Paper : https://arxiv.org/abs/2311.00945
Abstract
본 논문은 Diffusion 기반의 간단하고 효율적인 엔드투엔드 텍스트 음성 변환 모델인 Easy End-to-End Diffusion 기반 Text to Speech를 제안한다. 일반 텍스트를 직접 입력으로 받아 반복적인 정제 과정을 통해 오디오 파형을 생성한다.
이전 연구들과 달리 E3 TTS는 스펙트로그램 피처나 정렬 정보와 같은 중간 표현에 의존하지 않는다. 대신, E3 TTS는 Diffusion 과정을 통해 파형의 시간 구조를 모델링한다. 추가적인 조건 정보에 의존하지 않고 주어진 오디오 내에서 유연한 잠재 구조를 지원할 수 있다. 이를 통해 추가적인 훈련 없이 편집과 같은 zero shot 작업에 쉽게 적응시킬 수 있게 한다.
1. Introduction
Diffusion 모델은 데이터의 잠재적 표현에서 노이즈를 점진적으로 제거하여 실제 데이터와 구별이 어려울 정도로 만든다. Diffusion 모델을 사용하는 TTS 시스템은 최첨단 시스템과 유사한 고품질 음성을 생성할 수 있었다.
이 분야의 대부분의 이전 연구는 두 단계 생성 과정을 기반으로 했다.
-
생성자 모델은 중간 표현을 생성하며 일반적으로 오디오 토큰 또는 스펙트로그램 기반 특성을 생성한다. 이 중간 표현은 웨이브폼과 정렬되지만 낮은 해상도로 제공된다.
-
vocoder가 중간 특성에서 오디오를 예측한다.
두 단계 TTS 파이프라인은 높은 품질의 오디오를 생성할 수 있지만 중간 특성의 품질에 의존하는 등 다른 문제점을 가질 수 있다. 또한 다양한 상황에서 배포하고 설정하기가 더 복잡할 수 있다.
두 단계 프로세스 외에도 대부분의 모델은 텍스트를 다른 입력 단위로 변환하기 위해 추가적인 신경 모델이나 통계적 방법을 사용한다.
파형에서 강한 시간적 종속성을 효율적으로 모델링하기 어렵기 때문에 텍스트에서 오디오를 엔드투엔드로 생성하는 것은 어렵다.
-
샘플 수준의 자기 회귀 vocoder는 전체 이력에 대한 각 파형 샘플의 생성을 조건화함으로써 이러한 종속성을 처리한다. 그러나 높은 순차적 특성 때문에 현대 병렬 하드웨어에서 샘플링하는 데 비효율적이다.
-
일부 이전 작업은 대신 생성 속도를 높이기 위해 중첩되지 않는 고정 길이 블록의 시퀀스를 자동 회귀적으로 생성한다. 이는 블록 내의 모든 샘플을 병렬로 생성하여 생성 프로세스를 가속화한다.
이전 연구 중 다른 접근 방식은 훈련 중에 정렬 정보를 포함하는 것이다. 정렬 정보는 각 개별 입력 단위 (ex : 음소)와 생성된 오디오의 출력 샘플 간의 매핑을 제공한다. 이는 각 개별 입력 단위의 시작 시간과 종료 시간을 제공하는 외부 정렬 도구를 사용하여 추출된다.
-
FastSpeech 2 : 정렬 또는 지속 시간 정보 및 에너지 및 피치와 같은 다른 속성을 활용하여 오디오를 예측한다. 각 속성에 대해 하나의 내부 예측기도 훈련되어 추론 중에 예측 결과를 활용할 수 있다.
-
EATS : 미분 가능한 지속 시간 예측기를 사용하고 예측이 대상 오디오와 정렬되도록 하기 위해 Dynamic Time Wrapping (DTW)을 사용한다. 이는 외부 정렬 도구를 사용하지 않게 만들지만 훈련을 더 복잡하게 만든다.
본 논문에서는 웨이브폼의 시간 구조를 보존하기 위해 Diffusion에만 의존하는 쉬운 엔드 투 엔드 텍스트 투 스피치 프레임워크 (E3 TTS) 를 제안한다. 이는 텍스트를 직접 입력으로 받아 pretrained BERT 모델을 사용하여 정보를 추출한다. 그 후에는 BERT 표현에 주의를 기울이며 오디오를 예측하는 UNet 구조가 이어진다. 전체 모델은 non-autoregressive 이며, 직접 웨이브폼을 출력한다.
논문 구성
섹션 2 : TTS의 이전 작업에서 최적화할 수 있는 다양한 구성 요소에 대한 간략한 개요를 제공한다.
섹션 3 : BERT 표현을 입력으로 사용하는 확산 모델만을 포함하는 제안된 시스템을 소개한다.
섹션 4 : 소유 데이터셋에서의 실험을 시작하며 몇몇 이전 작업과 비교한다.
섹션 5 : 제안된 방법으로 달성할 수 있는 일부 응용 프로그램을 소개한다.
섹션 6 : 시스템을 요약하고 몇 가지 미래 작업에 대해 논의한다.
2. Complexitiex of TTS
기존 TTS 시스템의 복잡성을 크게 증가시키는 여러 구성 요소를 확인했다.
2.1. Text Normalization
입력 텍스트의 정규화는 텍스트를 쓰여진 형태에서 TTS 시스템에서 쉽게 처리할 수 있는 형태로 변환하는 과정이다. 텍스트는 다양한 방식으로 작성될 수 있기 때문에 어려운 작업이다.
-
"color"와 "colour"와 같이 동일한 단어가 다르게 쓰일 수 있다.
-
텍스트에는 약어, 두문자어 및 기타 비표준 형태가 포함될 수 있다.
2.2. Input Unit
텍스트 정규화 이후에도 동일한 단어를 다른 맥락에서 어떻게 발음해야 하는지에 대한 모호성이 남을 수 있다. 예를 들어, "record"는 명사인지 동사인지에 따라 발음이 다를 수 있다. 이것이 많은 TTS 시스템이 텍스트 대신 음운 또는 운율적 특성과 같은 발음 형태에 의존하는 이유다.
-
음운 : 음운은 단어를 구성하는 소리의 단위다. 이는 표준 쓰기 시스템이 없는 언어에서 음성을 생성하는 데 유용할 수 있다.
-
운율적 특성 : 운율적 특성은 음성의 특징으로 기본 주파수, 지속 시간 및 에너지와 같은 것들이 있다. 이는 생성된 음성의 억양과 강조를 제어하는 데 사용될 수 있다.
2.3. Alignment Modeling
정렬 모델링은 단어의 각 음운이 발음되어야 하는 시간을 예측하는 과정이다. 이는 생성된 음성이 자연스럽고 유창하게 들리도록 하는 데 중요하다. 정렬 모델링은 각 음운이 발음되는 시간에 영향을 미칠 수 있는 여러 요소가 있기 때문에 어려운 작업일 수 있다.
-
단어에서 음운의 위치
-
단어의 강세
End-to-End STT 시스템에서 정렬 모델의 전형적인 접근 방식은 정렬 정보를 제공하는 외부 정렬 도구에 의존하는 방법이 일반적이다. 모델 훈련 중에 지속 시간 예측기를 학습하여 추론에 대한 정렬을 추정하는 데 사용될 수 있는 정보를 예측한다.
-
Non-Attentive Tacotron 프레임워크 : Variational Auto-Encoder를 사용하여 지속 시간을 암묵적으로 학습하는 데 성공했다.
-
Glow-TTS 및 Grad-TTS : Monotonic Alignment Search 알고리즘 (Viterbi 훈련의 채택으로 두 시퀀스 간 가장 가능성 있는 숨겨진 정렬을 찾음)을 사용했다.
-
E3 TTS : GradTTS에서 언급한 품질 문제를 엔드 투 엔드 실험으로 해결했다.
3. METHOD
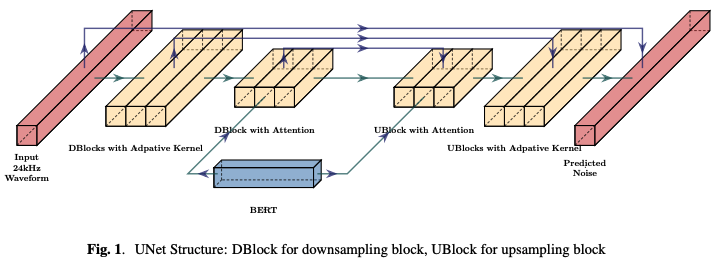
이전 섹션에서 제시된 도전 과제에 대한 해결책으로 TTS 시스템을 보다 폭넓은 커뮤니티에 접근 가능하게 만드는 솔루션을 제안한다.
-
Pretrained BERT : 텍스트에서 정보를 추출
-
Diffusion UNet : BERT 출력에 주의를 기울이고 노이즈를 포함한 웨이브폼을 반복적으로 정제하여 원시 웨이브폼을 예측
3.1. BERT model
최근의 대규모 언어 모델 개발의 장점을 활용하기 위해 미리 학습된 BERT 모델에 의해 제공되는 텍스트 표현을 기반으로 시스템을 구축했다. BERT 모델은 서브워드를 입력으로 사용하며 음운, 문자와 같은 음성의 다른 표현에 의존하지 않는다. 이는 이전 연구와 달리 사전에 훈련된 텍스트 언어 모델에 의존할 수 있기 때문에 여러 언어에 대한 텍스트 데이터만 사용하여 훈련될 수 있다.
3.2. Diffusion
E3 TTS는 score matching과 Diffusion 확률 모델에 기반한 이전 연구를 토대로 구축되었다.
TTS의 경우, 점수 함수는 조건부 분포 p(y|x)의 로그 도함수로 정의된다:
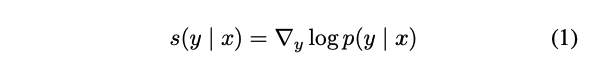
x : 조건 신호
y : 웨이브폼
Denoising Diffusion Probabilistic Models 의 특수한 매개변수화를 채택했다:
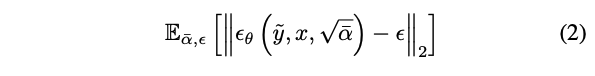
ϵ ∼ N (0, I) : 잡음 항
α¯ : 노이즈 레벨
점수 네트워크:
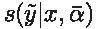
모델 예측과 실제 값 ϵ 사이의 거리를 최소화하여 스케일링된 도함수를 예측하도록 훈련된다.
y¯는 다음과 같이 샘플링된다:
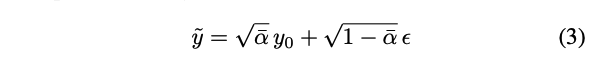
훈련 중에 α¯는 사전에 정의된 β의 선형 스케줄에 따라 간격 [α¯{n}, α¯{n+1}]에서 샘플링된다.
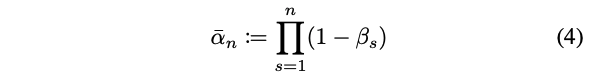
각 반복에서 업데이트된 웨이브폼은 다음과 같은 확률적 프로세스를 따라 추정된다:
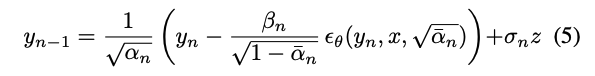
이 작업에서 수렴을 돕고 ϵ 손실의 크기를 더 잘 조절하기 위해 KL 형태의 손실을 채택했다. 또한 모델은 각 타임스텝에 대한 L2 손실의 분산 e ω(α)를 예측하고 다른 샘플된 타임스텝에서의 손실 가중치를 조절하기 위해 KL 형태의 손실을 사용한다:
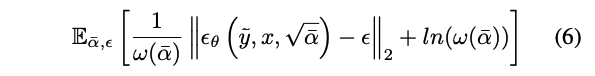
3.3. U-Net
1차원 U-Net을 도입하였으며, 이는 Photorealistic text-to-image diffusion models with deep language understanding의 구조를 따른다. 일반적인 모델 구조는 Figure 1에 나와 있으며, 일련의 다운샘플링과 업샘플링 블록으로 이루어져 있으며 잔차를 통해 연결된다.
UBlock/DBlock의 자세한 구조 :
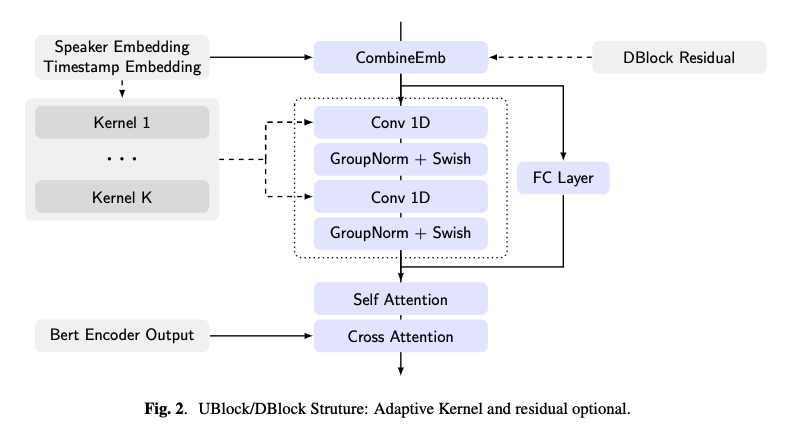
-
Autoregressive TTS의 전형적인 방법 과 같이 상위 UBlock/DBlock에서 BERT 출력으로부터 정보를 추출하기 위해 교차 어텐션을 채택한다.
-
하위 UBlock/DBlock에서는 타임스텝과 스피커에 따라 커널이 결정되는 적응형 소프트맥스 CNN 커널을 사용한다.
-
다른 레이어에서는 FiLM을 사용하여 스피커와 타임스텝 임베딩을 결합하며, 이는 채널별 스케일링과 바이어스를 예측하는 병합 레이어로 구성된다.
Feature-wise Linear Modulation (FiLM)
: 이미지로부터 추출된 각 feature map은 텍스트 입력받는 RNN 네트워크에 의해 독립적으로 조건화된다. 따라서 이미지와 텍스트의 통합된 특징을 활용할 수 있다.
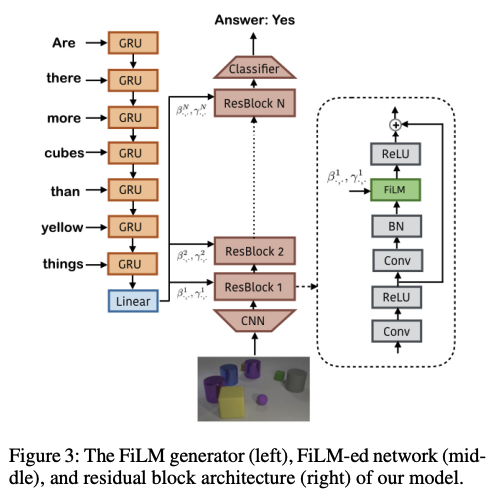
-
다운샘플러 : 마지막으로 노이즈 정보(24kHz)를 인코딩된 BERT 출력과 유사한 길이의 시퀀스로 정제한다. 이는 실제로 품질을 향상시키는 데 중요한 역할을 한 것으로 입증되었다.
-
업샘플러 : 입력 웨이브폼과 동일한 길이의 노이즈를 예측한다.
훈련 중에는 웨이브폼의 길이를 10.92초로 고정하고 웨이브폼 끝에는 zero padding을 적용했다. 손실을 계산할 때 각 패딩 프레임을 가중치 1/10로 설정했다.
추론 시에는 출력 웨이브폼의 길이를 고정하고 평균 크기를 사용하여 패딩 부분을 구별한다. 실제로 1024 샘플마다 평균 크기를 계산하고 ≤ 0.02 부분을 잘라냈다.
4. Experiement
E3 TTS를 다른 신경망 기반 TTS 시스템과 비교했다. 기준 시스템은 84명의 전문 음성 배우로부터 얻은 385시간의 고품질 미국 영어 음성으로 이루어진 독점 데이터셋에서 훈련되었다. 평가를 위해 훈련 데이터셋에서 여성 스피커를 선택했다.
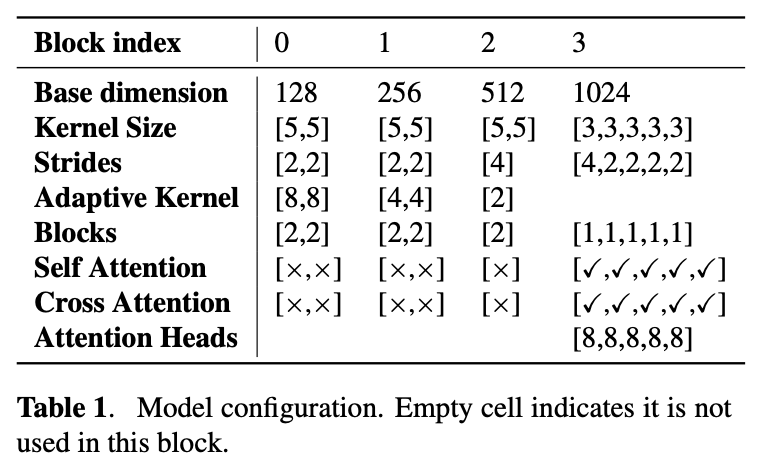
사전 훈련된 BERT에 대해서는 영어 전용 데이터에서 훈련된 기본 매개변수 크기 모델을 사용했다.
추론에서는 1000 단계 DDPM을 사용하며, 노이즈 스케줄링은 다음과 같이 정의된다:
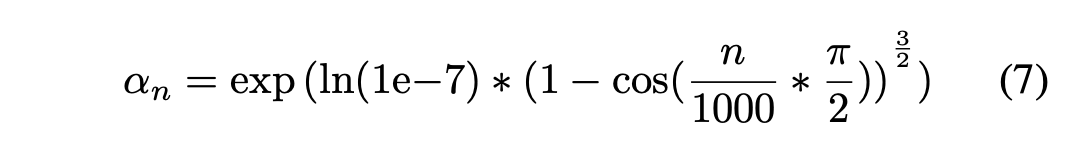
성능은 주관적 청취 테스트를 통해 측정되었으며, 헤드폰을 착용한 일부 원어민 청취자에 의해 수행되었다.
결과는 생성된 샘플의 자연스러움을 1에서 5까지의 십점 척도로 측정하는 평균 의견 점수(Mean Opinion Score, MOS)로 보고되었다. 각 샘플은 적어도 두 명의 다른 원어민 청취자에 의해 최소 두 번 평가되었다.
문자 기반 TTS 모델과 Wave-Tacotron과 본 논문의 모델을 비교하였으며, 결과는 다음과 같다:
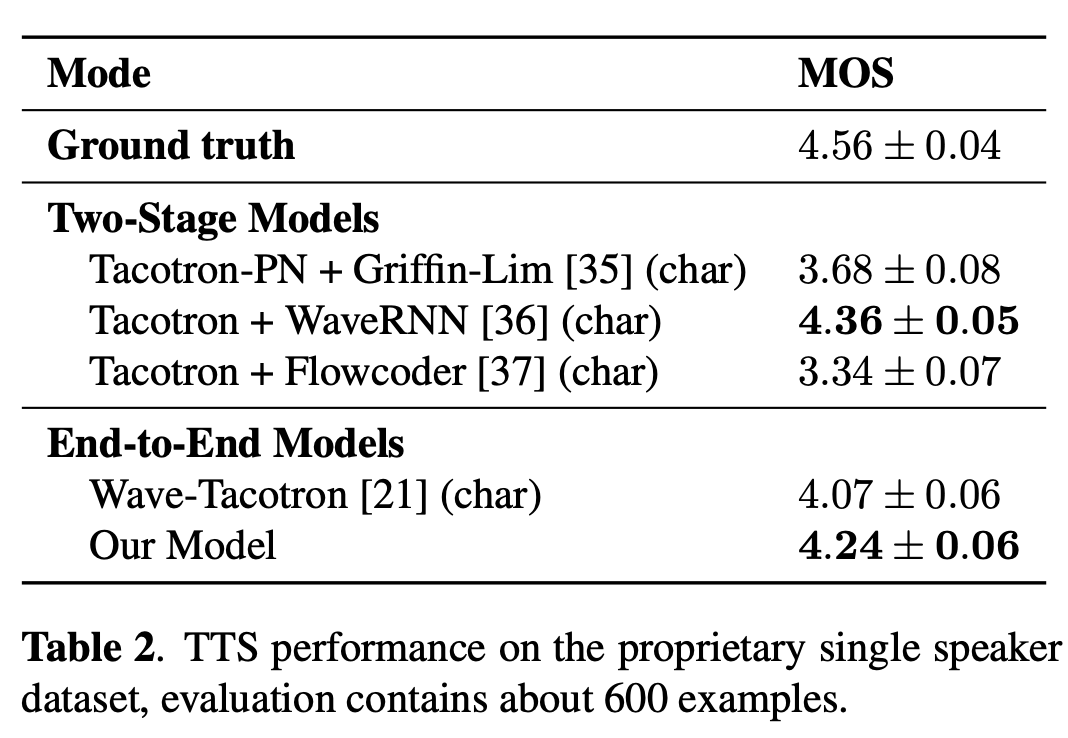
결과는 제안된 방법이 다른 end-to-end 시스템보다 더 높은 충실도를 제공한다는 것을 시사한다. 여기서의 작은 차이점은 제안된 시스템이 문자 대신에 하위 단어(sub-word)를 기반으로 하고 있다는 점인데, 본 논문에서는 그것이 TTS 적용에 비교가능해야 한다고 믿는다.
소감
해당 논문에서는 Diffusion UNet 구조로 Audio 생성을 End-to-End로 처리했으며, Pretrained BERT로 Text에 해당하는 정보를 공급해 준다. 캡스톤 프로젝트에서는 Audio의 특성에 관한 정보도 추가로 공급해 줘야 하는데, 어떤 방식으로 넣어줄지 고민해 봐야겠다.
Text에 해당하는 Audio 생성을 할 때, 사용자마다 각자가 원하는 음성이 다를 것이라고 생각했다. Diffusion UNet은 Inference 시 noise 값에 따라 다양한 output 생성이 가능하므로 프로젝트에서 사용하기에 적합한 것 같다.

tts에 대해 알아보려고 관련 논문 읽고 있었는데 제가 영어를 잘 못해서 뭔말인 지 몰라서 파파고 돌리고 그랬거든요. 근데 한글로 정리해주셔서 도움 받고 가요!