8. 시계열 특징의 생성 및 선택
- 시계열을 위한 특징 생성 및 선택
- 시계열 특징의 자동 생성 패키지의 사용법
입문자를 위한 예제
| 시간 | 온도(F) |
|---|---|
| 월요일 아침 | 35 |
| 월요일 점심 | 52 |
| 월요일 저녁 | 15 |
| 화요일 아침 | 37 |
| 화요일 점심 | 52 |
| 화요일 저녁 | 15 |
그래프로 데이터를 표현하면 온도가 주기성을 띄고 전반적으로 증가하는 추세를 가짐
→ 시계열을 요약해 많은 내용을 유실하지 않은 채 데이터를 압축할 수 있음
특징 계산 시 고려 사항
시계열의 특징
- 정상성
- 평균이라는 개념은 정상 상태에서만 의미를 가짐 → 평균을 특징으로 사용 : 정상 - 시계열의 길이
- 시계열의 최댓값이나 최솟값과 같은 특징은 시계열의 길이가 늘어남에 따라 불안정해짐
도메인 지식
: 시계열 특징 생성의 핵심으로 통찰을 얻을 수 있는 부분
외적 고려 사항
계산 및 스토리지 리소스의 정도, 특징의 개수 등을 고려해야 한다
특징의 발견에 영감을 주는 장소 목록
간단하면서도 자주 사용되는 요약 통계 특징
- 평균과 분산
- 최댓값과 최솟값
- 시작과 마지막 값의 다른 정도
계산이 복잡해도 유용한 특징을 시각적으로 식별
- 국소적 최소와 최대의 개수
- 시계열의 평활 정도
- 시계열의 주기성과 자기상관
시계열 특징 생성의 오픈 라이브러리
1. 파이썬의 tsfresh 모듈
- 기술 통계학
- 강화된 디키풀러검정 값
- AR(k) 계수
- 지연 에 대한 자기상관
- 물리학에서 영감을 받은 비선형성과 복잡성 지표
c3()함수는 의 기대값을 계산cid_ce()함수는 에서 까지 더한 것에 대한 제곱근을 계산friedrich_coefficients()함수는 복잡한 비선형적 움직임을 묘사하는 적합된 모델의 계수를 반환
- 기록 압축 개수
- 시계열에서 두 번 이상 발생한 값들의 합
- 평균보다 크거나 작은, 가장 긴 연속 하위 시퀀스의 길이
- 시계열의 가장 이른 시간에 발생한 최댓값 또는 최솟값
→ 모듈 사용 시 오픈소스를 활용한 분석을 진행할 때, 잘 검증된 도구를 사용하면 다양한 이점을 누릴 수 있다
- 표준적인 특징을 계산하기 위해서 쓸데없이 시간 낭비를 할 필요가 없다
tsfresh같은 라이브러리는 특징 계산용 프레임워크를 제공하는 것이지, 단순히 긴 특징들의 목록을 제공하는 것은 아니다tsfresh라이브러리는 특징을 사용하는 하위작업에 연결되도록 설계되었다
2. 시계열의 분석 플랫폼: Cusium
- 시간의 관계성을 고려하지 않는 전체 데이터 분포에 대한 특징 - 시간에 무지하지만 매우 포괄적인 특징 목록 제공
- 데이터의 시간 분포를 표현하는 특징
- 시계열이 가진 행동의 주기성을 표현하는 특징
→ 특징 생성 외에도 웹 기반 GUI를 포함하고 있어서 특징을 시각적으로 생성할 수 있게 해주고 sklearn과도 통합됨
3. R의 tsfeatures 패키지
acf_features()와pacf_features()함수는 시계열 행동에 대한 자기상관의 중요성에 관련된 여러 가지 값을 계산lumpiness()와stability()함수는 타일 윈도 기능을,max_level_shift()와max_var_shift()함수는 롤링 윈도 기능을 제공unitroot_kpss()와unitroot_pp()함수
→ 학계에서 이루어진 다양한 시계열 특징 연구 프로젝트의 내용을 포함
특정 도메인에 특화된 특징의 예
📌 주식시장의 기술지표
-
상대강도지수(RSI)
- 는 상승 기간 동안의 평균 이득을 하락 기간 동안의 평균 손실로 나눈 비율
- RSI는 자산의 움직임에 대한 측정에 기반하기 때문에 '모멘텀 지표'로도 알려져 있음
-
이동평균 수렴발산(MACD)
- 자산의 단기간 지수이동평균과 자산의 장기간 지수이동평균 간의 차이에 대한 시계열
- 평균 시계열은 MACD 시계열의 지수이동평균
- 발산 시계열은 MACD 시계열과 평균 시계열 간의 차이에 대한 시계열
-
체이킨 머니 플로(CMF)
- 머니 플로 승수 ((종가-최저가)-(최고가-종가))/(최고가-최저가)를 계산
- 머니 플로 양을 계산 - 하루 거래량에 머니 플로 승수를 곱한 것
- 특정 기간의 날짜에 대한 머니 플로 양을 더하고, 같은 기간의 거래량으로 나눔 → -1과 1 사이를 움직이는 '오실레이터'
📌 헬스케어 시계열
ex) EKG 데이터
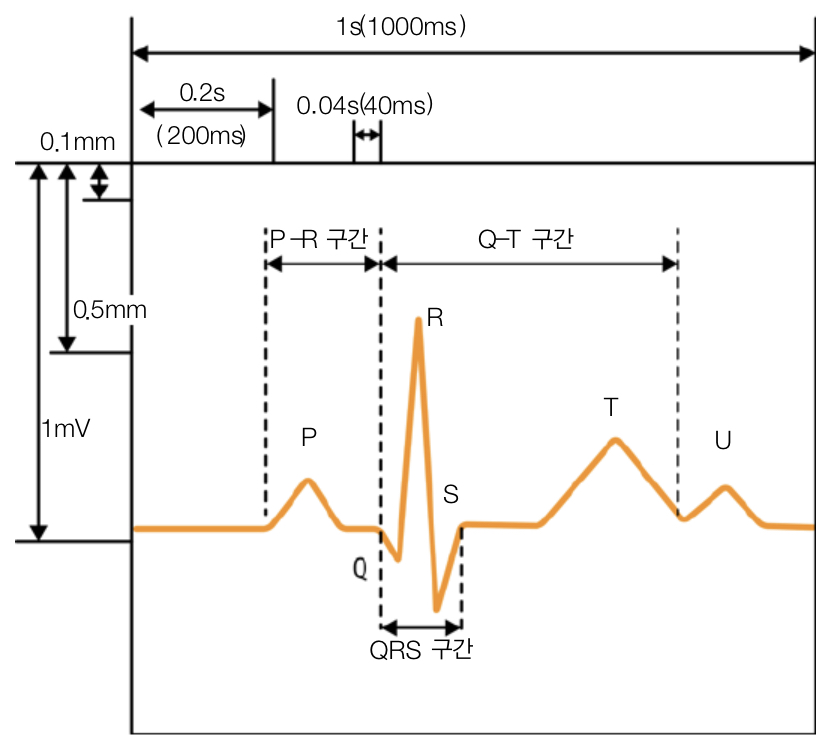
생성된 특징들 중 일부를 선택하는 방법
유용한 특징 선택 알고리즘 : FRESH
→ 확장 가능한 가설 검정에 기반한 특징 추출
→ 분산 방식으로 저장되는 경우가 많은 데이터를 병렬 계산을 용이하게 해줌
- 타깃 변수에 대한 각 입력 특징의 값을 계산하여 중요도를 평가
- 특징별 값은 허용 오차율 같은 입력 파라미터로 보존할 특징을 결정하는 벤자민-예쿠티에리 절차로 평가
tsfresh 를 사용해 자동으로 특징 추출
from tsfresh import extract_features
extracted_features = extract_features(timeseries, column_id = "id", column_sort = "time)재귀특징제거법(RFE) 으로 특징 선택 기법을 사용할 수 있다
FRESH 알고리즘이 고른 특징 목록 중 10개, FRESH 알고리즘이 기각한 특징 목록 중 10개를 무작위로 선택해 결합
x_idx = random.sample(range(len(features_filtered.columns)), 10)
selX = features_filtered.iloc[:, x_idx].values
unselected_features = list(set(extracted_features.columns).difference(set(features_filtered.columns)))
unselected_features = random.sample(unselected_features, 10)
unsel_x_idx = [idx for (idx, val) in enumerate(extracted_features.columns) if val in unselected_features]
unselX = extracted_features.iloc[:, unsel_x_idx].values
mixed_X = np.hstack([selX, unselX])20개의 특징에 대해 RFE를 수행하면 RFE에 사용되는 모델에 대한 중요도 순위를 알 수 있다
svc = SVC(kernel = "linear", C = 1)
rfe = RFE(estimator = svc, n_features_to_select = 1, step = 1)
rfe.fit(mixed_X, y)
rfe.ranking_array([9, 12, 8, 1, 2, 3, 6, 4, 10, 11, 16, 5, 15, 14, 7, 13, 17, 18, 19, 20])RFE를 사용해 선택된 특징을 좀 더 솎아낼 수 있고 입력 파라미터에 대해 미세조정, 최초 입력으로 생성한 특징의 개수를 조정할 때 온전성 검사를 위한 목적으로 사용할 수 있다
여러 가지 목적에서 특징 생성은 유용하다
- 머신러닝 알고리즘에 활용될 수 있는 형식으로 시계열의 데이터를 구성할 때 유용
- 시계열 데이터의 관측을 적은 수의 정량적 지표로 압축하여 요약하는 데 유용
- 다양한 조건에서 측정된 데이터를 설명하고, 유사성을 식별하기 위한 공통 지표를 제공
