로 가지치기한 후, 동일한 수의 가중치를 그래디언트 g_c^r를 통해 다시 성장시켜 원래 희소성으로 돌아간다.
-
같은 라운드에서 다른 클라이언트는 완전히 다른 방향으로 마스크 공간을 탐색한 다양한 희소 네트워크를 생성할 수 있기 때문에, 서버는 이러한 다양한 희소 네트워크를 집계해야 한다.
-
α_r을 위해 코사인 감쇠 업데이트 스케줄을 사용한다.
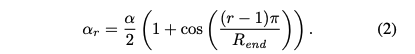
첫 번째 라운드에서는 a_1 = a이고, 재할당된 가중치의 비율은 라운드 R_end까지 0으로 감소한다.
α 값이 클수록 마스크 공간을 더 빠르게 탐색하고, 값이 작을수록 점진적 조정과 클라이언트 간의 합의를 촉진한다.
실험을 통해 α의 변화가 모델 성능에 미치는 영향을 탐구한다.
Server Aggregation with Robustness to Heterogeneity
서버 통합 방법은 클라이언트 이질성에 견고하도록 설계되었다. 서버는 클라이언트로부터 기울기를 직접 받지 않고, 클라이언트가 보낸 매개변수와 마스크를 사용하여 다음 라운드의 마스크를 결정한다.
이는 sparse weighted average를 사용하여 수행된다:
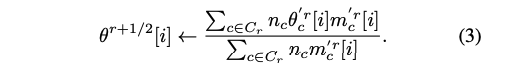
이 방법은 FedAvg에서 사용된 가중 평균에서 영감을 받아, 특정 매개변수에 대한 클라이언트의 영향을 해당 클라이언트의 데이터셋 크기로 가중치를 부여한다.
FedDST에서는 클라이언트가 가중치를 제거한 경우 해당 클라이언트의 매개변수 값은 무시되어, 병적인 non-IID FL 환경에서 도움이 된다.
이 접근 방식은 클라이언트 간 기울기 크기가 크게 달라질 수 있는 PruneFL과 같은 방법에서 발생하는 마스크 불안정성 문제를 피할 수 있다.
FedDST는 가중치 크기와 클라이언트의 "투표"를 사용하여 마스크 결정을 내려 이 문제를 해결한다.
Accuracy Gains from Dynamic Sparsity: A SpatialTemporal Ensembling Effect.
FedDST는 통신 및 계산 절감뿐만 아니라 성능 향상도 제공한다. 이는 특히 non-IID 환경에서 두드러진다. 이러한 향상은 공간-시간 앙상블 효과 덕분이다:
-
공간 앙상블 : FedDST에서는 클라우드에서 모든 클라이언트로 하나의 마스크가 전송되지만, 각 클라이언트는 마스크를 조정하고 로컬 데이터에 따라 가중치를 재샘플링할 수 있다.
이러한 새로운 희소 마스크와 가중치는 클라우드에서 주기적으로 재조립되어 드롭아웃과 유사한 정규화 효과를 만든다. 각 클라이언트는 밀집된 클라우드 모델의 다른 서브네트워크를 효과적으로 샘플링하여 글로벌 모델의 강인함을 제공한다.
-
시간 앙상블 : FedDST는 마스크 공간을 시간에 따라 탐색하면서 가중치 theta^r를 학습한다.
이는 훈련 내내 지속적인 매개변수 탐색을 가능하게 하여, 공간-시간 과잉 매개변수화를 통해 희소 학습의 표현력과 일반화 능력을 크게 향상시킬 수 있다.
이 공간-시간 앙상블 효과는 FedDST에만 고유하며, 다른 FL 가지치기 방법에 비해 우수한 성능을 제공한다.
Extending FedDST to Other FL Frameworks
위의 기본 예시에서 보았듯이, FedDST는 다양한 로컬 및 글로벌 최적화 도구를 쉽게 수용할 수 있다. 알고리즘 1은 FedDST의 일반적인 개요를 보여주며, 로컬 훈련은 필요에 따라 다양한 최적화 도구를 사용할 수 있다.
예를 들어, 실험에서 로컬 최적화 도구로 모멘텀을 사용하는 SGD를 사용했다. 집계된 희소 업데이트로 생성된 pseudo-gradients도 다른 글로벌 최적화 도구와 함께 사용할 수 있다.

-
서버에서 초기 모델을 설정하고, 각 라운드마다 클라이언트를 샘플링한다.
-
클라이언트는 로컬 데이터를 이용해 희소 네트워크를 학습하고, 특정 라운드마다 마스크를 재조정한다.
-
서버는 클라이언트로부터 업데이트된 모델을 수집하여 집계하고, 가지치기를 통해 희소성을 조정한다.
θ^{r+1/2} : 중간 집계 네트워크. 서버가 클라이언트로부터 갱신된 로컬 네트워크 마스크를 집계한 것
θ^{r+1} : 층별 크기 기반 가지치기를 수행하여 희소성 분포 S를 달성한 최종 모델
FedDST는 FedProx와 그 proximal 페널티 || theta_r^c - theta_r ||_2와도 호환된다.
FedProx
: 모델 파라미터의 변화량을 제한하는 추가적인 페널티 항을 포함하는 연합 학습 방법
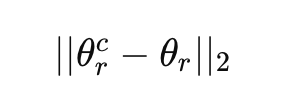
proximal 페널티 항
: 클라이언트 모델 θ_r^c가 서버 모델 θ_r와 크게 다르지 않도록 강제하는 역할을 한다.
그러나 이 페널티를 마스크 재조정에 직접 사용하면, 페널티가 pruning된 가중치에 가중치 감소 항으로 작용하게 된다. 이로 인해 이러한 가중치가 다시 활성화될 가능성이 낮아진다. 따라서 클라이언트 성장 시, proximal term 없이 손실에 해당하는 그라디언트를 사용한다.
Communication and Local Training Savings
Communication Analysis
FedDST는 업로드 및 다운로드 링크 모두에서 상당한 대역폭 절약을 제공한다. FedDST에서는 각 라운드에서 동일한 희소성 S가 유지되며, 마스크는 최대 Delta R 라운드마다 한 번씩만 업로드 및 다운로드된다.
따라서 FedDST의 평균 업로드 및 다운로드 비용은 다음과 같다:

n : 네트워크의 파라미터 수
R_end 이후에는 비용이 32(1 - S)n 이 된다. 또한, 어떤 클라이언트에서든 최대 업로드 또는 다운로드 비용은 (32(1 - S) + 1) n 비트로, 어떤 라운드에서도 큰 업로드 부담을 회피할 수 있다.
이러한 업로드 비용 절약은 느린 연결을 가진 클라이언트가 전체 모델이나 그라디언트를 업로드해야 하는 상황을 방지하여, 실질적으로 스트래글러 문제를 해결하는 데 도움이 된다.
상업적인 FL 시스템에서 많은 클라이언트를 고려할 때, 특정 클라이언트가 한 번만 선택될 가능성이 높다. 이러한 대역폭 비용 상한으로 인해, FedDST는 셀룰러 네트워크에서도 FL을 통해 모델 학습을 실용적으로 만든다.
이는 PruneFL과 대조된다. PruneFL은 클라이언트가 매 Delta R 라운드마다 전체 그라디언트를 서버로 전송해야 하므로, 평균 업로드 비용은 다음과 같다:
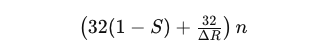
따라서 FedDST는 PruneFL보다 업로드 비용 면에서 최대 5배 저렴하다.
PruneFL은 또한 초기 희소성 패턴을 제공하기 위해 하나의 클라이언트에 의존한다. FL의 로컬 클라이언트 이질성 때문에, 하나의 클라이언트에 의해 생성된 마스크는 해당 클라이언트의 로컬 데이터 분포를 반영하는 경향이 있다.
같은 이유로, 나중에 희소성 패턴에 대한 업데이트는 불안정성을 보인다. FedDST는 초기 무작위 마스크로 시작한 후 희소 가중 평균 집계를 통해 이러한 문제를 완전히 회피한다.
Computation Analysis
FedDST는 FL 과정에서 희소 네트워크를 유지함으로써 로컬 계산 작업량을 상당히 절약한다. FedDST의 어떤 부분도 밀집 훈련을 요구하지 않는다. FLOP 절약 측면에서, 이는 모델의 희소성에 비례하여 훈련 및 추론에서 대부분의 FLOP를 건너뛸 수 있음을 의미한다.
예를 들어, CIFAR-10에서 사용하는 네트워크의 경우 80% 희소성에서 순방향 계산에 0.8 MFLOP만 필요하지만, 밀집 네트워크에는 4.6 MFLOP가 필요하다.
같은 이유로, 누적 업로드 데이터 제한과 관련된 실험도 다양한 FLOP 한도에서의 정확도를 대략 반영한다.
기존의 관례에 따라, FedDST는 현재까지 요소별 비구조적 희소성만 고려하고 있다. 비구조적 희소성은 전통적으로 불규칙한 접근으로 인해 실제 하드웨어 이점으로 번역하기 어렵다고 여겨졌다.
그러나 70%-90% 비구조적 희소성에서, XNNPack은 최근 스마트폰에서 밀집 기준보다 상당한 속도 향상을 보여, FL 하드웨어 플랫폼에서 실질적인 로컬 훈련 속도 향상을 최적화하고, 동적 희소 훈련에 구조적 희소성을 통합하는 미래 작업에 동기를 부여한다.
