Day 18
NLP ~4강
RNN
sequence 데이터를 입출력으로 사용
각 timestep에서 들어오는 입력벡터 와 전 timestep의 RNN 모듈에서 계산한 hidden state vector 을 입력으로 받아 현재 timestep에서의 를 출력으로 내는 구조
-> 재귀적으로 RNN 모듈의 출력이 다음 timestep의 입력으로 들어감
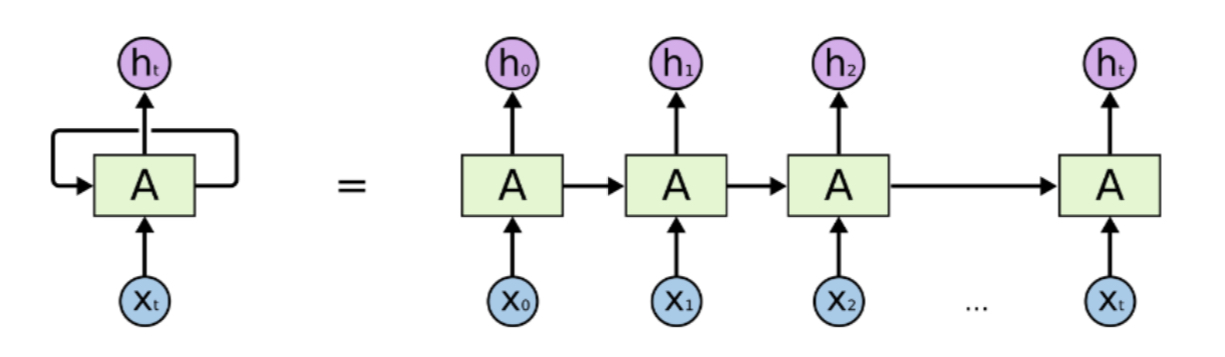
📌 서로 다른 timestep에서 들어오는 입력데이터를 처리할 때 동일한 파라미터를 가진, 반복적으로 등장하는 모듈이라는 뜻의 recurrent neuralnet module을 매 timestep에서 동일하게 사용
hidden state가 다음 timestep의 입력으로도 사용되고 필요한 경우 출력값을 계산할 수 있어야 함
Hidden state
: 전 timestep에서 계산된 hidden state vector
: timestep에서의 입력 vector
: 정보를 잘 조합해서 나타낸 timestep에서의 hidden state
: W를 파라미터로 가지는 RNN 함수 (W - RNN 모듈에 필요한 linear transformation matrix를 정의하는 parameter)
: 를 바탕으로 계산한 최종 예측값에 해당하는 output
hidden state를 계산하는 공식 :
-> 매 timestep마다 RNN 모듈을 정의하는 parameter W는 모든 timestep에서 동일한 값을 공유
hidden state vector의 node수나 layer는 hyperparameter
->

Types of RNN
- One-to-one
입력과 출력 데이터의 timestep이 하나 - sequence 데이터가 아님
ex) (키, 몸무게, 나이)로 이루어진 입력을 선형결합과 비선형결합의 NN을 통과해 (고혈압, 정상, 저혈압) 확률을 출력 - One-to-many
입력이 하나의 timestep으로 주어지고 출력은 여러 timestep으로 주어지는 형태
ex) 하나의 이미지가 들어가면 이미지를 설명하는 단어를 각 timestep별로 순차적으로 생성
-> 매 timestep마다 입력이 들어가므로 입력이 들어가지 않은 timestep에서는 같은 사이즈의 벡터나 행렬이 들어가는데 모두 값이 0으로 채워진 형태의 입력이 들어감 - Many-to-one
sequence를 입력으로 받은 뒤에 최종값을 마지막 timestep에 출력으로 내보냄
ex) sentiment classification - sequence-to-sequence
입력과 출력 모두 sequence 형태를 가짐
ex1) 기계번역과 같이 timestep이 5개 주어질 때 입력 3까지 문장을 끝까지 읽은 후에 입력 문장의 마지막 timestep에서 문장에 해당하는 번역 단어를 생성
ex2) 입력이 주어질 때마다 예측을 생성 - 각각의 시간 순으로 이루어진 image frame이 입력일 때 어떤 scene에 해당하는지 분류
Character-level Language Model
언어모델 : 문자열이나 단어들의 순서를 바탕으로 다음 단어가 무엇인지 맞히는 task
- character level의 사전 구축
- one-hot vector로 나타냄
- 모델에 입력으로 넣음
Example) sequence "Little"
사전 : [L, i, t, l, e]
--> 모델에 L, i, t, t, l 을 입력으로 주었을 때 각 timestep마다 다음 단어 (i, t, t, l, e)를 예측하는 모델
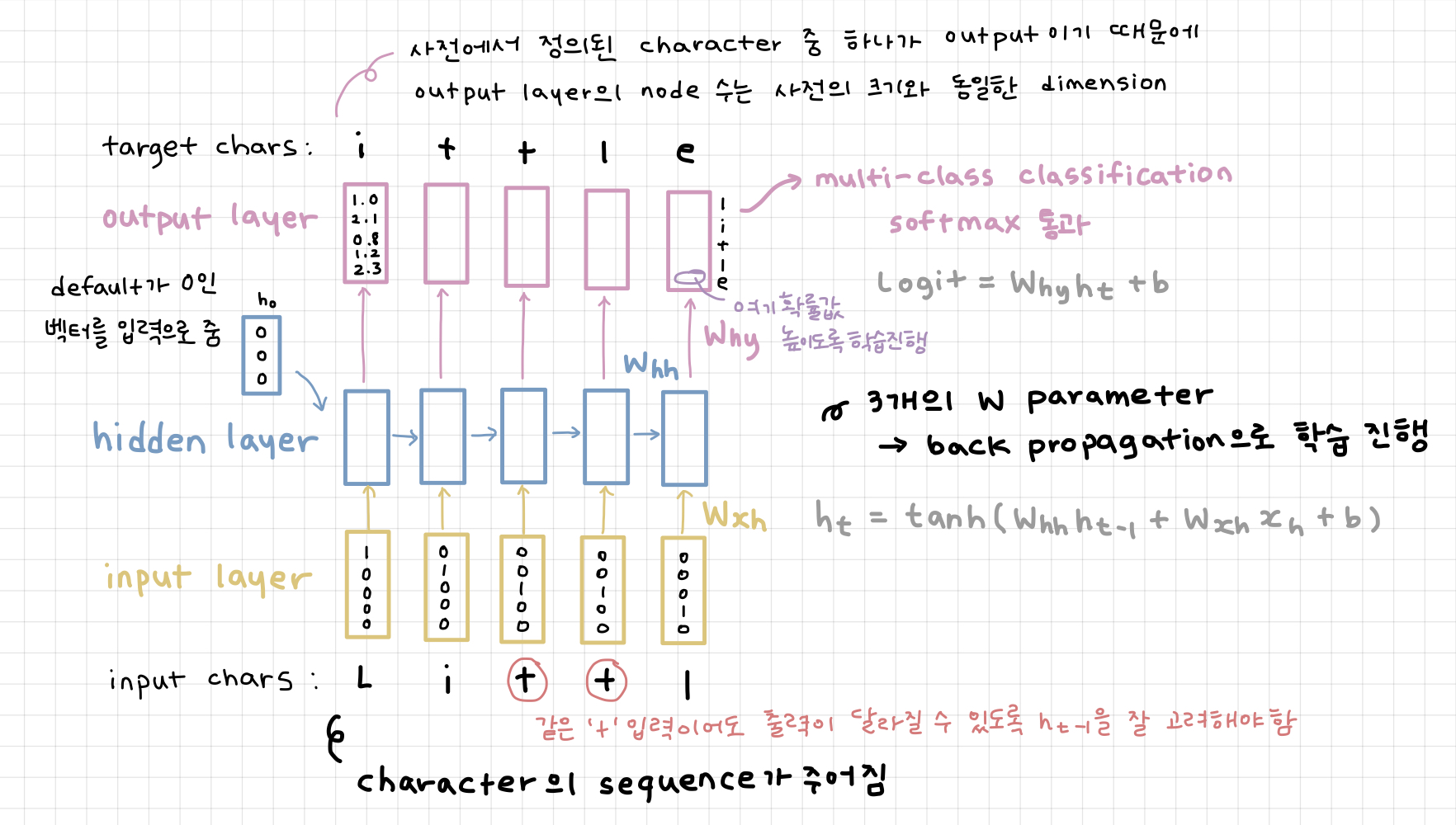
여기서 추론을 진행할 때에는 입력으로 첫번째 character만 주고 해당 timestep의 예측값으로 다음 timestep의 입력으로 재사용
-> 무한한 길이의 character sequence를 자유롭게 생성 가능
BPTT
Backpropagation trough time
RNN은 매 timestep마다 주어진 character로 발생한 hidden state vector를 통해 output layer를 각자 통과시킨 후 예측값과 다음 timestep에서 나와야 하는 ground truth와 비교해 loss function을 통해 network가 학습
-> 행렬들이 back propagation으로 학습 진행
하지만 학습이 길어지면 한번에 학습할 수 있는 정보량이 한정되어 정보가 담기지 못할 수 있음 → Truncation
"한번에 학습할 수 있는 제한된 길이의 sequence를 한정시키고 이 안에서만 학습이 이루어지고 학습의 결과를 다음으로 전달"
hidden state vector의 각각의 차원 하나를 고정하고 그 값이 timestep이 진행됨에 따라 어떻게 변하는지 분석하면 RNN의 특징을 분석할 수 있음
📌 RNN에서 필요로 하는 정보를 저장하는 공간은 매 timestep마다 업데이트를 수행하는
-> 계속해서 학습하다보면 하나의 dimenstion에서 따옴표 안에서는 항상 음수, 밖에서는 양수 등 특정 패턴을 보임
Simple한 RNN은 Vanishing/Exploding Gradient 문제를 가지고 있음
-backpropagation이 제대로 이루어져야 하는데 동일한 matrix () 를 매 timestep마다 곱하다보니 gradient vanishing/exploding 발생할 수 있음
LSTM
Long Short-Term Memory
gradient vanishing/exploding 문제를 해결하고 timestep이 먼 경우에도 필요로 하는 정보 처리 및 학습
-> hidden state vector 단기 기억을 보다 길게 가져가기 위해 개선
전 timestep에서 넘어오는게 두 가지로 다른 역할을 하는 vector
: cell state vector 여러 필요한 정보를 담고있는 완전한 정보를 포함하는 벡터
: hidden state vector cell state 벡터를 한 번 더 가공해서 그 timestep에서 노출할 정보만을 남기는 벡터
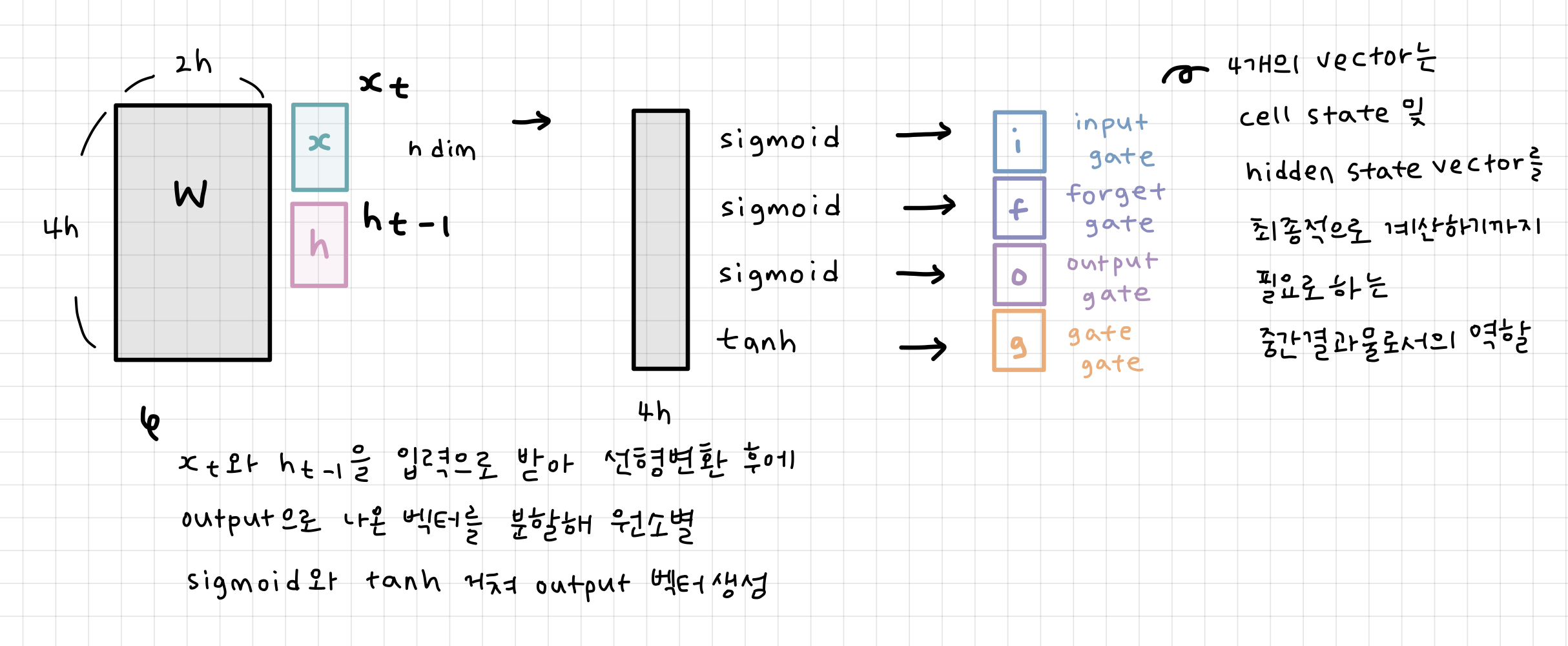
따라서 4개의 vector는 을 적절하게 변환하는데 사용
GRU
Gated Recurrent Unit
LSTM 모델을 경량화시킨 모델로 cell state vector와 hidden state vector를 일원화
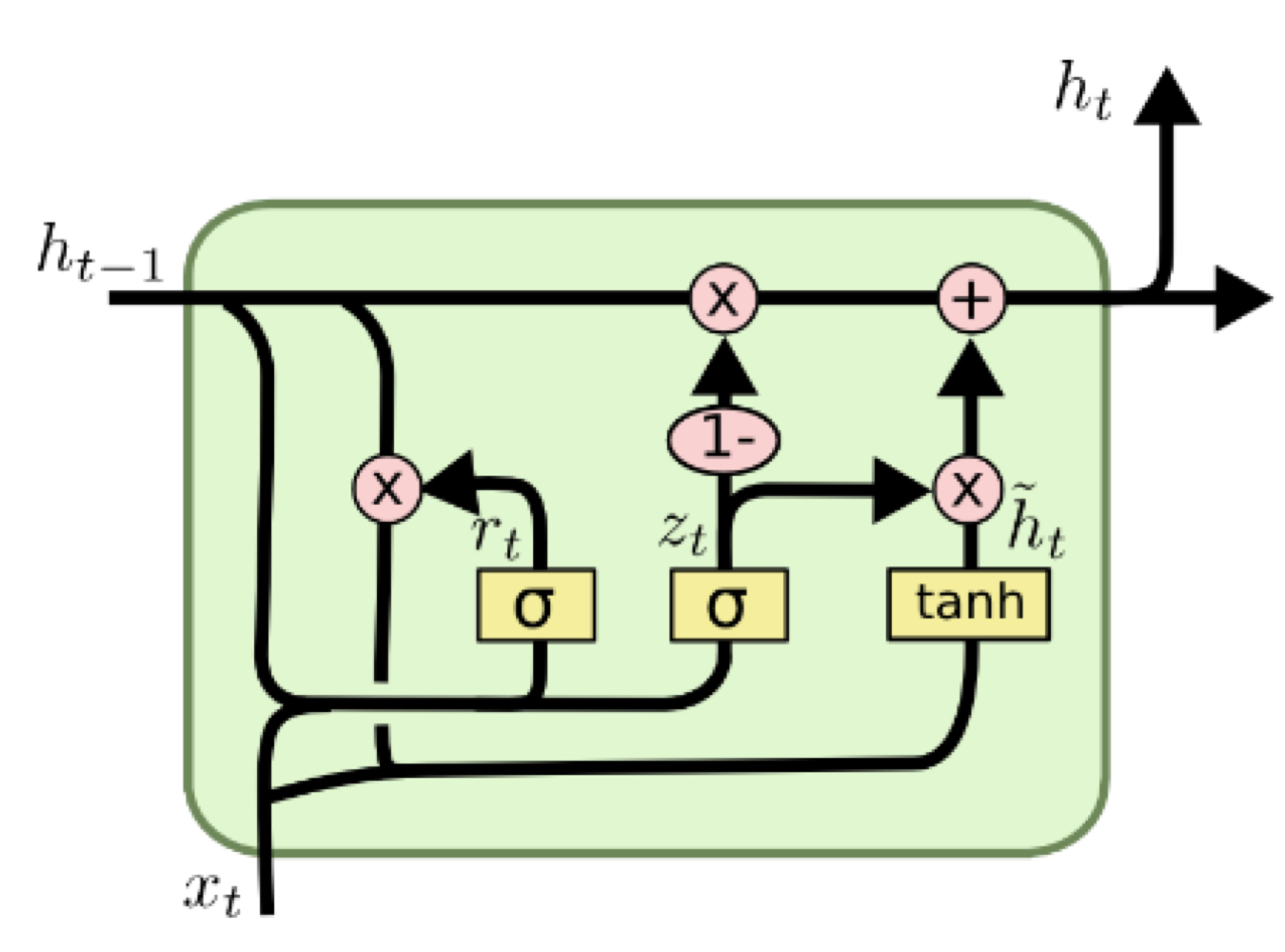
LSTM의 와 비슷한 역할을 하는 만 존재
-> 과 두 정보간의 가중평균을 내는 형태로 계산
✔︎ GRU에서는 forget gate 대신에 input gate를 1에서 뺀 값을 사용
-> input gate값이 커지면 forget gate 값은 작아짐
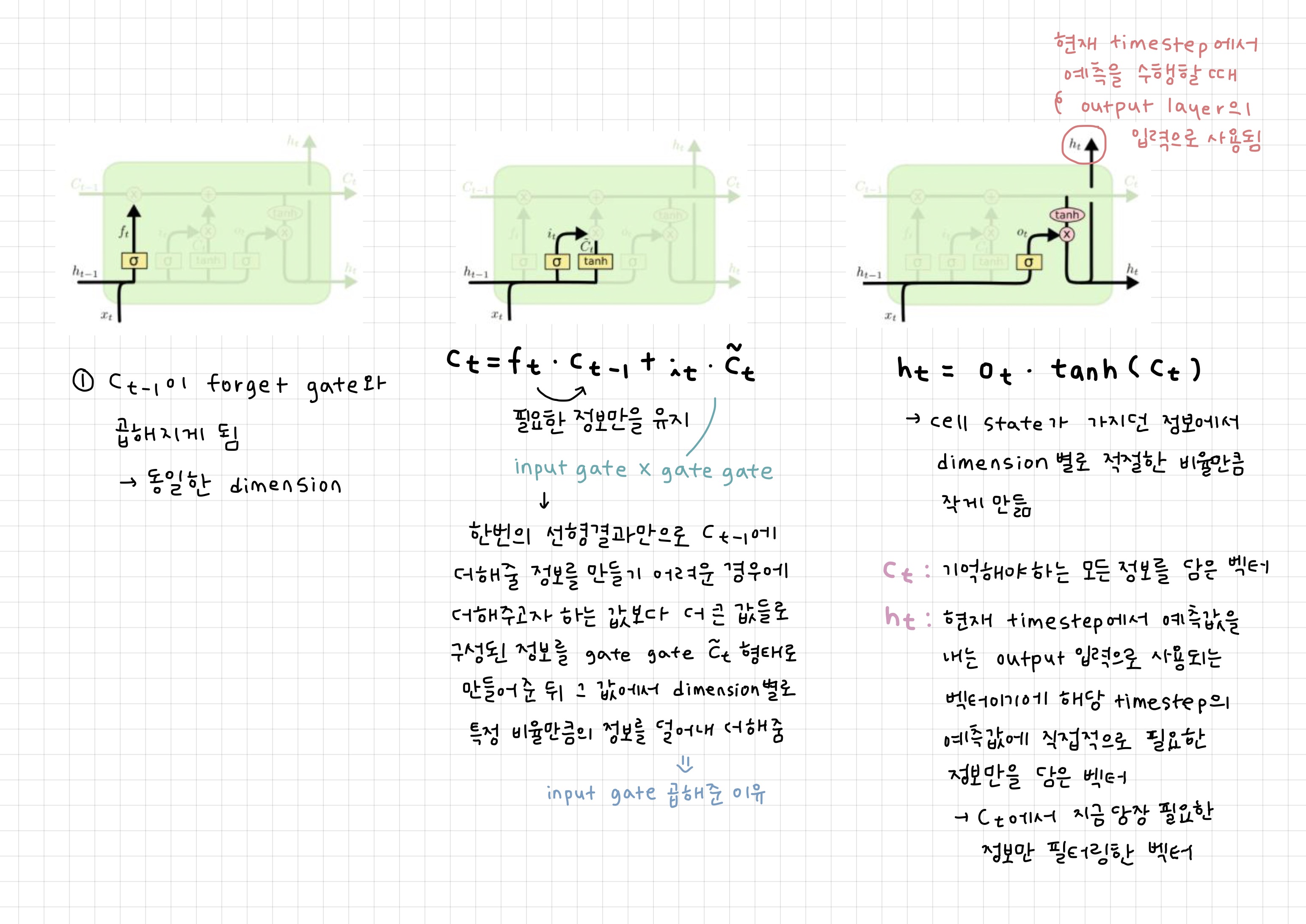
cell state의 업데이트 과정
: 기존 RNN과 같이 를 계속 곱해주는게 아닌 전 timestep의 cell state 벡터에서 서로 다른 값으로 이루어진 forget gate를 곱하고 필요로 하는 정보를 곱셈이 아닌 덧셈으로 원하는 정보를 만듦
-> gradient vanishing/exploding 문제 사라짐
📌 덧셈으로 만들기 때문에 gradient 복사가 이루어져 gradient에 큰 변형이 없이 전달해 long-term 오래된 기억도 가능
