정의
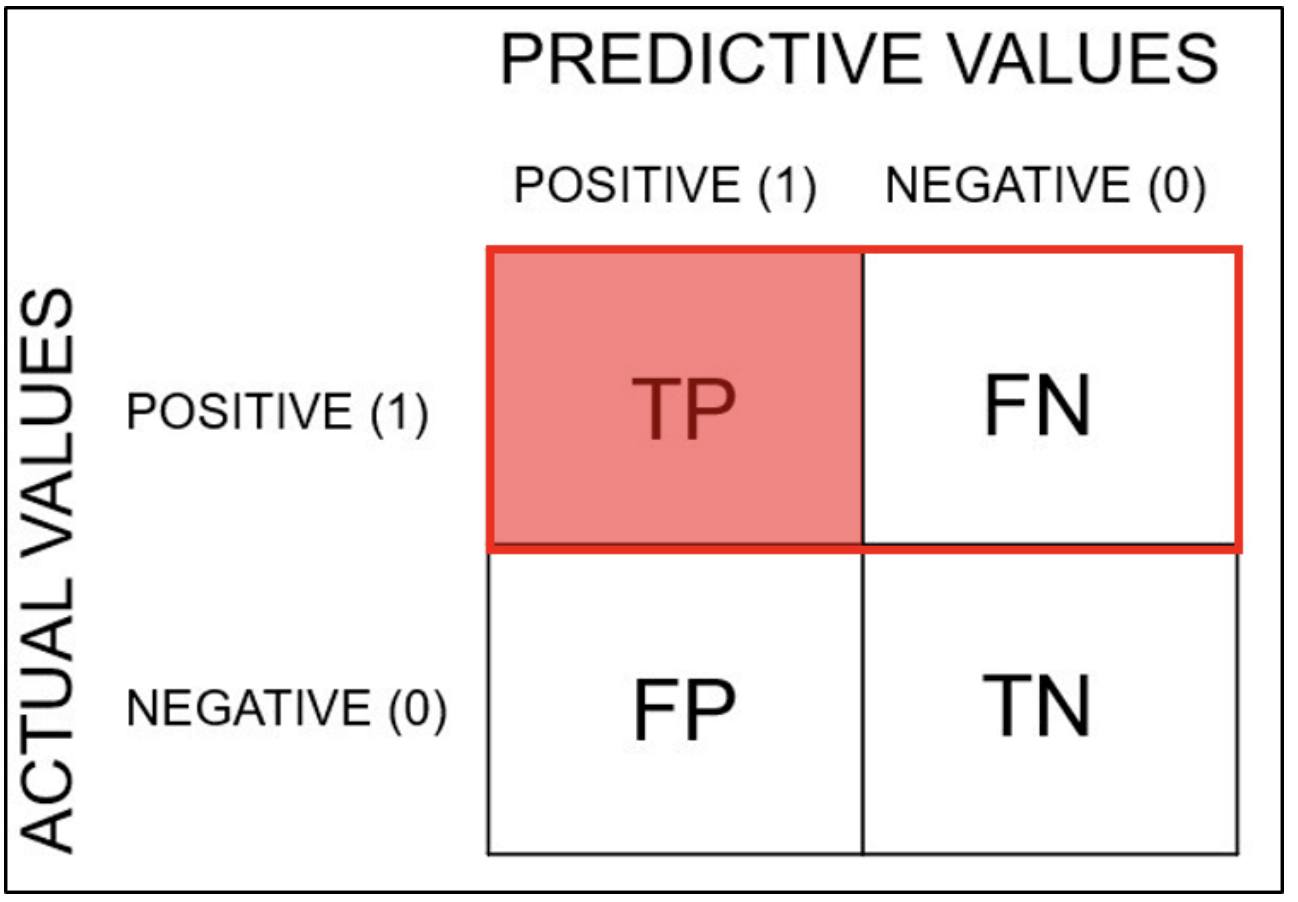
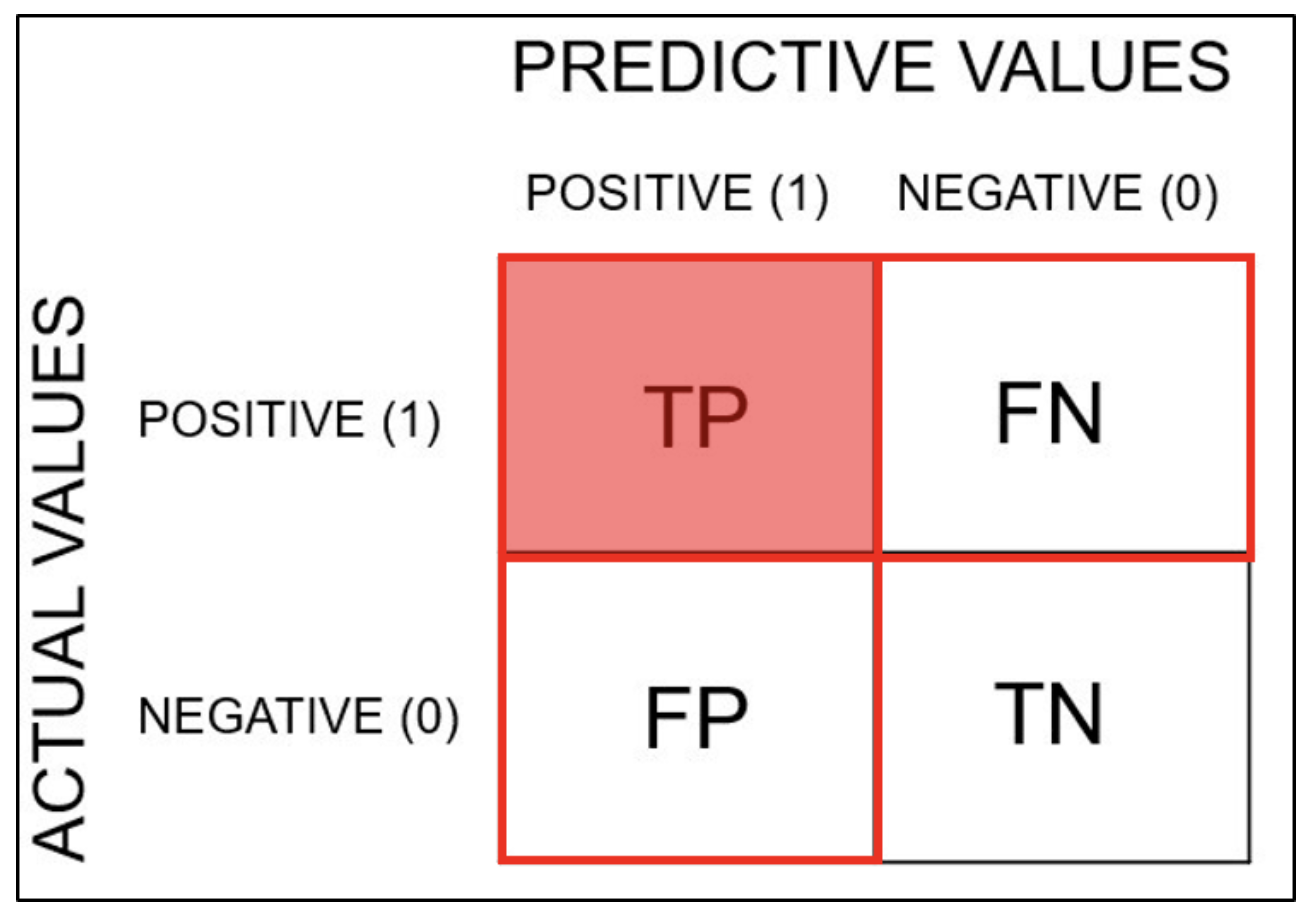
분류모델의 성능 평가 지표를 보여주는 표로 training을 통한 prediction 성능을 예측하기 위해 예측 value와 실제 value를 비교하기 위한 표이다.
Confusion Matrix(혼동 행렬, Error Matrix): Specific table layout that allows visualization of the performance of an algorithm, typically a supervised learning one (in unsupervised learning it is usually called a matching matrix. 출처: 위키피디아 'confusion matrix'
python 구현
#confusion matrix 시각화
from sklearn.metrics import plot_confusion_matrix
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
pcm = plot_confusion_matrix(pipe, X_val, y_val,
cmap = plt.cm.Blues, ax=ax)
plt.title(f'confusion matrix, n= {len(y_val)}',fontsize=15)
plt.show()
#plot_confusion_matrix에서 테이블 데이터만 가져오기
from sklearn.metrics import plot_confusion_matrix
pcm = plot_confusion_matrix(pipe, X_val, y_val,
cmap = plt.cm.Blues, ax=ax)
cm = pcm.confusion_matrix
cm평가지표
모델(분류기)의 정확한 성능을 판단하기 위해서는 정확도 외의 다른 평가지표를 같이 사용해야한다. 특히 정밀도(precision)과 재현율(recall)을 살펴보면서 내가 해결하고자 하는 문제에 적합한 모델이 얼마나 성능이 좋은지 판단할 수 있도록 평가지표를 정해주는 것이 좋다.
- 병원에서 초기 암진단을 하는 경우
- 메일함에서 스팸메일을 분류하는 경우
암진단의 경우 초기에 암을 잡아야 완치할 가능성이 커진다. 그런데 암환자가 아닌데 암이라고 진단할 수도 있고 암환자인데 암이 아니라고 진단할 수도 있다. 이 경우에서 문제되는 것은 암환자인데도 암이 아니라고 진단한 경우로 이를 FN라고 설정한다면 Recall값이 큰 모델이 더 좋은 모델이라고 할 수 있다.
메일함에서 스팸메일을 분류할 때 중요한 메일을 스팸메일로 분류하지 않는 것이 중요하다고 할 수 있다. 스팸메일이면 positive라고 설정한 뒤 벌어질 수 있는 오류를 생각해본다. 스팸메일이 아닌데 스팸메일이라고 분류할 경우와 스팸메일인데 스팸메일이 아닌 것으로 분류하는 오류를 범할 수 있다. 이 때 내가 일반 메일을 스팸메일로 분류하는 것이 더 치명적이라고 생각한다면 FP를 줄인 모델이 더 좋은 모델이라고 할 수 있다. 즉, precision 값이 큰 모델이 더 좋은 모델이라고 볼 수 있는 것이다.
평가지표들을 한 눈에 볼 수 있기도 하다.
classification report
classification_report function builds a text report showing the main classification metrics.
from sklearn.metrics import classification_report
y_true = [0,1,2,2,0]
y_pred = [0,0,2,1,0]
target_names = ['class 0','class 1','class 2']
print(classification_report(y_true, y_pred, target_names=target_names))이 결과는 target_names에 대해 precision, recall, f1-score 등을 나타내준다. 공식 문서
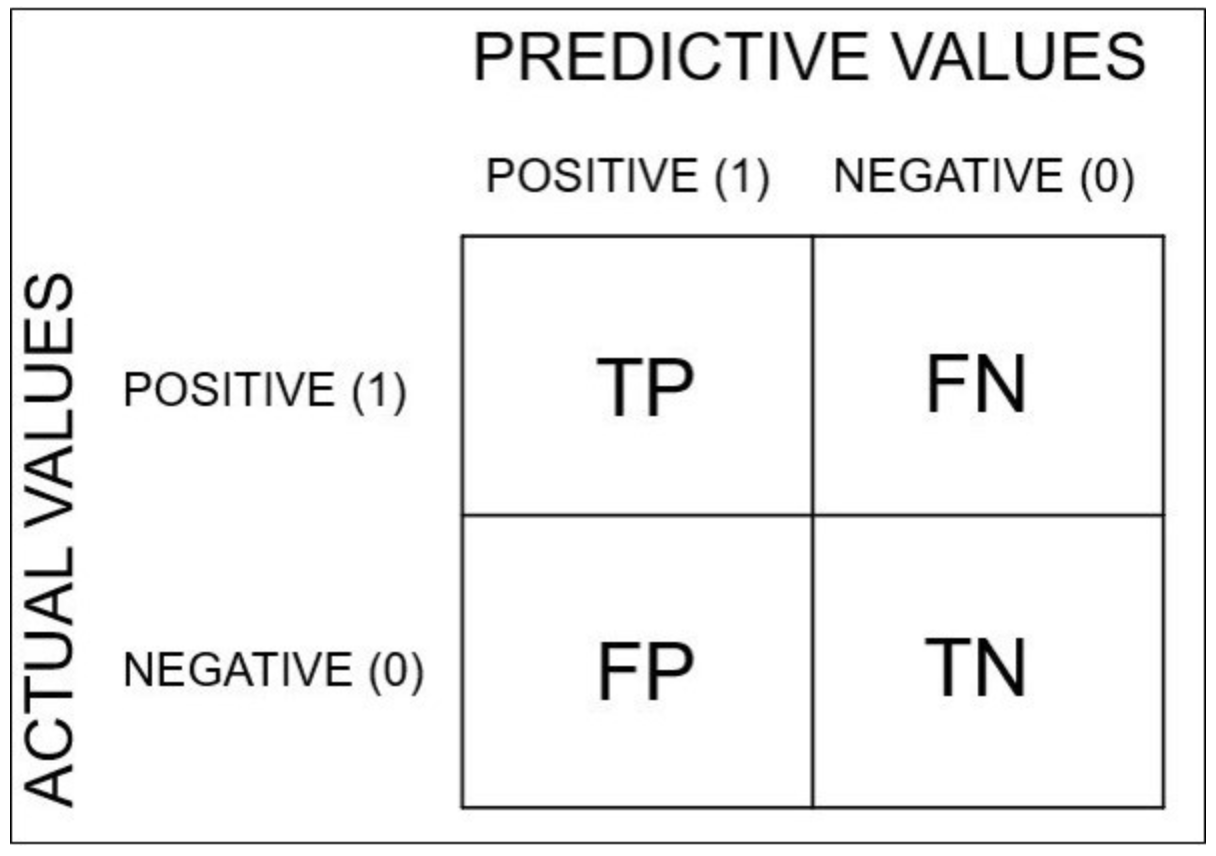
Accuracy(정확도)
모델이 정확하게 분류한 비율이다.
참인 것을 참이라 분류하고 거짓인 것을 거짓이라고 분류한 비율인 것이다.
즉 TP, TN의 비율이다.
TP = cm[0][0]
TN = cm[1][1]이런 식으로 지정해서 구할 수는 있지만 Positive와 Negative를 어떻게 설정하였는 지 살펴보아야 한다.
correct_prediction = np.diag(cm).sum()
total_prediction = cm.sum()
correct_prediction/total_predictionaccuracy_score(y_val,y_pred)로 계산한 검증 정확도와 같은 값이다.
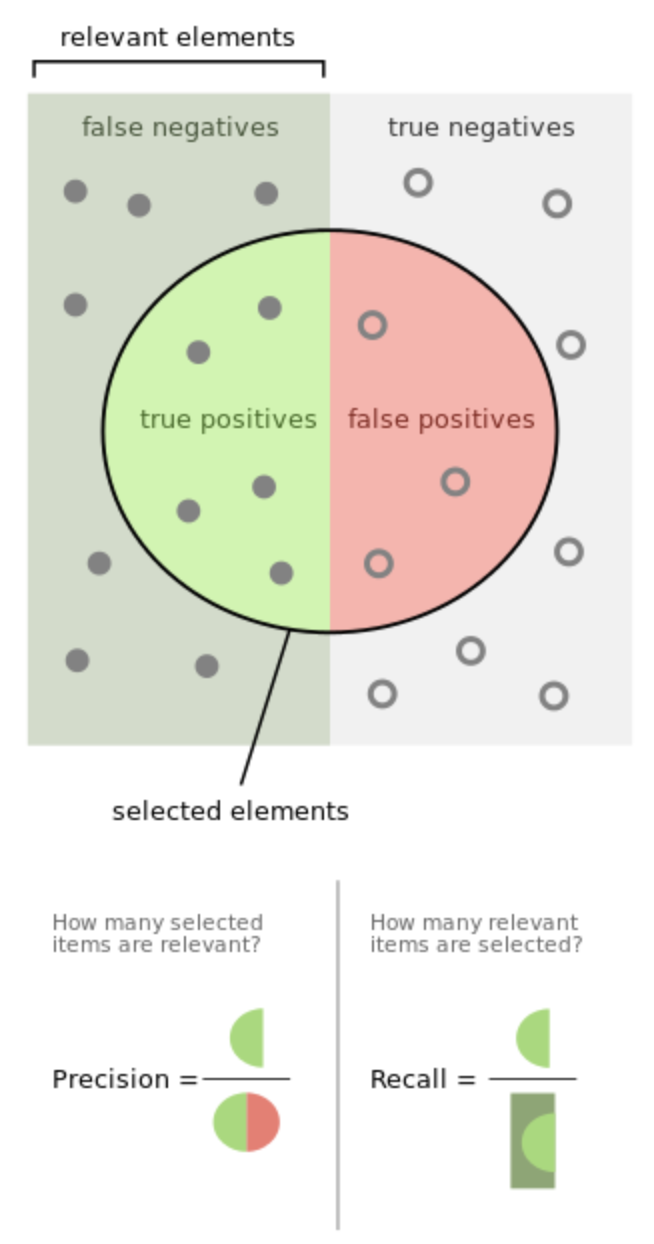
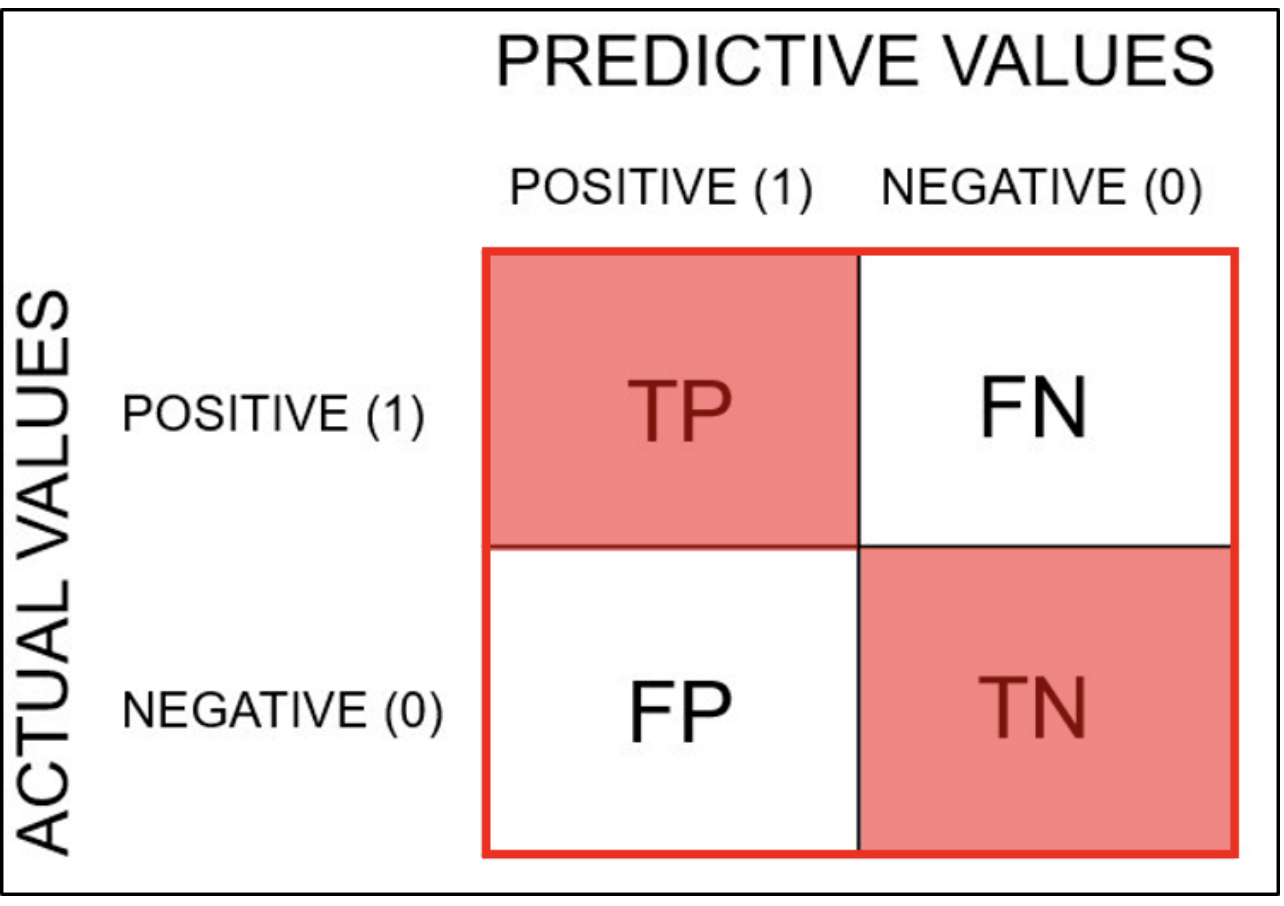
Precision(정밀도)
모델이 positive라고 분류한 것들 중 실제로 positive인 데이터의 비율이다.
참이라고 분류한 것들 중 실제로는 거짓인 것과 참이 있는데, 이 중 참인 것들이 얼마나 있는지에 대한 비율이다.
즉 TP, FP에 대한 TP의 비율이다.
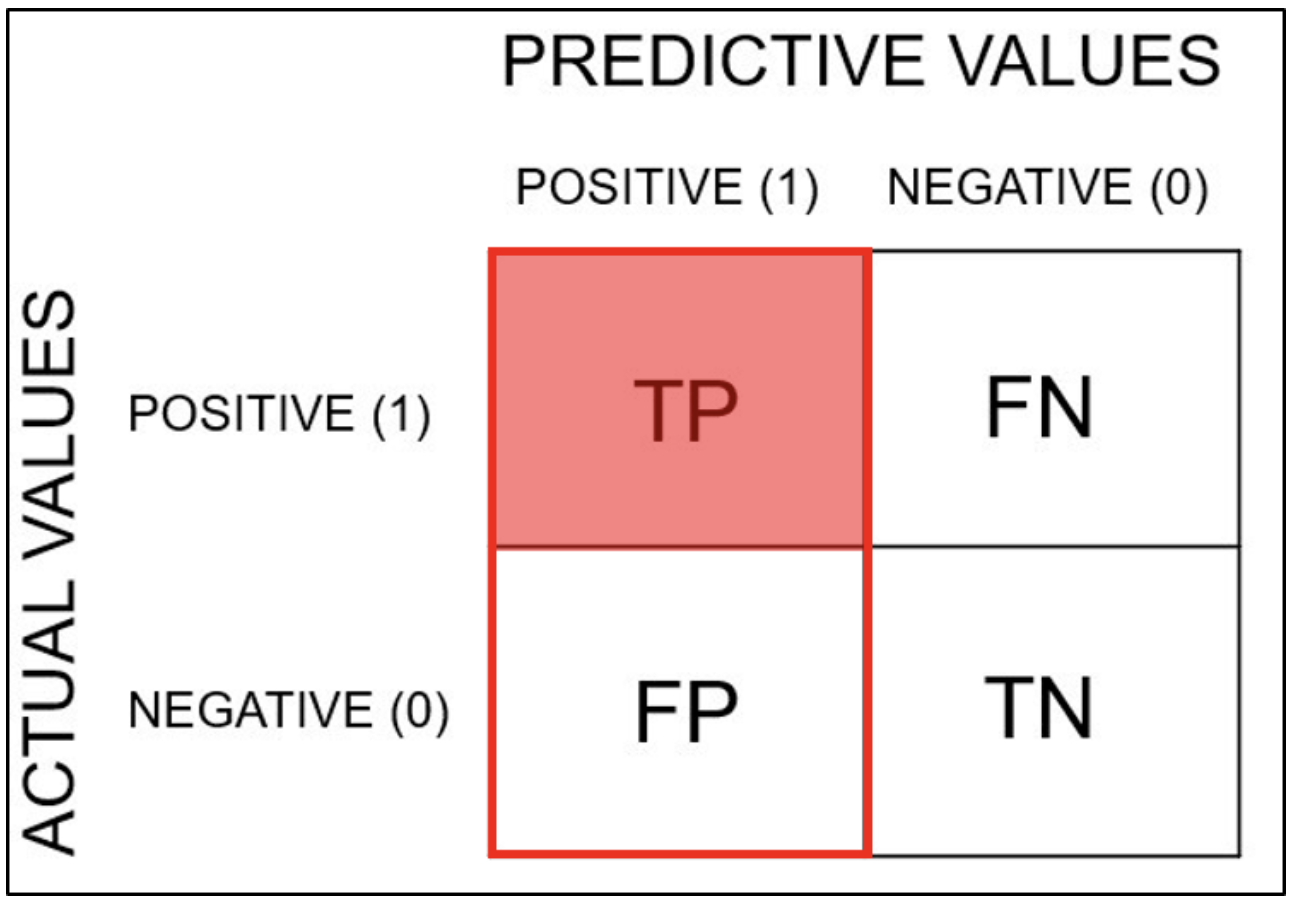
Recall(재현율)
실제로 positive인 데이터들 중 모델이 positive라고 분류한 데이터의 비율이다.
즉, TP와 FN에 대한 TP의 비율이다.
f1 score(조화 평균)
Precision과 Recall의 조화평균이다.
data imbalance에서 accuracy보다 모델이 일반적으로 얼마나 정확하게 처리하는지 알 수 있다.
model imbalance일 때 f1-score
class가 A, B, C, D로 나누어진 데이터를 분류하는 모델 1과 모델 2가 있다고 해보자. 실제 데이터에는 A가 200, B가 10, C가 10, D가 10이 있는데 모델 1과 모델 2는 각각 아래의 그림처럼 분류를 했다고 하자.

모델 1는 각각의 class를 전반적으로 잘 맞추고 모델 2는 A class에 대해서만 잘 맞추는 모델이다. 정확도만 보면 A class에 대해서는 모델 2가 모델 1보다 성능이 좋다고 할 수 있지만 전반적인 성능을 보면 모델 1이 모델 2보다 성능이 좋다고 할 수 있다.
