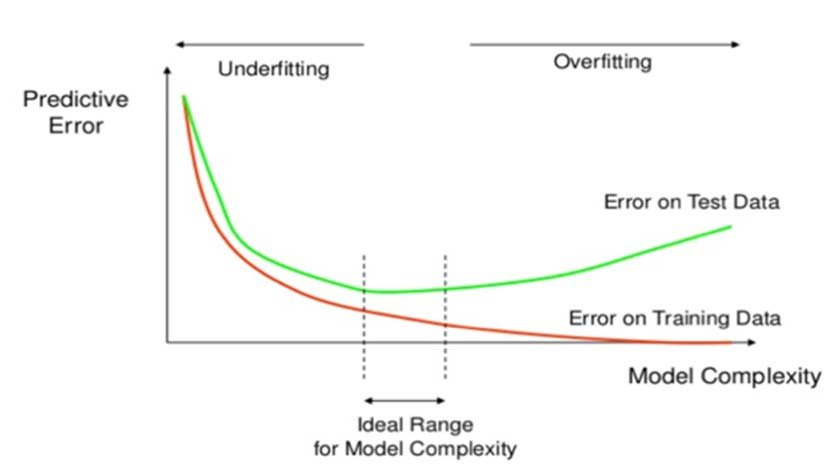
이상적인 모델은 과적합과 과소적합 사이에 존재한다. 최적화(훈련 데이터로 더 좋은 성능을 얻기 위해 모델을 조정하는 과정)와 일반화(학습된 모델이 처음 본 데이터에서 얼마나 좋은 성능을 내는가)가 좋은 모델의 특성이 된다. 모델의 복잡도를 높이는 과정에서 훈련 및 검증 세트의 손실이 함께 감소하는 시점이 과소적합이다.
하이퍼 파라미터란?
파라미터(Parameter, 인자)란 가중치나 편향처럼 모델의 학습 과정에서 자동으로 업그레이드되며 갱신되는 값으로 모델이 스스로 조정하는 값이기에 연구자가 직접 조정할 수 없다.
하이퍼파라미터(Hyper Parameter)란 연구자가 수정할 수 있는 값으로 학습률, optimizer, 활성화 함수, 손실 함수 등이 있다. 하이퍼 파라미터를 통해 모델이 학습한 데이터셋을 잘 모르거나 데이터 셋의 형태를 모를 때에도 데이터의 패턴을 찾아 모델에 학습시켜줄 수 있다.
하이퍼파라미터는 모델 훈련 중에 학습아 되지 않는 파라미터로 사용자가 직접 설정해주는 인자이다. 현실적으로 하이퍼파라미터를 수작업으로 정해주는 것은 어렵다. 최적의 하이퍼파라미터 조합을 찾아주는 도구들로 GridSearch CV와 RandomizedSearch CV를 들 수 있다.
하이퍼 파리미터 조합 찾는 방법
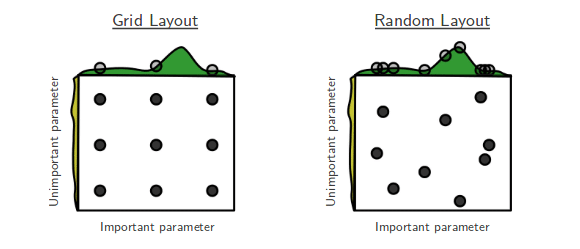
Randomized Search CV
Randomized Search CV : 검증하려는 하이퍼파라미터들의 값 범위를 지정해주면 무작위로 값을 지정해 그 조합을 모두 검증한다.
여러 하이퍼파라미터의 최적값을 찾기 위해 사용하는 검증이다.
#릿지 회귀모델의 하이퍼파라미터 튜닝하기
from sklearn.model_selection import RandomizedSearchCV
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True)
, SimpleImputer()
, StandardScaler()
, SelectKBest(f_regression)
, Ridge()
)
# 튜닝할 하이퍼파라미터의 범위를 지정해 주는 부분
dists = {
'simpleimputer__strategy': ['mean', 'median'],
'selectkbest__k': range(1, len(X_train.columns)+1),
'ridge__alpha': [0.1, 1, 10],
}
clf = RandomizedSearchCV(
pipe,
param_distributions=dists,
n_iter=50,
cv=3,
scoring='neg_mean_absolute_error',
verbose=1,
n_jobs=-1
)
clf.fit(X_train, y_train);
print('최적 하이퍼파라미터: ', clf.best_params_)
print('MAE: ', -clf.best_score_)위의 예에서 RandomSearchCV는 n_iter(=50)*cv(교차검증, cv = 3) 즉, 150번의 task를 수행했다.
GridSearch CV
GridSearch CV : 검증하고 싶은 하이퍼파라미터들의 수치를 정해주고 그 조합을 모두 검증한다.
위의 예에서 GridSearchCV를 통해 이 범위를 검색하려면
2 impitation n cols 3 alphas 3 cv = 2 len(X_train.columns) 3 3 = 1386의 태스크를 해야한다.
각 하이퍼파라미터 조합으로 만들어진 모델들을 순위별로 나열하기
# rank_test_score: 테스트 순위
# mean_score_time: 예측에 걸리는 시간
pd.DataFrame(clf.cv_results_).sort_values(by = 'rank_test_score').T선형회귀, 랜덤포레스트 모델들의 튜닝 추천 파라미터
Random Forest
class_weight: 불균형(imbalanced)클래스인 경우 사용.max_depth: 너무 깊어지면 과적합이 된다.n_estimators: 적을 경우 과소적합, 높을 경우 긴 학습 시간.min_samples_leaf: 과적합일 경우 높여준다.max_features: 줄일수록 다양한 트리를 생성한다.
Logistic Regression
C: inverse of regularization strengthclass_weight: 불균형 클래스인 경우penalty
Ridge/Lasso Regression
alpha
