데이터 처리
분산처리 VS 병렬처리
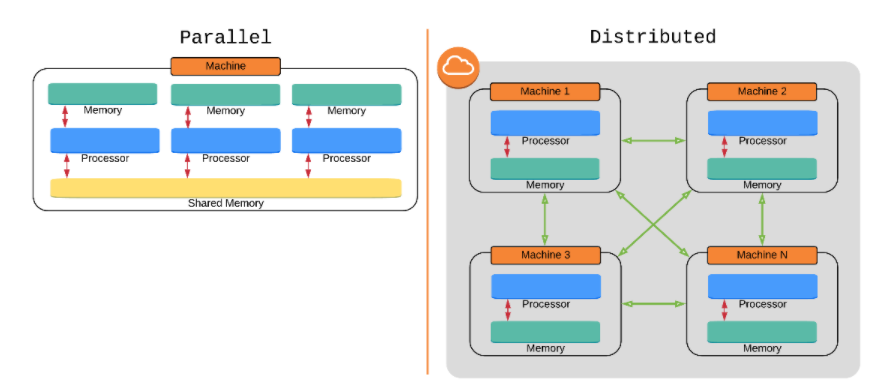
분산처리
한가지의 일을 여러 컴퓨터들에게 나누어서 동시에 처리하는 시스템 방식
병렬처리
프로세서를 늘려서 여러 일을 동시에, 더 빨리 처리 할 수 있게 해주는 시스템 방식
맵리듀스 VS 하둡 VS 스파크
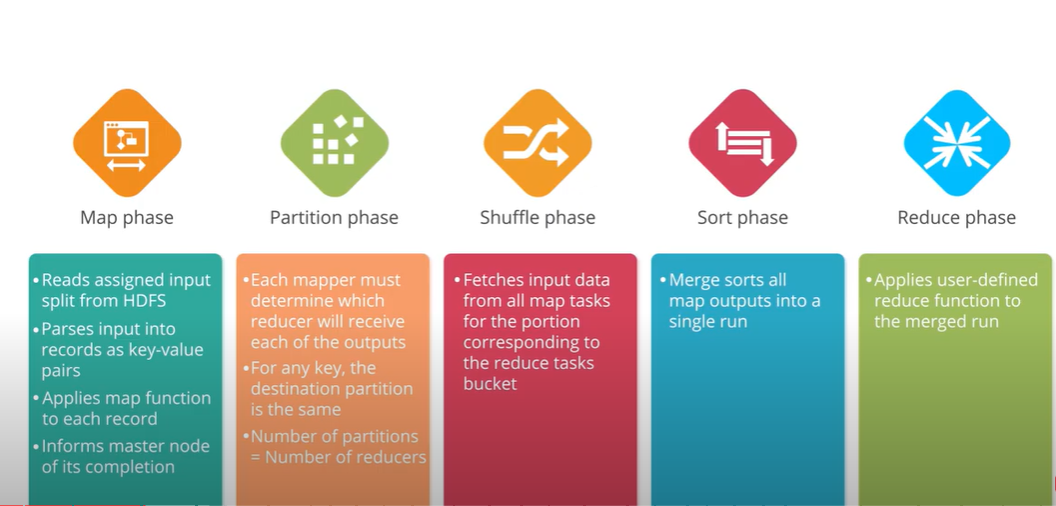
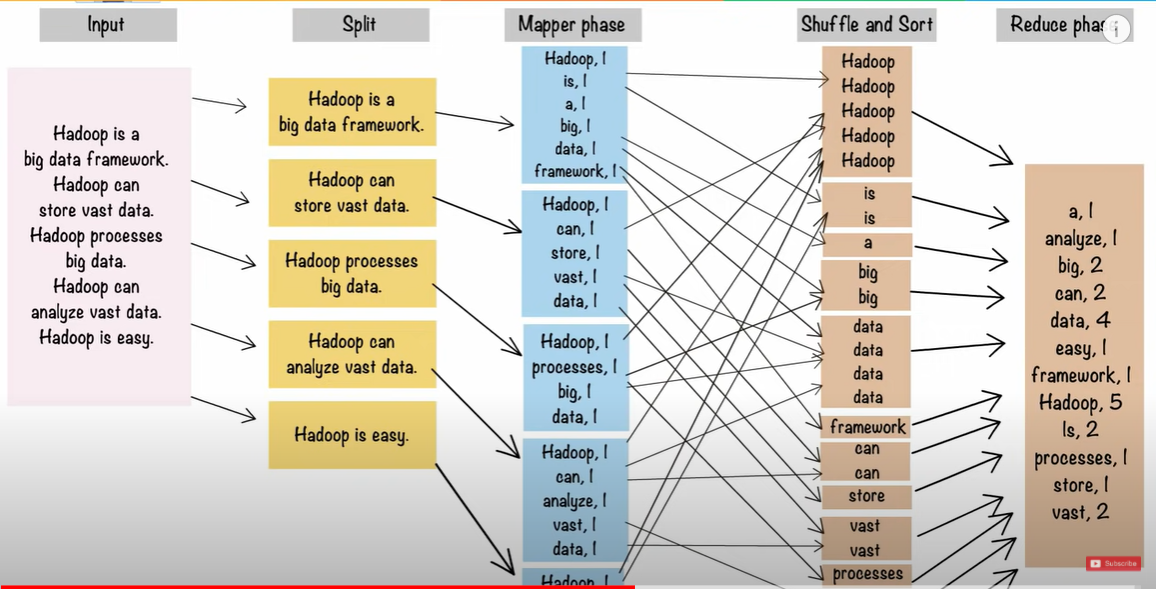
맵리듀스(Mapreduce)
구글이 빅데이터 처리를 위해 만든 프레임워크.
- prior to 2004, Huge amounts of data were stored in single server. so the threat of data loss, challenge of data backup, and etc comes up.
하둡(Hadoop)
용량 데이터를 분산 처리할 수 있는 자바 기반의 오픈 소스 프레임워크
빅데이터를 처리하기 위해 3가지의 components로 디자인 되었다.
- Stroage Unit (HDFS)
HDFS splits thet data into multiple blocks of data, and 128 megabytes is the default size of each block.
HDFS makes copies of the data and stores it across multiple systems.
- MapReduce
- Traditional data processing method
- Single Machine having a single processor. It is rally inefficient espeically when processing large volumes of a variety of data
- split data into parts and processes each of them separately on different data nodes
- Yarn
- to efficiently manage these resources
- consists of a resource manager, node manager, Application master, and containers.
첫째, application master requests the container from the node manager
둘째, once the node manager gets the resources, it sends them to the resource manager
셋째, yarn preocesses job requests and manages cluster resources in hadoop
스파크(Spark)
빅데이터 처리를 위한 오픈소스
하둡 VS 스파크
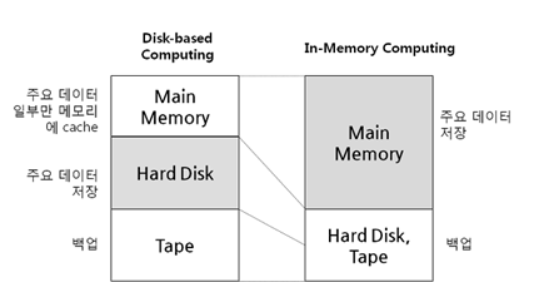
하둡은 데이터를 디스크를 기반으로 다룬다.
스파크는 데이터를 메모리 기반으로 다룬다.
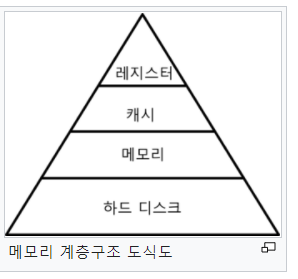
메모리 구조
레지스터와 캐시는 CPU내부에 존재하기 때문에 빠르게 접근할 수 있다.
메모리는 CPU외부에 존재하기 때문에 레지스터와 캐시보다 느리게 접근한다.
하드디스크는 CPU가 접근할 방법이 없기 때문에, 디스크의 데이터를 메모리로 이동시켜 접근해야 한다.
In-Memory DB VS Disk-Based DB