machine learning 알고리즘들 중에는 모든 문제에 적용가능한 최고의 학습 모델은 존재하지 않는다.
- 우리는 문제를 풀기 위해 어떤 학습 모델을 사용해야 하는가?
- 어떤 하이퍼파라미터를 사용해야 하는가?
이러한 문제를 고려하는 것은 모델선택(Model Selection)의 과정이다.
이러한 데이터의 크기에 대한 문제와 모델 선택에 대한 문제를 해결하기 위해 사용하는 방법 중 하나가 바로 교차검증이다.
❗️ 시계열(time series)데이터에는 교차검증이 적합하지 않다.
hold-out 교차검증
데이터를 훈련/검증/테스트 세트로 나누어서 학습 진행하는 방법
단점
- 훈련세트의 크기가 모델학습에 충분하지 않을 경우 문제가 될 수 있다.
- 검증세트의 크기가 충분하지 않으면 예측 성능에 대한 추정이 부정확하다.
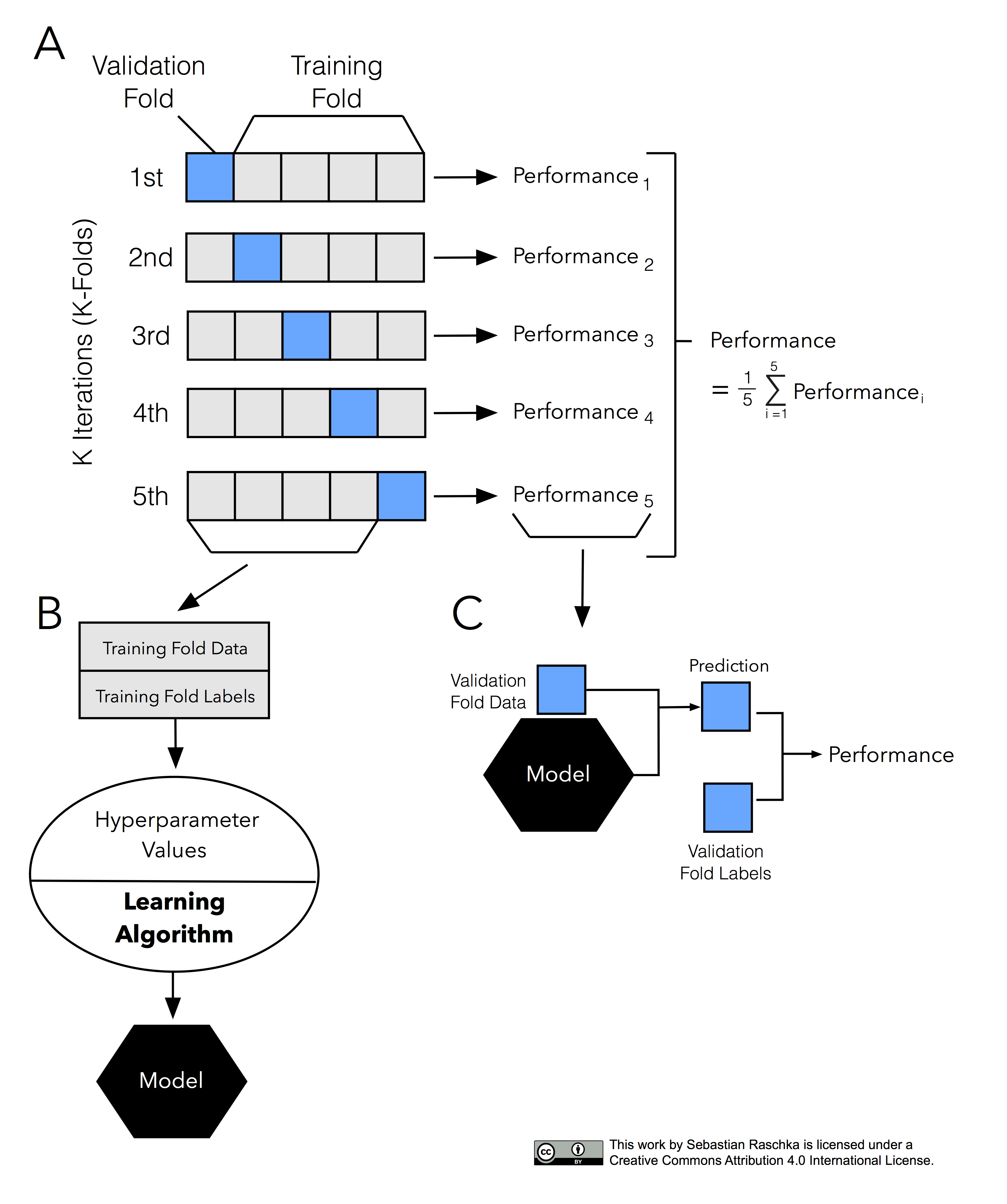
k-fold cross-validation(CV)
데이터를 k개로 등분해서 교차검증을 하는 것.
k개의 집합에서 k-1개의 부분집합을 훈련에 사용하고 나머지 부분집합을 테스트 데이터로 검증한다.
예) 3-fold crossvalidation : 데이터를 3등분하고 검증(1/3)과 훈련세트(2/3)를 총 세 번 바꾸어가며 검증하는 것으로 총 3번 검증한다.
sklearn.model_selection.cross_cal_score
사이킷런에 cross_val_score를 사용하면 교차검증을 쉽게 적용할 수 있다.
학습된 모델, 학습데이터, 타겟데이터, k값(default=5)를 준비하면 쉽게 사용할 수 있다.
#3-fold 교차검증을 수행한다고 가정해보자.
k = 3
scores = cross_val_score(pipe, X_train, y_train, cv = k,
scoring = 'neg_mean_absolute_error')
print(f'MAE({k} folds):',-scores) 
💛 공부 블로그 💛