Mixture of Attention Heads: Selecting Attention Heads Per Token
Paper: https://arxiv.org/abs/2210.05144
Abstract
Mixture of Expert 네트워크는 모델 용량을 확장하고 조건부 계산을 구현하는 효율적인 방법으로 제안되었다. 그러나 MoE 구성 요소에 대한 연구는 주로 Transformer 아키텍처의 피드포워드 레이어에 집중되었다.
이 논문은 Mixture of Attention Heads라는 새로운 아키텍처를 제안하여 Multi Attention 메커니즘과 MoE 메커니즘을 결합한다. MoA는 각자 고유한 매개변수를 가진 일련의 Attention Head를 포함한다.
주어진 입력에 대해 라우터가 동적으로 토큰별로 k개의 Multi Head의 부분 집합을 선택한다. 이러한 조건부 계산 방식은 MoA가 표준 Multi Attention 레이어보다 강력한 성능을 발휘할 수 있게 한다. 더 나아가, 희소하게 게이트된 MoA는 계산 효율성을 유지하면서 Attention 헤드와 매개변수의 수를 쉽게 확장할 수 있다.
성능 향상 외에도 MoA는 자동으로 헤드의 유틸리티를 구분하여 모델의 해석 가능성에 대한 새로운 관점을 제공한다. 기계 번역과 마스킹된 언어 모델링을 포함한 여러 중요한 작업에 대해 실험을 수행했다. 실험 결과, 큰 규모와 매우 깊은 모델을 포함하는 강력한 기준선 대비 여러 작업에서 유망한 결과를 보여주었다.
1. Introduction
최근 몇 년 동안 대형 모델은 자연어 처리(NLP) 연구에서 인기를 끌고 있으며, 특히 대규모 Transformer에 집중되고 있다. 모델의 용량은 수백만 개의 매개변수에서 수십억 개의 매개변수, 심지어 수조 개의 매개변수로 증가하고 있다. 그러나 이러한 대규모 모델은 소규모 모델에 비해 상당히 많은 계산을 요구한다.
인기 있는 추세는 희소하게 활성화된 모델을 사용하여 더 큰 계산 효율성을 추구하는 조건부 계산을 활용하는 것이다. 따라서 특정 입력에 대해 forward 연산 동안 모델의 매개변수 중 일부만 사용되어 계산 부하를 줄일 수 있다.
이 시도들 중에서 Mixture of Experts (MoE) 은 중요한 기술이다. 처음으로 전문가 혼합을 Transformer 아키텍처에 적용한 이후, 연구자들은 주로 피드포워드 네트워크 레이어와 expert loads를 결합하는 데 집중해왔다. 최근 연구들은 더 나은 라우팅 전략을 찾는 방법이나 여러 GPU 노드에서 전문가 혼합을 확장하는 방법에 대해 논의했다.
그러나 MoE를 Multi-Head Attention과 결합하는 가능성은 거의 탐구되지 않았다. MHA는 Transformer 아키텍처에서 또 다른 필수 모듈이기 때문에, MoE와 Attention 메커니즘을 결합하면 계산 비용을 억제하면서도 더 나은 성능을 달성할 수 있다.
또한, 이전 연구들은 서로 다른 Attention Head의 유용성을 조사했다.
-
Peng et al.(2020)은 Attention Head의 하위 집합을 재배치하는 것이 번역 작업에 도움이 된다는 것을 발견했는데, 이는 쓸모없는 attention head를 제거하기 때문이다.
-
의존 구문 분석 분야에서는 BERT와 같은 언어 모델에서 일부 Attention Head가 개별 의존성 유형 및 구문적 기능을 모델링한다는 것을 밝혀냈다.
-
Voita et al.(2019)은 Attention Head가 세 가지 유형으로 분류될 수 있는 다양한 기능을 가지고 있다고 주장했다.
따라서 입력 토큰에 대해 모든 multi attention head를 통과할 필요가 없으며, 적절한 기능을 가진 관련 attention head를 선택할 수 있다면 더 효율적일 것이다. 이에 따라 토큰별로 다른 attention head를 선택하는 attention 메커니즘을 구상하게 되었다.
위의 논의를 바탕으로, Mixture of Attention Heads, MoA을 제안했다. 이는 서로 다른 입력에 대해 서로 다른 attention head를 선택하는 attention 메커니즘이다.
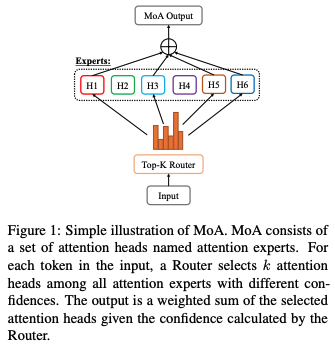
이 아이디어의 간단한 예시는 그림 1에 나와 있다. MoA는 서로 다른 매개변수를 가진 일련의 attention head를 포함한다.
-
주어진 입력에 대해 라우팅 네트워크가 동적으로 각 토큰에 대해 k개의 Attention Head 하위 집합을 선택한다.
-
출력은 라우팅 네트워크가 계산한 신뢰도에 따라 선택된 Attention Head의 가중 합계로 이루어진다.
기계 번역 및 마스킹된 언어 모델링 두 가지 작업에서 실험을 수행했다. 실험 결과는 여러 강력한 기준선 대비 유망한 결과를 보여주었다. 모든 작업에서 제안한 Attention Head의 Mixture는 원래의 Transformer 아키텍처를 능가했다. 본 논문의 모델은 많은 대형 모델을 능가하거나 절반의 계산 비용으로도 비슷한 결과를 얻을 수 있었다.
기여는 다음 세 가지로 요약될 수 있다:
1) Attention 메커니즘과 전문가 혼합 아이디어를 결합한 새로운 Attention 메커니즘인 Mixture of Attention Heads을 제안했다.
2) MoA는 매개변수와 계산 비용을 크게 추가하지 않고도 모델의 성능을 향상시킬 수 있다.
3) MoA는 계산 복잡성을 억제하면서 쉽게 확장할 수 있어 추가적인 성능 향상을 가져온다.
2. Related Work
Mixture of Experts
전문가 혼합(MoE)은 1990년대 처음 도입되었다.
-
Shazeer et al. (2017)은 이 방법을 현대 심층 학습 아키텍처(LSTM)에 도입하여 언어 모델링과 기계 번역에서의 효과를 입증했다. MoE는 Transformer 아키텍처의 FFN 레이어를 Mesh TensorFlow 라이브러리를 통해 대체하는 데 사용되었다.
-
Gshard는 6000억 개 이상의 매개변수를 가진 다국어 신경 기계 번역 Transformer를 Sparse-Gated Mixture of Experts로 확장할 수 있는 경량 모듈이다.
-
Switch Transformer에서는 MoE가 통합된 Transformer 아키텍처를 수조 개 매개변수 모델로 확장니다.
-
GLaM은 디코더 전용 아키텍처를 활용하여 언어 모델 사전 훈련을 수행했다.
-
Pyramid-Residual-MoE는 더 작은 모델 크기와 빠른 추론을 위해 제안되었다.
다양한 라우팅 전략이 MoE 훈련을 안정화하고 전문가 간의 작업 부하를 균형 있게 분배하기 위해 조사되었다.
- Sparse Mixture of Experts 모델에서 표현 붕괴 문제를 지적하고 두 단계 라우팅 전략으로 해결했다.
Machine Translation Architectures
원래의 Transformer 아키텍처를 사용하여
-
Ott et al. (2018)은 정밀도를 줄이고 대형 배치로 훈련하면 번역 성능이 향상될 수 있음을 발견했다. 일부 모델은 더 큰 규모의 Transformer를 사용하여 번역 성능을 향상시켰다.
-
Liu et al. (2020a)은 모델을 적절히 초기화하여 Transformer의 인코더와 디코더를 깊게 만들었다.
-
DeepNet(Wang et al., 2022)은 새로운 정규화 함수를 도입하여 Transformer를 1,000 레이어로 확장했다.
그러나 이러한 방법들은 많은 계산 비용이 필요하다. 일부 모델은 Self Attention 메커니즘에 변화를 주었다.
-
Peng et al. (2020)은 Attention Head의 재배치가 번역 성능을 향상시켰다고 주장했다.
그러나 이 방법은 모델의 모든 Attention Head를 사용해야 하므로 드문드문 활성화하는 것보다 확장하기 어렵고 추가적인 성능 향상을 얻기 어렵다. 또한 복잡한 블록 좌표 하강 훈련 단계를 필요로 한다.
-
Wu et al. (2019)은 자체 Attention 메커니즘을 가벼운 합성곱으로 대체하여 DynamicConv와 LightConv를 제안했다.
Specialization of Attention Heads
Transformer 아키텍처 출판 이후, 많은 연구자들이 Attention 메커니즘이 어떻게 작동하는지 분석하는 데 관심을 가졌다.
-
Voita et al. (2019)은 인코더의 Attention 헤드를 체계적으로 분석하고 이를 세 가지 기능적 하위 집합으로 분류했다: 위치적, 구문적, 희귀 단어.
-
의존 구문 분석을 처리할 때, 연구자들은 서로 다른 헤드가 서로 다른 구문적 기능을 포착할 수 있다는 동일한 현상을 관찰했다.
3. Preliminaries
3.1 Mixture of Experts
MoE는 전문가 네트워크 E1,E2,…,EN과 라우팅 네트워크 G로 구성된다. MoE의 출력은 각 전문가 출력의 가중합이다. 라우팅 네트워크는 각 전문가의 확률을 계산한다.
공식적으로, MoE의 출력은 다음과 같이 쓸 수 있다:
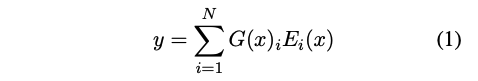
라우팅 네트워크 G는 Noisy Top-k 라우팅 네트워크이다. 소프트맥스 함수 이전에, 그들은 게이트 logit에 가우시안 노이즈를 추가한다. 그런 다음, 상위 k개의 값만 유지하고 나머지 게이트 값을 0으로 설정한다.
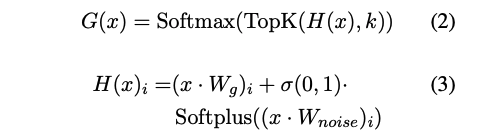
3.2 Multi-head Attention
Vaswani et al. (2017)는 인코더-디코더 아키텍처인 Transformer를 제안했으며, 이 아키텍처에는 Multi-head Attention 모듈이 포함되어 있다. Multi-head Attention 모듈의 다양한 헤드는 서로 다른 표현 하위 공간의 정보를 주목하며, 이는 다양한 관점에서 입력을 학습한다.
k개의 헤드로 다중 헤드 어텐션을 수행할 때, Q, K, V는 서로 다른 학습된 선형 프로젝션을 통해 k번 선형적으로 투영된다. 각 투영된 Q와 K에서, 어텐션 점수는 다음 식을 통해 계산된다:

서로 다른 헤드에서 유도된 값들은 다시 모델 차원 크기로 투영되고, 다음 식에 따라 합산된다:
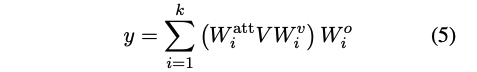

4. Mixture of Attention Heads
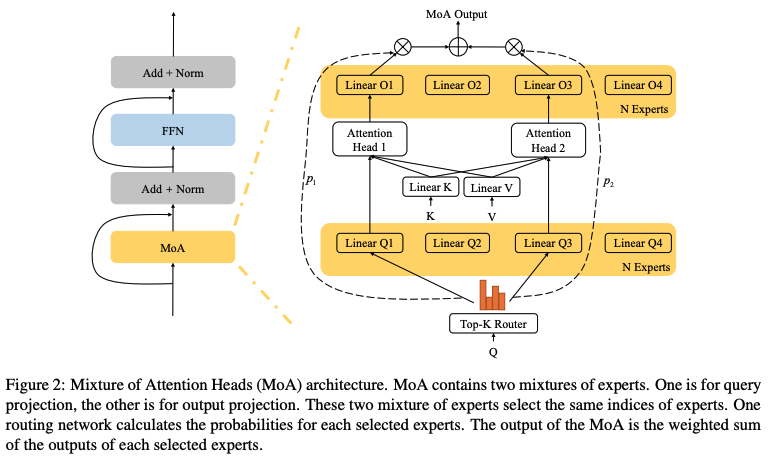
이 연구에서는 Transformer의 Multi-head Attention을 변형한 Mixture of Attention Heads (MoA)를 제안한다. MoA는 그림 2에 설명된 대로 두 가지 주요 구성 요소로 이루어져 있다:
-
라우팅 네트워크 G와 N개의 Attention Expert 그룹 {E1,...,EN}
-
표준 Multi-head Self Attention과 유사하게, MoA의 입력은 세 개의 시퀀스인 쿼리 시퀀스 Q, 키 시퀀스 K, 값 시퀀스 V를 포함한다.
-
시간 단계 t에서 쿼리 벡터를 q_t 라고 한다.
-
각 q_t에 대해 라우팅 네트워크 G는 q_t를 기반으로 k개의 전문가 E_i 중 G(q_t) ⊆ E_i를 선택하고 각 선택된 전문가에 가중치 w_i를 할당한다.
-
그런 다음, 선택된 전문가들이 q_t, K, V를 입력으로 받아 출력 E_i(q_t, K, V)를 계산한다. MoA의 출력은 선택된 전문가 출력의 가중합이다.
공식적으로, 시간 단계 t에서 MoA 출력은 다음과 같이 쓸 수 있다:
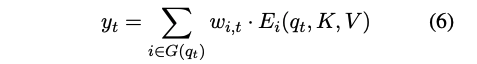
4.1 Routing Network
이전의 mixture-of-expert 방법과 유사하게, 라우팅 네트워크는 입력 쿼리에 전문가를 할당한다. 쿼리 q_t에 대해 k개의 전문가를 선택하려면, 각 전문가 E_i에 대한 라우팅 확률 p_i 를 계산한다.
라우팅 확률은 선형 레이어 W_g 와 소프트맥스 함수로 모델링된다:
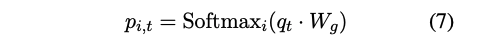
라우팅 확률 p를 기반으로, 확률이 가장 큰 k개의 Attention Expert를 모든 N개의 Attention Expert 중에서 선택한다. 공식적으로, 라우팅 네트워크는 다음과 같이 정의된다:

여기서 W_g ∈ R^d_m×N 는 라우팅 행렬을 나타낸다. 그런 다음, 선택된 전문가들의 라우팅 확률을 재정규화하여 정규화된 전문가 가중치를 얻는다:
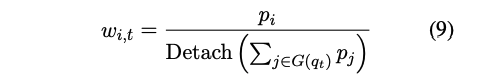
여기서 Detach(·)는 그래디언트 역전파를 멈추는 함수이다. 즉, 분모는 훈련 과정에서 그래디언트를 받지 않는다. 이 방법은 라우팅 네트워크가 더 나은 라우팅 확률을 학습하도록 도와준다.
4.2 Attention Expert
Attention Expert는 네 가지 서로 다른 투영 행렬 Wq, Wk, Wv, Wo를 포함한다. Attention 계산은 Multi Head Attention과 유사하다.
먼저 키에 대한 Attention 가중치를 계산한다:
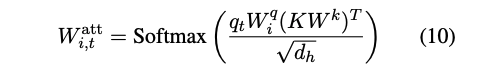
W_q^i ∈ R^{d_m*d_h} : 쿼리 투영 행렬
W_k^i ∈ R^{d_m*d_h} : 키 투영 행렬
d_m : 히든 상태 크기
d_h : 헤드 차원
그런 다음 값의 가중합을 계산한다:
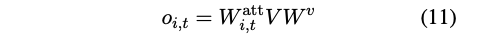
W_v ∈ R^{d_m*d_h} : 값 투영 행렬
마지막으로, attention 출력을 hidden state space로 다시 투영하여 얻는다:
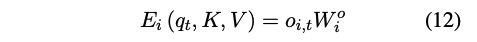
W_o^i ∈ R^{d_h*d_m} : 출력 투영 행렬
Multi-head attention에서는 projection matrix Wq, Wk, Wv, Wo가 모두 attention head 간에 다르다. MoA는 계산 복잡성을 줄이기 위해 Attention Expert 간에 Wk와 Wv를 공유한다.
Attention Expert는 오직 W_q^i와 W_o^i로만 구분된다. 따라서 key sequence KW_k와 value sequence VW_v의 비싼 행렬 투영은 사전 계산 및 모든 Attention Expert와 공유될 수 있다.
각 Expert는 쿼리 q_t W_q^i와 출력 o_i,t W_o^i의 벡터 투영만 계산하면 된다. 이 설계는 전문가의 수가 많을 때 계산 및 공간 복잡성을 크게 줄일 수 있다.
4.3 Training Losses
이전 연구에서는 라우팅 네트워크가 항상 동일한 몇몇 전문가에게 큰 가중치를 부여하는 상태로 수렴하는 경향이 있음을 관찰했다. 이는 모든 전문가의 활용이 부족함을 나타낸다.
Shazeer et al. (2017) 및 Fedus et al. (2021)을 따르며, 다른 전문가들의 부하를 균형 있게 하기 위해 보조 손실을 추가한다.
주어진 N개의 전문가와 T개의 쿼리로 구성된 시퀀스 Q = {q1, q2, ..., qT}에 대해 보조 손실 L_a는 다음과 같이 계산될 수 있다:
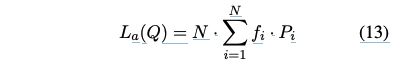
여기서 f_i는 i번째 전문가에게 할당된 토큰의 수이다:
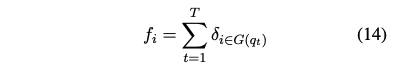
여기서 delta는 Kronecker-Symbol을 나타낸다.

Pi는 i번째 전문가에게 할당된 라우터 확률의 합이다:
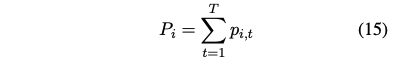
그런 다음 이들은 전문가 열에 따라 1로 정규화된다. 수학적으로, f_i는 미분 불가능하지만 P_i는 미분 가능하다. 따라서 더 큰 f_i는 더 큰 미분 값을 가져온다. 이는 더 큰 P_i를 작게 만드는 것을 페널티로 준다. 더욱이, P_i는 소프트맥스에 의해 계산된다. 따라서 더 작은 P_i는 더 커지게 된다.
Zoph et al. (2022)은 게이팅 네트워크에서 큰 logit을 페널티로 주는 라우터 z-손실(식 16)을 도입하여 훈련을 안정화하고 성능을 향상시켰다.
여기서 x_i,t는 i번째 전문가와 입력 쿼리 q_t에 대해 라우터에 의해 계산된 소프트맥스 전 logit이다.
각 Attention Head의 혼합 모듈에는 보조 손실과 라우터 z-손실이 있다.
이들을 합산하고, 곱셈 계수 α와 β를 각각 추가하여 훈련 중 전체 모델 손실에 추가한다. 이 연구 전반에 걸쳐 α=0.01과 β=0.001을 사용하여 두 추가 손실의 효율성을 보장하고 주요 교차 엔트로피 모델 손실에 방해되지 않도록 한다.
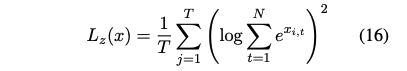
4.4 Computational Complexity and Number of Parameters
한편으로, T개의 토큰을 가진 시퀀스가 주어졌을 때, top-k 전문가를 선택하는 MoA 레이어가 요구하는 계산량은 다음과 같다:
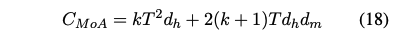
kd_h : 선택된 전문가의 헤드 차원의 합을 나타내며, 이는 MoA 레이어가 토큰에 대해 수집할 수 있는 최대 정보량을 나타낸다.
다른 한편으로, 표준 다중 헤드 어텐션(MHA)이 요구하는 계산량은 다음과 같다:
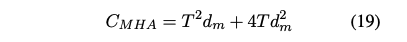
d_m : 헤드 차원의 합
만약 kd_h ≈ d_m이라면, MoA의 계산 복잡도는 MHA보다 작다. 즉, MoA는 각 토큰에 대해 더 많은 정보를 수집하면서도 MHA와 유사한 수준의 계산 복잡도를 유지할 수 있다.
파라미터 수에 대해서는, E개의 어텐션 전문가를 가진 Mixture of Attention Heads가 주어졌을 때, MoA와 MHA의 파라미터 수는 다음과 같다:
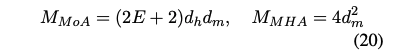
k=E이고 Ed_h ≈ d_m 일 때, MoA의 파라미터 수는 MHA보다 작다. 즉, MoA는 각 토큰에 대해 더 많은 정보를 수집하면서도 MHA와 유사한 파라미터 수를 유지할 수 있다. 계산의 자세한 내용은 부록 B에 있다.
위의 논의는 정보 수집 관점에서 MoA가 표준 MHA보다 계산 및 파라미터 효율성이 더 높음을 시사한다. 추가적으로, MoA의 시간 복잡도는 어텐션 헤드의 수 k와 어텐션 헤드 차원 d_h에 의해 결정되며, 모델의 총 파라미터 수에 의해 결정되지 않는다. 파라미터 수를 임의로 증가시킬 수 있지만, 계산 복잡도는 증가하지 않는다.
