출처 : https://eugeneyan.com/writing/llm-patterns/
LLM 기반의 시스템 & 제품 구축 패턴들
다음은 기업에서 LLM 기반 서비스를 도입하는 걸 고민할 때, 이 서비스가 “성능 향상 vs. 비용/리스크 감소” 및 “데이터 친화 vs 사용자 친화” 측면에서 어떻게 구현하는지 볼 수 있는 기준점이다.
- Evals: 성능 측정
- RAG(Retrieval-Augmented Generation): 최신, 외부 지식을 추가
- Fine-tuning: 특정 작업을 더 잘 수행하기 위해
- Caching: 레이턴시 및 비용 감소
- Guardrails: 출력 품질 보장
- Defensive UX: 오류를 에측하고 관리하기 위해
- Collect user feedback: 데이터 플라이 휠 구축
RAG(Retrieval-Augmented Generation): 지식 추가
RAG란?
- RAG는 기존 모델 외부에서 관련 데이터를 검색하여 입력을 향상시키는 방법으로, 이를 통해 결과를 개선하며 더 풍부한 맥락을 제공한다.
- 사전 훈련된 대형 언어 모델의 단점(기억을 확장하거나 수정할 수 없음, 생성된 출력에 대한 통찰을 제공하지 않음, 환상 등)을 해결하기 위해 제안되었다.
RAG의 이점:
- 환상 감소와 사실성 증가: 검색된 맥락에 근거하여 모델을 고정시킴으로써 환상을 줄이고 사실적인 결과를 얻을 수 있다.
- 비용 효율성: 사전 훈련을 계속하는 것보다 검색 인덱스를 최신 상태로 유지하는 비용이 더 적다. 이는 최근 데이터에 더 쉽게 접근할 수 있게 하여 LLM에 이점을 제공한다.
- 데이터 업데이트 용이성: 편향된 또는 유해한 데이터를 업데이트하거나 제거해야 할 경우 검색 인덱스를 업데이트하기가 (미세 조정이나 유해한 결과 생성 방지와 비교하여) 더 간단하다.
RAG의 기원:
- RAG는 오픈 도메인 Q&A에서 시작되었으며, 초기 Meta 논문에서는 TF-IDF를 사용하여 관련 문서를 검색하고 이를 언어 모델(BERT)에 맥락으로 제공함으로써 오픈 도메인 Q&A 작업의 성능을 향상시켰다.
Retrieval Augmented Generation (RAG)
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
추론 과정에서는 입력과 검색된 문서를 연결하고, 언어 모델은 원래 입력, 검색된 문서, 이전 i-1 토큰을 기반으로 토큰 i를 생성한다.
밀집 벡터 검색은 비매개변수 구성 요소로 작용하며, 사전 훈련된 언어 모델은 매개변수 구성 요소로 작용하기 때문에 반 매개변수 모델이라고도 불린다.
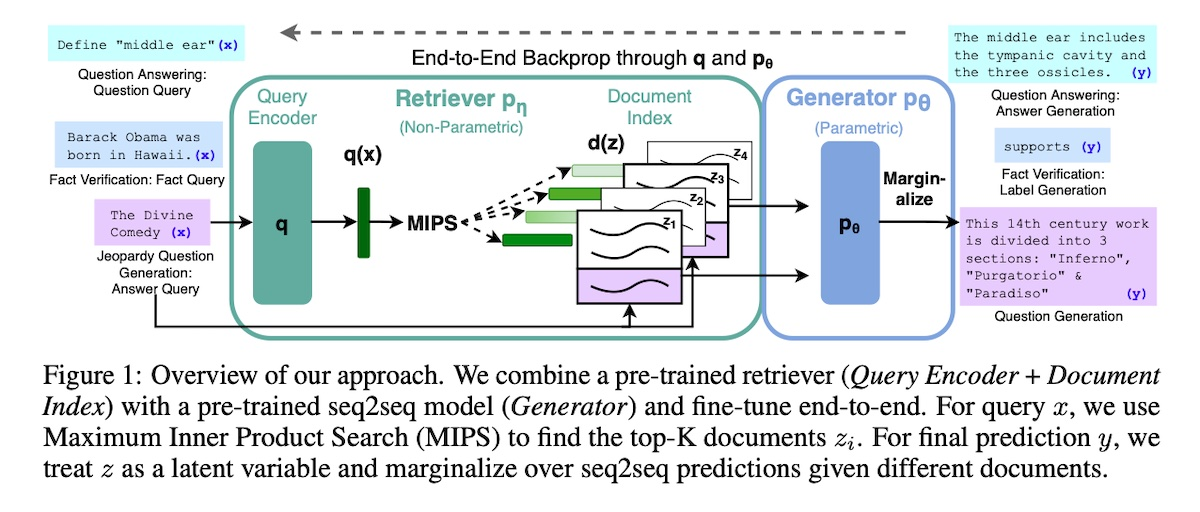
RAG의 두 가지 생성 접근 방식:
-
RAG-Sequence
완전한 시퀀스를 생성하기 위해 동일한 문서를 사용한다.
- k개의 검색된 문서에 대해 생성기는 해당 문서에 대한 출력을 생성한다.
- 각 출력 시퀀스의 확률은 k에서 각 출력 시퀀스의 확률을 합산하고, 각 문서가 검색되는 확률에 따라 가중치를 적용한다.
- 마지막으로 가장 높은 확률을 가진 출력 시퀀스가 선택된다.
-
RAG-Token
각 토큰을 다른 문서를 기반으로 생성할 수 있다.
- k개의 검색된 문서가 주어진 경우, 생성기는 각 문서에 대해 다음 출력 토큰에 대한 분포를 생성한다.
- 개별 토큰 분포를 모두 집계, 반복한다.
각 토큰 생성마다 원래 입력과 이전에 생성된 토큰을 기반으로 k개의 서로 다른 관련 문서를 검색할 수 있음을 의미한다. 따라서 문서는 다른 검색 확률을 가지며 다음 생성된 토큰에 다르게 기여할 수 있다.
Fusion-in-Decoder (FiD)
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
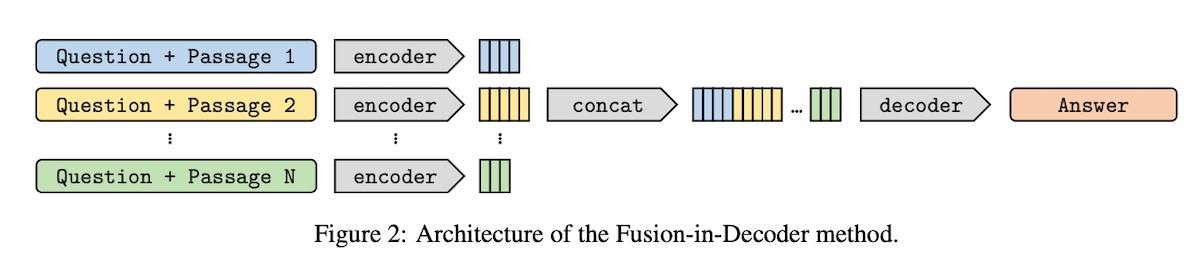
오픈 도메인 질문 응답을 위한 모델로, 검색된 정보를 활용하여 답변을 생성하는데 사용된다.
- 각 검색된 passage에 대해 제목과 passage를 질문과 결합한다.
- 결합된 쌍은 인코더에서 독립적으로 처리된다.
- 각 섹션 앞에는 question:, title:, context:와 같은 특별한 토큰이 추가된다.
- 디코더는 이러한 검색된 passage들의 연결에 attention을 기울인다.
인코더에서는 각 passage를 독립적으로 처리하기 때문에 한 번에 한 문맥에 대한 self-attention만 필요하므로 많은 수의 passage에 대해 확장할 수 있다. 따라서 연산이 검색된 passage의 수와 선형적으로 증가하므로, RAG-Token과 같은 대안에 비해 더 확장 가능하다. 디코더는 인코딩된 passage를 공동으로 처리하여 여러 검색된 passage에 걸쳐 문맥을 더 잘 집계할 수 있다.
Retrieval-Enhanced Transformer (RETRO)
Improving language models by retrieving from trillions of tokens
트랜스포머, 어텐션을 이용한 또다른 접근 방식이다.
Internet-augmented LMs
Internet-augmented language models through few-shot prompting for open-domain question answering
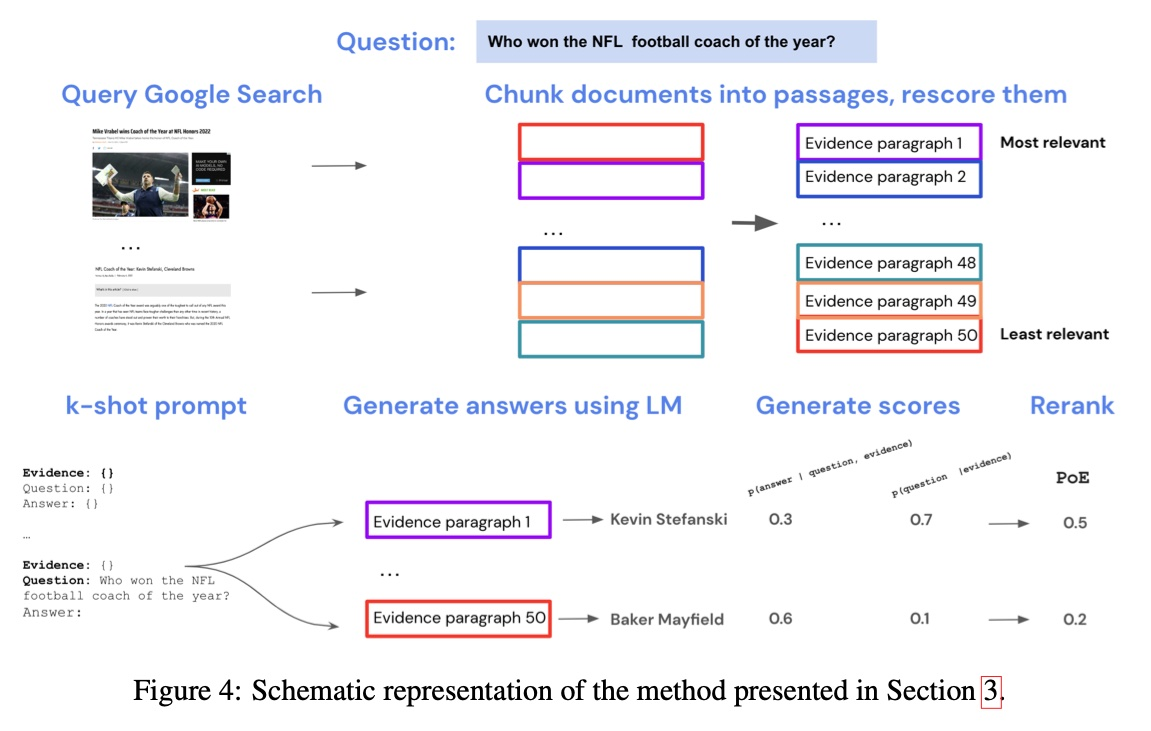
LLMs를 강화하기 위해 일반적인 "off-the-shelf" 검색 엔진을 사용하는 방안이다.
- Google 검색을 통해 관련 문서 세트를 검색한다.
- 이러한 검색된 문서들은 보통 길기 때문에(평균 길이 2,056 단어), 각각을 여섯 문장씩으로 나누어 단락으로 만든다.
- TF-IDF를 사용하여 질문과 단락을 임베딩하고, 각 쿼리에 대해 가장 관련성 높은 단락을 순위로 매긴다.
- 검색된 단락을 LLM을 few-shot prompting을 통해 조건화하는 데 사용한다.
- closed-book QA(질문-답변 쌍만 제공)에서 일반적인 k-shot prompting(k=15)을 채택하고, 각 문맥이 증거, 질문, 답변 세트인 방식으로 확장한다.
- 생성기는 각 질문에 대해 50개의 검색된 단락 중 각각에 기반한 네 개의 후보 답변을 생성한다.
- 답변 확률을 평가하여 최적의 답변을 선택한다.
Hypothetical document embeddings (HyDE)
Precise Zero-Shot Dense Retrieval without Relevance Labels
질문과 문서 쌍에 대한 관련성 레이블이 없는 경우 쿼리와 문서를 같은 임베딩 공간에 내재시키는 Bi-encoder를 훈련시키기 어렵다는 문제점을 해결하기 위해 제안되었다. 관련성 모델링 문제를 표현 학습 작업에서 생성 작업으로 재구성했다.
Bi-Encoder
https://velog.io/@xuio/Cross-Encoder와-Bi-Encoder-feat.-SentenceBERT
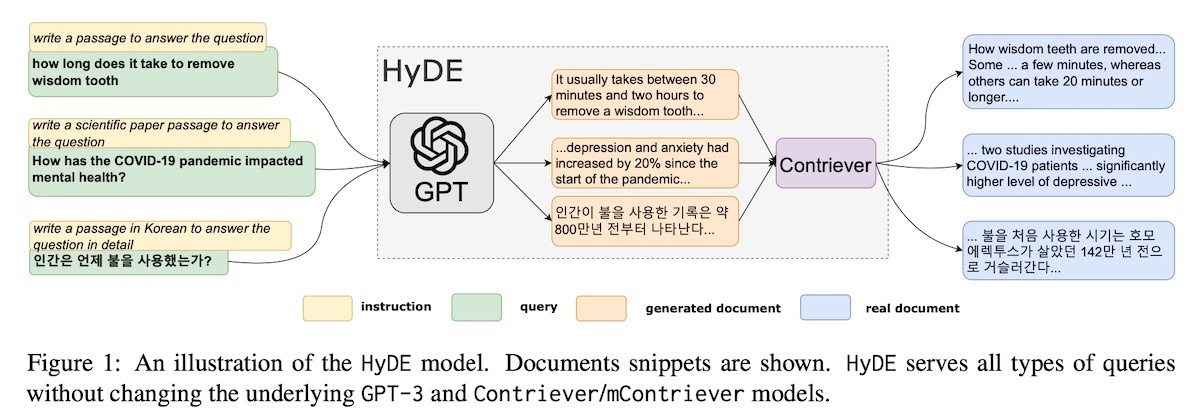
- 주어진 쿼리에 대해, InstructGPT와 같은 LLM에 가상 문서를 생성하도록 유도한다. 이 문서는 관련성 패턴을 포착하지만 실제가 아닐 뿐더러 잘못된 세부사항을 포함할 수 있다.
- Contriver와 같은 비지도 대조 학습된 인코더가 문서를 임베딩 벡터로 변환한다.
- 가상 문서와 말뭉치 간에 내적이 계산되고 가장 유사한 실제 문서가 검색된다.
이를 통해 생성된 문서를 실제 코퍼스에 묶어주며, 인코더의 dense bottleneck은 부정확한 세부사항을 걸러낼 수 있다.
RAG 적용 방법과 경험
전통적인 검색 인덱스와 임베딩 기반 검색을 혼합한 하이브리드 검색이 각각 독립적으로 사용하는 것보다 효과적이다. 고전적인 검색(BM25를 통한 OpenSearch)에 의한 검색을 보완하기 위해 의미 기반 검색(e5-small-v2)을 도입했다.
왜 임베딩 기반 검색만 사용하지 않는가?
임베딩 기반 검색이 많은 경우에 효과적이지만, 특정 상황에서는 한계가 있다.
- 사람이나 물체의 이름 검색 (예: Eugene, Kaptir 2.0)
- 약어나 구문 검색 (예: RAG, RLHF)
- ID 검색 (예: gpt-3.5-turbo, titan-xlarge-v1.01)
키워드 검색의 한계:
키워드 검색은 단순한 단어 빈도만을 모델링하며 의미론적이거나 상관 관계 정보를 캡처하지 않는다. 따라서 동의어나 상위어 (즉, 일반화를 나타내는 단어)에 대해 잘 처리하지 못한다. 이는 의미 기반 검색과 조합함으로써 상호 보완적인 효과를 얻을 수 있다.
메타데이터 활용:
전통적인 검색 인덱스를 사용하면 결과를 세분화하는 데 메타데이터를 활용할 수 있다.
- 날짜 필터를 사용하여 최신 문서를 우선적으로 처리하거나 검색을 특정 시간 범위로 제한할 수 있다.
- 전자 상거래와 관련된 검색인 경우, 평균 평점이나 카테고리에 대한 필터가 유용하다.
- 메타데이터는 하향식 순위 지정에 유용하며, 더 많이 인용되는 문서를 우선적으로 처리하거나 판매량에 따라 제품에 가중치를 부여하는 데 도움이 된다.
