HADOOP
- 대용량의 데이터를 저장, 처리, 분석을 할 수 있는 오픈 소스 프레임워크
- 목적: 대규모 데이터를 여러 대의 컴퓨터에서 병렬로 분산 처리하여 처리 속도향상, 비용 절감
- 등장 배경: 비정형 데이터의 기하급수적인 증가를 수용하기 위한 기존의 방식은(RDMS) 높은 비용 요구.
Google File System(2003) >> Google Map Reduce(2004) >> Hadoop(2005)
- 특징:
Server 증설 -> 선형적(X = Y) 성능 향상(Scale-Out) -> 비용절감
대용량 데이터(PB이상) 저장
한 번 저장된 데이터 수정 불가 -> 데이터 일관성(무결성) 보장
빠른 장애 복구 및 대응 -> 데이터 유실 방지
이중화(High Availability) (Hadoop 2.x) -> 운영 서비스 장애 방지
다양한 Haddop Ecosystem 연계 -> 데이터 저장/수집
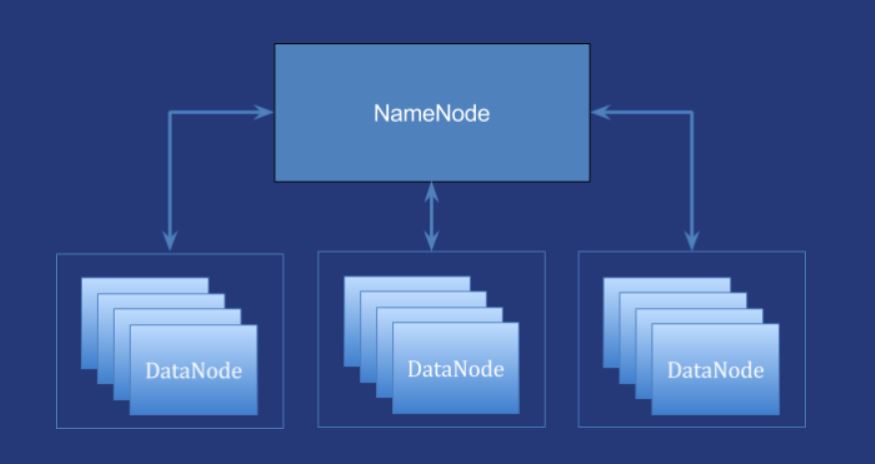
namenode vs datanode
-
namenode(MASTER)
메타 데이터 블록 관리
Hadoop에 저장된 file을 클라이언트가 접근 할 수 있도록 지원
Datanode 모니터링
백업을 위한 File(Fsimage, Editlog)저장 -
datanode(SLAVE)
실제 데이터 저장
Hadoop Job(ex. Mapreduce)수행 시 Datanode에서 작업
Namenode에게 주기적으로 상태 정보 전송
HADOOP VS RDMS


RDMS
구조화된 데이터 // 데이터가 저장된 서버에서 처리 // scale-up방식// 높은 유지보수 비용 // 데이터 정형화 필요 // Ggabyte급 데이터 저장
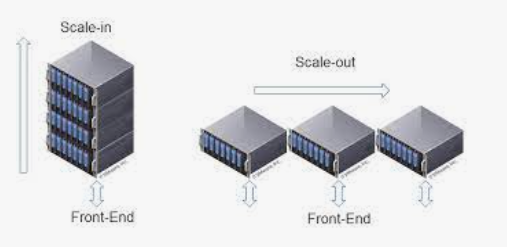
- Scale- up 방식이란? >> adding more components in parallel to spread out a load
Hadoop
데이터 저장소 확장 가능 // 다양한 확장 가능(에코시스템) // scale-out 방식 // 낮은 유지 보수 비용 // 정형& 비정형 데이터 // Petabyte 급 데이터
- Scale - out 방식이란? >> making a component bigger or faster so that it can handle more load
Hadoop의 구성요
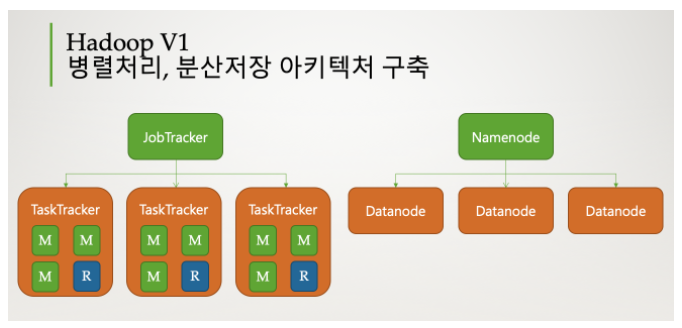
Hadoop V1
구성
HDFS
네트워크로 연결된 여러 컴퓨터에 file을 분산(Distribute)시켜 저장하는 File system
특징
대용량 데이터 분산 병렬 처리 -> File로 저장(file은 블록(64MB) 단위로 저장 )
장애 발생 해도 데이터 유실 방지(Fault Tolerance)
Namenode(Master) : file관리 Datanode(Slave) : file저장
Seconary Namenode: file 백업
1. Name node(MASTER): Data node를 관리, Hadoop에 저장된 file를 클라이언트가 접근 할 수 있도록 지원, 메타 데이터 & 블록관리( 하둡은 데이터를 저장할 때 블록 단위로 저장한다)
-
Data node(SLAVE): 실제 데이터가 저장되는 장소 , Namenode에게 주기적으로 상태 정보(HeartBeat와 Blcok Report)를 전송
-
Secondary Name node: Namenode의 File블록 저장 상태 기록, 장애 발생 시 기록했던 File로 장애 발생 시점 전의 데이터 복구(back-up)
-
MAPREDUCE
- 네트워크로 연결된 여러 컴퓨터에 File를 분산(Distribute)시켜 처리하는 프레임워크
- 안정성 높은 대용량 데이터 병렬 처리
- Example: WordCount
- Job Tracker: File관리
- TasK Tracker: File처리
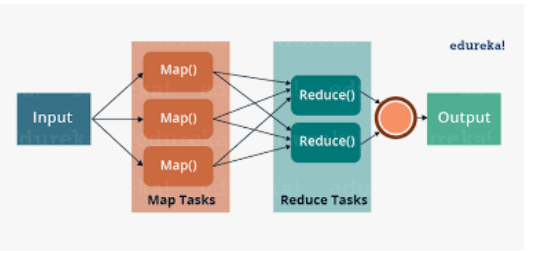
2-1) MapTask(데이터묶음): 입력 데이터 집합을 분할하여Key-value 형태 생성
2-2) Shuffle: Key별로 데이터 수집
2-3) ReduceTask(데이터집계):Key별로 모은 데이터에 대한 집계
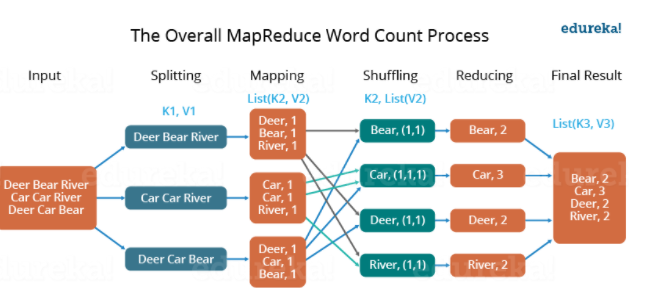
특징
Fault Tolerace
- Datanode가 1~4대까지 있다고 할 때, 3번의 datanode가 장애 발생하여 안에 있는 블록들이 일부 손상되었다.
- 장애가 발생한 서버의 블록을 다른 서버에 각각 복제하여 데이터 유실을 방지한다.
Rebalancer
- Datanode(3번) 복구 -> Rebalancer -> File 블록 분산 저장
- 블록 복제 개수 설정 가능(Deault 값은 홀수로 하자 ex 3, 5)
한계
1. 이중원화를 지원하지 않는다.
- NameNode장애 발생 시, 복구 전까지 데이터 사용 불가(이중화를 지원 하지 않는다.)
이중화란?! - 운영중인 서비스의 안정성을 위해 각종 자원을 이중 또는 그 이상으로 구성하는 것.
- JobTracker 과부하
- JobTracker 한개에 너무 많은 역할이 몰려 있음(Resource 관리, Job, 스케줄링/모니터링..)
- 하둡 에코시스템과 연계과 어렵다.
- 데이터 처리시 Mapreduce로만 수행 - 프로그래밍 언어(JAVA)에 대한 지식 필수
- 길고 복잡한 Code로 인한 기술지원&유지보수의 어려움
- 즉각적인 응답의 어려움(온라인 자원을 사용하기 어렵다)
- 대용량 데이터(배치 처리 주로 수행) -> 즉각적인 응답의 어려움
- 여러 사용자 운영 환경 지원 X(타 Ecosystem 연계 어려움)
- 클러스터당 노드 수 4000대 이상 확잘 불가
- Map과 Reduce에대한 자원 할당 고정. 따라서 추가 JOb을 수행하기 어렵다.
Hadoop V2
Hadoop 2 is also a Master-Slave architecture. But this consists of multiple masters (i.e active namenodes and standby namenodes) and multiple slaves
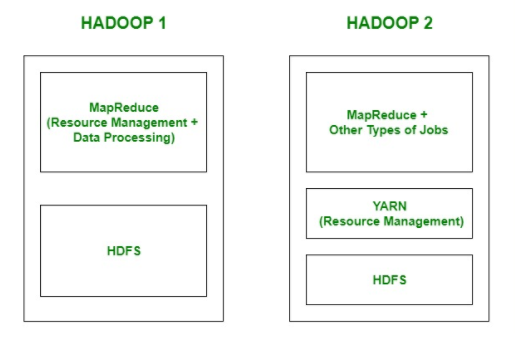
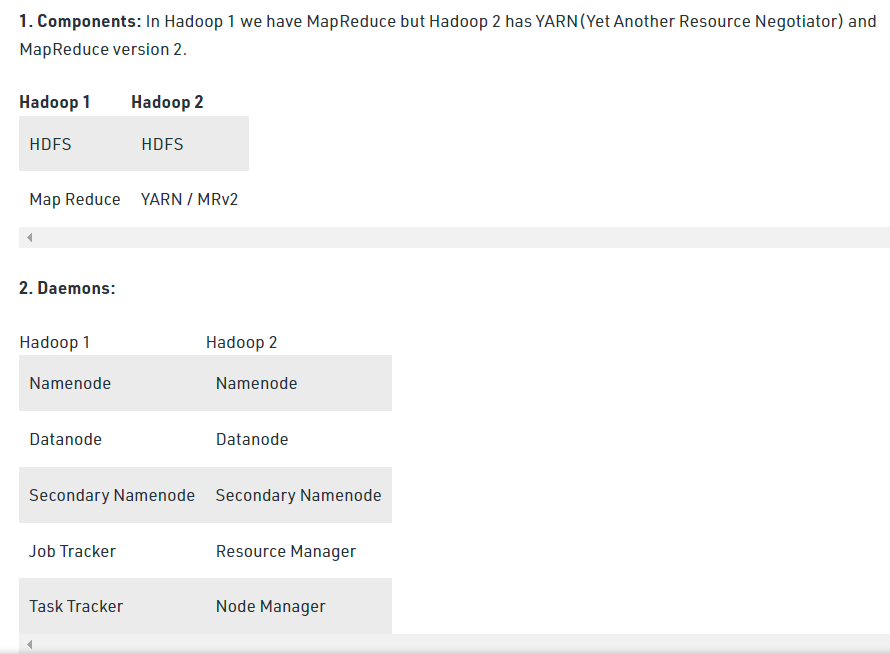
YARN(Yet Another Resource Negotiator)
Hadoop V3
HDFS
= Hadoop Distributed File System
= 데이터 저장의 분산 파일 시스템
provides for the storage of Hadoop. As the name suggests it stores the data in a distributed manner. The file gets divided into a number of blocks which spreads across the cluster of commodity hardware.
MapReduce
This is the processing engine of Hadoop. MapReduce works on the principle of distributed processing. It divides the task submitted by the user into a number of independent subtasks. These sub-task executes in parallel thereby increasing the throughput.
-
YARN 상에서 동작하는 분산 애플리케이션 중 하나이며, 분산 시스템에서 데이터 처리를 실행하는데 사용.
-
흩어져 있는 데이터를 수직화, 그 데이터를 각각의 종류별로 모으고(Map), 필터링과 정렬을 거쳐 데이터를 추출(Reduce)하는 분산처리 기술과 관랸된 FrameWork.

YARN
= Yet Another Resource Negotiator
- 각 어플리케이션에 필요한 자원을 할당하고 모니터링하는 프레임워크
- 자원 균등 할당 -> Hadoop 1.x의 고정된 자우너 할당 문제 해결
- 여러 job수행 >> job마다 scheduler 특성(Fair, Capacity) 활용하여 자원 할당
- 다양한 Ecosystem(hive, spark..) 연계 >> 보다 쉽고 빠른 데이터 정제/분석
특징
- 역할분리(자원 관리 & 스케줄링/모니터링)
-
JobTracker의 역할을 Resource Manager 와 Application Master로 분리
-
Resource Manager: 자원관리 담당
-
Application Master: Job에 대한 스케줄링과 모니터링 담당
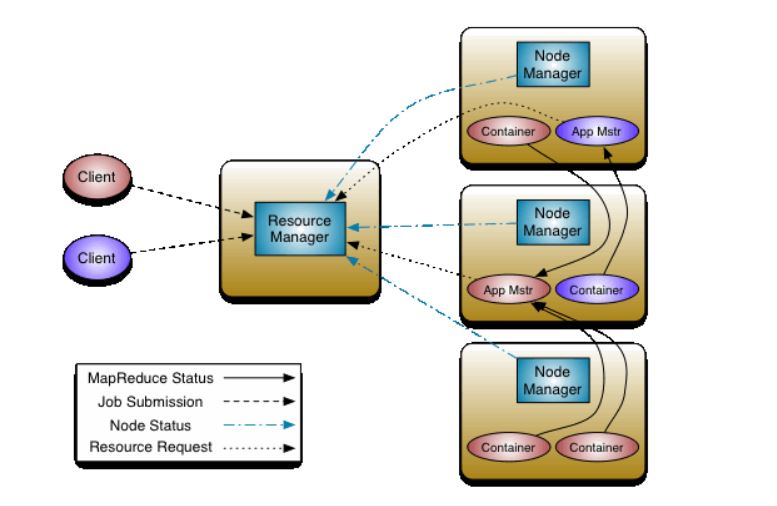
출처: https://data-flair.training/blogs/how-hadoop-works-internally/
https://spidyweb.tistory.com/239?category=910416
