Cross Validation이란?
인공지능 모델을 학습할 때 데이터를 train data세트와 test data세트로 나누어서 수행하곤 한다. 훈련데이터를 통해 모델을 학습시키고 테스트 데이터로 이 모델이 유용한지 평가하는 것이다.
그러나 이 경우 테스트 데이터로 성능을 검증하고 수정하는 과정을 반복할 때 모델이 테스트 데이터에서만 잘 작동하는 모델이 될 수 있다. 이렇게 특정한 데이터에 지나치게 적합하게 된 경우를 과적합(Over fitting)이라고 한다.
이러한 과적합을 방지하고 모델이 현실을 더 적합하게 해석할 수 있도록 사용하는 방법이 바로 Cross Validation이다.
Cross validation은 train set을 다시 한 번 train set과 validation set으로 나누어 학습시캬 검증과 수정을 하는 것을 의미한다.
이를 통해 데이터의 편중을 막고 한정된 데이터로도 정확도를 향상시킬 수 있다.
이 때, iteration 횟수가 많아 훈련과 평가에 시간이 많이 걸리지 않도록 유의.
어떤 검증방법을 사용하기 전에 문헌조사로 자신이 연구하는 분야에서 보통 어떤 검증 방법을 채택하는 지 살펴본 후 해결하고자 하는 방향에 맞춰 cross validation 방법을 선택해야 한다.
Hold-Out Cross Validation
Hold-Out은 훈련 데이터 세트와 테스트 세트로 분리한다.
많은 경우 데이터세트의 80%를 훈련세트로 삼고 나머지 20%를 테스트세트로 이용하는 것 같지만 이는 상황에 따라 변동할 수 있다!
train dataset이 작으면 모델 정확도의 분산이 커져 underfitting의 가능성이 커지고 train dataset이 크면 test set으로부터 측정한 정확도의 신뢰도가 overfitting되어 하락할 수 있다.
데이터의 수는 모델의 성능에 큰 영향을 미치는 경우가 많기 때문에 일단 데이터를 많이 수집하는 것이 필요하며 한정되어 있는 데이터에서 최고의 효율을 가지기 위해 나온 random subsampling이 있다. 이는 한정되어 있는 데이터에서 train set과 test set을 바꿔가면서 hold-out을 반복적으로 실행하는 것을 의미한다.
이 방식은 학습에서 제외시킨 테스트 데이터를 학습-평가에 반영하지 않는다는 점이 단점으로 부각되었다.
K-Fold Cross Validation
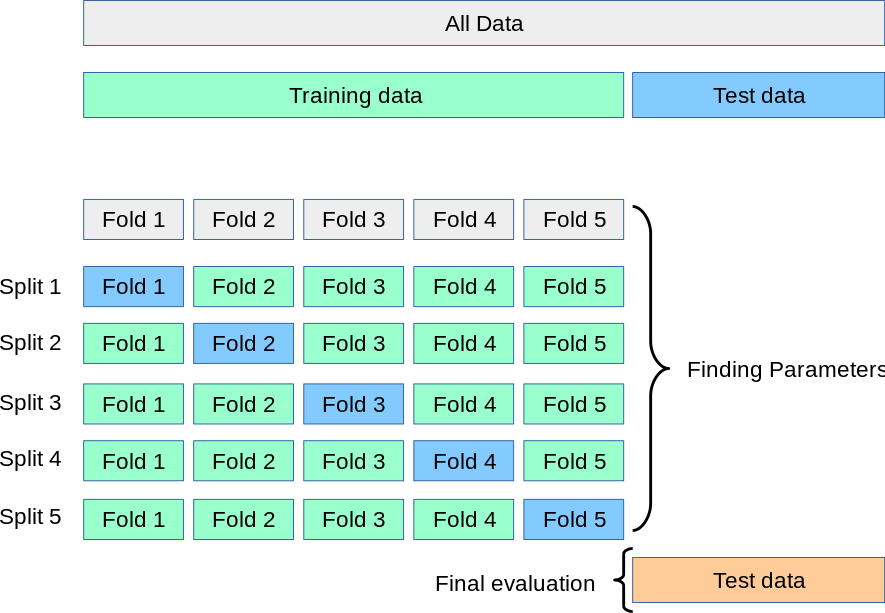
데이터셋을 K개의 fold로 나누어 사용되며 k번의 실험을 통해 1개는 테스트 데이터셋으로, K-1개는 학습 데이터로 반복적으로 실험하는 것이다.
데이터의 수가 상대적으로 적은 경우에도 수차례 검증할 수 있다는 점이 두드러진다.
최종적인 성능은 k번의 실험 성능의 평균으로 도출이 되는 것으로 보인다.
당연하겠지만, k가 커질수록, 즉 나누는 집단의 수가 클수록 계산량이 많아진다.
leave-one-out cross validation(LOOCV)

K-Fold Cross Validation에서 k를 매우 크게하여 데이터 사이즈와 같게 하는 방법으로 결국 모든 데이터 한 개씩을 빼가면서 모든 데이터를 테스트하는 방법이다.
데이터의 수가 클수록 m(데이터 사이즈)번의 모델링을 진행해야하기 때문에 시간이 오래 걸린다.
회귀, 로지스틱, 분류 모형 등에 다양하게 적용할 수 있다.
참고자료
https://velog.io/@recoder/Cross-Validation
https://doublekpark.blogspot.com/2019/01/3-resampling-leave-one-out-cross.html
