Paper : https://arxiv.org/abs/2207.02463
Github : https://github.com/kainoj/pruning-bias
💡 로 표시된 부분은 제가 이해한 내용을 적은 부분입니다. 오류가 있다면 댓글로 남겨주세요 🙏🏻
Abstract
언어 모델의 편향 제거는 NLP 커뮤니티에서 중요한 연구 분야로 떠오르고 있다. 다양한 편향 제거 기술이 제안되었지만, 편향 제거는 아직 다루지 않은 문제다. 본 논문에서는 pre-trained transformer 기반 언어 모델에서 편향을 조사하기 위한 새로운 프레임워크를 소개한다.
주어진 모델과 편향 제거 목적에 대해, 원본 모델보다 편향을 적게 포함하는 모델 하위 집합을 찾는다. 모델을 편향 제거 목적으로 fine-tuning하면서 모델을 pruning하는 프레임워크를 구현한다.
최적화 대상은 모델의 가중치와 결합된 가중치와 함께 작동하는 게이트 역할을 하는 가중치다. Pruning 대상은 트랜스포머의 중요한 구성 요소인 어텐션 헤드다. 정사각형 블록을 제거하고 전체 헤드를 pruning하는 새로운 방법을 도입한다.
마지막으로, 본 논문의 프레임워크를 성별 편향을 사용하여 시연하고, 발견된 내용을 기반으로 기존의 편향 제거 방법을 개선할 수 있는 방법을 제안한다. 모델이 성능이 더 우수할수록 더 많은 편향이 포함된다는 편향-성능 트레이드오프를 재발견했다.
1. Introduction
언어 모델(LM)에서 편향은 어디에 저장되어 있을까?
신경망 아키텍처 자체가 편향을 부과할 수 있을까?
Debiasing Pre-trained Contextualised Embeddings은 성별 편향이 트랜스포머 기반 LM의 모든 레이어에 존재한다고 제안한다. 그러나 이는 어떤 측면에서는 모호하다. 트랜스포머 레이어는 더 작은 구성 요소인 어텐션 헤드로 분해될 수 있으며, 이는 또한 행렬로 더 세분화될 수 있다.
반면에 Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned의 연구 결과는 몇몇 어텐션 헤드가 특정 작업에 특화되어 있다는 것을 보여준다. 이러한 작업에는 구문 및 위치 종속성이 포함된다. 이는 어떤 헤드나 그 부분이 편향을 학습하는 데 특화될 수 있다는 직관을 제공한다.
언어 모델에서 편향을 더 세부적으로 분석할 수 있다면, 모델 및 편향 현상에 대한 더 나은 이해를 얻을 수 있다. 편향이 어디에 저장되어 있는지를 알면 모델의 특정 부분을 대상으로 하는 편향 제거 기술을 설계하여 편향 제거를 더 정확하고 효율적으로 수행할 수 있다.
Movement pruning을 활용하여 언어 모델에서 편향을 조사하는 새로운 프레임워크를 소개한다. 이는 원래 신경망 모델을 압축하고 추론 속도를 빠르게 하는 데 사용되었다.
Movement pruning의 수정 버전을 소개하여 주어진 모델의 저편향 하위 집합을 선택하거나 동등하게 임의의 편향 제거 목적의 수렴을 이끄는 가중치를 찾을 수 있게 했다. 구체적으로 모델의 신경 가중치를 고정하고 가중치와 결합된 가중치 및 게이트 역할을 하는 pruning scores만 최적화한다. 이렇게 하면 어텐션 헤드와 같은 트랜스포머의 구성 요소가 어떤 것이 편향을 유발할 수 있는지를 조사할 수 있다.
헤드가 pruning으로 제거되고 편향 제거 목적이 수렴하면 해당 헤드에는 편향이 포함되어 있었을 것이라 가정한다.
편향은 광범위하게 연구되어 많은 편향 제거 방법이 제안되었다. 그러나 이 작업들의 대다수는 편향 감지 또는 완화의 문제만 다루고 있다.
본 논문에서는 다음을 수행했다:
-
LMs에서 편향을 조사하기 위한 독창적인 프레임워크를 시연했다. 이는 movement pruning, weight freezing 및 편향 제거의 혼합이다.
-
BERT 모델에서 성별 편향의 존재를 조사한다.
-
기존의 편향 제거 방법을 개선한다.
2. Background
2.1 Language Model Debiasing
언어 모델 편향 제거를 위한 다양한 패러다임이 제안되었다. 이에는 특징 추출 기반, 데이터 증강, 또는 어구 변형과 같은 방법들이 포함된다. 이들은 모두 특징 엔지니어링, 재훈련 또는 보조 모델 구축과 같은 추가 노력이 필요하다.
본 논문에서는 성별 편향된 편견적 연상을 제거하기 위한 Debiasing Pre-trained Contextualised Embeddings 알고리즘을 선택했다. 이는 많은 트랜스포머 기반 모델에 적용될 수 있으며 최소한의 데이터 주석이 필요하다.
이 알고리즘은 미리 정의된 성별 관련 단어의 임베딩(예: 남자, 여자)이 그들의 편견적인 동등물(예: 의사, 간호사)과 직교하도록 fine-tuning을 통해 이루어진다.
손실 함수는 이러한 임베딩의 squared dot product 및 원래 모델과 편향 제거된 모델 간의 정규화 항으로 구성된다.
💡 임베딩의 squared dot product
두 벡터가 서로 직교할 때, 내적은 0이 되며, 이는 두 벡터가 서로 독립적이고 관련이 없음을 의미한다. 따라서, 편향을 제거하기 위해서는 성별과 같은 특정 편향을 나타내는 단어의 임베딩을 그와 관련이 없는 단어의 임베딩과 직교하도록 학습해야 한다.
임베딩의 squared dot product를 최소화하면 직교를 촉진하는 효과를 얻을 수 있다. 편향을 줄이고 서로 다른 특성 간의 독립성을 유지하게 된다.
💡 원래 모델과 편향 제거된 모델 간의 정규화 항
정규화 항은 모델이 학습하는 파라미터의 값을 제한해, 모델이 특정한 패턴을 따르도록 제약을 가할 수 있다.
원래 모델과 편향 제거된 모델 간의 정규화 항은 두 모델간의 유사도를 유지하도록 유도하여 구문 정보를 보존하는 데 도움이 된다.
저자들은 임베딩의 소스 (트랜스포머 기반 모델의 모든 레이어의 첫 번째, 마지막 또는 모든 토큰) 및 손실의 대상 (대상 토큰 또는 문장의 모든 토큰)에 따라 여섯 가지의 편향 제거 모드를 제안했다.
이 모드들은 "all-token", "all-sentence", "first-token", "first-sentence", "last-token", 그리고 "last-sentence"다. 본 연구에서는 "first-*" 모드를 생략하였는데, 이는 이러한 모드가 편향 제거 효과가 미미하다는 것이 실험적으로 나타났기 때문이다.
2.2 Block Movement Pruning
Pruning은 신경망에서 일부 가중치를 비활성화하거나 제거할 때 사용된다. 이는 높은 희소성을 유발하여 모델을 더 빠르고 작게 만들면서 원래의 성능을 유지할 수 있다. 가중치가 0에 가까워질 때 해당 가중치를 제거한다.
각 가중치 행렬 W ∈ R^M×N에는 점수 행렬 S ∈ R^M/M0×N/N0이 관련되어 있으며, 여기서 (M0, N0)는 pruning block 크기다. 순전파에서 W는 그 마스크 버전인 W0 ∈ R^M×N으로 대체된다:
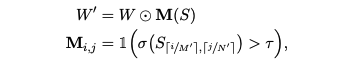
τ : 임계값
1 : 지시 함수
- 특정 집합에 특정 값이 속하는지를 표시하는 함수로, 특정 값이 집합에 속한다면 1, 속하지 않는다면 0의 값을 가진다.
- 출처 : https://ko.wikipedia.org/wiki/%EC%A7%80%EC%8B%9C_%ED%95%A8%EC%88%98
역전파에서는 W와 S 모두 업데이트된다. 원래 모델의 성능을 보존하기 위해 Block Pruning For Faster Transformers는 Distilbert에서처럼 교사 모델을 사용하는 것을 제안했다.
본 논문은 점수 S의 메커니즘 때문에 movement pruning을 사용하기로 결정했다. 이 점수는 가중치와 독립적으로 최적화될 수 있으므로 가중치를 고정시킬 수 있다. 이는 가중치 값(크기)에 직접 작용하는 magnitude pruning으로는 불가능하다.
3. Exploring Gender Bias Using Movement Pruning
남성과 여성 엔터티 간의 편견적 연상으로 정의되는 성별 편향에 중점을 두었다. 본 논문의 연구는 영어 언어 및 이진 성별에만 한정되어 있다.
다음과 같은 질문에 답하려고 노력했다:
- 트랜스포머 기반 사전 훈련 언어 모델에서, 어떤 특정 레이어 또는 인접 영역이 편향을 담당하는지를 식별할 수 있을까?
본 논문에서는 Pre-trained 모델과 Fine-tuning 목적이 주어졌을 때, 어떤 어텐션 블록을 비활성화할 수 있는지 찾아내어 모델이 작업에서 잘 수행되도록 한다.
모델을 pruning하면서 §2.1에서 설명한 것과 같은 편향 제거 목적으로 fine-tuning한다. 가중치 W는 그대로 두고(고정된 채로 두고), Pruning score S만을 최적화한다.
트랜스포머 기반 모델의 구성 요소인 어텐션 헤드를 pruning 한다. 각 헤드는 네 개의 학습 가능한 행렬로 구성되어 있으며, 우리는 이들을 모두 pruning한다. §3.1에서는 행렬의 정사각형 블록을 pruning하는 전략과 전체 어텐션 헤드를 pruning하는 두 가지 전략을 시험한다.
편향을 평가하기 위해 Sentence Encoder Association Test (SEAT) 및 StereoSet Stereotype Score (SS)를 활용하며, 이는 성별 도메인에서 평가된다. 모델 성능을 측정하기 위해 표준 NLP 벤치마크인 GLUE를 사용한다.
3.1 Experiments
모든 실험에서는 BERT-base 모델을 사용했다.
Square Block Pruning
어텐션 헤드 행렬에서의 square block pruning이 전체 어텐션 헤드를 제거하는 결과를 보였다. 본 논문의 목적은 그들과 다르지만, 이러한 행동을 재현하려고 노력했다.
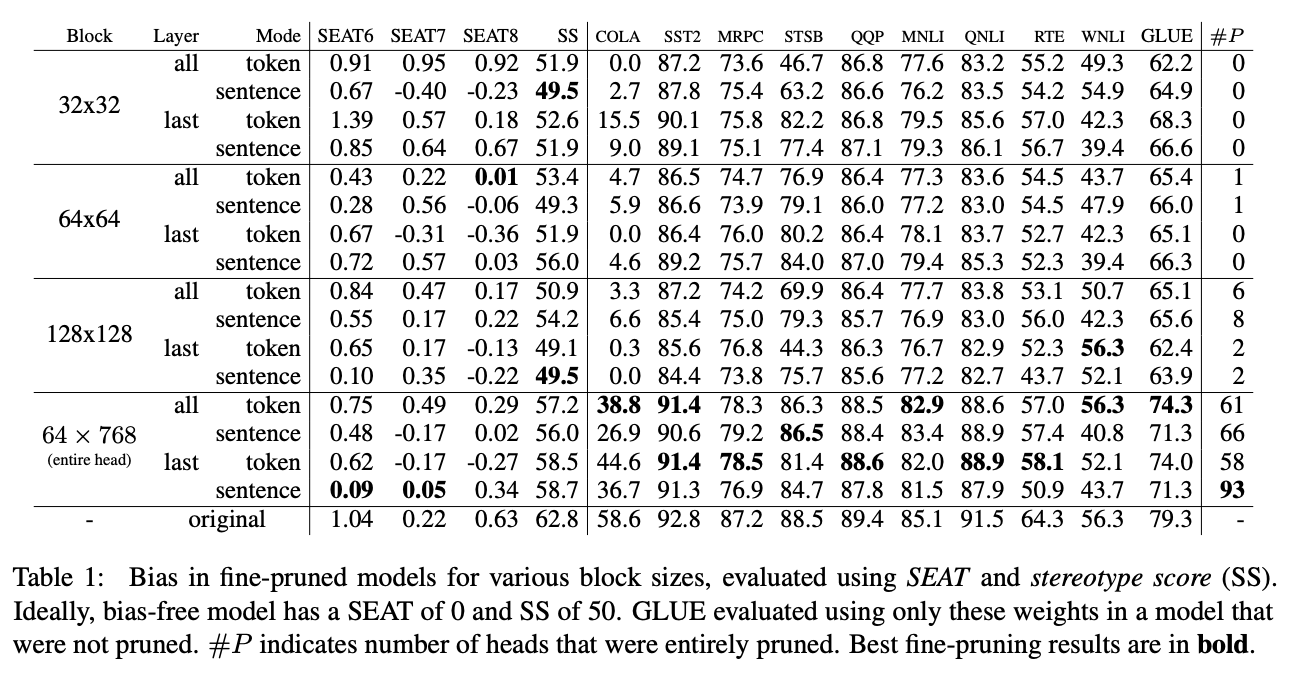
최적의 정사각형 블록 크기(B, B)를 찾기 위해 B = 32, 64, 128과 함께 실험을 진행했다. 또한 B = 256, 384, 768로 시도해 보았지만 수렴 문제가 발생하여 이러한 값들은 폐기했다. 적절한 블록 크기를 선택하는 것이 작업의 주요 제약사항 중 하나다.
Attention Head Pruning
전체 어텐션 헤드를 제거하려면 한 번에 모든 헤드 행렬을 pruning할 수 없다. 대신 값 행렬의 64×768 블록 (BERT-base의 어텐션 헤드 크기)만을 pruning한다.
3.2 Discussion
Square Block Pruning Does Not Remove Entire Heads
Block Pruning For Faster Transformers에서는 Square block pruning이 전체 헤드를 제거한다는 결과를 얻었다. 그러나 본 논문에서는 편향 제거 설정에서 이 현상을 관찰하지 못했다. 최대 8개의 헤드만을 상대적으로 큰 블록 크기, 128 × 128에 대해서만 pruning할 수 있다.
사전 훈련된 모델의 가중치를 고정하는 것이 그 이유라고 가설을 세운다. 이를 확인하기 위해 32 × 32 블록 크기로 실험을 반복하지만, 가중치를 고정하지 않는다.
편향이 크게 변하지 않았지만 어텐션 헤드가 완전히 pruning되지 않았다. 이는 편향이 특정 헤드에 인코딩되어 있지 않을 수 있으며, 대신 여러 헤드에 분산되어 있을 수 있다는 것을 시사한다.
Performance-Bias Trade-off
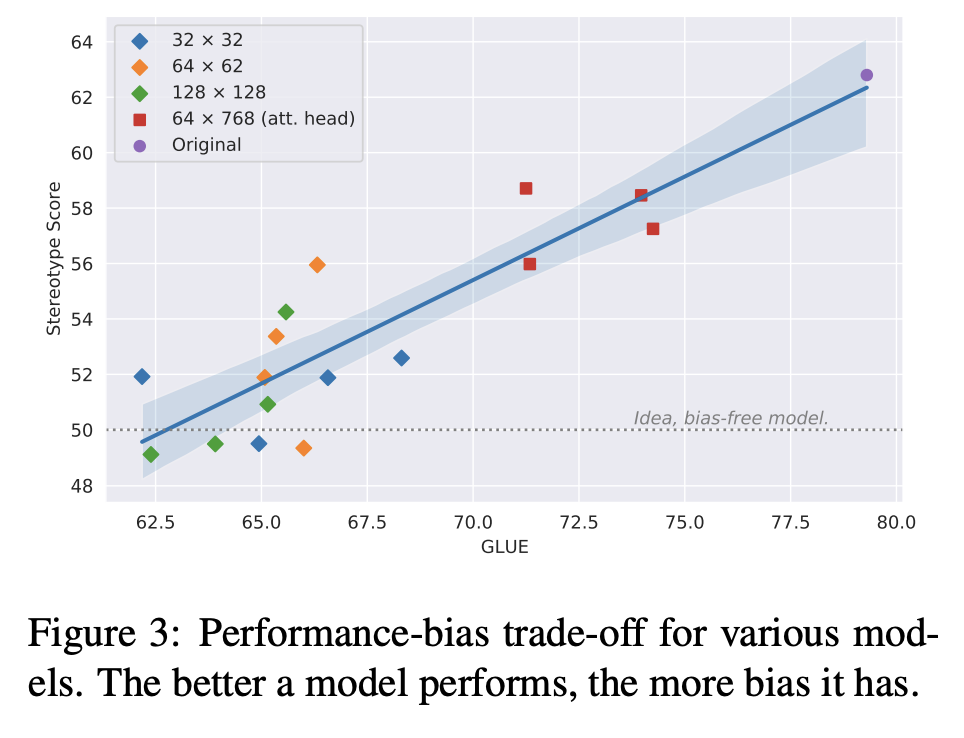
모델 성능과 그 편향 간에 부정적인 상관 관계를 관찰했다. 편향이 없는 모델, 즉 SS가 50에 가까운 모델은 성능이 낮다. 최고의 GLUE를 가진 모델이 가장 많은 편향을 포함하고 있다. 이 현상은 편향 제거 알고리즘의 내재적인 약점일 수 있다.
이 문제를 완화하기 위해서는 알고리즘을 개선하거나 더 나은 알고리즘을 개발하거나, 또는 편향 제거 데이터에 중점을 둘 필요가 있을 수 있다. 또한 편향 제거와 하향 작업 목표를 동시에 최적화하는 것도 흥미로울 것이다. 그러나 이는 연구의 범위를 벗어나며, 향후 연구에 남겨두었다.
본 논문의 모델은 언어 수용성 작업 (CoLA)에서 성능이 좋지 않다. 대부분의 모델은 거의 제로에 가까운 점수를 가지고 있어 무작위로 정보가 없는 추측을 하는 것으로 해석된다. 이는 작업의 복잡성에 기인할 수 있다. CoLA는 전체 GLUE 스위트 중에서 가장 어려운 작업으로, 깊은 문법 및 구문 지식이 필요하다.
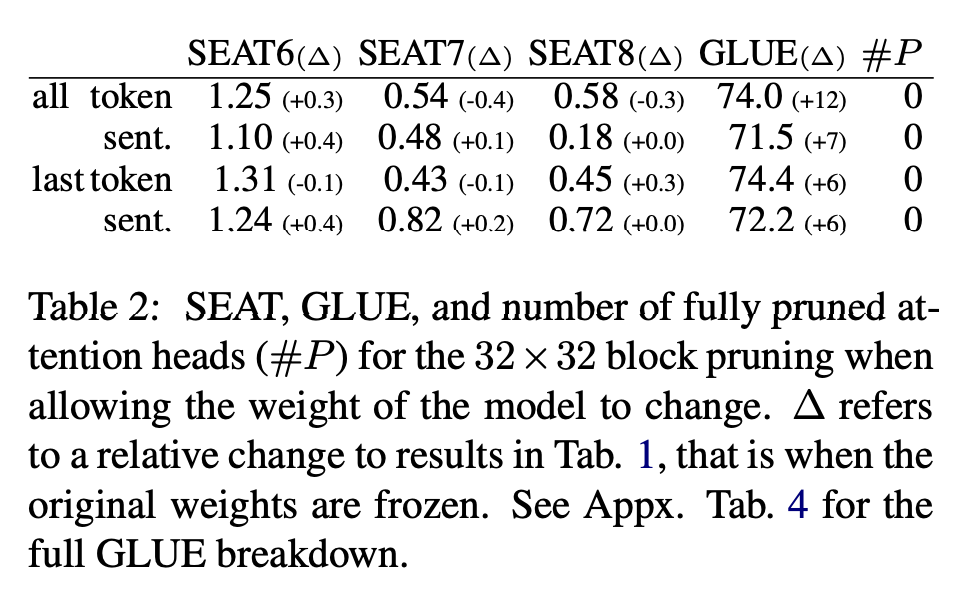
언어 모델이 문법적 추론에서 뛰어나지 않을 수 있다는 제안이 있었으며, Pruning으로 인한 가중치의 부재와 같은 변형이 이미 약한 문법 능력을 더욱 약화시킬 수 있다. 위 결과는 이 가설을 지원한다. 'frozen' 설정과 비교하여 CoLA 점수가 현저히 높아지는 반면, 다른 작업에서는 약간의 증가만 나타났다.
4. Debiasing Early Intermediate Layers Is Competitive
Debiasing Pre-trained Contextualised Embeddings은 세 가지 휴리스틱을 제안했다:
- 첫 번째 레이어의 편향 제거
- 마지막 레이어의 편향 제거
- 모든 레이어의 편향 제거
그러나 편향 제거가 가능한 레이어 부분집합은 훨씬 많다. 모든 부분집합을 시도하여 최상의 부분집합을 찾는 것은 계산 비용이 많이 든다. 본 논문의 프레임워크를 사용하면 낮은 계산 비용으로 더 좋은 부분집합을 찾을 수 있다.
실험으로 다음을 관찰했다:
-
Square block pruning은 일반적으로 다른 레이어보다 첫 번째와 마지막 레이어에는 큰 영향을 미치지 않는다. 이러한 레이어의 밀도는 일반적으로 다른 레이어보다 높다.
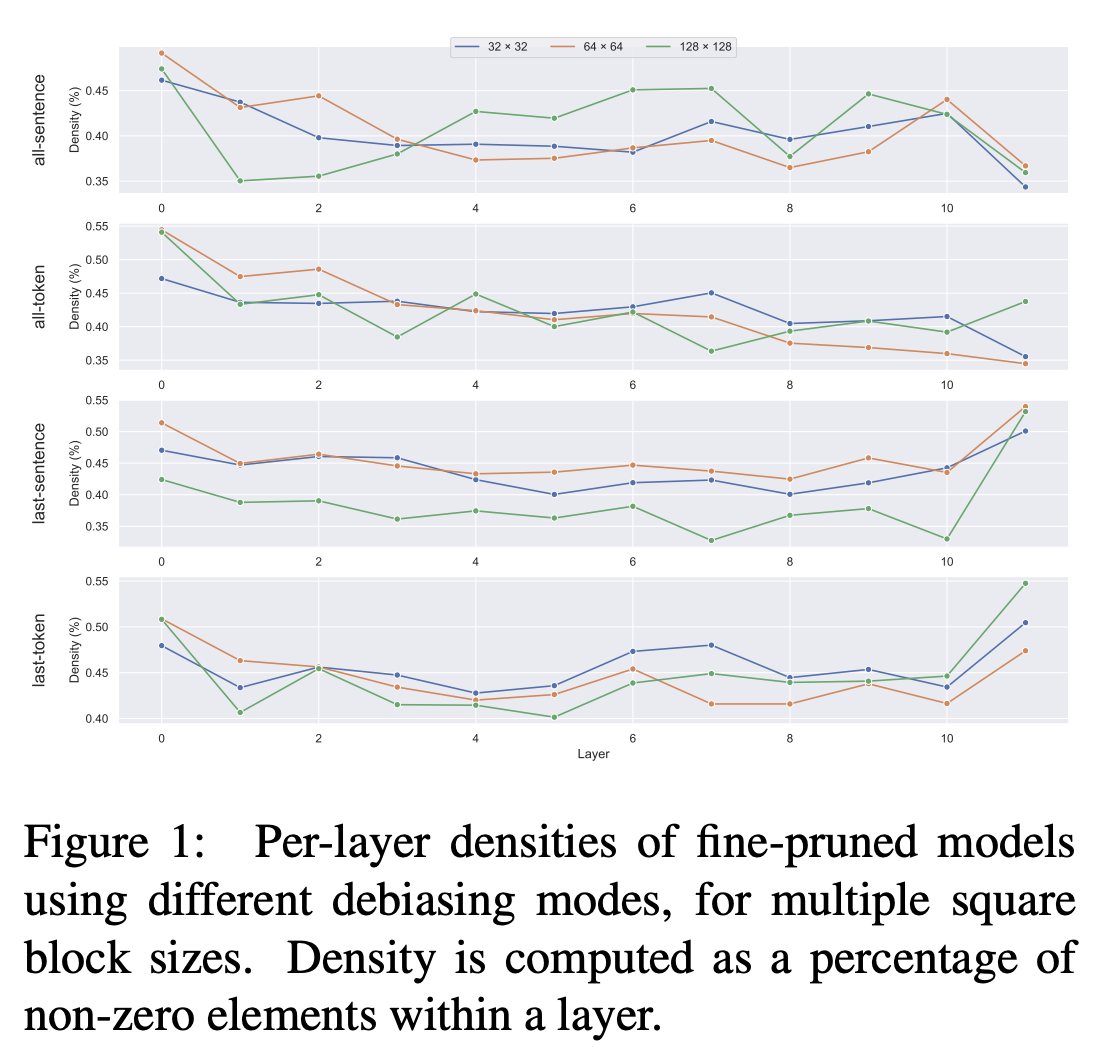
-
어텐션 헤드 pruning은 주로 중간 레이어에 영향을 미친다. 이를 기반으로 우리는 중간 레이어를 편향 제거하기로 제안한다.

구체적으로, 레이어 인덱스 1에서 4까지의 임베딩을 취하고 §2.1에서 설명한 편향 제거 알고리즘을 실행한다. 일반적으로 레이어 0은 높은 밀도를 나타내므로 포함하지 않고, 레이어 5는 모든 실험에서 pruning되지 않은 가장 많은 헤드를 포함하고 있기 때문에 포함하지 않는다.
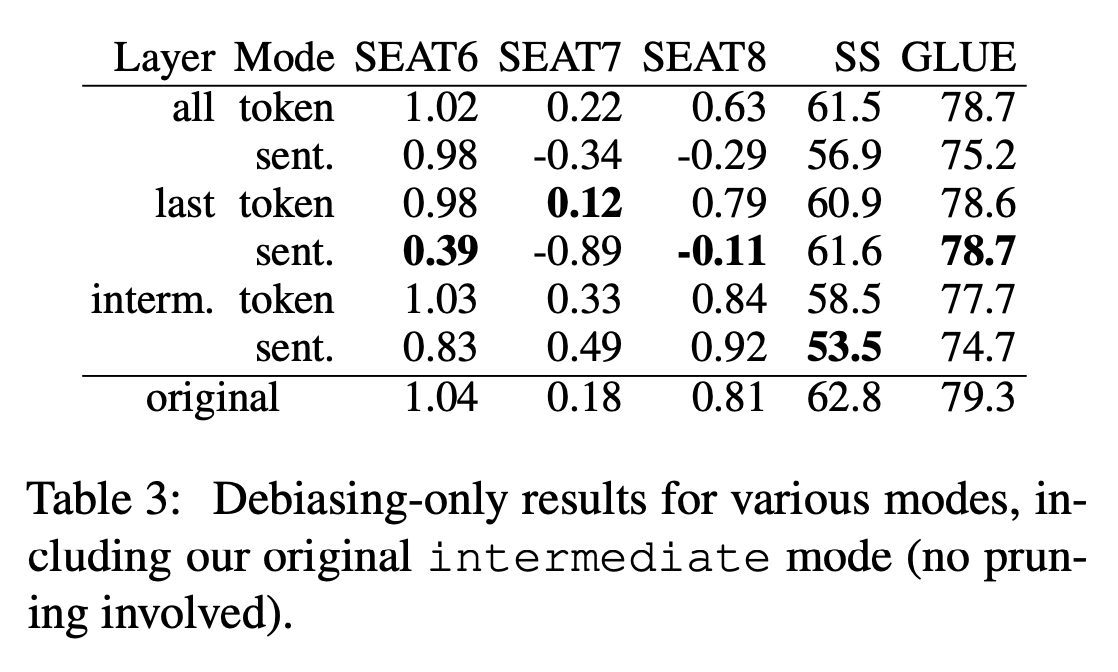
결과적으로 intermediate-token 및 intermediate-sentence라는 두 가지 모드가 더 추가되었다. 위 표는 본 논문의 모드 및 다른 모드에 대한 결과다.
중간 레이어의 편향 제거는 모든 레이어 및 마지막 레이어의 편향 제거와 경쟁력이 있다. 중간 모드의 SS는 해당 모든 및 마지막 모드의 SS보다 낮다. 중간-sentence의 SS는 50에 가까워진다.
5. Conclusion
Pre-trained 트랜스포머 기반 언어 모델에서 편향의 원천을 검사하기 위한 새로운 프레임워크를 소개한다. 모델과 편향 제거 목적이 주어지면, 이 프레임워크는 Movement pruning을 활용하여 원래 모델보다 더 적은 편향을 포함하는 하위 집합을 찾는다.
이 프레임워크를 성별 편향을 사용하여 실험하고, 편향이 주로 BERT의 중간 레이어에 인코딩되어 있다는 것을 발견했다. 이러한 결과를 기반으로 기존 모드보다 더 많은 편향을 감소시키는 두 가지 새로운 편향 제거 모드를 제안한다. 편향은 SEAT 및 Stereotype Score 메트릭을 사용하여 평가된다.
성능-편향 트레이드 오프를 탐구했다: 모델이 작업에서 더 잘 수행될수록 성별 편향이 더 많이 나타난다. 추후에 이 프레임워크가 성별 편향에만 국한되지 않고 더 많은 응용 분야를 찾을 것을 기대한다.
