Paper : https://arxiv.org/abs/2109.04838
Github : https://github.com/huggingface/nn_pruning
Abstract
Pre-training은 분류 및 생성 작업에서 모델 정확도를 향상시켰지만, 이는 훨씬 크고 느린 모델을 도입하는 비용이 따른다. Pruning은 모델 크기를 줄이는 효과적인 방법으로 입증되었으며, Distillation은 추론 속도를 높이는 데 효과적으로 입증되었다.
본 논문에서는 작고 빠른 모델을 대상으로 하는 block pruning을 소개한다. 임의의 크기의 블록을 고려함으로써 구조화된 방법을 확장하고, 이 구조를 fine-tuning을 위한 movement pruning 패러다임에 통합한다.
이 방법이 기본 모델의 전체 구성 요소를 제거하는 것과 같은 결과를 얻는다는 것을 발견했다. 실험은 분류 및 생성 작업을 고려하며, SQuAD v1에서 BERT의 크기를 74% 줄이고 속도를 2.4배 높인 가지치기된 모델을 얻었으며, F1에서 1% 감소했다.
1. Introduction
NLP 테스크에서 pre-trained 트랜스포머 모델은 분류 및 생성 작업 모두에서 표준으로 사용되고 있으며, 표준 벤치마크에서 성능이 향상되는 동안 모델 크기가 계속해서 증가하고 있다. 이러한 발전은 사전 훈련된 모델의 저장 크기를 줄이고 효율성을 향상시키는 필요성을 강조한다.
Pruning은 특정 작업에 대해 미세 조정된 모델의 저장 크기를 줄이는 데 효과적임이 입증되었다. Magnitude pruning, L0 regularization, lottery ticket hypothesis, diff pruning, 및 movement pruning과 같은 접근 방법들은 모델 크기를 현저하게 줄이는 데 성공했다.
-
Movement pruning : SQuAD v1.1에서 정확도 1% 하락에 대해 매개 변수 저장에서 77%의 절약을 달성했다. 그러나 이러한 모델들은 원래의 dense 구조를 재구성하기 위해 표준 하드웨어에서 실행하는 데 많은 비효율적인 부분이 있다.
-
Distillation : DistilBERT, TinyBERT, MobileBERT에서 확인되었듯이 보다 빠른 모델을 생성하는 데 더 효과적이었다. 이러한 접근 방식은 대상 증류를 활용하여 표준 하드웨어에서 빠른 밀집 구조를 갖는 더 작은 모델을 생성한다. 그러나 신중한 엔지니어링과 크기 선택 없이는 이러한 모델이 pruning된 모델보다 훨씬 크다.
본 논문에서는 이러한 간극을 메우기 위해 block pruning에 중점을 두고 있다. 개별 파라미터의 pruning과 달리 이 방법은 dense 구조의 하드웨어에서 최적화될 수 있는 pruning을 촉진한다. 이는 일반적으로 structured 방법에서 사용되는 행 또는 열 기반 pruning보다 유연한 방법이며, 트랜스포머에 효과적으로 적용하기 어려웠던 방법이다.
이 방법을 Movement pruning과 통합하였는데, 이는 fine-tuning 중에 pre-trained 모델을 pruning하는 간단한 방법이다. 최종 방법은 추가적인 하이퍼파라미터나 훈련 요구사항을 필요로 하지 않는다.
실험은 정확도와 효율성을 비교하여 다양한 벤치마크 데이터셋을 고려한다. 훈련 중에 하위 행 정사각형 블록을 사용하더라도, 이 방법이 모델의 전체 구성 요소를 제거하는 데 효과적으로 학습되어, 많은 어텐션 헤드를 효과적으로 제거한다는 결과를 찾았다.
이는 모델이 feed-forward 레이어의 표준 structured pruning을 초과하는 속도 향상을 가능하게 한다. 결과는 F1에서 1% 하락과 함께 SQuAD v1.1에서 2.4배의 속도 향상 및 QQP에서 F1의 1% 손실과 함께 2.3배의 속도 향상을 보여준다.
Summarization에 대한 실험은 CNN/DailyMail의 모든 ROUGE 메트릭에서 2점 평균 하락과 함께 1.39배의 속도 향상을 보여주며, 디코더 가중치를 3.5배 감소시키는 결과를 나타낸다.
2. Related Work
Knowledge distillation
경쟁력 있는 성능을 달성하는 훨씬 작은 BERT 모델을 얻기 위해 사용되었다. Distilling the Knowledge in a Neural Network에서 처음 소개된 인기있는 compression 방법이다.
- DistilBERT는 BERT를 pre-triaining 단계 및 선택적으로 fine-tuning 단계에서 더 얕은 학생 모델로 증류한다.
- MobileBERT 및 TinyBERT는 레이어별 증류 전략을 통해 얻어졌다. MobileBERT는 작업에 무관하지만, TinyBERT는 task-specific하다.
Unstructured pruning
트랜스포머 모델을 대상으로 할 때, 일반적으로 가중치의 크기를 기준으로 pruning하는 것이 일반적이다.
- Movement Pruning은 일차 방법을 사용하여 중요도 점수를 계산한다.
이러한 방법은 모델 크기를 상당히 줄일 수 있게 해주지만, 결과적으로 나오는 unstructured sparse matrix를 활용하여 추론을 가속화하기 위해서는 특수한 하드웨어가 필요하다.
Stuructured pruning
일관된 그룹의 가중치를 제거한다.
-
최근 연구들은 일부 어텐션 헤드가 성능에 중대한 저하 없이 제거될 수 있다는 것을 보여주었으며, 대부분의 헤드가 중복 정보를 제공한다는 결론을 내렸다.
-
다른 연구자들은 행렬 인수분해와 가중치 pruning을 결합하는 데 노력해왔다.
- LadaBERT는 SVD 기반 행렬 인수분해와 unstructured pruning을 결합한다.
- Structured Pruning of Large Language Models는 stuructured pruning을 사용하여 rank를 감소시킨다.
특이값분해 (Singular Value Decomposition, SVD)
: 임의의 행렬을 세 개의 행렬로 분해하는 기술이다. 이 세 행렬은 특이값 분해의 고유한 특성을 가지며, 주어진 행렬의 모든 정보를 표현할 수 있다.
참고 : https://angeloyeo.github.io/2019/08/01/SVD.html
Rank
: 랭크는 행렬의 선형 독립적인 행 또는 열의 최대 개수를 나타낸다. 다시 말해, 행렬의 랭크는 해당 행렬이 담고 있는 정보의 차원을 나타내는 지표다. 랭크가 높을수록 행렬이 담고 있는 정보가 많고, 랭크가 낮을수록 정보의 손실이 크다.
-
본 논문의 방법과 관련된 연구는 multi-head attention과 feed-forward network의 내부 레이어 노드에 structured pruning을 적용했다.
-
FastFormers: Highly Efficient Transformer Models for Natural Language Understanding는 중요도 점수를 기준으로 정렬한 후 모든 레이어에서 공유되는 미리 정의된 pruning 비율을 사용하여 pruning할 모듈을 선택한다.
-
Structured Pruning of a BERT-based Question Answering Model는 pruning 가능한 모듈 마스크를 계산하기 위한 다양한 방법을 비교하고, L0 정규화가 가장 우수한 성능을 보인다고 결론지었다.
-
3. Background
파라미터 θ를 가진 트랜스포머 모델에서 시작하여, 본 논문의 목표는 특정 end-task에 대해 fine-tuning된 동시에 병렬 하드웨어에서 효율적으로 계산할 수 있는 작은 파라미터 세트인 θ₀를 생성하는 것이다.
트랜스포머 파라미터 중 가장 큰 범위를 차지하는 두 부분은 feed-forward network와 multi-head attention의 sub-layer다.
-
FFN : R^d_model×d_ff 형태의 두 행렬 (W1 및 W2)으로 이루어져 있다.
-
MHA : R^d_model×d_model (query, key, value, out) 크기의 4개의 프로젝션 행렬 (Wq, Wk, Wv 및 Wo)으로 이루어져 있다.
이러한 행렬은 hidden vector를 component attention parts로 projection하고 해당 부분에서 다시 projection하는 데 사용된다. 구현에서 이 projection은 텐서 형태의 행렬로 이루어진 R^n_heads×n_heads×d_model 폴딩된 형태로 이루어진다.
d_model : hidden size
d_ff : inner size
n_heads : attention heads number
Standard fine-tuning
θ에서 시작하여 손실 L(예를 들어, 분류를 위한 교차 엔트로피)을 최적화한다:
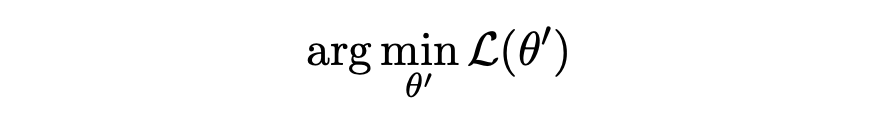
Score-based pruning
각 파라미터 i에 대한 score 파라미터 S를 도입하여 모델을 수정하고 원래의 파라미터 행렬을 마스크된 버전인 W' = W * M(S)로 대체한다. 가장 간단한 형태의 크기 가지치기에서는 낮은 절대값을 가진 파라미터를 단순히 zero-out하는 마스크가 될 것이다.
Movement pruning
모델이 이러한 스코어 파라미터를 최적화하도록 하는 score-based pruning 방법이다. 구체적으로, 우리는 이러한 score 파라미터를 최적화하는 movement pruning의 soft-movement variant에 중점을 둔다. 이는 임계값 파라미터 τ에 대해 M(S) = 1(S > τ)로 설정되며, 정규화된 목적 함수를 최적화한다.
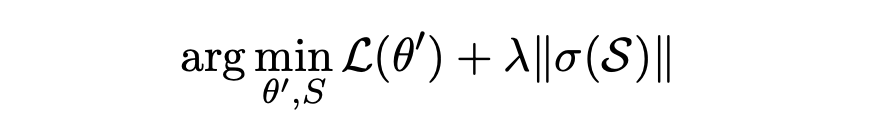
λ : hyper-parameter
σ : sigmoid function
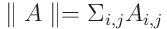
Pruning objective는 모델이 파라미터를 fine-tune하면서 중요하지 않은 파라미터의 score를 낮추어 더 많은 sparsity를 유도하도록 장려한다. threshold를 훈련하기 위해, Straight-Through Estimator가 사용된다.
Movement pruning은 distillation과 결합된 경우, 기존 모델의 파라미터 수를 줄이는 매우 효과적인 방법으로 나타났다. 예를 들어 SQuAD v1.1에서 F1이 87.5인 경우 94% 가지치기가 이루어졌다 (BERT-base는 88.5다). 이로써 증류만 사용하는 것보다 훨씬 작은 모델이 생성된다. 그러나 이러한 희소성 수준에서도 대부분의 표준 하드웨어에서는 이러한 유형의 sparse matrix-vector 곱을 효과적으로 활용할 수 없다.
4. Model: Block Movement Pruning
Movement pruning을 로컬 파라미터 블록에 적용하여 확장한다. 구체적으로 트랜스포머의 각 행렬은 고정 크기의 블록으로 분할된다. 이 설정은 임의의 unstructured 메서드의 pruning을 넘어서 효율성을 위해 데이터 근접성을 장려하는 것을 목표로 한다.
본 논문의 방법은 매우 간단하다. 각 파라미터 행렬 W ∈ R^M×N에 대해 고정 크기의 블록 구조 (M₀, N₀)를 가정한다. 이러한 각 블록은 regularization에서 shared score parameter를 가진 개별 그룹 역할을 한다. 이 score parameter는 해당 score matrix S ∈ R^M/M₀×N/N₀에서 파생된다.
Masked weight를 계산하는 것은 thresholded values를 확장하여 수행된다:
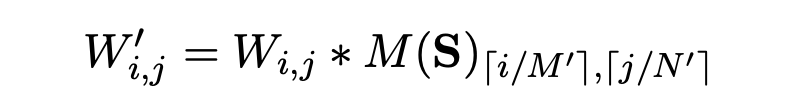
과거 연구와 마찬가지로, 이 모델은 선생 모델의 성능과 일치하도록 distillation으로 훈련된다. 다른 distillation 방법이 새로운 모델 구조를 완전히 지정해야 하는 반면, 본 논문의 방법은 모델의 각 파라미터 행렬에 대한 (M₀, N₀) 집합, 즉 블록의 크기와 모양만 지정하면 된다. 블록이 너무 크면 pruning이 어렵지만 너무 작으면 효율적인 추론을 지원하지 않는다.
검색 공간을 줄이기 위해 (M₀, N₀) att와 (M₀, N₀) ff에 대해서만 테스트한다. 동일한 블록 크기가 모든 레이어의 attention weights Wq, Wk, Wv 및 Wo에 사용되며, feed-forward weights W1 및 W2에 사용될 것이다.
Movement pruning regularization term을 다음과 같이 분할한다:
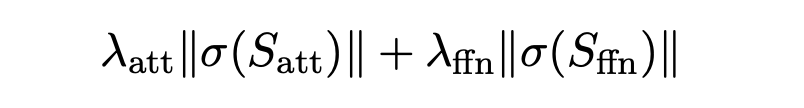
이를 통해 score parameter가 받는 gradient의 차이를 고려할 수 있다.
검색 공간을 더욱 줄이기 위해 두 종류의 블록에서 테스트했다:
- (32, 32): square blocks
- (1, dmodel) 및 (dmodel, 1): FFN 행과 열에 대한 dimension pruning (Dim)
이러한 블록 크기는 효율적인 모델을 가능하게 한다.
- 최소 (16, 16) 크기의 블록은 적절한 GPU 커널을 사용하여 효율적으로 계산할 수 있다.
- 전체 행, 열 또는 헤드를 행렬에서 완전히 제거할 수 있다.
- 나머지 행렬은 그 후 dense 형태가 된다.
접근 방식을 확인하기 위해 두 가지 추가 기준 블록 유형을 포함시켰다:
-
(2^n, 2^n), n ∈ [2, 5] : 성능에 대한 크기의 영향을 연구하기 위한 작은 2의 거듭제곱 정사각형 블록 크기 (Block)
-
(d_model/n_heads, d_model) : attention head를 위한 블록 크기 (Heads)
첫 번째는 작은 블록을 고려하고, 두 번째는 매우 큰 functional 블록을 고려한다.
5. Experimental Setup
Pre-trained language model을 평가하는 데 일반적으로 사용되는 다섯 가지 (영어) 작업에 대한 실험을 수행한다:
- 질문 응답 (SQuAD)
- 자연어 추론 (MNLI)
- 감정 분류 (SST2 Socher et al., 2013)
- 개요 생성 (CNN/DailyMail)
트랜스포머 언어 모델의 task별 pruning 실험을 진행한다. 문장 분류 및 질문 응답을 위해 BERT를 사용하며(110M 파라미터의 인코더 전용 트랜스포머 언어 모델, 그 중 85M은 트랜스포머 레이어의 선형 레이어에 포함됨), 요약을 위해 BART를 사용한다(139M 파라미터의 인코더-디코더 언어 모델, 그 중 99M은 트랜스포머 레이어의 선형 레이어에 포함됨).
Movement pruning 완전히 unstructured 방법이며 속도 이점이 거의 없지만 본 논문이 달성하길 희망하는 희소성 교환의 상한을 제공한다. 또한 트랜스포머 기반 언어 모델의 빠른 추론을 위해 개발된 최첨단 접근 방식과 비교한다.
-
DistilBERT : 사전 훈련된 BERT를 더 작은 모델로 증류하여 얻는다.
-
TinyBERT : 데이터 증강을 사용하여 미세 조정된 모델을 증류한다.
-
MobileBERT : 대규모 아키텍처 탐색의 결과다.
-
dBART : 큰 모델의 일부 레이어를 작은 모델로 임의로 복사하여 얻는다.
GPU에서 추론 속도를 측정하기 위해 24GB 3090 RTX 및 Intel i7 CPU를 사용하며 평가에 대한 대형 배치 크기(128)와 PyTorch CUDA 타이밍 프리미티브를 사용해서 측정했다. 결과는 플랫폼마다 지연 및 처리량 특성이 다르기 때문에 원래 논문과 다를 수 있다. 또한 각 모델 및 참조 모델의 트랜스포머 레이어의 선형 레이어에 있는 파라미터 수를 제공한다. 선형 레이어는 대부분의 FLOPS를 나타내므로 계산이 필요하며 모델 특성이 동등한 경우에는 어느 정도 계산 시간에 대한 좋은 proxy다.
Resources and Reproducibility
최소한의 하이퍼파라미터 세트를 사용하고 있다. λatt 및 λffn의 비율은 상대적인 크기에 의해 고정된다. 이러한 매개변수에 대해 수동으로 다양한 값을 사용하여 몇 가지 실험을 수행했지만 그 영향은 미미했다.
주요 하이퍼파라미터는 training epoch다. SQuAD v1.1의 경우 BERT 모델에 대해 일반적으로 2 대신 20 epoch을 사용하고 있다. 이는 표준 fine-tuning 설정에서 45분이 소요되는 것 대비 본 논문의 방법에서는 약 12시간이 소요됨을 의미한다. 이 숫자는 주어진 작업에 대한 pruning이 충분히 느리게 진행되도록 충분히 커야 한다.
Warming up 단계 및 pruning 이후의 cool-down 단계가 도움이 되지만 정확한 길이는 최종 성능에 큰 영향을 미치지 않는다. 에너지 고려를 위해 훈련 시간이 추론 시간보다 덜 중요하다. 추론은 반복적으로 수행되기 때문에 우리의 방법은 추론을 크게 최적화하고 있으며 훈련 에너지는 추론 절약으로 큰 폭으로 회복될 수 있다.
Pruning Methods
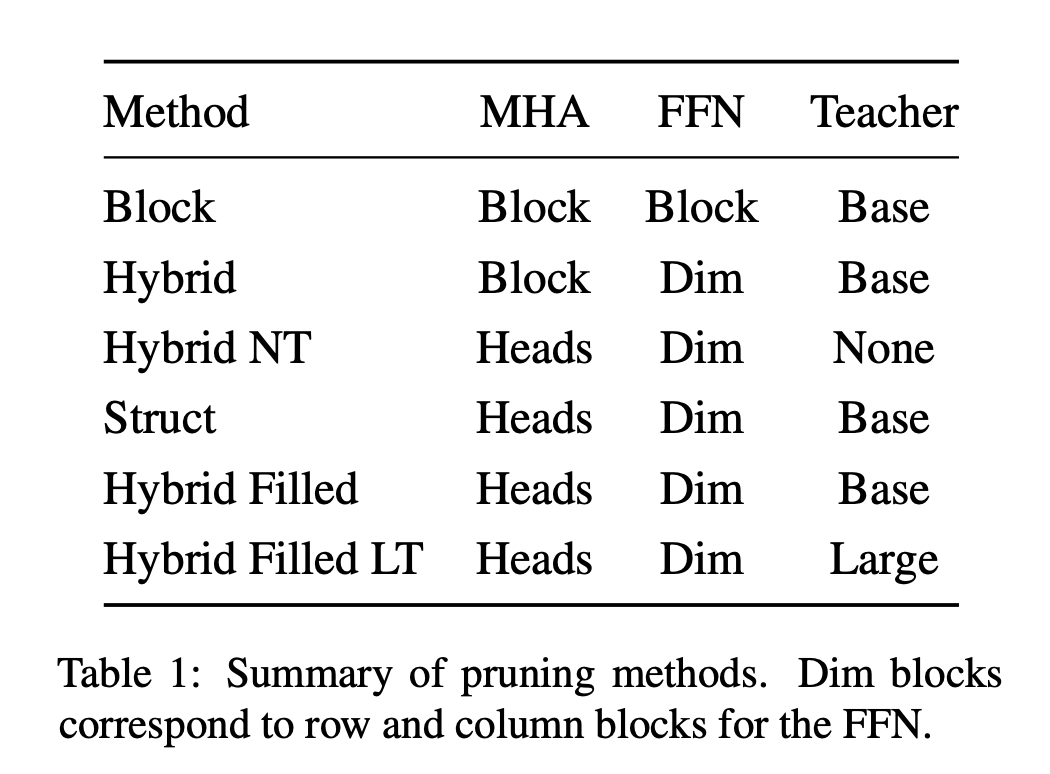
Pruning 접근 방법은 위와 같다.
-
Block pruning : original movement pruning의 확장으로 모든 선형 레이어에서 정사각형 블록 크기를 사용한다. 원래 movement pruning의 경우 블록 크기가 1이었다.
-
Hybrid pruning : movement pruning을 사용하여 feed-forward 레이어 W1 및 W2의 hidden dimension을 동시에 제거하며, 이를 통해 차원 마스크를 생성한다. 이는 매개변수 행렬에서 전체 행 또는 열에 해당한다. pruning된 W01 및 W02은 그런 다음 완전히 밀집되도록 압축될 수 있다. crop된 행렬에 대해 dense operation을 수행한다.
어텐션 레이어의 경우 Wq, Wk, Wv 및 Wo에서 일부 행 또는 열만 pruning하면 실용적으로 활용할 수 없다. 이는 계산의 구조 때문에 텐서 크기를 조절하는 추가 비용이 비효율적이기 때문이다. 따라서 어텐션 레이어에 대해 정사각형 블록 가지치기를 사용하며 성능과 정확도 간의 최상의 균형을 보여주는 (32, 32) 크기의 블록을 사용한다.

-
Struct pruning : FFN 레이어에 대해 동일한 방법을 사용하지만 모델 어텐션 헤드를 직접 제거하려고 한다. 이를 위해 어텐션에 대한 블록 크기를 헤드 크기와 동일하게 선택하면서 여전히 동일한 soft movement pruning 전략을 사용한다. 이 접근 방식에 대해 λatt를 1/32로 사용한다. 어텐션 블록에는 피드포워드 차원에 비해 매개변수가 32배 더 많기 때문이다.
- Block Pruning이 attention head와 같은 구성요소를 완전히 제거하지 않을 때, 모델을 가속화할 수 없다. 그러나 zero weights를 사용하여 만들어진 sparsity로 인해 speed와 marginal cost 없이 성능의 일부를 개선할 수 있다.
-
Hybrid Filled pruning : 모델이 이러한 회수된 가중치를 균일하게 무작위로 다시 초기화하고 더 작은 모델에 대한 몇 단계 동안 계속해서 fine-tuning할 수 있게 한다. 또한 "rewinding"을 통해 pruning해서는 안 되는 가중치(비어 있지 않은 어텐션 헤드의 일부)를 식별하고 pre-trained 모델을 re-fine-pruning하는 것도 있다.
-
첫 번째 실행에서는 pruning되지 않은 attention head를 표시하고
-
두 번째 실행에서는 이 정보를 사용하여 pruning에서 보호되는 가중치의 positive mask를 생성한다. 두 방법 간에 중요한 차이를 찾지 못했다. 여기 제시된 결과는 rewinding을 사용하지 않았다.
-
소감
4달 전에 읽었던 논문이었는데, 그동안에 논문 중 일부를 다시 찾아볼 일이 여러 번 있었고, 그때마다 논문을 다시 읽느라 시간이 많이 소요되었다. 블로그에 정리해두는 데에 시간이 좀 걸리더라도 미래에 다시 참고할 필요가 있을 때를 대비해서 정리하는 시간을 아끼지 말아야겠다.
기존의 movement pruning을 블록 단위로 적용하는 방식이다. Pruning에 다양한 방법론들이 제안되고 있다는 것을 확인할 수 있었고, 트랜스포머에서 어떤 레이어에 pruning을 적용하는지 파악할 수 있었다. Hugging face에서 block movement pruning을 적용할 수 있도록 코드를 제공해 주고 있어서 코드 상으로 어떻게 적용되는지까지 알 수 있다.
