어느새 부캠 4주차.. 이번주는 각자 트랙별 도메인 기초 이론에 대해 배운다.
Day 16
NLP ~2강
NLP
- Low-level parsing
문장을 이루는 단어를 정보 단위로 생각- Tokenization 문장을 단어 단위로 쪼개나가는 것
- stemming 단어의 어근을 추출하는 것
- Word and pharse level
- Named entity recognition(NER) 단일언어나 여러 단어로 이루어진 고유명사를 인식하는 task
- part-of-speech(POS) tagging 단어가 문장 내에 어떤 품사인지 성분이 무엇인지 알아내는 것
- noun-phrase chunking, dependency parsing, coreference resolution
- Sentence level
- Sentiment analysis 문장이 긍정인지 부정인지 확인하는 task
- mschine translation 기계번역
- Multi-sentence and paragraph level
- Entailment prediction 두 문장간의 논리적인 내포, 모순 관계 예측하는 task
- question answering 독해 기반의 질의응답 - 질문의 키워드가 포함된 문서를 읽고 이해한 뒤 대답하는 것
- *dialog systems, summarization
단어를 벡터공간의 한 점으로 표현하는 것 → Word Embedding
Bag-of Words
딥러닝 이전 많이 사용되던 방법
1. 텍스트 데이터에서 unique한 단어를 모아 vocabulary 사전을 만듦 - 중복된 단어 제거
sentence : "I like apple", "He love apple"
vocabulary : {"I", "like", "apple", "love"}
2. 각 단어를 categorical variable로 보고 one-hot vector로 표현
∙ 여기서 one-hot vector는 word-embedding과 대비되는 특성
I : [1 0 0 0] like : [0 1 0 0] apple : [0 0 1 0] love : [0 0 0 1]
=> 이렇게 되면 문장도 단어의 one-hot vector를 더한 형태로 표현할 수 있음
ex) "I like apple" : [1 1 1 0]
Naive Bayes Classifier
Bayes 법칙에 기반한 분류기
document d가 주어졌을 때 클래스의 확률
※ 여기서 는 상수값으로 무시 가능
Bayes rule을 적용하면
각 단어가 나올 확률을 독립이라고 가정하면
📌 하지만 이런 가정을 하면 만약 i라는 단어가 a 클래스에 속해있지 않으면 확률이 0이 되어 나중에 i가 들어간 문장이 다 a 클래스에 속할 확률이 0이 되기에 추가적인 regularization이 필요
- 문장에 대한 토큰화 진행
- 토큰화된 단어들에 대해 숫자로 변환한 뒤 vocabulary에 추가 (w2i)
- naive bayes classifier 모델
class NaiveBayesClassifier():
def __init__(self, w2i, k=0.1):
self.k = k # smoothing 상수
self.w2i = w2i
self.priors = {} # 각 class의 prior 확률
self.likelihoods = {} # 각 토큰의 class 별 liklihood
def train(self, train_tokenized, train_labels):
self.set_priors(train_labels) # Priors 계산.
self.set_likelihoods(train_tokenized, train_labels) # Likelihoods 계산.
# laplace smooting 진행 - log 사용해 곱셈을 덧셈으로 바꿈
def inference(self, tokens):
log_prob0 = 0.0
log_prob1 = 0.0
for token in tokens:
if token in self.likelihoods: # 학습 당시 추가했던 단어에 대해서만 고려.
log_prob0 += math.log(self.likelihoods[token][0])
log_prob1 += math.log(self.likelihoods[token][1])
# 마지막에 prior를 고려.
log_prob0 += math.log(self.priors[0])
log_prob1 += math.log(self.priors[1])
if log_prob0 >= log_prob1:
return 0
else:
return 1
# 전체 label에 대해 얼마나 class 등장했는지 - P(c) 구함
def set_priors(self, train_labels):
class_counts = Counter(train_labels)
for label, count in class_counts.items():
self.priors[label] = class_counts[label] / len(train_labels)
def set_likelihoods(self, train_tokenized, train_labels):
token_dists = {} # 각 단어의 특정 class 조건 하에서의 등장 횟수.
class_counts = defaultdict(int) # 특정 class에서 등장한 모든 단어의 등장 횟수.
for tokens, label in zip(train_tokenized, tqdm(train_labels)):
count = 0
for token in tokens:
if token in self.w2i: # 학습 데이터로 구축한 vocab에 있는 token만 고려.
if token not in token_dists:
token_dists[token] = {0:0, 1:0} # 안에 0과 1 클래스가 있는 dictionary 추가 -> class 별로 (긍정/부정)
token_dists[token][label] += 1
count += 1
class_counts[label] += count
for token, dist in tqdm(token_dists.items()):
if token not in self.likelihoods:
self.likelihoods[token] = {
0:(token_dists[token][0] + self.k) / (class_counts[0] + len(self.w2i)*self.k),
1:(token_dists[token][1] + self.k) / (class_counts[1] + len(self.w2i)*self.k),
}
Word Embedding
각각의 단어를 어떠한 특정한 차원의 벡터로 표현
-> 비슷한 의미를 가진 단어가 좌표공간에 비슷한 공간에 위치
Word2Vec
word embedding을 학습하는 방법 중 하나로 같은 문장에서 나온 인접한 단어들 간에 의미가 비슷할 것이라는 가정을 이용
-> 주변애 등장하는 단어들을 통해 의미를 알 수 있음
- 단어별로 분류하는 tokenization을 수행
- unizue한 단어들만 모아 사전 구축
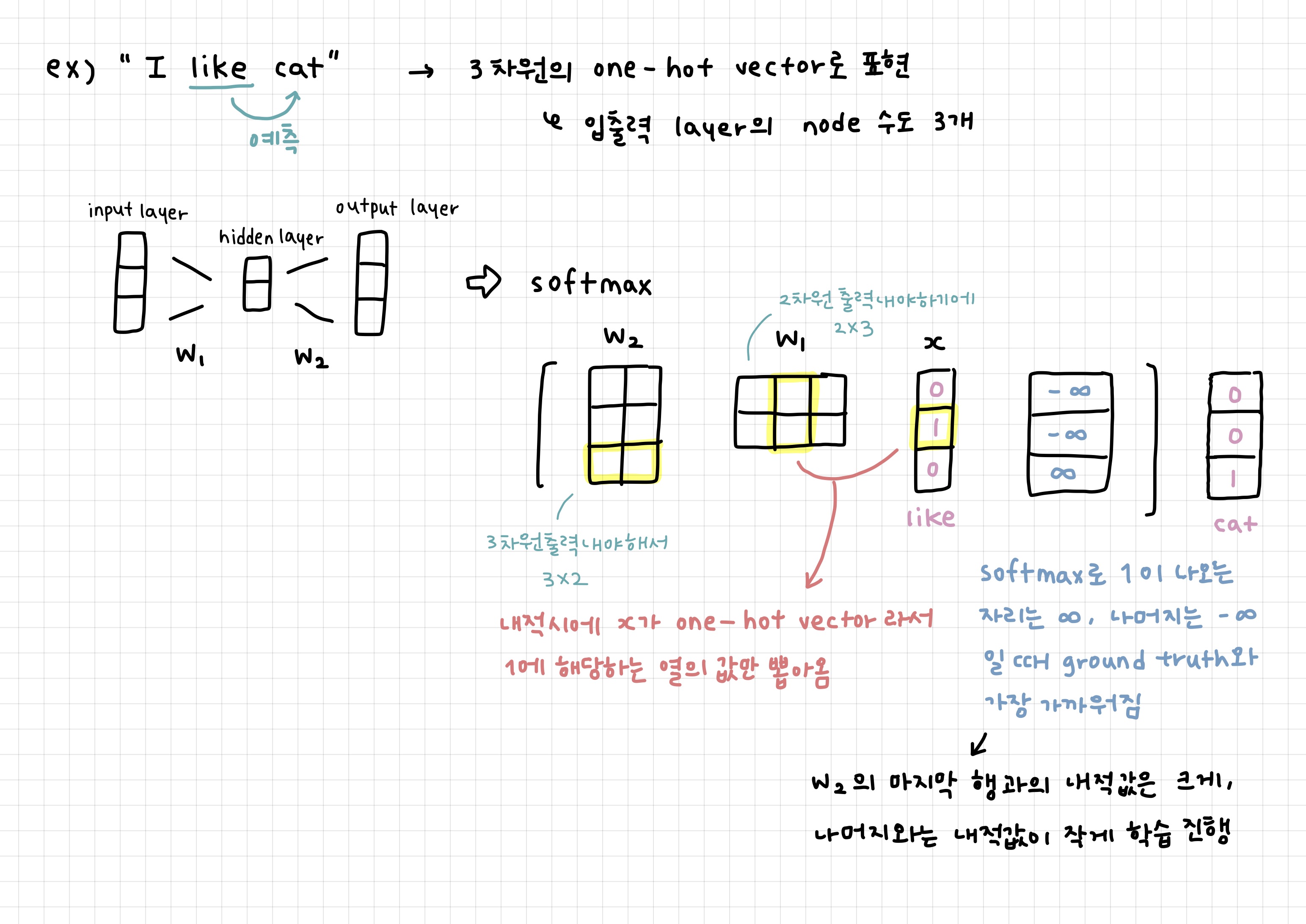
- 사전 size만큼의 차원을 갖는 one-hot vector로 단어를 표현
- sliding window를 적용해 한 단어를 중심으로 앞 뒤로 나타난 단어 각각과 입출력 단어 쌍을 구성
ex) window size가 3이면 I love cat and dog 에서 cat이 중심단어면 (love, cat), (cat, and)가 입출력 쌍이 됨
Word2Vec은 단어들 간의 의미론적 관계를 잘 학습하기에 의미가 비슷한 단어쌍들은 벡터가 유사
Word intrusion detection : 여러 단어가 주어져 있을 때 나머지 단어와 의미가 가장 상이한 단어를 찾아내는 것
-> 단어들 끼리의 거리를 평균값 내서 가장 큰 것이 상이한 단어가 됨
Glove
word2vec에서는 자주 나오는 입출력 쌍이라면 여러번 학습을 통해 두 word embedding간의 내적값이 커지도록 학습한다면 Glove는 미리 등장 횟수를 계산해 내적값의 groung truth로 사용해 학습
-> 중복되는 계산을 줄여줌
📌 각 입력, 출력 단어 쌍들에 대해 두 단어가 한 window 내에서 총 몇번 동시에 등장했는지 사전에 미리 계산
새로운 형태의 loss function을 사용
와 는 입력, 출력 단어의 임베딩 벡터이고 는 사전에 계산한 값으로 한 window내에 총 몇번 동시에 나타났는지
와 에 가까워질 수 있도록 학습
